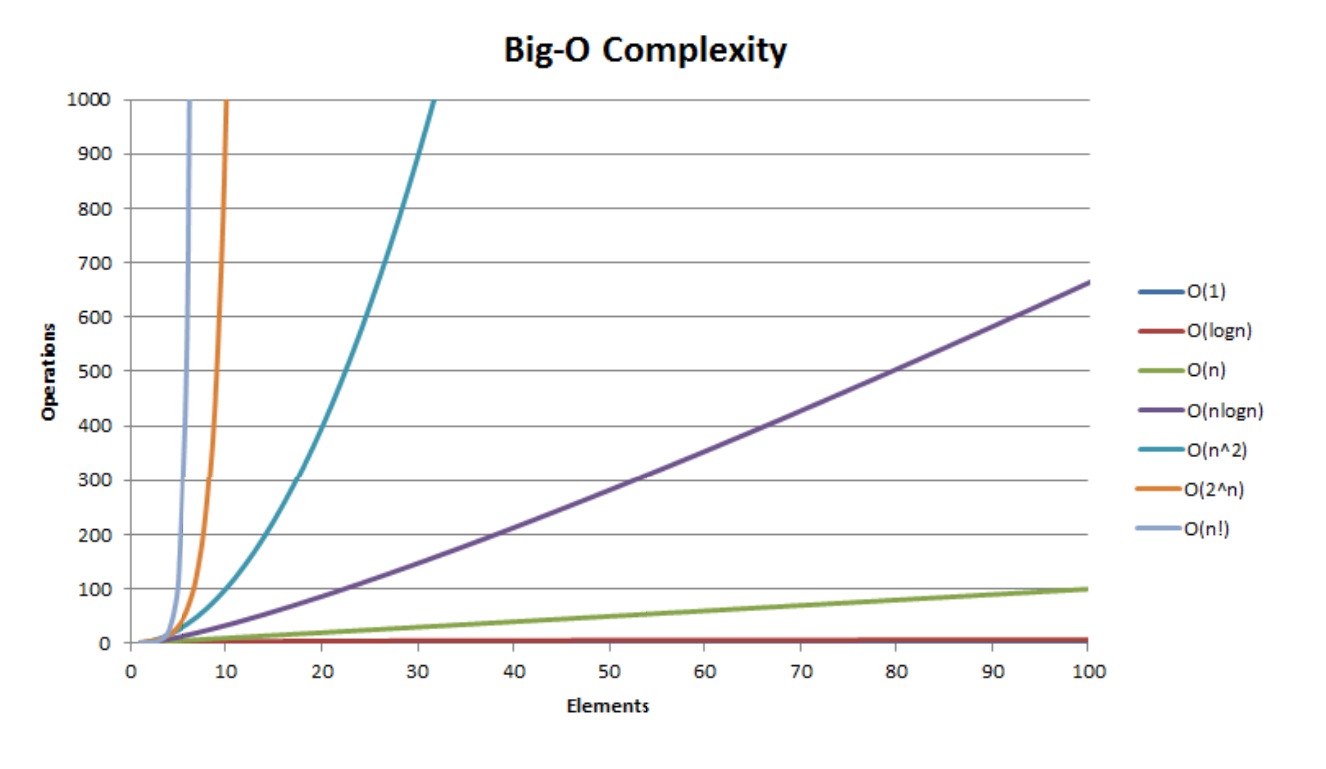
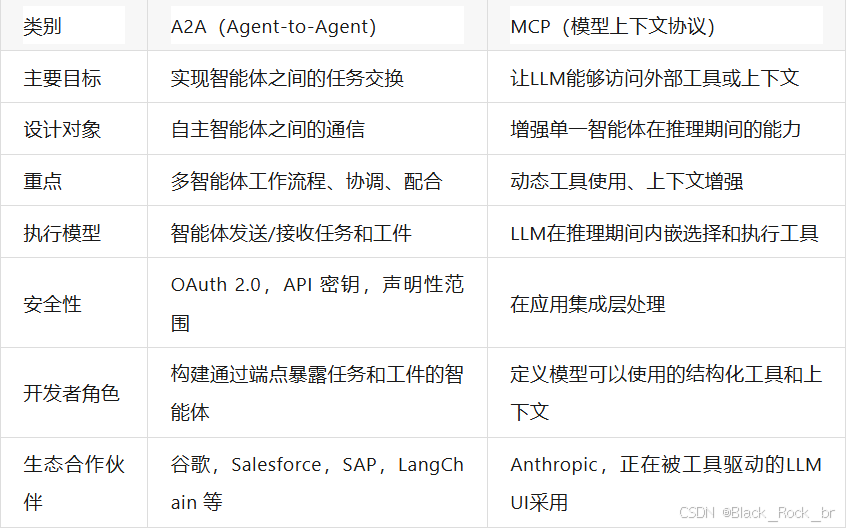
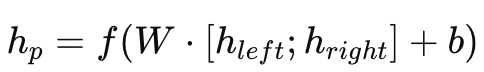Prometheus 是一个开源的监控与告警系统,专为动态的云原生环境(如 Kubernetes)设计。其架构基于主动拉取(Pull)模型,支持多维数据模型和灵活的查询语言(PromQL)。以下是 Prometheus 的核心架构组件及其工作原理的详细说明:
1. Prometheus 核心架构图
+-------------------+ +------------+ +--------------+
| 监控目标 | | Prometheus | | Alertmanager |
| (Exporters/Apps) |<----| Server |---->| |
+-------------------+ +-----+------+ +-------^------+
| |
| 存储/查询 | 告警通知
v |
+-------------+ +-------v------+
| 可视化工具 | | 通知渠道 |
| (Grafana) | | (Email/Slack)|
+-------------+ +--------------+
2. 核心组件与功能
(1) Prometheus Server
- 功能:数据抓取、存储、处理查询和触发告警。
- 子模块:
- Retrieval(抓取模块):根据配置定期从监控目标(如 Exporters、应用程序)拉取指标数据。
- Time Series Database(TSDB):高效存储时间序列数据(默认本地存储,支持远程写入)。
- HTTP Server:提供 API 和 Web UI 用于查询(PromQL)和管理。
(2) 监控目标(Targets)
- Exporters:将第三方系统(如 Node、MySQL、Redis)的指标转换为 Prometheus 可读格式。
- 示例:
Node Exporter(主机监控)、cAdvisor(容器监控)。
- 示例:
- Instrumented Applications:应用程序直接通过客户端库(如 Go、Java、Python)暴露指标。
- 暴露端点:
http://<app>:<port>/metrics。
- 暴露端点:
- Pushgateway:处理短暂任务(如批处理作业)的指标推送。
- 任务将指标推送到 Pushgateway,Prometheus 再从 Pushgateway 拉取。
(3) Alertmanager
- 功能:接收 Prometheus Server 生成的告警,进行去重、分组、静默,并通过渠道(邮件、Slack 等)通知。
- 流程:
- Prometheus Server 根据告警规则(
alerting_rules.yml)触发告警。 - 告警发送至 Alertmanager。
- Alertmanager 按配置的路由策略分发告警。
- Prometheus Server 根据告警规则(
(4) 服务发现(Service Discovery)
- 作用:动态发现监控目标(如 Kubernetes Pods、云服务实例)。
- 支持的发现机制:
- Kubernetes:自动发现集群内的 Pods、Services、Endpoints。
- Consul/Etcd:基于服务注册中心发现目标。
- 文件发现:通过 JSON/YAML 文件静态配置目标列表。
- 云服务商:AWS EC2、Azure VM 等。
(5) 数据存储与远程集成
- 本地存储:默认使用 TSDB 存储数据,适合单节点中小规模场景。
- 远程存储:通过
remote_write和remote_read集成外部存储(如 Thanos、Cortex、InfluxDB),解决长期存储和高可用问题。
3. 工作流程
- 配置:定义抓取目标(
scrape_configs)和告警规则(alerting_rules.yml)。 - 服务发现:动态识别需要监控的端点(如 Kubernetes Pod IP)。
- 数据抓取:Prometheus Server 定期(如 15s)从目标拉取指标(HTTP 请求
/metrics)。 - 存储:抓取的指标存储于本地 TSDB,支持压缩和分块管理。
- 查询与告警:
- 用户通过 PromQL 查询数据(如
rate(http_requests_total[5m]))。 - 触发告警规则时,发送告警至 Alertmanager。
- 用户通过 PromQL 查询数据(如
- 告警处理:Alertmanager 过滤、分组并通知用户。
- 可视化:通过 Grafana 或 Prometheus Web UI 展示监控仪表盘。
4. 关键特性
(1) 拉取模型(Pull-based)
- 优势:集中控制抓取频率,避免客户端推送压力。
- 适用场景:可控的网络环境,如内部服务监控。
(2) 多维数据模型
- 数据结构:每个时间序列由
指标名称+标签组唯一标识。- 示例:
http_requests_total{method="POST", path="/api", status="200"}。
- 示例:
- 灵活性:通过标签过滤、聚合数据(如按
method统计请求量)。
(3) PromQL 查询语言
- 功能:支持实时聚合、切片、预测和连接操作。
- 示例查询:
sum(rate(container_cpu_usage_seconds_total[5m])) by (pod)。
- 示例查询:
(4) 动态服务发现
- 自动化:适应云环境中 IP 频繁变化的场景(如 Kubernetes Pod 重启)。
5. 典型应用场景
- Kubernetes 集群监控:结合
kube-state-metrics和cAdvisor监控容器资源使用。 - 微服务性能分析:通过客户端库(如 Spring Boot Actuator)暴露应用指标。
- 主机与中间件监控:使用
Node Exporter、MySQL Exporter监控基础设施。 - 批处理作业监控:通过
Pushgateway收集短期任务的运行状态。
6. 局限性及解决方案
| 局限性 | 解决方案 |
|---|---|
| 单点存储瓶颈 | 使用 Thanos/Cortex 实现远程存储和联邦集群 |
| 仅支持拉取模型 | 结合 Pushgateway 处理短暂任务 |
| 无长期数据保留 | 集成远程存储(如 InfluxDB) |
| 告警依赖静态配置 | 结合服务发现动态更新告警目标 |
总结
Prometheus 的架构以 高效拉取模型、多维数据 和 动态服务发现 为核心,结合 Alertmanager 和可视化工具,为云原生应用提供了强大的监控能力。尽管存在单点存储和长期数据管理的挑战,但通过与生态系统工具(如 Thanos、Grafana)集成,可扩展为生产级监控解决方案。
![[OS] mmap | fd是什么 | inode机制 | vfs封装](https://i-blog.csdnimg.cn/img_convert/8cf61529d3a6d4a5fd4cf662d891dd48.png)