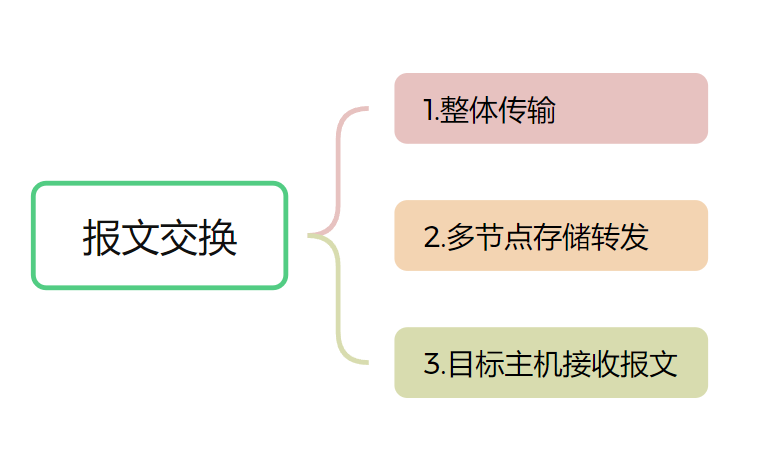
基于BERT的文本分类实战:从原理到部署
一、Transformer与BERT核心原理
Transformer模型通过自注意力机制(Self-Attention)突破了RNN的顺序计算限制,BERT(Bidirectional Encoder Representations from Transformers)作为其典型代表,具有两大创新:
- 双向上下文编码:通过MLM(Masked Language Model)任务实现
- 预训练-微调范式:先在无标注数据预训练,再针对下游任务微调
自注意力计算公式:
\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
二、实战环境搭建与数据准备
1. 安装依赖库
pip