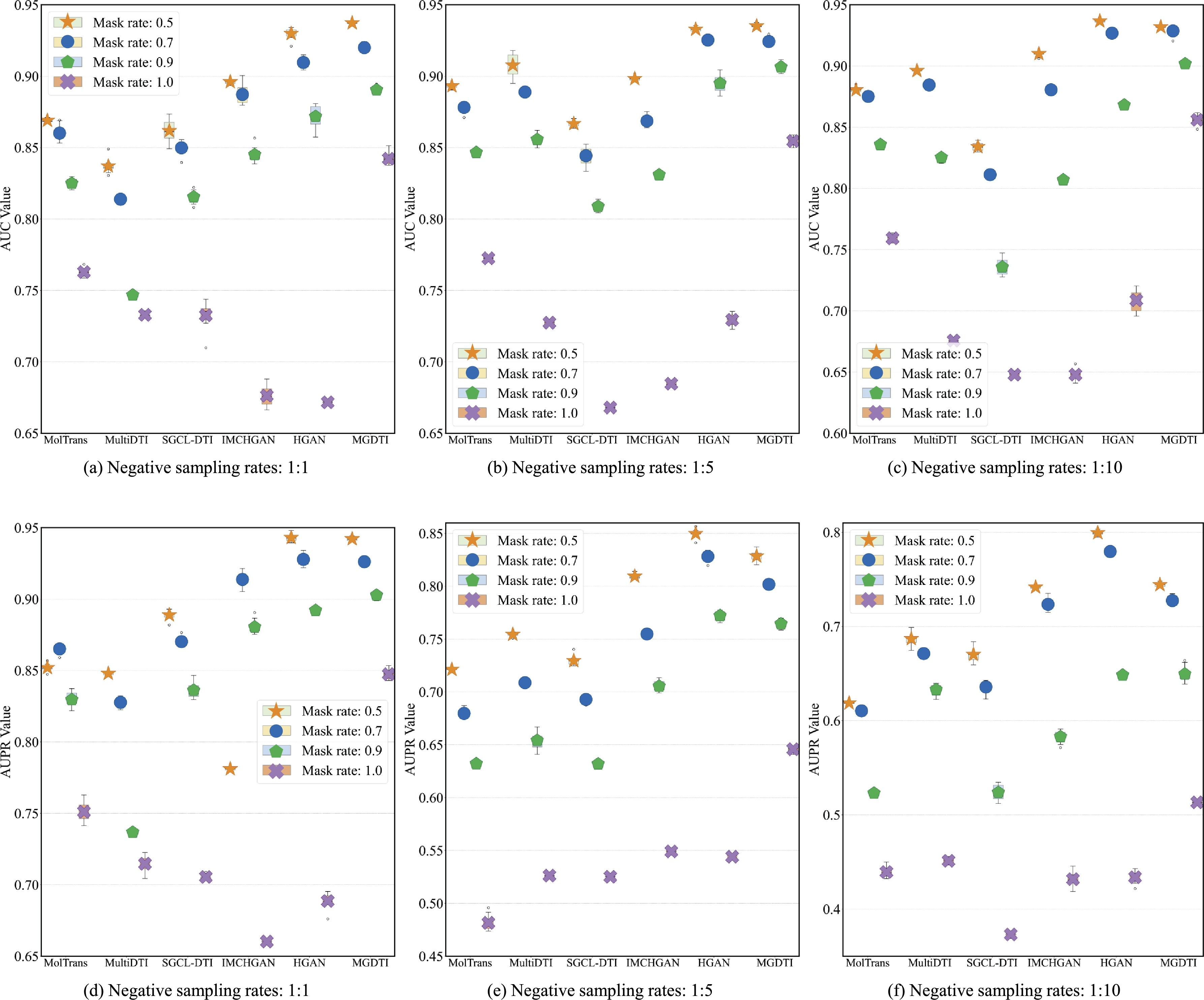
目录
- 代码
- 代码解释
- 1. 导入和初始化
- 2. Label 类定义
- 3. RerankedResults 类
- 4. 重排序函数
- 示例
- 类似例子
- 例子中的jinjia模板语法
- 变量
- 2. 控制结构
- 条件语句
- 循环语句
代码
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfo
# Initialize the OpenAI client with Instructor
client = instructor.from_openai(OpenAI(api_key = "your api key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"))
class Label(BaseModel):
chunk_id: str = Field(description="The unique identifier of the text chunk")
chain_of_thought: str = Field(
description="The reasoning process used to evaluate the relevance"
)
relevancy: int = Field(
description="Relevancy score from 0 to 10, where 10 is most relevant",
ge=0,
le=10,
)
@field_validator("chunk_id")
@classmethod
def validate_chunk_id(cls, v: str, info: ValidationInfo) -> str:
context = info.context
chunks = context.get("chunks", [])
if v not in [chunk["id"] for chunk in chunks]:
raise ValueError(
f"Chunk with id {v} not found, must be one of {[chunk['id'] for chunk in chunks]}"
)
return v
class RerankedResults(BaseModel):
labels: list[Label] = Field(description="List of labeled and ranked chunks")
@field_validator("labels")
@classmethod
def model_validate(cls, v: list[Label]) -> list[Label]:
return sorted(v, key=lambda x: x.relevancy, reverse=True)
def rerank_results(query: str, chunks: list[dict]) -> RerankedResults:
return client.chat.completions.create(
model="qwen-turbo",
response_model=RerankedResults,
messages=[
{
"role": "system",
"content": """
You are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.
For each chunk:
1. Analyze its content in relation to the query.
2. Provide a chain of thought explaining your reasoning.
3. Assign a relevancy score from 0 to 10, where 10 is most relevant.
Be objective and consistent in your evaluations.
""",
},
{
"role": "user",
"content": """
<query>{{ query }}</query>
<chunks_to_rank>
{% for chunk in chunks %}
<chunk chunk_id="{{ chunk.id }}">
{{ chunk.text }}
</chunk>
{% endfor %}
</chunks_to_rank>
Please provide a RerankedResults object with a Label for each chunk.
""",
},
],
context={"query": query, "chunks": chunks},
)
代码解释
1. 导入和初始化
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfo
client = instructor.from_openai(OpenAI(...))
- 使用 instructor 增强 OpenAI 功能
- 使用 Pydantic 进行数据验证和序列化
2. Label 类定义
class Label(BaseModel):
chunk_id: str = Field(...)
chain_of_thought: str = Field(...)
relevancy: int = Field(..., ge=0, le=10)
定义了文本块的标签模型:
chunk_id: 文本块的唯一标识符chain_of_thought: 相关性评估的推理过程relevancy: 0-10的相关性得分
包含了一个验证器:
@field_validator("chunk_id")
def validate_chunk_id(cls, v: str, info: ValidationInfo) -> str:
确保 chunk_id 存在于输入的文本块列表中
3. RerankedResults 类
class RerankedResults(BaseModel):
labels: list[Label]
- 存储所有标签的容器类
- 包含一个验证器,按相关性得分降序排序结果
4. 重排序函数
def rerank_results(query: str, chunks: list[dict]) -> RerankedResults:
核心功能:
- 接收查询和文本块列表
- 使用 AI 模型评估相关性
- 返回排序后的结果
系统提示设置:
- 定义 AI 为专家排序系统
- 提供评估标准和打分规则
用户提示模板:
- 使用 Jinja2 模板语法
- 动态插入查询和文本块
- 格式化为结构化的 XML 格式
这个系统的主要用途:
- 智能文本相关性排序
- 提供透明的推理过程
- 确保结果的一致性和可验证性
示例
def main():
# Sample query and chunks
query = "What are the health benefits of regular exercise?"
chunks = [
{
"id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"text": "Regular exercise can improve cardiovascular health and reduce the risk of heart disease.",
},
{
"id": "b2c3d4e5-f6g7-8901-bcde-fg2345678901",
"text": "The price of gym memberships varies widely depending on location and facilities.",
},
{
"id": "c3d4e5f6-g7h8-9012-cdef-gh3456789012",
"text": "Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.",
},
{
"id": "d4e5f6g7-h8i9-0123-defg-hi4567890123",
"text": "Proper nutrition is essential for maintaining a healthy lifestyle.",
},
{
"id": "e5f6g7h8-i9j0-1234-efgh-ij5678901234",
"text": "Strength training can increase muscle mass and improve bone density, especially important as we age.",
},
]
# Rerank the results
results = rerank_results(query, chunks)
# Print the reranked results
print("Reranked results:")
for label in results.labels:
print(f"Chunk {label.chunk_id} (Relevancy: {label.relevancy}):")
print(
f"Text: {next(chunk['text'] for chunk in chunks if chunk['id'] == label.chunk_id)}"
)
print(f"Reasoning: {label.chain_of_thought}")
print()
main()
Reranked results:
Chunk a1b2c3d4-e5f6-7890-abcd-ef1234567890 (Relevancy: 10):
Text: Regular exercise can improve cardiovascular health and reduce the risk of heart disease.
Reasoning: This chunk directly discusses the health benefits of exercise, specifically improving cardiovascular health and reducing heart disease risk.
Chunk c3d4e5f6-g7h8-9012-cdef-gh3456789012 (Relevancy: 8):
Text: Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.
Reasoning: This chunk talks about how exercise can boost mood and reduce symptoms of depression and anxiety, which are health benefits.
Chunk e5f6g7h8-i9j0-1234-efgh-ij5678901234 (Relevancy: 7):
Text: Strength training can increase muscle mass and improve bone density, especially important as we age.
Reasoning: Strength training's effects on muscle mass and bone density are health benefits associated with exercise.
Chunk d4e5f6g7-h8i9-0123-defg-hi4567890123 (Relevancy: 2):
Text: Proper nutrition is essential for maintaining a healthy lifestyle.
Reasoning: While nutrition is important, this chunk does not discuss the health benefits of exercise itself.
Chunk b2c3d4e5-f6g7-8901-bcde-fg2345678901 (Relevancy: 0):
Text: The price of gym memberships varies widely depending on location and facilities.
Reasoning: This chunk is about gym membership prices, which is unrelated to the health benefits of exercise.
类似例子
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator, ValidationInfo
# 初始化 OpenAI 客户端
client = instructor.from_openai(OpenAI(api_key = "your api key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"))
class ReviewLabel(BaseModel):
review_id: str = Field(description="评论的唯一标识符")
chain_of_thought: str = Field(
description="评估相关性的推理过程"
)
relevancy: int = Field(
description="相关性得分,0-10分,10分最相关",
ge=0,
le=10,
)
@field_validator("review_id")
@classmethod
def validate_review_id(cls, v: str, info: ValidationInfo) -> str:
context = info.context
reviews = context.get("reviews", [])
if v not in [review["id"] for review in reviews]:
raise ValueError(
f"找不到ID为 {v} 的评论,必须是以下ID之一: {[review['id'] for review in reviews]}"
)
return v
class RankedReviews(BaseModel):
labels: list[ReviewLabel] = Field(description="已标记和排序的评论列表")
@field_validator("labels")
@classmethod
def model_validate(cls, v: list[ReviewLabel]) -> list[ReviewLabel]:
return sorted(v, key=lambda x: x.relevancy, reverse=True)
def rank_reviews(movie_title: str, reviews: list[dict]) -> RankedReviews:
return client.chat.completions.create(
model="qwen-turbo",
response_model=RankedReviews,
messages=[
{
"role": "system",
"content": """
你是一个专业的电影评论分析专家。你的任务是评估每条评论与给定电影的相关性,并给出相关性得分。
对每条评论:
1. 分析评论内容与电影的相关程度
2. 提供推理过程说明你的评分理由
3. 给出0-10的相关性得分,10分表示最相关
请保持客观和一致性。
""",
},
{
"role": "user",
"content": """
<movie>{{ movie_title }}</movie>
<reviews_to_rank>
{% for review in reviews %}
<review review_id="{{ review.id }}">
{{ review.text }}
</review>
{% endfor %}
</reviews_to_rank>
请提供一个包含每条评论标签的RankedReviews对象。
""",
},
],
context={"movie_title": movie_title, "reviews": reviews},
)
def main():
# 示例数据
movie_title = "泰坦尼克号"
reviews = [
{
"id": "rev001",
"text": "这部电影完美展现了泰坦尼克号的悲剧,演员表演令人动容。",
},
{
"id": "rev002",
"text": "最近电影票价格上涨了不少,看电影越来越贵了。",
},
{
"id": "rev003",
"text": "Jack和Rose的爱情故事让人难忘,经典场景依然令人感动。",
},
{
"id": "rev004",
"text": "这家电影院的爆米花很好吃,推荐尝试。",
},
{
"id": "rev005",
"text": "电影的特效和场景还原都很精良,展现了那个年代的奢华。",
},
]
# 对评论进行排序
results = rank_reviews(movie_title, reviews)
# 打印排序结果
print("评论排序结果:")
for label in results.labels:
print(f"评论 {label.review_id} (相关性得分: {label.relevancy}):")
print(
f"内容: {next(review['text'] for review in reviews if review['id'] == label.review_id)}"
)
print(f"推理过程: {label.chain_of_thought}")
print()
main()
评论排序结果:
评论 rev001 (相关性得分: 10):
内容: 这部电影完美展现了泰坦尼克号的悲剧,演员表演令人动容。
推理过程: 评论直接提到电影《泰坦尼克号》,并赞扬其悲剧展现和演员表演,明显与电影高度相关。
评论 rev003 (相关性得分: 9):
内容: Jack和Rose的爱情故事让人难忘,经典场景依然令人感动。
推理过程: 评论聚焦于电影中的爱情故事和经典场景,与《泰坦尼克号》的主题紧密相关。
评论 rev005 (相关性得分: 8):
内容: 电影的特效和场景还原都很精良,展现了那个年代的奢华。
推理过程: 评论称赞电影的特效和场景还原,这与《泰坦尼克号》的内容直接相关。
评论 rev002 (相关性得分: 2):
内容: 最近电影票价格上涨了不少,看电影越来越贵了。
推理过程: 评论讨论的是电影票价上涨的问题,与具体电影《泰坦尼克号》无关,因此相关性较低。
评论 rev004 (相关性得分: 1):
内容: 这家电影院的爆米花很好吃,推荐尝试。
推理过程: 评论谈论的是电影院的爆米花,与电影本身无直接关系,因此相关性很低。
例子中的jinjia模板语法
例子中用到Jinja 模板语法的核心概念:
变量
{{ 变量名 }}
用于在模板中插入变量值,例如:
"你好,{{ username }}" # 如果 username = "小明",输出: "你好,小明"
2. 控制结构
条件语句
{% if 条件 %}
内容1
{% else %}
内容2
{% endif %}
循环语句
{% for item in items %}
{{ item }}
{% endfor %}
Jinja 模板的主要优势:
- 代码复用
- 逻辑与展示分离
- 动态内容生成
- 安全性(自动转义)
- 灵活的扩展性
这些特性使得 Jinja2 成为 Python 生态系统中最流行的模板引擎之一。
例子1:
from instructor.templating import handle_templating
from instructor.mode import Mode
# 输入参数示例
kwargs = {
"messages": [
{
"role": "system",
"content": "你是一个专业的{{ domain }}助手"
},
{
"role": "user",
"content": "请分析关于{{ topic }}的问题"
}
]
}
mode = Mode.TOOLS # 使用 OpenAI 格式
context = {
"domain": "医疗",
"topic": "心脏病预防"
}
# 调用函数
result = handle_templating(kwargs, mode, context)
# 输出结果
print(result)
{'messages': [{'role': 'system', 'content': '你是一个专业的医疗助手'}, {'role': 'user', 'content': '请分析关于心脏病预防的问题'}]}
例子2:
query = "What are the health benefits of regular exercise?"
chunks = [
{
"id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"text": "Regular exercise can improve cardiovascular health and reduce the risk of heart disease.",
},
{
"id": "b2c3d4e5-f6g7-8901-bcde-fg2345678901",
"text": "The price of gym memberships varies widely depending on location and facilities.",
},
{
"id": "c3d4e5f6-g7h8-9012-cdef-gh3456789012",
"text": "Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.",
},
{
"id": "d4e5f6g7-h8i9-0123-defg-hi4567890123",
"text": "Proper nutrition is essential for maintaining a healthy lifestyle.",
},
{
"id": "e5f6g7h8-i9j0-1234-efgh-ij5678901234",
"text": "Strength training can increase muscle mass and improve bone density, especially important as we age.",
},
]
kwargs = {
"messages": [
{
"role": "system",
"content": """
You are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.
For each chunk:
1. Analyze its content in relation to the query.
2. Provide a chain of thought explaining your reasoning.
3. Assign a relevancy score from 0 to 10, where 10 is most relevant.
Be objective and consistent in your evaluations.
""",
},
{
"role": "user",
"content": """
<query>{{ query }}</query>
<chunks_to_rank>
{% for chunk in chunks %}
<chunk chunk_id="{{ chunk.id }}">
{{ chunk.text }}
</chunk>
{% endfor %}
</chunks_to_rank>
Please provide a RerankedResults object with a Label for each chunk.
""",
},
]
}
context={"query": query, "chunks": chunks}
mode = Mode.TOOLS # 使用 OpenAI 格式
# 调用函数
handle_templating(kwargs, mode, context)
{'messages': [{'role': 'system',
'content': '\nYou are an expert search result ranker. Your task is to evaluate the relevance of each text chunk to the given query and assign a relevancy score.\n\nFor each chunk:\n1. Analyze its content in relation to the query.\n2. Provide a chain of thought explaining your reasoning.\n3. Assign a relevancy score from 0 to 10, where 10 is most relevant.\n\nBe objective and consistent in your evaluations.\n'},
{'role': 'user',
'content': '\n<query>What are the health benefits of regular exercise?</query>\n\n<chunks_to_rank>\n\n<chunk chunk_id="a1b2c3d4-e5f6-7890-abcd-ef1234567890">\n Regular exercise can improve cardiovascular health and reduce the risk of heart disease.\n</chunk>\n\n<chunk chunk_id="b2c3d4e5-f6g7-8901-bcde-fg2345678901">\n The price of gym memberships varies widely depending on location and facilities.\n</chunk>\n\n<chunk chunk_id="c3d4e5f6-g7h8-9012-cdef-gh3456789012">\n Exercise has been shown to boost mood and reduce symptoms of depression and anxiety.\n</chunk>\n\n<chunk chunk_id="d4e5f6g7-h8i9-0123-defg-hi4567890123">\n Proper nutrition is essential for maintaining a healthy lifestyle.\n</chunk>\n\n<chunk chunk_id="e5f6g7h8-i9j0-1234-efgh-ij5678901234">\n Strength training can increase muscle mass and improve bone density, especially important as we age.\n</chunk>\n\n</chunks_to_rank>\n\nPlease provide a RerankedResults object with a Label for each chunk.\n'}]}
参考链接:https://github.com/instructor-ai/instructor/tree/main