目录
- 打造AI应用基础设施:Milvus向量数据库部署与运维
- 1. Milvus介绍
- 1.1 什么是向量数据库?
- 1.2 Milvus主要特点
- 2. Milvus部署方案对比
- 2.1 Milvus Lite
- 2.2 Milvus Standalone
- 2.3 Milvus Distributed
- 2.4 部署方案对比表
- 3. Milvus部署操作命令实战
- 3.1 Milvus Lite部署
- 3.2 Milvus Standalone Docker部署
- 3.3 Milvus Distributed Kubernetes部署
- 3.3.1 使用Helm安装Milvus Operator
- 3.3.2 使用kubectl安装Milvus Operator
- 3.3.3 部署Milvus集群
- 3.3.4 检查Milvus集群状态
- 3.3.5 端口转发以便本地访问
- 3.3.6 卸载Milvus集群
- 4. Milvus部署后的使用
- 4.1 基本概念
- 4.1.1 集合(Collection)
- 4.1.2 模式(Schema)和字段(Fields)
- 4.1.3 主键(Primary Key)和自动ID(AutoId)
- 4.2 Python代码示例
- 4.3 基本操作流程
- 4.4 高级功能
- 5. Milvus运维方案
- 5.1 Prometheus监控
- 5.1.1 部署Prometheus监控服务
- 5.1.2 为Milvus启用ServiceMonitor
- 5.2 可视化和管理工具
- 5.3 备份和恢复
- 5.4 集群扩容
- 5.5 升级Milvus版本
- 6. 总结
- 参考资料
打造AI应用基础设施:Milvus向量数据库部署与运维
1. Milvus介绍
Milvus是一款高性能、可扩展的开源向量数据库,专为管理和检索向量数据而设计。它支持从Jupyter Notebook本地演示到处理数十亿向量的大规模Kubernetes集群的各种规模用例。
1.1 什么是向量数据库?
向量数据库是专门设计用于存储、管理和检索向量嵌入(embeddings)的数据库系统。在AI和机器学习领域,向量嵌入是将文本、图像、音频等转换为数值向量的过程,这些向量可以用于相似性搜索。Milvus可以高效地执行相似性搜索操作,是AI应用(如语义搜索、推荐系统、图像识别等)的理想选择。
1.2 Milvus主要特点
- 高性能:支持数十亿规模的向量管理和高效的相似性搜索
- 可扩展:提供从轻量级到分布式集群的多种部署方案
- 多模态支持:支持多种数据类型,包括稠密向量、稀疏向量、二进制向量等
- 高级搜索能力:支持ANN搜索、元数据过滤、范围搜索、混合搜索等
- 灵活部署:提供多种部署模式,适应不同规模和场景的需求
- 开源生态:拥有丰富的工具和集成选项,如WebUI、备份工具等
2. Milvus部署方案对比
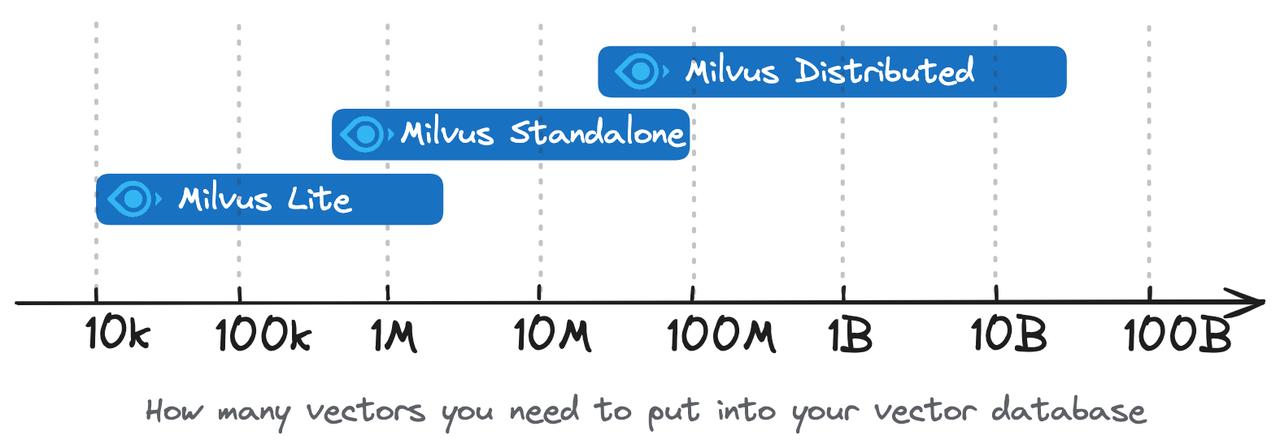
目前,Milvus提供了三种主要的部署选项:Milvus Lite、Milvus Standalone和Milvus Distributed。
2.1 Milvus Lite
Milvus Lite是一个Python库,可以直接导入到应用程序中。作为Milvus的轻量级版本,它非常适合在Jupyter Notebook中快速原型设计或在资源有限的智能设备上运行。
特点:
- 轻量级,仅需通过pip安装
- 适用于小型数据集(建议不超过几百万向量)
- 简单易用,适合快速原型设计和学习
- 与其他Milvus部署模式共享相同的API
适用场景:
- 快速原型开发(RAG演示、AI聊天机器人、多模态搜索等)
- Jupyter Notebook或Google Colab环境
- 边缘设备上的本地搜索
- 处理私密或敏感数据
2.2 Milvus Standalone
Milvus Standalone是单机服务器部署。所有组件都打包到一个Docker镜像中,便于部署。
特点:
- 单一Docker镜像,部署简便
- 适合中等规模数据集(可扩展至1亿向量)
- 通过主从复制支持高可用性
- 比集群部署需要更少的DevOps工作
适用场景:
- 早期生产环境
- 产品市场适应性测试阶段
- 灵活性比可扩展性更重要的场景
- 中等规模的生产部署
2.3 Milvus Distributed
Milvus Distributed可以部署在Kubernetes集群上,具有云原生架构,摄取负载和搜索查询由独立节点单独处理,允许关键组件冗余。
特点:
- 高可扩展性和高可用性
- 灵活定制每个组件的资源分配
- 适合大规模数据集(从1亿到数百亿向量)
- 企业级生产环境的首选
适用场景:
- 大规模生产部署
- 数据规模超出单台服务器容量的业务
- 需要定制化负载处理的环境(如高读取、低写入或高写入、低读取)
2.4 部署方案对比表
| 特性 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| 部署方式 | Python库 | Docker容器 | Kubernetes集群 |
| 适用数据规模 | 数百万向量 | 高达1亿向量 | 1亿至数百亿向量 |
| SDK支持 | Python、gRPC | Python、Go、Java、Node.js、C#、RESTful | Python、Java、Go、Node.js、C#、RESTful |
| 资源要求 | 最低 | 中等 | 高 |
| 运维复杂度 | 简单 | 中等 | 复杂 |
| 一致性级别 | 强一致性 | 强一致性、有界陈旧、会话一致性、最终一致性 | 强一致性、有界陈旧、会话一致性、最终一致性 |
| 高级数据管理 | 不支持 | 访问控制、分区、分区键 | 访问控制、分区、分区键、物理资源分组 |
3. Milvus部署操作命令实战
3.1 Milvus Lite部署
Milvus Lite作为Python库,部署非常简单:
# 安装pymilvus(包含Milvus Lite)
pip install -U pymilvus
# 在Python代码中使用
from pymilvus import MilvusClient
# 使用本地文件初始化Milvus Lite实例
client = MilvusClient("./milvus_demo.db")
3.2 Milvus Standalone Docker部署
Milvus提供了一个安装脚本,可以轻松地将其作为Docker容器安装:
# 下载安装脚本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# 启动Docker容器
bash standalone_embed.sh start
安装后:
- Milvus容器在端口19530上启动
- 一个嵌入式etcd与Milvus一起安装在同一容器中,端口为2379
- 可通过修改当前文件夹中的user.yaml文件来更改默认Milvus配置
- Milvus数据卷映射到当前文件夹中的volumes/milvus目录
停止和删除Milvus:
# 停止Milvus
bash standalone_embed.sh stop
# 删除Milvus数据
bash standalone_embed.sh delete
升级Milvus版本:
# 升级Milvus
bash standalone_embed.sh upgrade
3.3 Milvus Distributed Kubernetes部署
使用Milvus Operator在Kubernetes上部署Milvus集群:
3.3.1 使用Helm安装Milvus Operator
helm install milvus-operator \
-n milvus-operator --create-namespace \
--wait --wait-for-jobs \
https://github.com/zilliztech/milvus-operator/releases/download/v1.2.0/milvus-operator-1.2.0.tgz
3.3.2 使用kubectl安装Milvus Operator
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/deploy/manifests/deployment.yaml
3.3.3 部署Milvus集群
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/config/samples/milvus_cluster_default.yaml
3.3.4 检查Milvus集群状态
kubectl get milvus my-release -o yaml
3.3.5 端口转发以便本地访问
# 转发Milvus服务端口
kubectl port-forward service/my-release-milvus 27017:19530
# 转发WebUI端口
kubectl port-forward service/my-release-milvus 27018:9091
3.3.6 卸载Milvus集群
kubectl delete milvus my-release
4. Milvus部署后的使用
4.1 基本概念
4.1.1 集合(Collection)
集合是Milvus中的基本数据组织单位,类似于关系数据库中的表。集合是具有固定列和可变行的二维表。每列代表一个字段,每行代表一个实体。
4.1.2 模式(Schema)和字段(Fields)
模式定义了集合中字段的属性(如数据类型、向量维度等)。每个字段都有各种约束属性,如数据类型和向量字段的维度。
4.1.3 主键(Primary Key)和自动ID(AutoId)
主键字段用于区分实体,每个值在全局范围内是唯一的。主键字段只接受整数或字符串。如果启用了AutoId,Milvus将在数据插入时自动生成这些值。
4.2 Python代码示例
以下是使用Milvus进行文本搜索的简单演示:
from pymilvus import MilvusClient
import numpy as np
# 连接到Milvus
client = MilvusClient("./milvus_demo.db") # Milvus Lite本地文件
# 或者连接到Milvus服务器
# client = MilvusClient(uri="http://localhost:19530", token="username:password")
# 创建集合
client.create_collection(
collection_name="demo_collection",
dimension=384 # 本例中向量维度为384
)
# 示例文本
docs = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
# 生成示例向量(实际应用中应使用真实的嵌入模型)
vectors = [[ np.random.uniform(-1, 1) for _ in range(384) ] for _ in range(len(docs)) ]
data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ]
# 插入数据
res = client.insert(
collection_name="demo_collection",
data=data
)
# 执行带过滤条件的搜索
res = client.search(
collection_name="demo_collection",
data=[vectors[0]],
filter="subject == 'history'",
limit=2,
output_fields=["text", "subject"],
)
print(res)
# 查询匹配过滤表达式的所有实体
res = client.query(
collection_name="demo_collection",
filter="subject == 'history'",
output_fields=["text", "subject"],
)
print(res)
# 删除数据
res = client.delete(
collection_name="demo_collection",
filter="subject == 'history'",
)
print(res)
4.3 基本操作流程
- 创建集合:定义向量和标量字段的集合模式
- 插入数据:将向量和元数据插入集合
- 创建索引:为向量字段创建索引以加速搜索
- 加载集合:将集合加载到内存中以准备搜索
- 执行搜索/查询:执行相似度搜索或基于标量条件的查询
- 释放集合:不使用时释放内存资源
4.4 高级功能
- 分区(Partition):集合的子集,共享相同的字段集,每个分区包含实体的子集
- 分片(Shard):集合的水平切片,每个分片对应一个数据输入通道
- 别名(Alias):为集合创建别名,便于管理
- 一致性级别:定义跨数据节点和副本的数据一致性级别
5. Milvus运维方案
5.1 Prometheus监控
Milvus支持使用Prometheus进行监控,提供了各组件的指标,可通过http://<component-host>:9091/metrics端点导出。
5.1.1 部署Prometheus监控服务
使用kube-prometheus部署监控服务:
# 克隆kube-prometheus仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus
# 创建监控栈
kubectl apply --server-side -f manifests/setup
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
kubectl apply -f manifests/
# 修补prometheus-k8s clusterrole以获取Milvus指标
kubectl patch clusterrole prometheus-k8s --type=json -p='[{"op": "add", "path": "/rules/-", "value": {"apiGroups": [""], "resources": ["pods", "services", "endpoints"], "verbs": ["get", "watch", "list"]}}]'
# 端口转发Prometheus和Grafana服务
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/prometheus-k8s 9090
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/grafana 3000
5.1.2 为Milvus启用ServiceMonitor
通过Helm参数启用ServiceMonitor:
helm upgrade my-release milvus/milvus --set metrics.serviceMonitor.enabled=true --reuse-values
检查ServiceMonitor资源:
kubectl get servicemonitor
5.2 可视化和管理工具
Milvus提供了多种工具来帮助可视化和管理:
-
Milvus WebUI:通过浏览器访问的内置GUI工具,提供系统可观察性和简单的界面。可通过
http://127.0.0.1:9091/webui/访问。 -
Milvus Backup:开源工具,用于Milvus数据备份。
-
Birdwatcher:开源工具,用于调试Milvus和动态配置更新。
-
Attu:开源GUI工具,用于直观的Milvus管理。
5.3 备份和恢复
Milvus Lite提供了命令行工具,可以将数据导出到JSON文件中:
# 安装带bulk_writer的pymilvus
pip install -U "pymilvus[bulk_writer]"
# 导出数据
milvus-lite dump -d ./milvus_demo.db -c demo_collection -p ./data_dir
使用导出的文件,可以通过以下方式上传数据:
- 通过数据导入功能上传到Zilliz Cloud
- 通过批量插入功能上传到Milvus服务器
5.4 集群扩容
对于Milvus Distributed,可以通过修改Kubernetes配置来扩展集群:
- 调整资源请求和限制
- 增加副本数量
- 添加更多节点到Kubernetes集群
5.5 升级Milvus版本
- Milvus Standalone:使用
bash standalone_embed.sh upgrade命令 - Milvus Distributed:使用Helm或Milvus Operator进行升级
6. 总结
Milvus是一款功能强大的向量数据库,提供了从轻量级到分布式集群的多种部署选项,适应不同规模和场景的需求。通过本博客,我们介绍了Milvus的基本概念、部署方案对比、部署操作实战、使用方法和运维方案。
无论您是在进行快速原型设计、构建小型生产应用还是需要大规模向量搜索系统,Milvus都能提供灵活而强大的解决方案。根据您的项目阶段和规模选择合适的Milvus部署模式,可以获得最佳的性能和资源利用效率。
参考资料
- Milvus官方文档
- Milvus安装概述
- Milvus Lite文档
- Milvus集合管理
- Milvus监控指南