文章目录
- 省流结论
- 机器配置
- 不同量化模型占用显存
- 1. 创建虚拟环境
- 2. 创建测试jsonl文件
- 3. 新建测试脚本
- 3. 默认加载方式,单卡运行模型
- 3.1 7b模型输出213 tok/s
- 3.1 32b模型输出81 tok/s
- 3.1 70b模型输出43tok/s
- 4. 使用负载均衡,多卡运行
- 4.1 7b模型输出217tok/s
- 4.2 32b模型输出83 tok/s
- 4.3 70b模型输出45 tok/s
- 5. 结论
由于ollama默认调用模型,模型实例会运行在一张卡上,如果有几张显卡,模型只会永远跑在第一张卡上,除非显存超出,然后才会将模型跑在第二张卡,这造成了资源很大的浪费。网上通过修改ollama.service的配置,如下:
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3"
Environment="OLLAMA_SCHED_SPREAD=1"
Environment="OLLAMA_KEEP_ALIVE=-1"
修改之后可以负载均衡,显存平均分配在集群中的每张卡上,但是我不太了解这种方式是否会提升模型吞吐量?和默认的调用单卡实例有啥区别呢?
因此我决定使用EvalScope进行模型性能测试,从而查看这两种方式区别有多大。
EvalScope简介:
EvalScope是魔搭社区官方推出的模型评测与性能基准测试框架,内置多个常用测试基准和评测指标,如MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH和HumanEval等;支持多种类型的模型评测,包括LLM、多模态LLM、embedding模型和reranker模型。EvalScope还适用于多种评测场景,如端到端RAG评测、竞技场模式和模型推理性能压测等。此外,通过ms-swift训练框架的无缝集成,可一键发起评测,实现了模型训练到评测的全链路支持。
省流结论
我修改ollama的配置环境,使用负载均衡,发现输出tok并没有增加很多,性能几乎没有提升。我看网上使用负载均衡会提升吞吐量,经过我的测试,发现配置修改前后性能差不多。
但是负载均衡毕竟可以使用多GPU,感觉也挺不错。
机器配置
使用显卡如下,4张L20。
懒得查资料,问了gpt 4o,抛开显存不谈,L20的算力性能约等于哪个消费级显卡?
它说:L20 性能 ≈ RTX 4080。介于4080和4090之间。
| 参数 | NVIDIA L20 | RTX 4080 | RTX 4090 |
|---|---|---|---|
| 架构 | Ada Lovelace | Ada Lovelace | Ada Lovelace |
| CUDA 核心数 | 11,776 | 9,728 | 16,384 |
| Tensor 核心数 | 368 | 304 | 512 |
| 基础频率 | 1,440 MHz | 2,205 MHz | 2,235 MHz |
| Boost 频率 | 2,520 MHz | 2,505 MHz | 2,520 MHz |
| FP16 Tensor Core | 119.5 TFLOPS | 97.4 TFLOPS | 165.2 TFLOPS |
| FP32 算力 | 59.8 TFLOPS | 49.1 TFLOPS | 82.6 TFLOPS |
| TDP 功耗 | 275W | 320W | 450W |
不同量化模型占用显存
deepseek-r1量化的几个模型显存占用:
deepseek-r1:7b大概需要5.5G的显存
deepseek-r1:32b大概需要21.2G的显存
deepseek-r1:70b大概需要43G的显存
我们使用evalscope的perf进行模型性能压力测试
evalscope的perf主要用于模型性能压测(吞吐量、速度)
🔍 作用:
用于测试你部署的模型在高并发或大输入下的响应能力和性能,比如:每秒处理多少条请求?并发处理能力怎么样?最慢 / 最快 / 平均响应时间是多少?
📊 输出内容:
吞吐率(tokens/s)平均响应延迟(ms)流式输出响应时间等
1. 创建虚拟环境
首先使用conda新建虚拟环境,之后安装依赖:
pip install evalscope # 安装 Native backend (默认)
# 额外选项
pip install 'evalscope[opencompass]' # 安装 OpenCompass backend
pip install 'evalscope[vlmeval]' # 安装 VLMEvalKit backend
pip install 'evalscope[rag]' # 安装 RAGEval backend
pip install 'evalscope[perf]' # 安装 模型压测模块 依赖
pip install 'evalscope[app]' # 安装 可视化 相关依赖
pip install 'evalscope[all]' # 安装所有 backends (Native, OpenCompass, VLMEvalKit, RAGEval)
如果个别的包由于无法连接github下载导致安装错误,可以手动下载依赖,手动安装。
2. 创建测试jsonl文件
我们需要写一个简单测试的jsonl文件。
新建open_qa.jsonl文件,我的测试jsonl文件内容如下:
{"question": "什么是深度学习?"}
{"question": "请介绍一下量子纠缠。"}
{"question": "图像恢复是什么?"}
{"question": "解释一下牛顿第三定律。"}
{"question": "《红楼梦》讲述了什么内容?"}
{"question": "地球为什么有四季变化?"}
{"question": "黑洞是如何形成的?"}
{"question": "什么是注意力机制(Attention Mechanism)?"}
{"question": "二战的主要原因有哪些?"}
{"question": "如何提高自然语言处理模型的泛化能力?"}
{"question": "什么是摩尔定律?它现在还有效吗?"}
{"question": "请简述贝叶斯定理及其应用。"}
{"question": "中国的四大发明是什么?"}
{"question": "什么是元宇宙(Metaverse)?"}
{"question": "请解释区块链的基本原理。"}
{"question": "DNA 是什么?它的结构特点是什么?"}
{"question": "介绍一下古希腊哲学的主要流派。"}
{"question": "什么是强化学习?它与监督学习有何区别?"}
{"question": "太阳内部发生了什么物理过程?"}
{"question": "人工智能会取代人类的工作吗?"}
{"question": "解释电磁感应现象及其应用。"}
{"question": "什么是熵?它在信息论中代表什么?"}
{"question": "5G 网络有哪些核心技术?"}
{"question": "请说明气候变化的主要原因。"}
{"question": "什么是图神经网络(GNN)?"}
3. 新建测试脚本
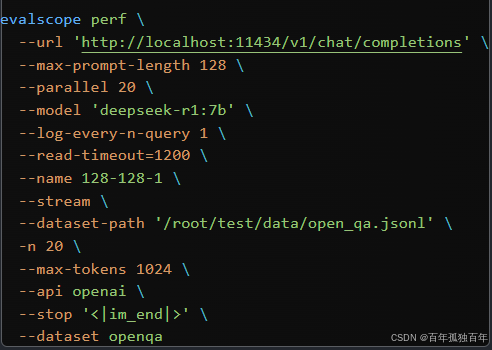
新建test_perf_deepseek.sh文件,内容如下,测试的是7b模型:
如果测试其他模型,修改–model的参数
修改–dataset-path的路径,改为你存放
open_qa.jsonl的路径
evalscope perf \
--url 'http://localhost:11434/v1/chat/completions' \
--max-prompt-length 128 \
--parallel 20 \
--model 'deepseek-r1:7b' \
--log-every-n-query 1 \
--read-timeout=1200 \
--name 128-128-1 \
--stream \
--dataset-path '/root/test/data/open_qa.jsonl' \
-n 20 \
--max-tokens 1024 \
--api openai \
--stop '<|im_end|>' \
--dataset openqa
参数说明:
--url: 请求的URL地址,例如:http://localhost:11434/v1/chat/completions,这是本地部署的模型API接口。--max-prompt-length: 单个请求中prompt的最大长度限制,这里是128个token。--parallel: 并行请求的任务数量,这里是20,意味着同时发起20个请求进行性能测试。--model: 使用的模型名称,这里是deepseek-r1:7b。--log-every-n-query: 每隔多少个请求打印一次日志,这里是每1个请求都打印一次。--read-timeout: 单个请求的最长等待时间(秒),超过这个时间会认为请求超时。这里设置为1200秒(20分钟),适合长时间响应的情况。--name: 当前测试的名称/标识,用于记录结果或日志标记。这里为128-128-1,可能是自定义的配置标识(如max_prompt/max_tokens/batch_size之类)。--stream: 是否启用流式处理。开启后,将使用流式响应模式接收生成结果(比如OpenAI的stream=True),适合处理大输出或加速响应体验。--dataset-path: 指定本地数据集的路径,这里是/root/test/data/open_qa.jsonl,通常为JSON Lines格式的数据集。-n: 请求总数,这里是20,表示总共发送20个请求进行测试。--max-tokens: 模型在生成时最多生成的token数量,这里为1024。--api: 使用的API协议或服务类型,这里是openai风格的API(即参数格式符合OpenAI Chat API标准)。--stop: 指定生成的停止标记,这里是<|im_end|>,用于控制生成结果在遇到该标记时停止。--dataset: 使用的数据集名称或类型标识,这里是openqa,常用于区分测试任务或用于内部适配。
3. 默认加载方式,单卡运行模型
测试命令如下,测试的模型:
测试不同的模型,修改这个–model参数
测试7b:deepseek-r1:7b
测试32b:deepseek-r1:32b
测试70b:deepseek-r1:70b
3.1 7b模型输出213 tok/s
显存占用如下,由于我先启动了32b和70b模型,最后启动了7b模型,可以看到前两张卡运行了两个模型。
第三张卡运行的是7b模型。
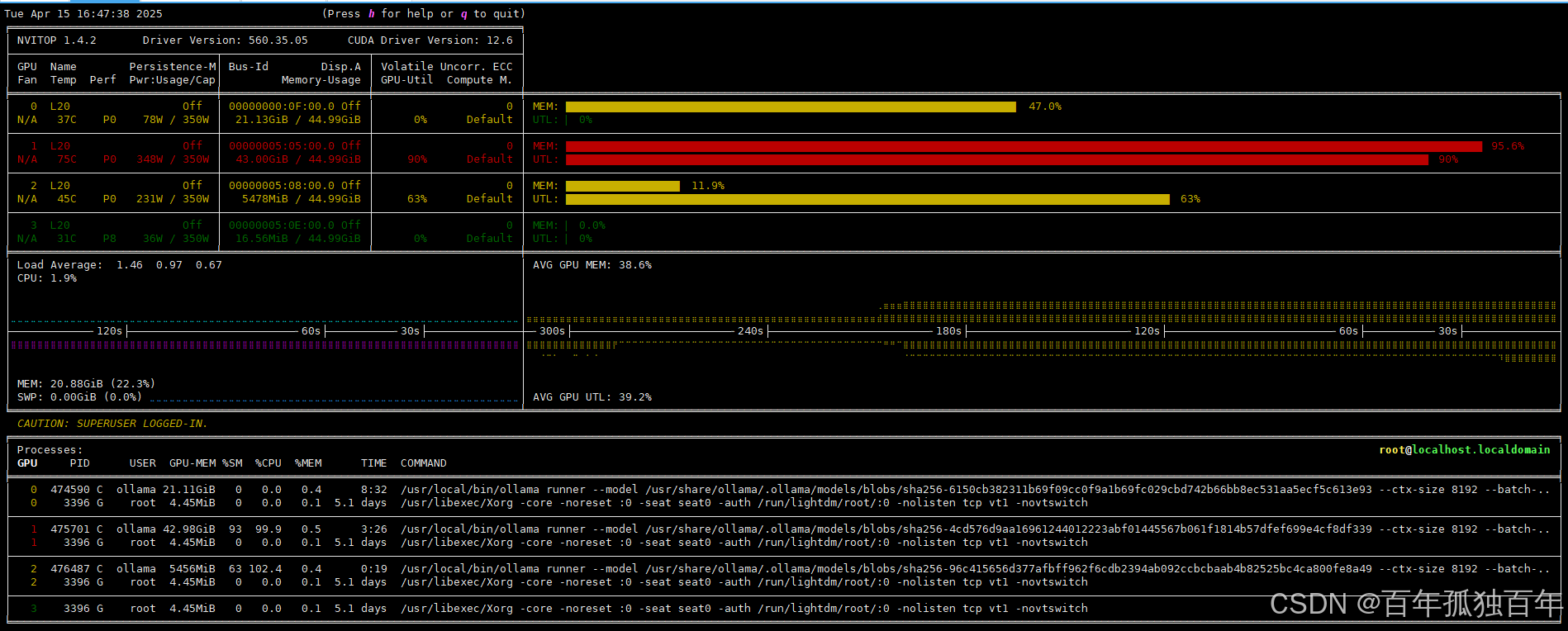
不使用负载均衡,使用ollama默认的调用方式,使用单张卡进行推理,deepseek-r1:7b测试结果如下,可以看到每秒输出的token大概有213。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 69.5776 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 213.79 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 216.7363 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.2874 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 39.6962 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 26.5699 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.0776 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 743.75 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0178 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 739.25 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_091602/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 09:17:12,411 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1328 | 0.0173 | 13.8207 | 7 | 490 | 9.5719 |
| 25% | 12.052 | 0.0177 | 25.8903 | 8 | 664 | 14.3005 |
| 50% | 27.0828 | 0.0179 | 42.0287 | 10 | 772 | 18.1264 |
| 66% | 39.8597 | 0.018 | 53.5647 | 11 | 897 | 29.8181 |
| 75% | 44.5788 | 0.018 | 62.9357 | 12 | 1024 | 33.9352 |
| 80% | 45.7624 | 0.0181 | 64.1272 | 14 | 1024 | 56.3658 |
| 90% | 54.2245 | 0.0182 | 65.4349 | 14 | 1024 | 56.5702 |
| 95% | 62.9888 | 0.0183 | 69.5807 | 14 | 1024 | 56.6541 |
| 98% | 62.9888 | 0.0184 | 69.5807 | 14 | 1024 | 56.6541 |
| 99% | 62.9888 | 0.0188 | 69.5807 | 14 | 1024 | 56.6541 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
3.1 32b模型输出81 tok/s
显存占用,可以看到就单卡运行
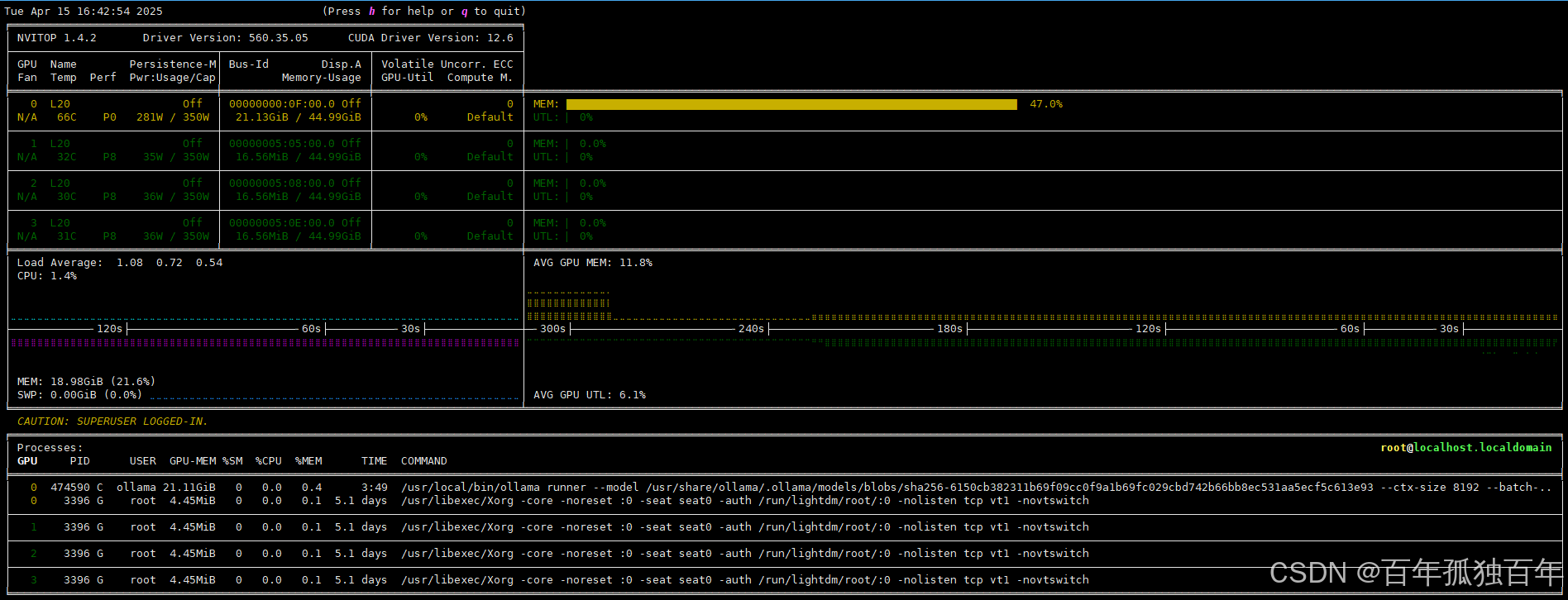
测试的deepseek-r1:32b模型,每秒输出token有81。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 215.884 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 81.5021 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 82.4517 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0926 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 122.059 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 81.843 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1421 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 879.75 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0461 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 872.05 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_092445/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 09:28:26,988 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1992 | 0.0432 | 41.9602 | 7 | 664 | 4.52 |
| 25% | 40.2375 | 0.0454 | 81.6553 | 8 | 797 | 4.7959 |
| 50% | 87.3562 | 0.0465 | 135.0661 | 10 | 892 | 7.5815 |
| 66% | 113.3376 | 0.0466 | 153.0112 | 11 | 1020 | 10.1626 |
| 75% | 137.7377 | 0.0467 | 182.9889 | 12 | 1024 | 11.4105 |
| 80% | 143.7239 | 0.0467 | 184.4415 | 14 | 1024 | 22.1322 |
| 90% | 168.787 | 0.0468 | 212.6837 | 14 | 1024 | 22.247 |
| 95% | 183.1294 | 0.0469 | 215.8822 | 14 | 1024 | 22.2935 |
| 98% | 183.1294 | 0.0471 | 215.8822 | 14 | 1024 | 22.2935 |
| 99% | 183.1294 | 0.0488 | 215.8822 | 14 | 1024 | 22.2935 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
3.1 70b模型输出43tok/s
显存占用如下,可以看到当运行32b模型时,由于再唤醒70b模型需要占用42.9G的显存,单卡48G的显存显然不够用的,因此会调用下一张卡。
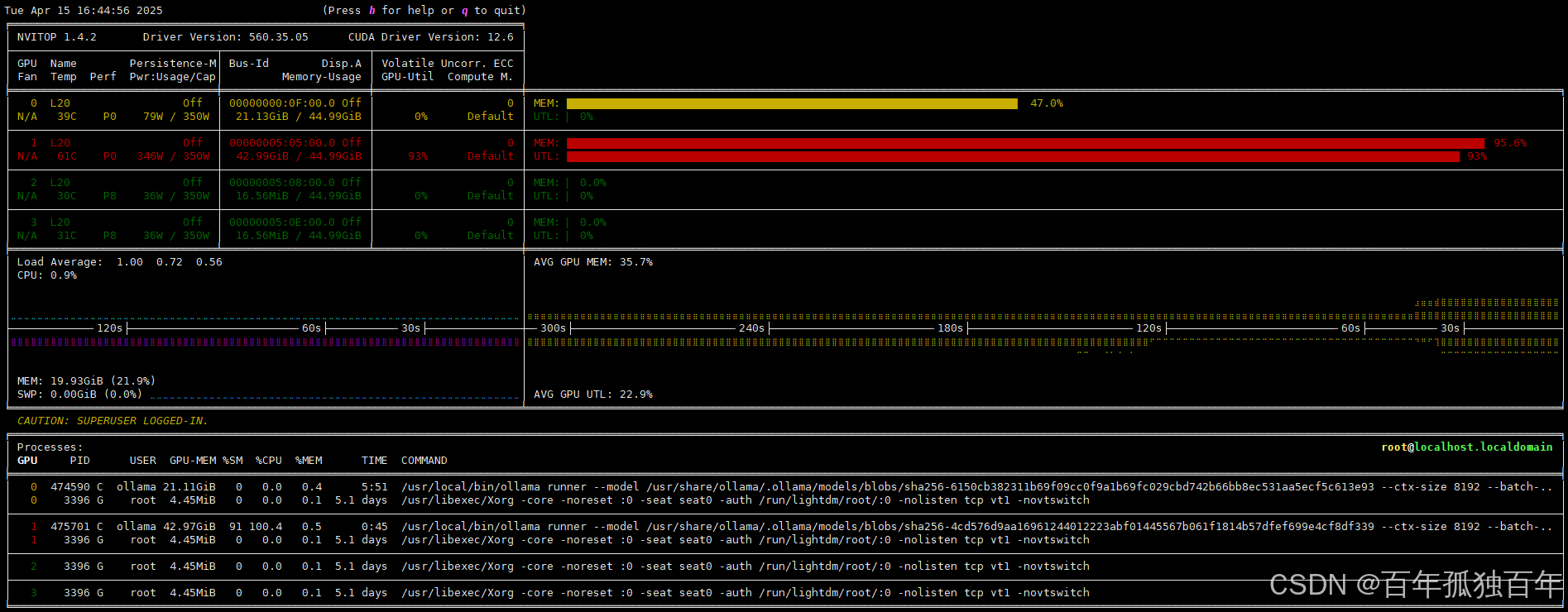
测试的deepseek-r1:70b模型,每秒输出token只有43。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 376.5257 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 43.2029 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 43.8934 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0531 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 206.8567 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 139.3129 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.4626 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 13.0 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 813.35 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0854 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 791.3 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_111007/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 11:16:35,963 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.358 | 0.0788 | 83.4586 | 10 | 476 | 2.2468 |
| 25% | 83.7387 | 0.0813 | 124.8847 | 12 | 695 | 2.7196 |
| 50% | 126.7937 | 0.0847 | 212.0645 | 14 | 1024 | 3.8596 |
| 66% | 211.6319 | 0.085 | 269.4886 | 14 | 1024 | 4.8287 |
| 75% | 214.0528 | 0.0853 | 298.9557 | 14 | 1024 | 5.9358 |
| 80% | 216.7131 | 0.0854 | 301.3438 | 15 | 1024 | 12.2285 |
| 90% | 276.0923 | 0.0858 | 347.9994 | 16 | 1024 | 12.2702 |
| 95% | 299.2182 | 0.0862 | 376.5222 | 18 | 1024 | 12.2703 |
| 98% | 299.2182 | 0.1646 | 376.5222 | 18 | 1024 | 12.2703 |
| 99% | 299.2182 | 0.17 | 376.5222 | 18 | 1024 | 12.2703 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
4. 使用负载均衡,多卡运行
4.1 7b模型输出217tok/s
测试的deepseek-r1:7b模型,每秒输出token变成217。
奇怪,使用负载均衡之后,吐出的tok数量并没有增加很多啊,甚至和单张卡输出tok几乎差不多,我看网上说会增加的。
这是为什么?我也不知道。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 68.8518 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 217.409 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 220.3864 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.2905 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 40.9902 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 27.764 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1033 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 748.45 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0178 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 742.25 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_145249/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 14:54:01,950 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1713 | 0.0172 | 13.0051 | 7 | 579 | 10.83 |
| 25% | 12.5773 | 0.0177 | 27.2219 | 8 | 709 | 15.7196 |
| 50% | 29.3214 | 0.0179 | 45.6927 | 10 | 755 | 19.3558 |
| 66% | 42.2444 | 0.018 | 52.9042 | 11 | 897 | 31.1884 |
| 75% | 46.6769 | 0.018 | 64.2114 | 12 | 1012 | 33.106 |
| 80% | 52.7525 | 0.0181 | 65.1415 | 14 | 1024 | 57.1314 |
| 90% | 54.2956 | 0.0182 | 66.5091 | 14 | 1024 | 57.1984 |
| 95% | 64.2614 | 0.0183 | 68.8467 | 14 | 1024 | 57.4499 |
| 98% | 64.2614 | 0.0185 | 68.8467 | 14 | 1024 | 57.4499 |
| 99% | 64.2614 | 0.0195 | 68.8467 | 14 | 1024 | 57.4499 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
4.2 32b模型输出83 tok/s
测试的deepseek-r1:32b模型,每秒输出token有83左右,单卡输出为83,可以说几乎没区别。
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 210.3824 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 83.3245 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 84.2989 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0951 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 116.6855 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 76.7932 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.1313 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 10.25 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 876.5 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0458 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 870.55 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_162240/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 16:26:11,509 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.1945 | 0.0429 | 45.1571 | 7 | 645 | 4.9526 |
| 25% | 36.8916 | 0.0451 | 73.0001 | 8 | 807 | 5.6556 |
| 50% | 81.7751 | 0.0463 | 119.9128 | 10 | 958 | 8.1476 |
| 66% | 117.7298 | 0.0464 | 159.4871 | 11 | 1007 | 10.6849 |
| 75% | 129.4489 | 0.0464 | 174.0512 | 12 | 1024 | 12.8373 |
| 80% | 134.1872 | 0.0464 | 176.8538 | 14 | 1024 | 22.1902 |
| 90% | 166.9573 | 0.0465 | 208.7023 | 14 | 1024 | 22.3439 |
| 95% | 174.1963 | 0.0466 | 210.3796 | 14 | 1024 | 22.5919 |
| 98% | 174.1963 | 0.0467 | 210.3796 | 14 | 1024 | 22.5919 |
| 99% | 174.1963 | 0.0469 | 210.3796 | 14 | 1024 | 22.5919 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
4.3 70b模型输出45 tok/s
测试的deepseek-r1:70b模型,每秒输出token变成45左右。和单卡的43差不多,似乎性能也没有增加。
为什么?不清楚。
占用显存如下所示,可以看到不像之前占用一张卡,如果显存超过了,启动下一张卡。使用负载均衡可以将显存平均分配到每一张卡上,需要每张卡都出一点力。
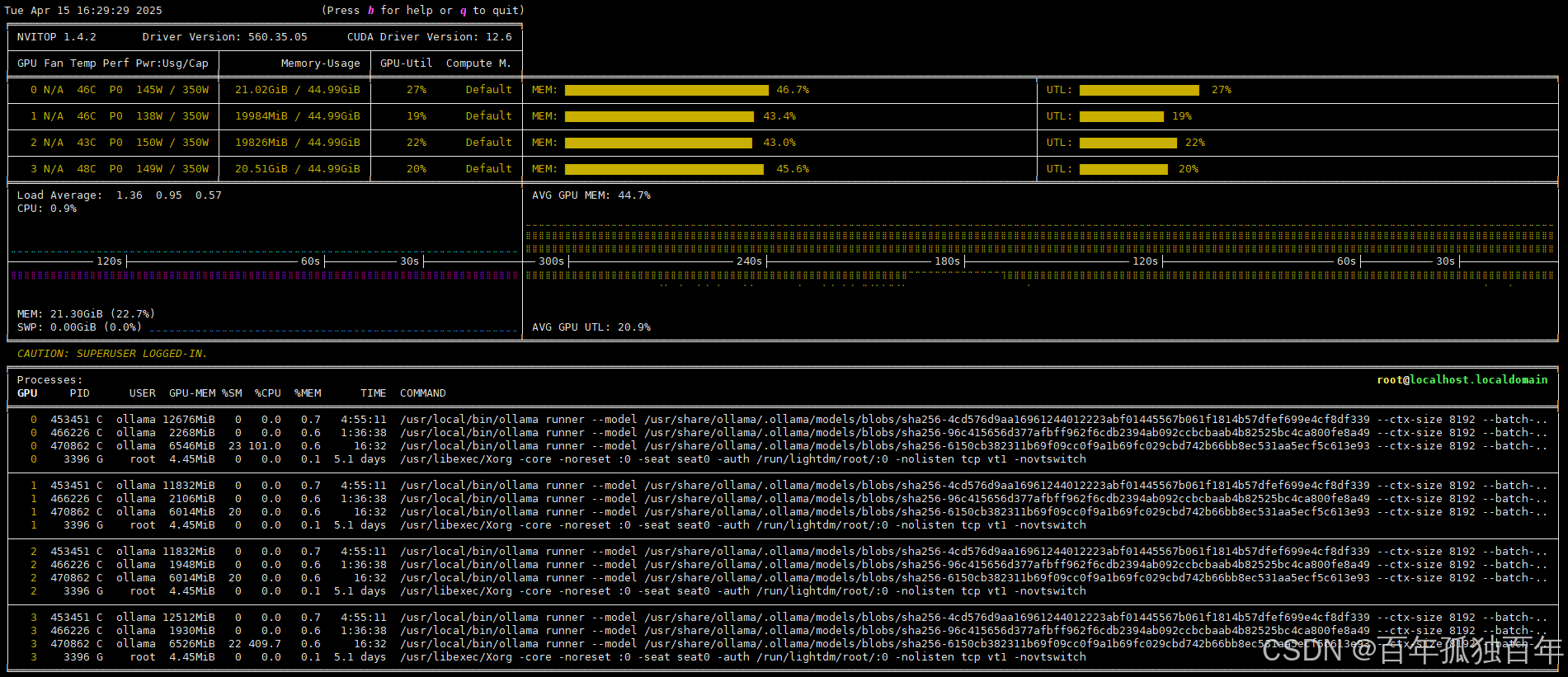
性能测试如下:
Benchmarking summary:
+-----------------------------------+-----------------------------------------------------+
| Key | Value |
+===================================+=====================================================+
| Time taken for tests (s) | 350.0327 |
+-----------------------------------+-----------------------------------------------------+
| Number of concurrency | 20 |
+-----------------------------------+-----------------------------------------------------+
| Total requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Succeed requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-----------------------------------------------------+
| Output token throughput (tok/s) | 45.4586 |
+-----------------------------------+-----------------------------------------------------+
| Total token throughput (tok/s) | 46.2014 |
+-----------------------------------+-----------------------------------------------------+
| Request throughput (req/s) | 0.0571 |
+-----------------------------------+-----------------------------------------------------+
| Average latency (s) | 185.3367 |
+-----------------------------------+-----------------------------------------------------+
| Average time to first token (s) | 120.6031 |
+-----------------------------------+-----------------------------------------------------+
| Average time per output token (s) | 0.2389 |
+-----------------------------------+-----------------------------------------------------+
| Average input tokens per request | 13.0 |
+-----------------------------------+-----------------------------------------------------+
| Average output tokens per request | 795.6 |
+-----------------------------------+-----------------------------------------------------+
| Average package latency (s) | 0.0837 |
+-----------------------------------+-----------------------------------------------------+
| Average package per request | 772.95 |
+-----------------------------------+-----------------------------------------------------+
| Expected number of requests | 20 |
+-----------------------------------+-----------------------------------------------------+
| Result DB path | outputs/20250415_115239/128-128-1/benchmark_data.db |
+-----------------------------------+-----------------------------------------------------+
2025-04-15 11:58:30,043 - evalscope - INFO -
Percentile results:
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | ITL (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
| 10% | 0.3932 | 0.08 | 55.6919 | 10 | 482 | 2.5115 |
| 25% | 51.2654 | 0.0819 | 95.2744 | 12 | 617 | 3.0284 |
| 50% | 135.0597 | 0.0819 | 172.4987 | 14 | 1024 | 4.5089 |
| 66% | 170.2825 | 0.082 | 254.2084 | 14 | 1024 | 6.0887 |
| 75% | 214.4321 | 0.082 | 270.23 | 14 | 1024 | 11.3 |
| 80% | 252.6452 | 0.082 | 297.0692 | 15 | 1024 | 11.5983 |
| 90% | 256.9616 | 0.0822 | 338.1322 | 16 | 1024 | 12.1382 |
| 95% | 270.4241 | 0.0824 | 350.0368 | 18 | 1024 | 12.1909 |
| 98% | 270.4241 | 0.1634 | 350.0368 | 18 | 1024 | 12.1909 |
| 99% | 270.4241 | 0.1639 | 350.0368 | 18 | 1024 | 12.1909 |
+------------+----------+---------+-------------+--------------+---------------+----------------------+
5. 结论
使用负载均衡之后,7b模型吞吐量从213变为217,32b模型从81到83,70b模型从43到45。
可以说几乎没有提升,因为每次运行,结果会有上下浮动,所以说差不多。

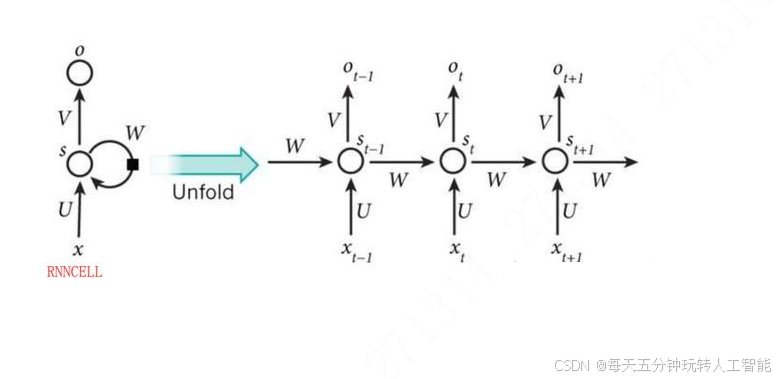
![[连载]Transformer架构详解](https://i-blog.csdnimg.cn/direct/5c0929e48f7f41a498455d295488e37a.png)