文章目录
- 1、pandas介绍
- 2、为什么使用pandas
- 3、pandas的数据结构
- 1、Series
- 2、DataFrame
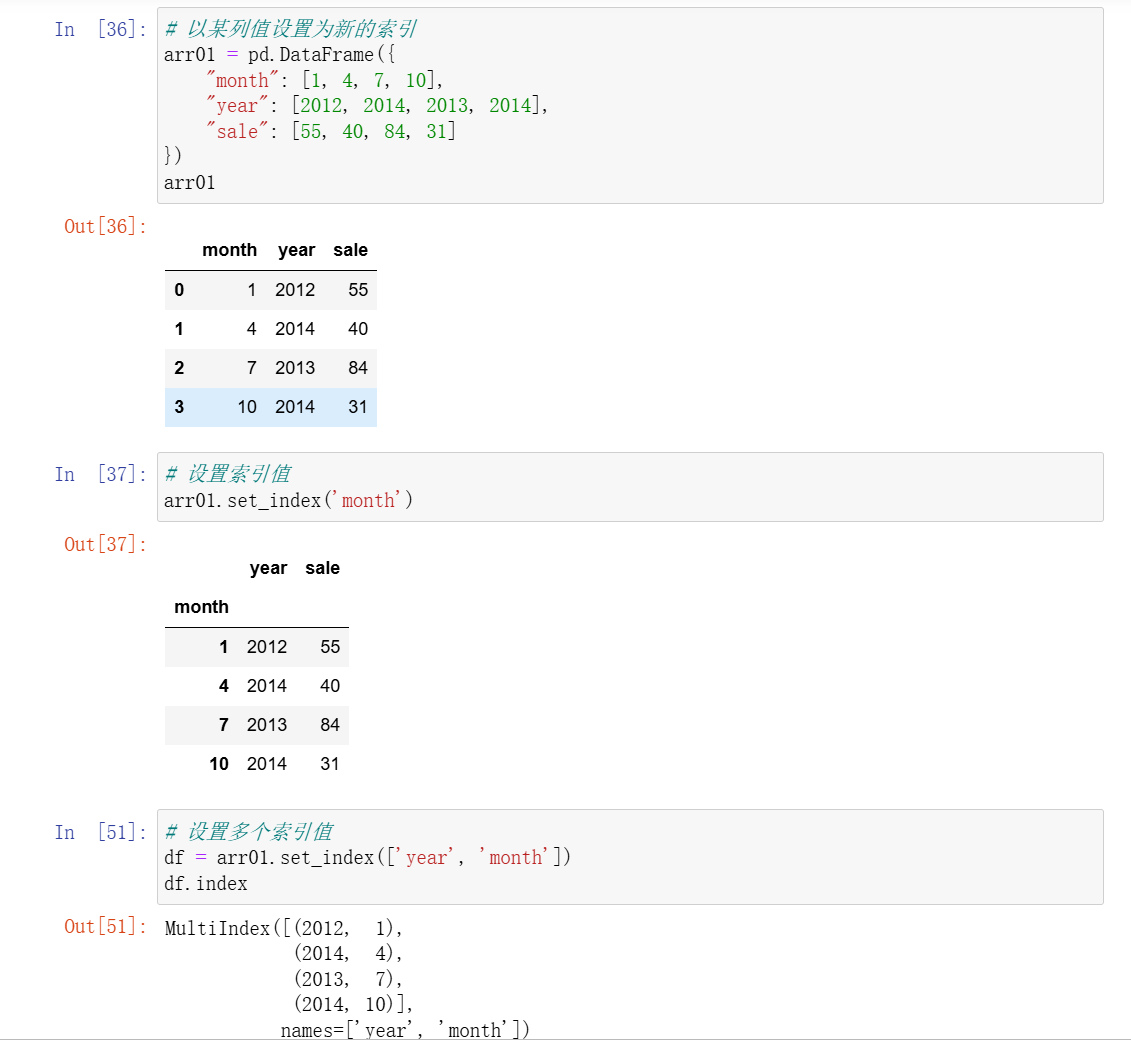
- 3、MultiIndex
- 4、pandas基本数据操作
- 1、索引操作
- 2、赋值操作
- 3、排序
- 4、算术运算
- 5、逻辑运算
- 6、逻辑运算函数
- 7、统计函数
- 8、累计统计函数
- 9、自定义运算
- 5、pandas读取文件和存储
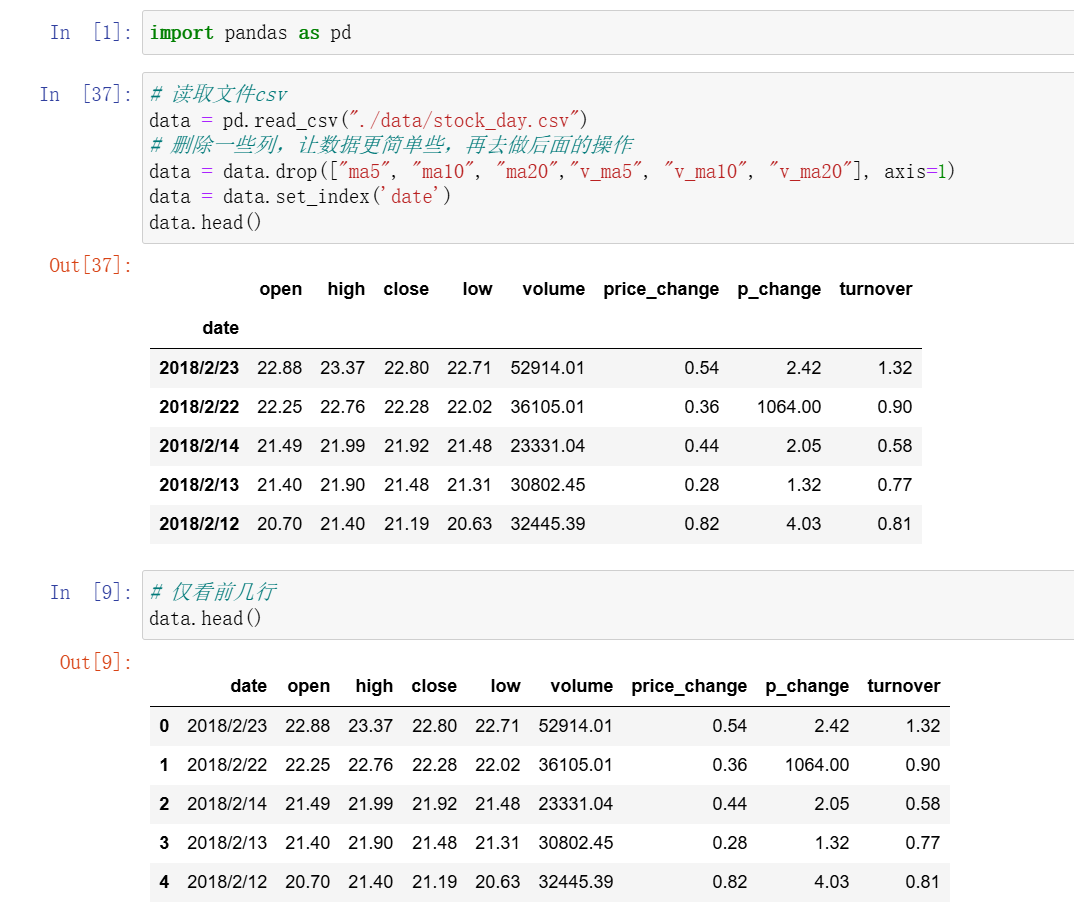
- 1、csv文件
- 2、HDF5
- 3、JSON
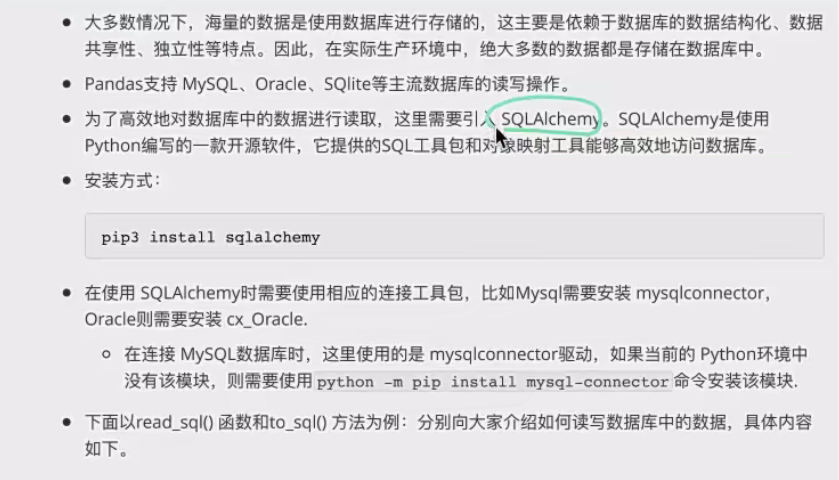
- 6、使用pandas连接数据库
- 1、安装sqlalchemy
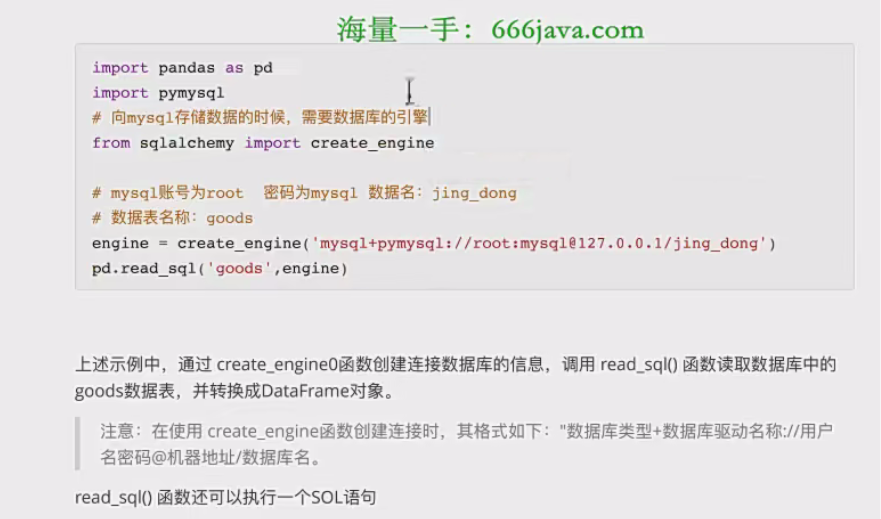
- 2、使用read_sql()函数读取数据
- 7、pandas高级用法
- 1、缺失值处理
- 2、数据离散化
- 3、合并
- 4、交叉表和透视表
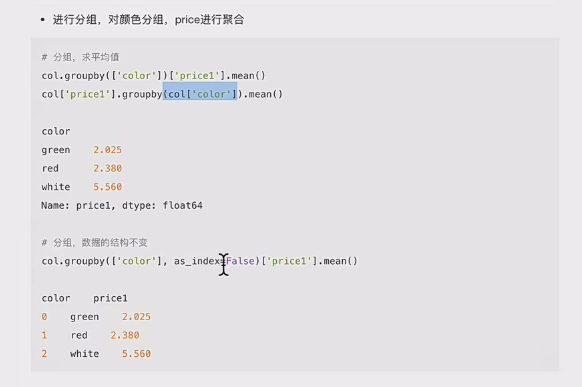
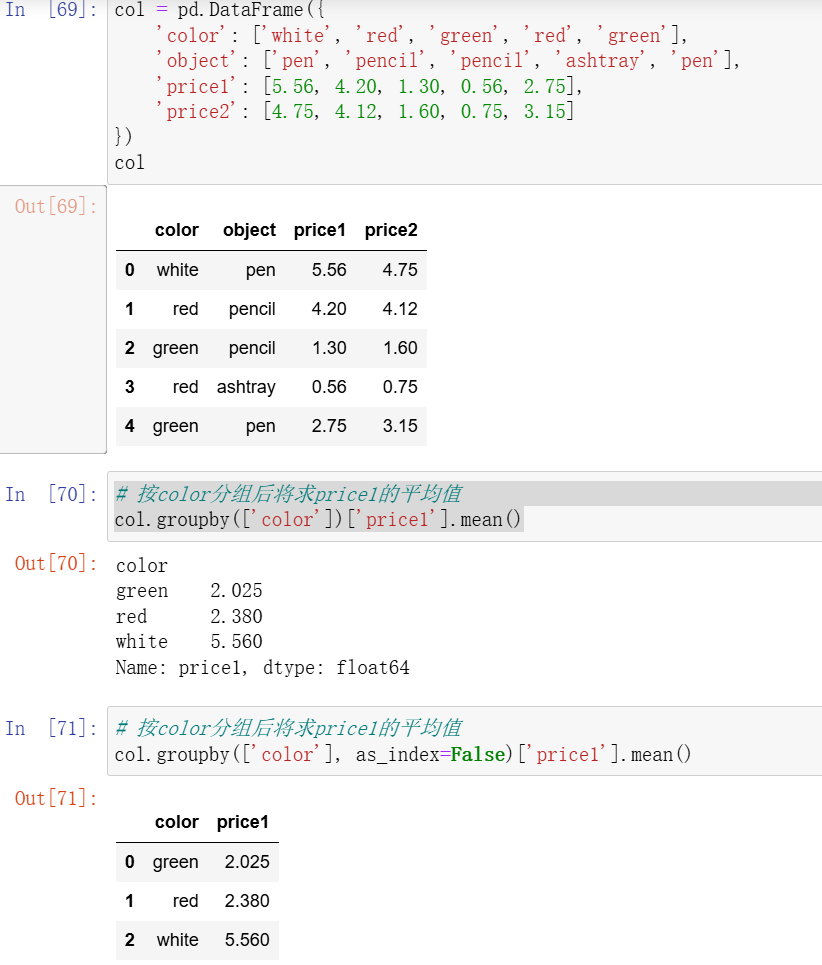
- 5、分组与聚合
需要使用的库
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
1、pandas介绍
- 专门用于数据挖掘的开源python库
- 以numpy为基础,借力numpy模块在计算方面性能高的优势
- 基于matplotlib,能够简便的画图
- 独特的数据结构
2、为什么使用pandas
Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢?
- 增强图表可读性
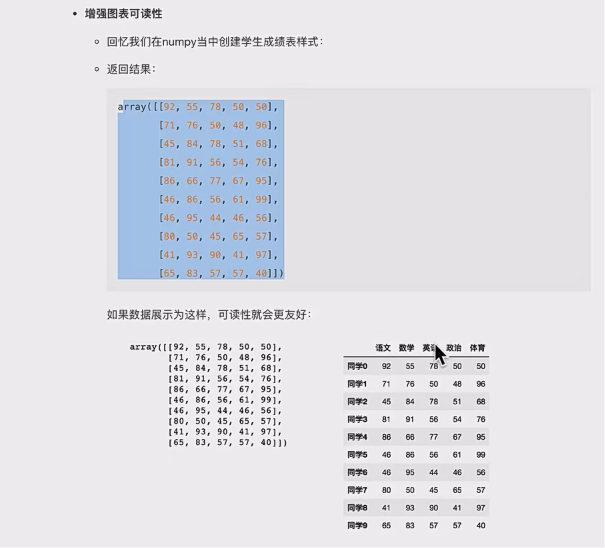
- 便捷的数据处理能力
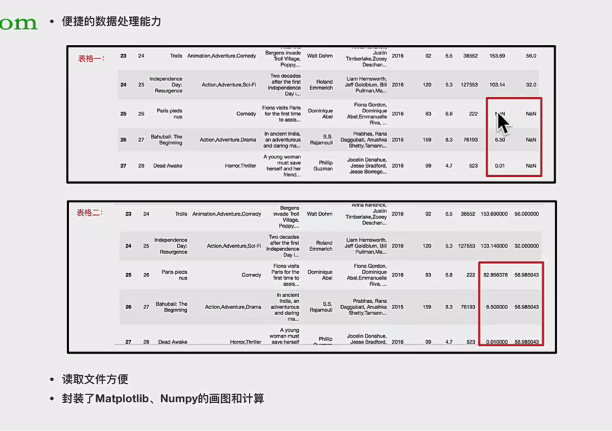
3、pandas的数据结构
pandas中一共有三种数据结构,分别为:Series、DataFrame和MultiIndex。
其中Series是一维数据结构,DataFrame是二维表格型数据结构,MultiIndex是三维的数据结构。
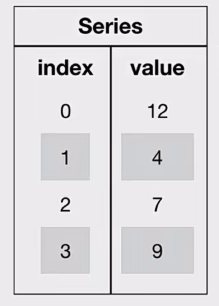
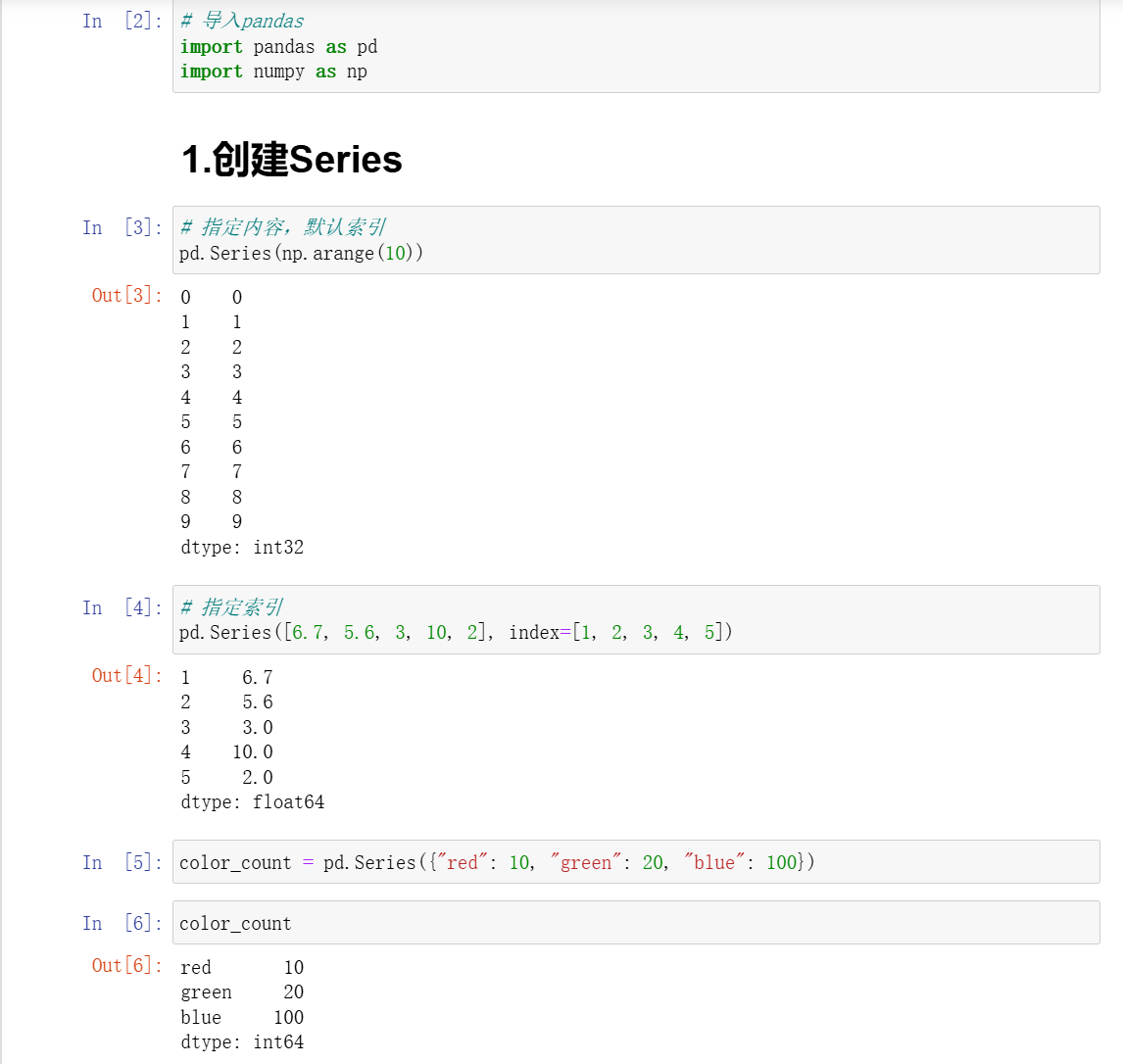
1、Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两部分构成。


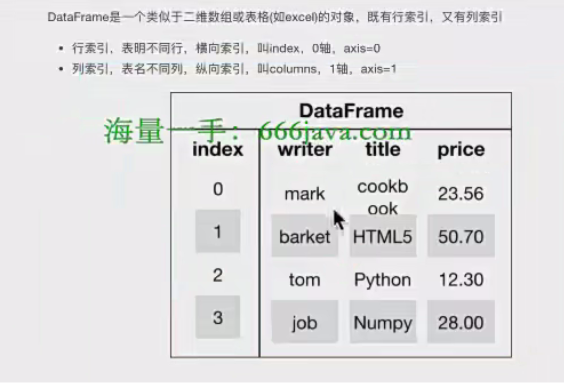
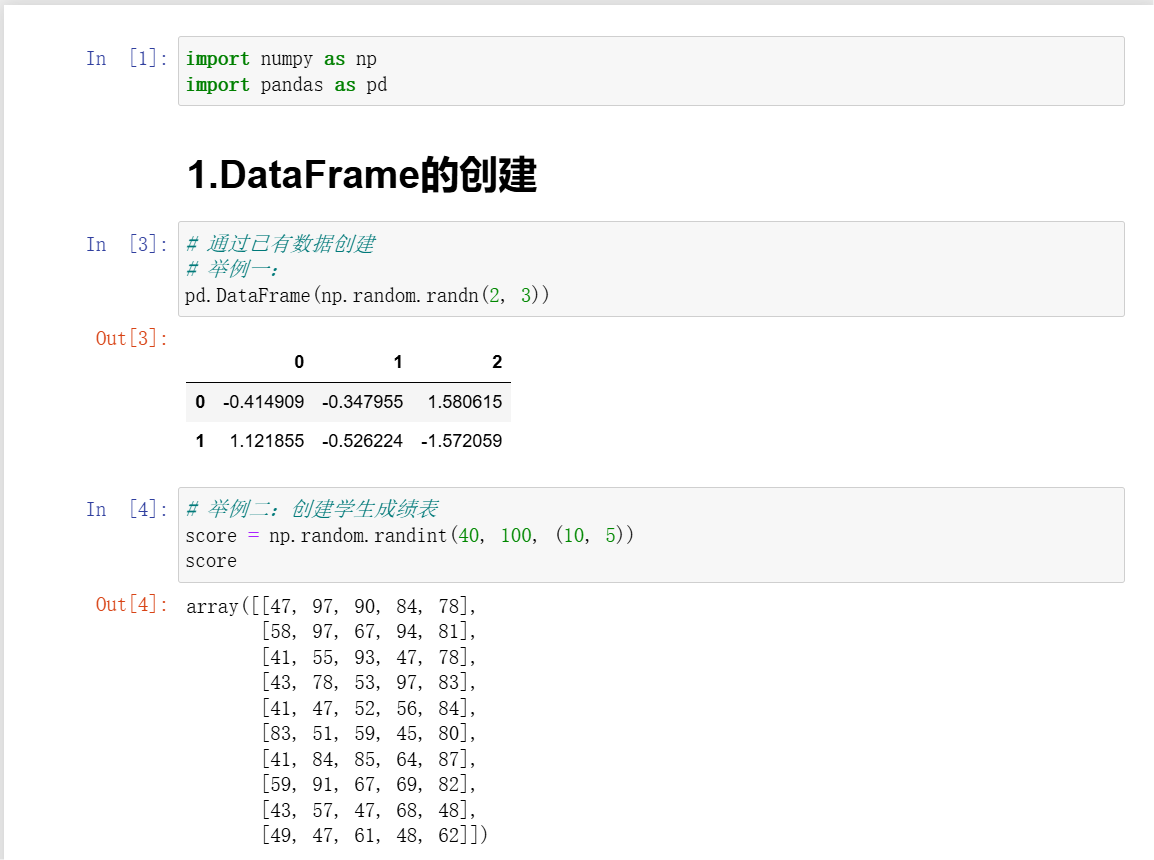
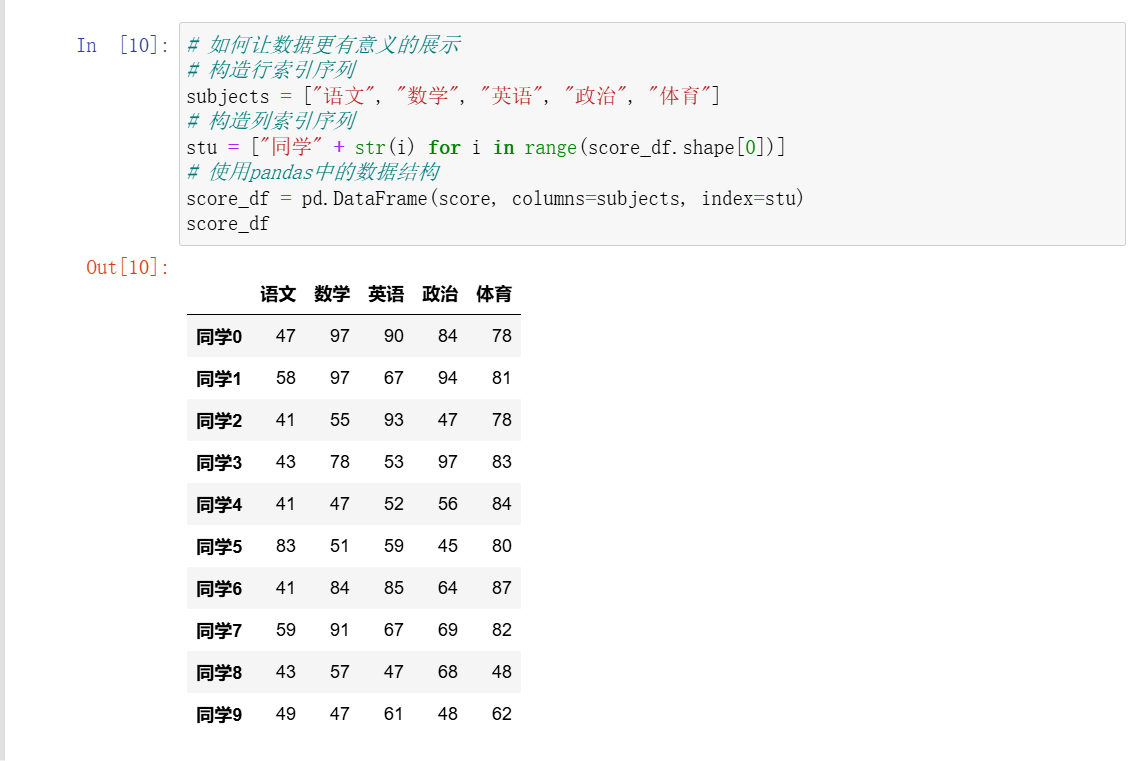
2、DataFrame



3、MultiIndex

4、pandas基本数据操作
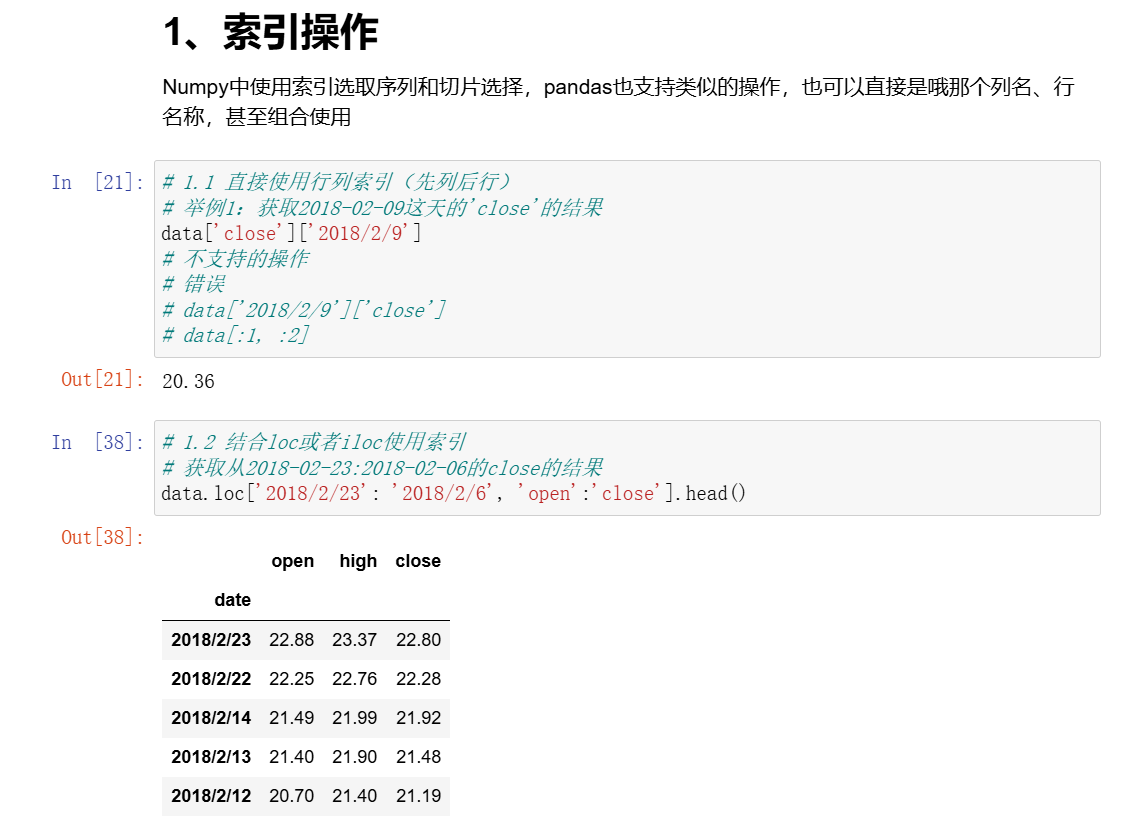
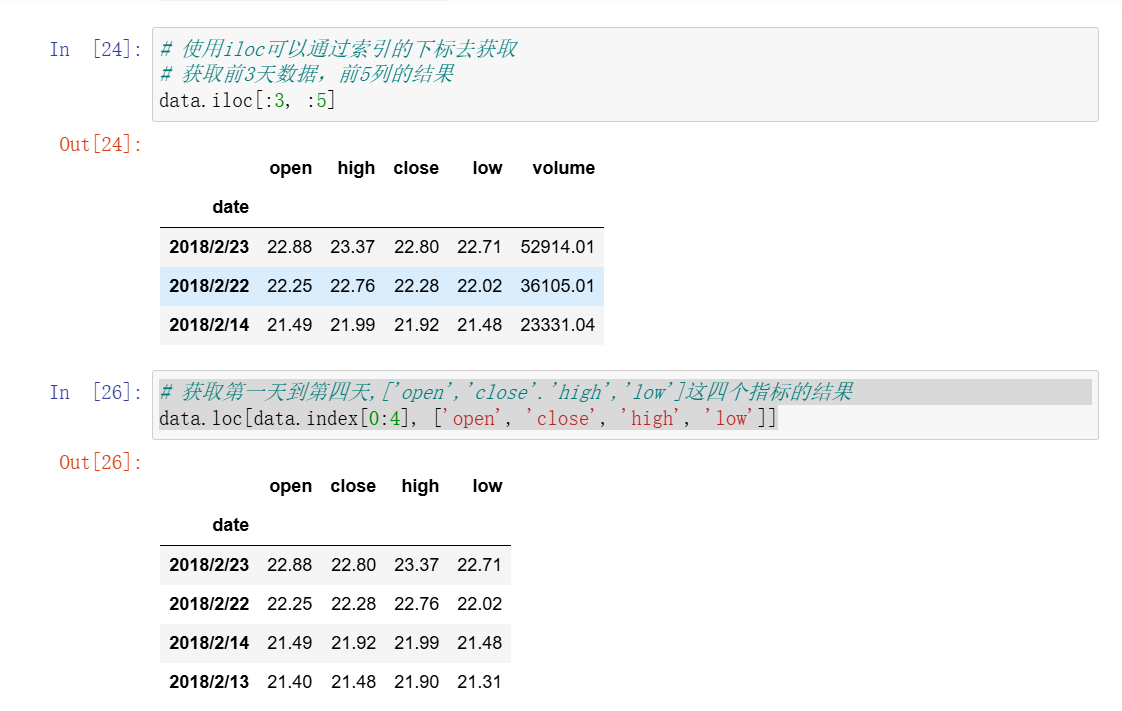
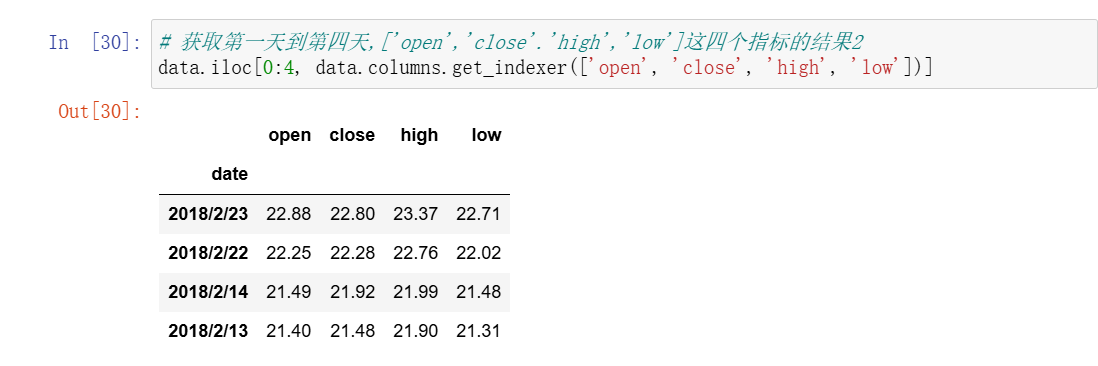
1、索引操作
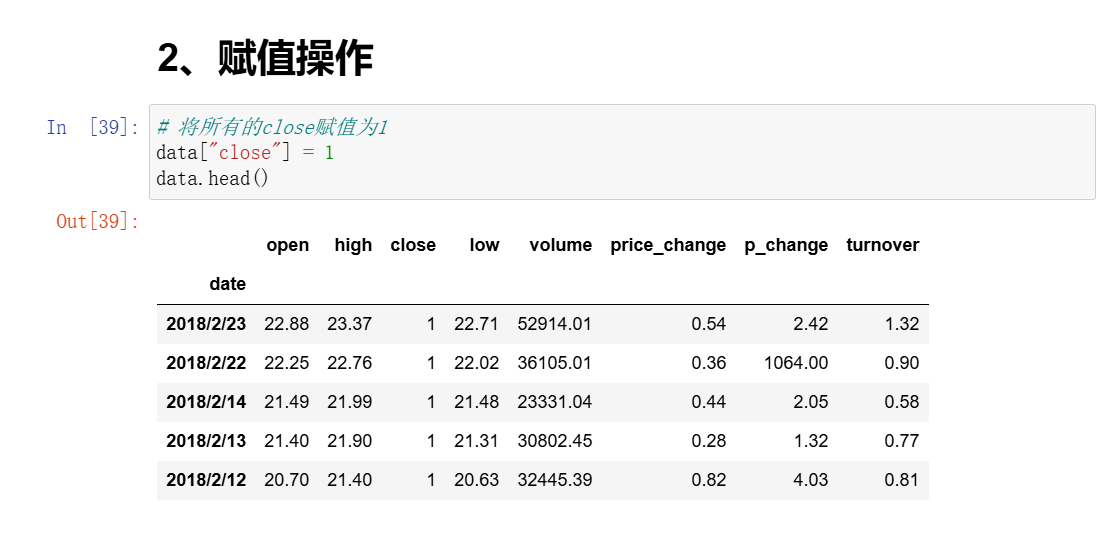
2、赋值操作
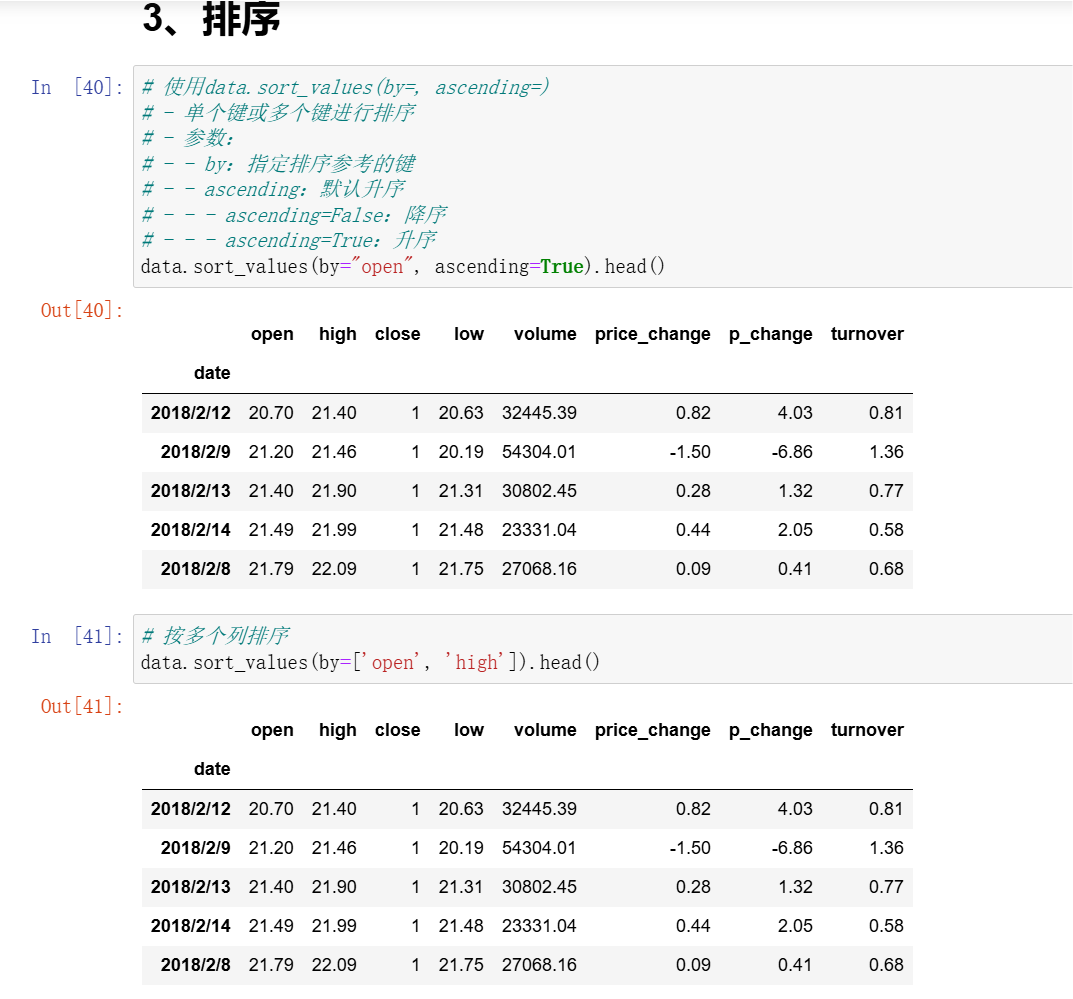
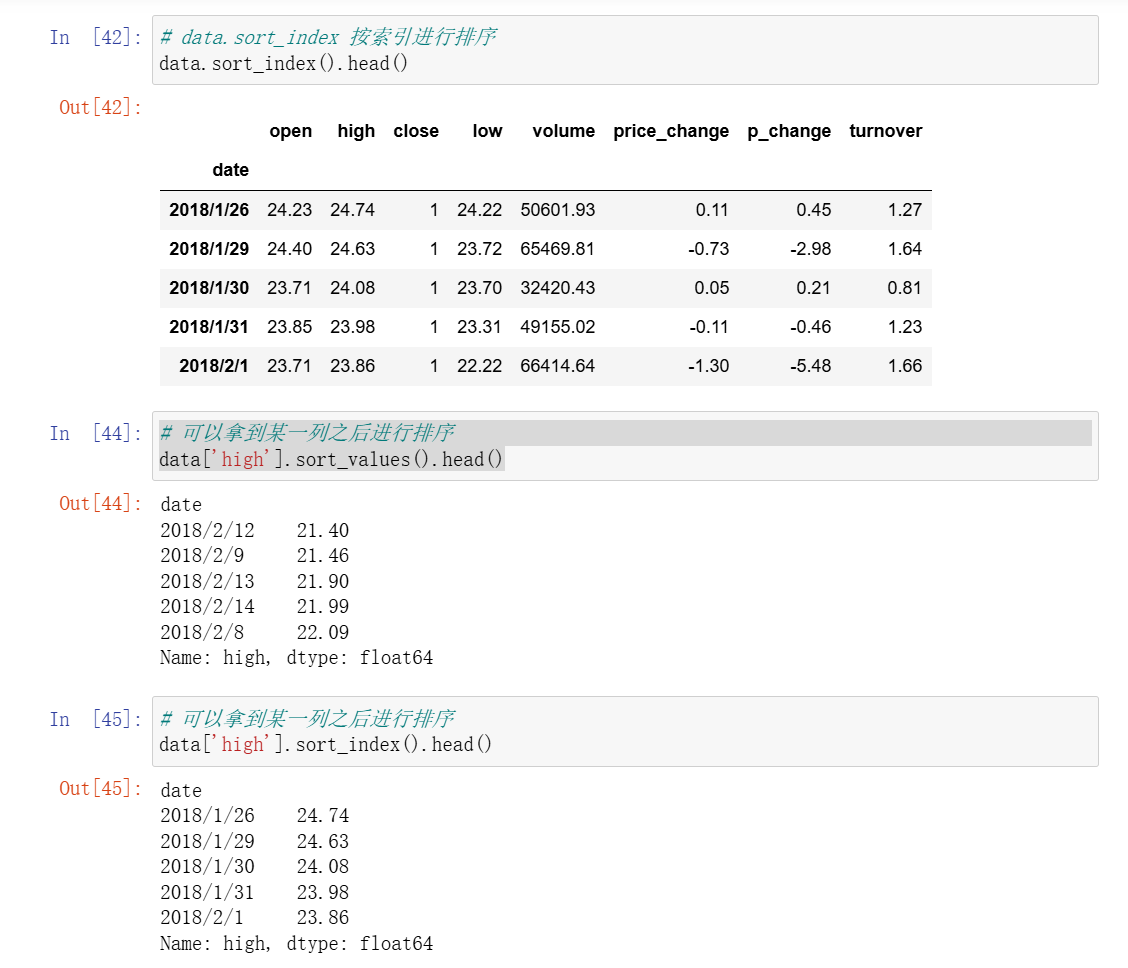
3、排序
4、算术运算

5、逻辑运算
6、逻辑运算函数
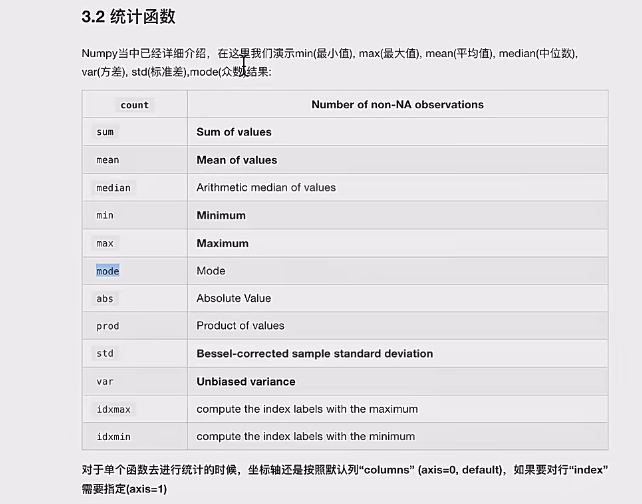
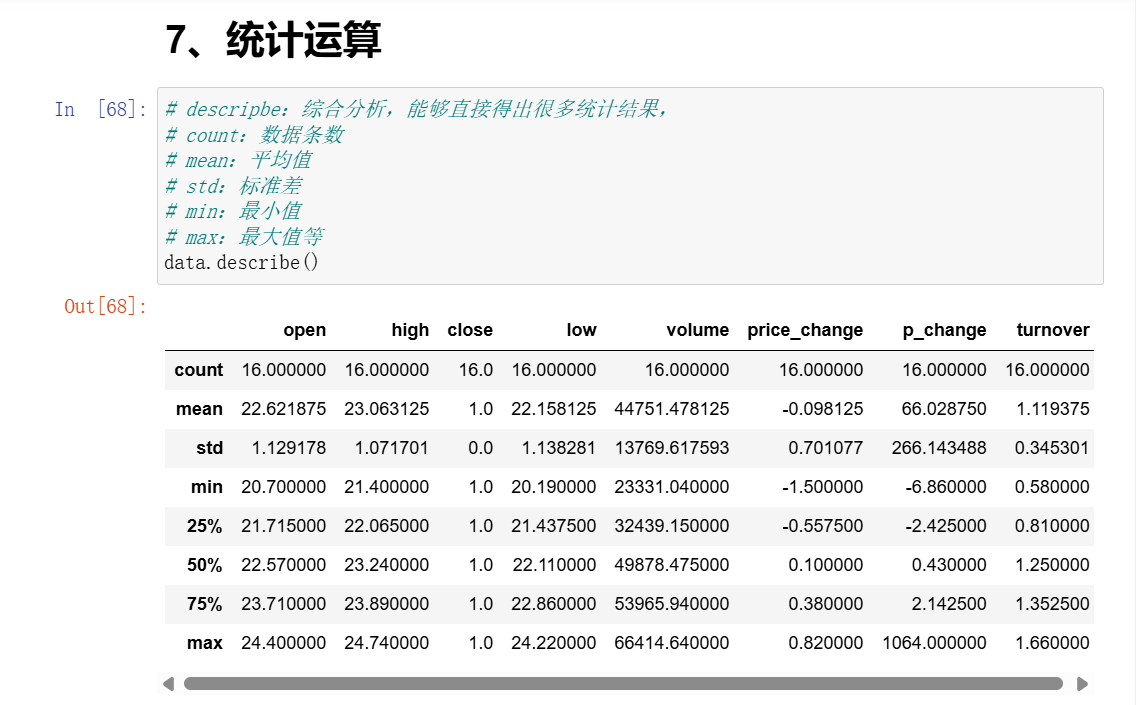
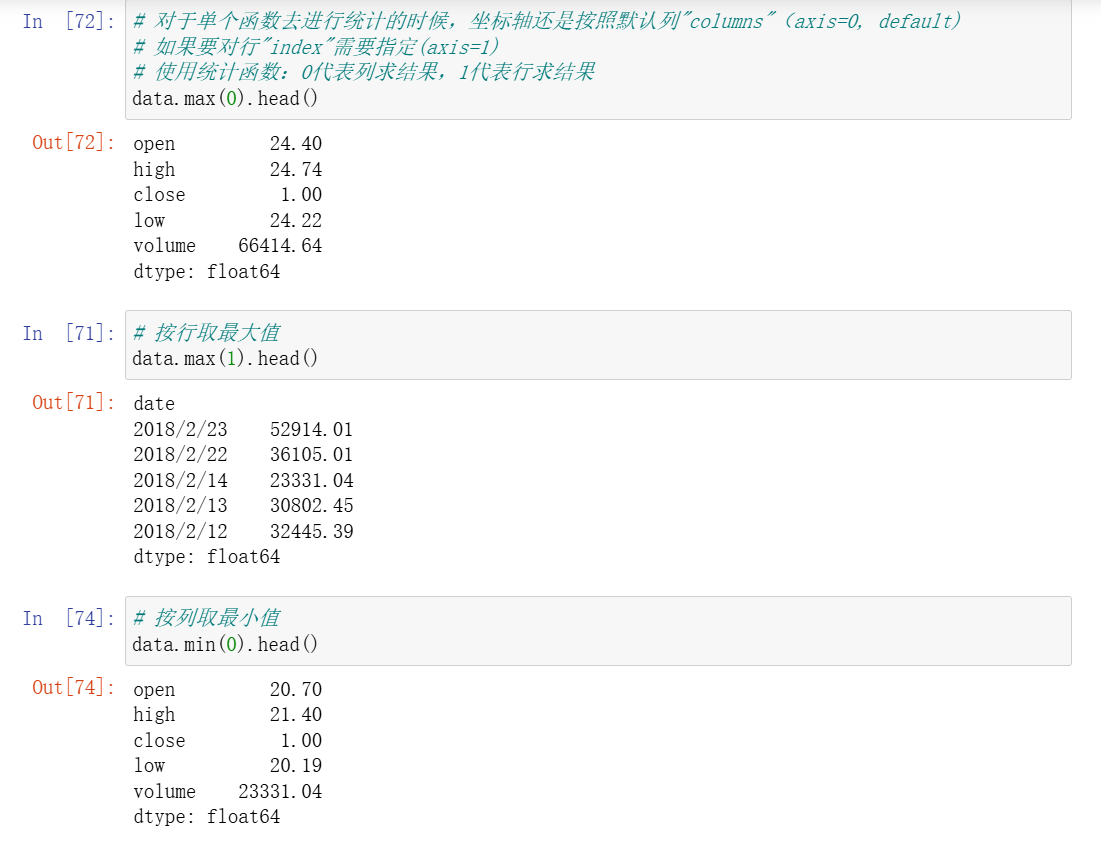
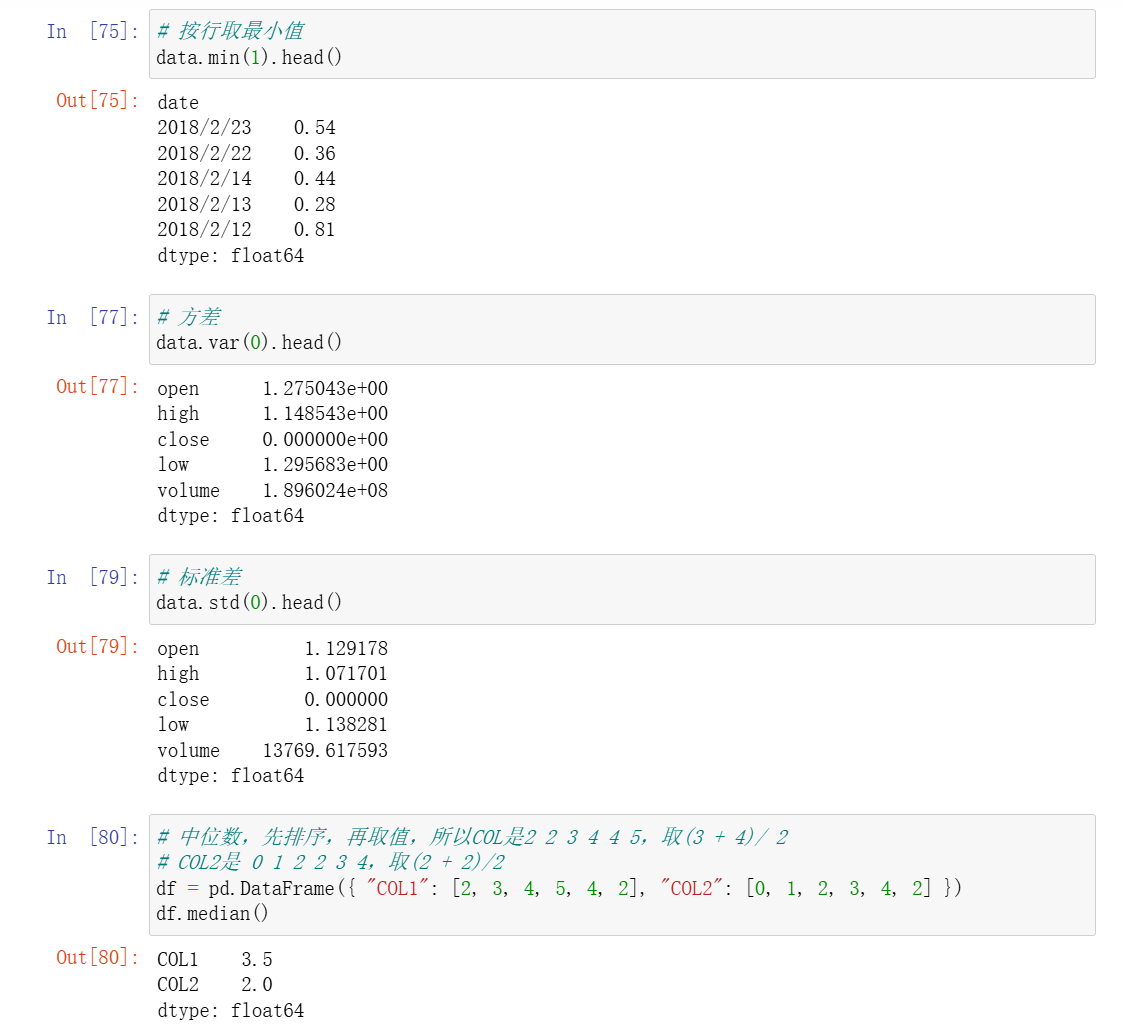
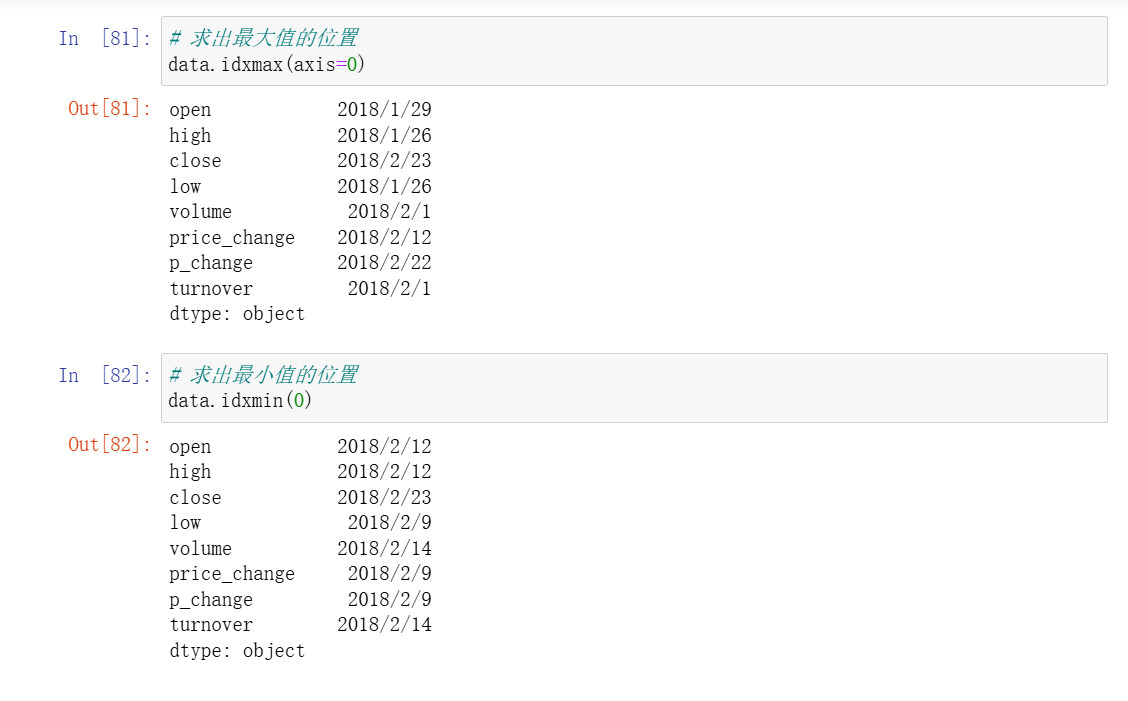
7、统计函数
8、累计统计函数

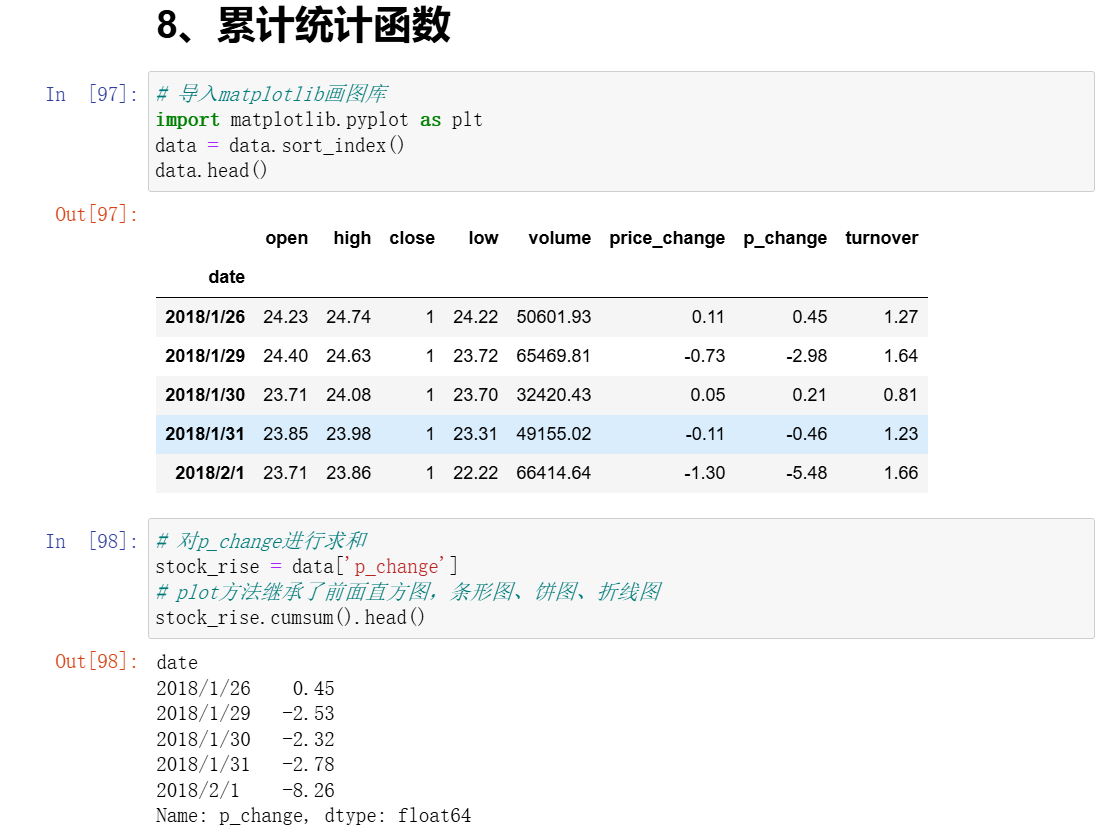
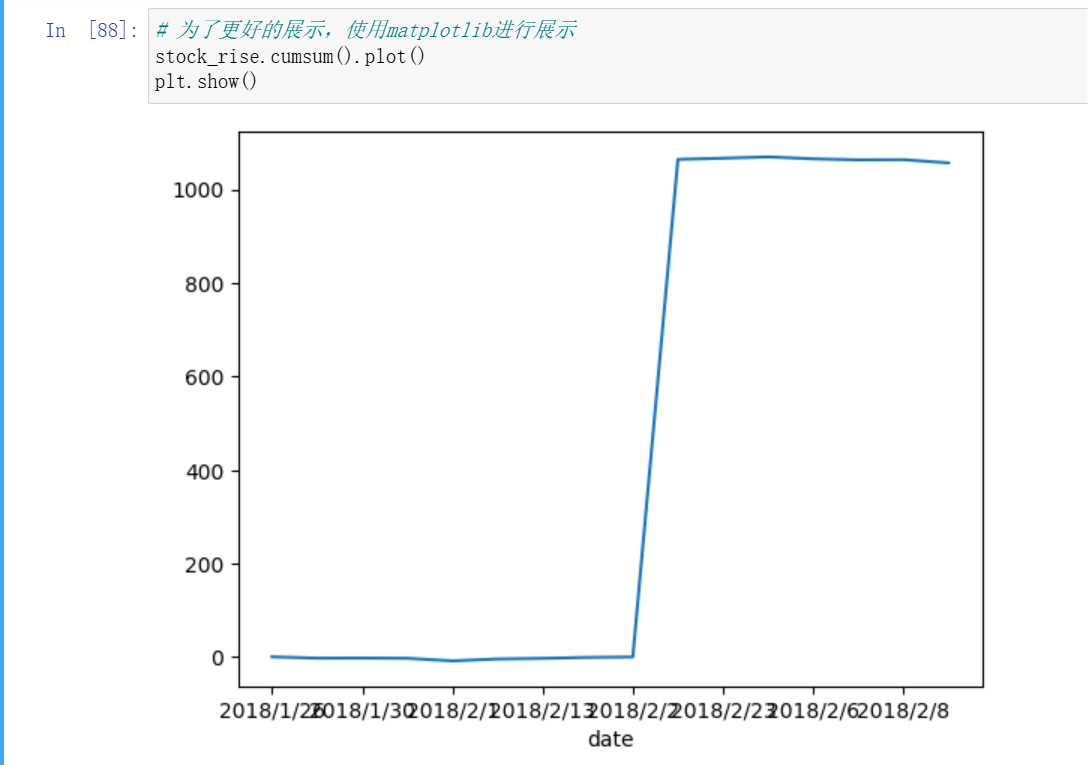
9、自定义运算

5、pandas读取文件和存储
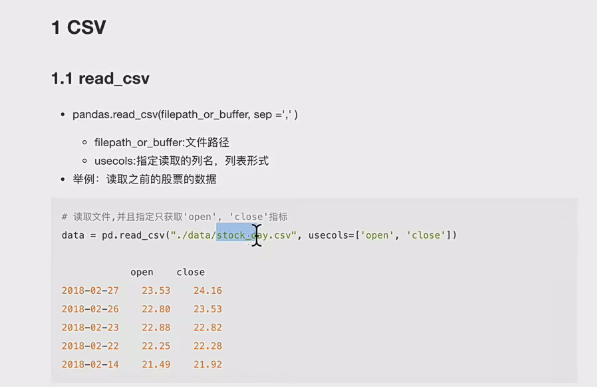
1、csv文件
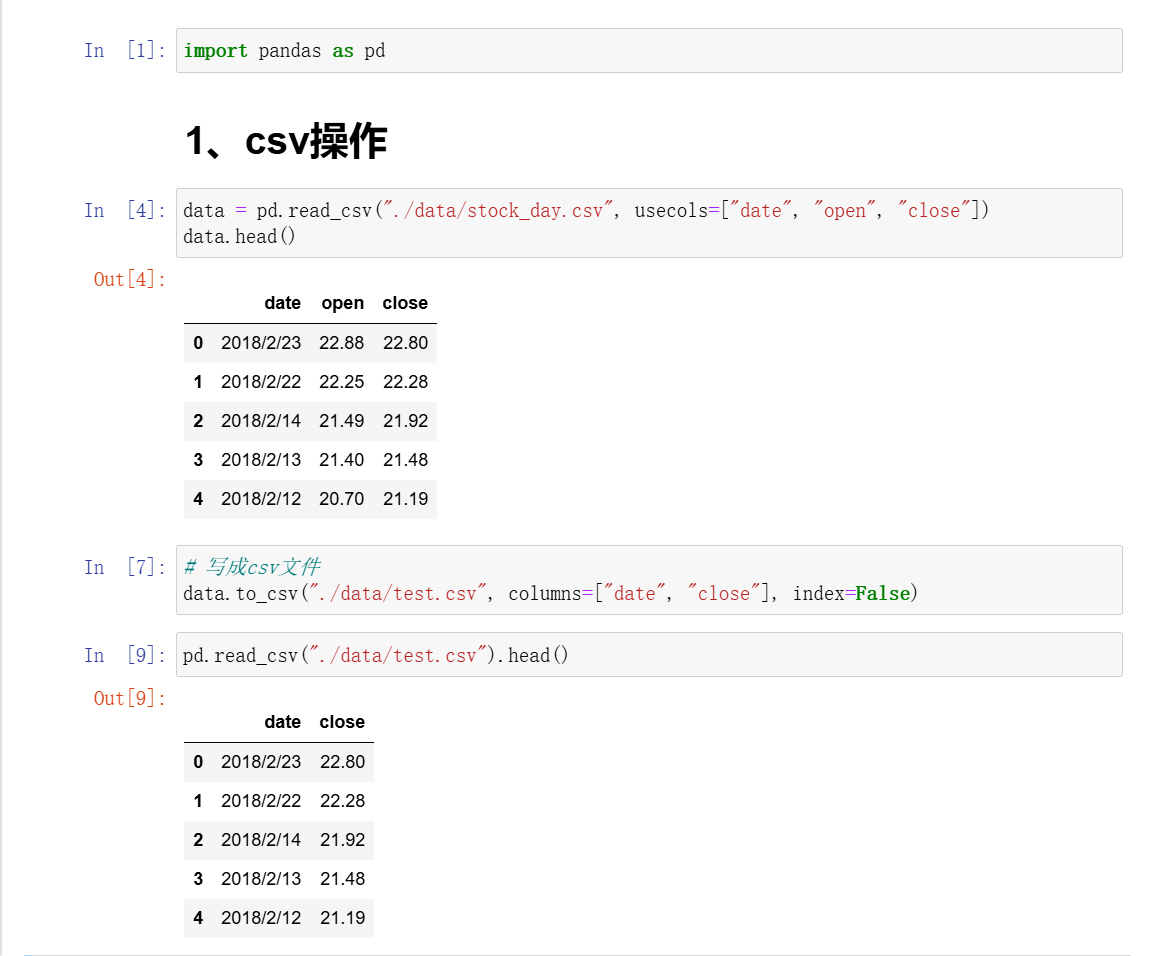
- 1、读取csv文件方法
- 2、保存csv

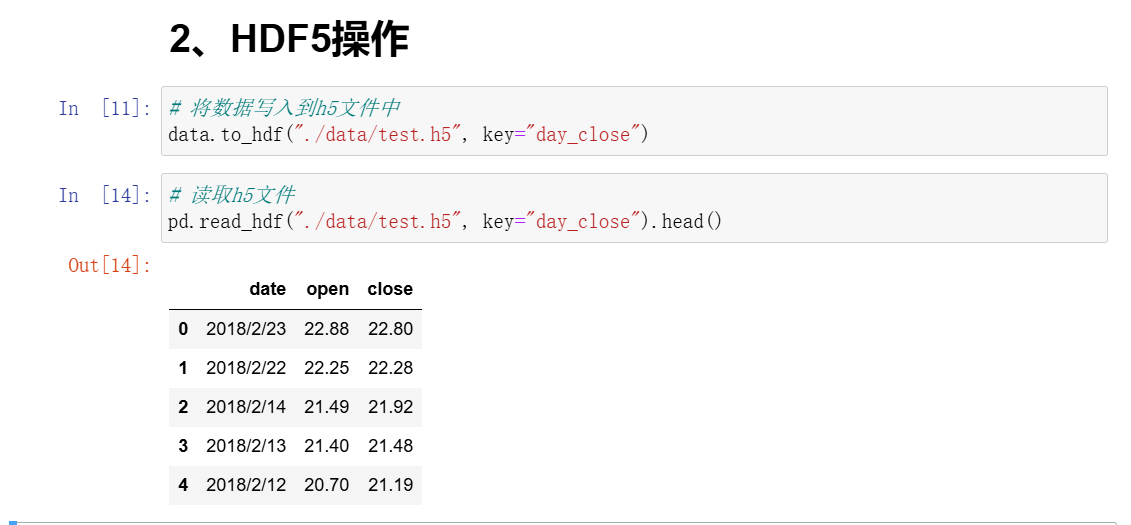
2、HDF5


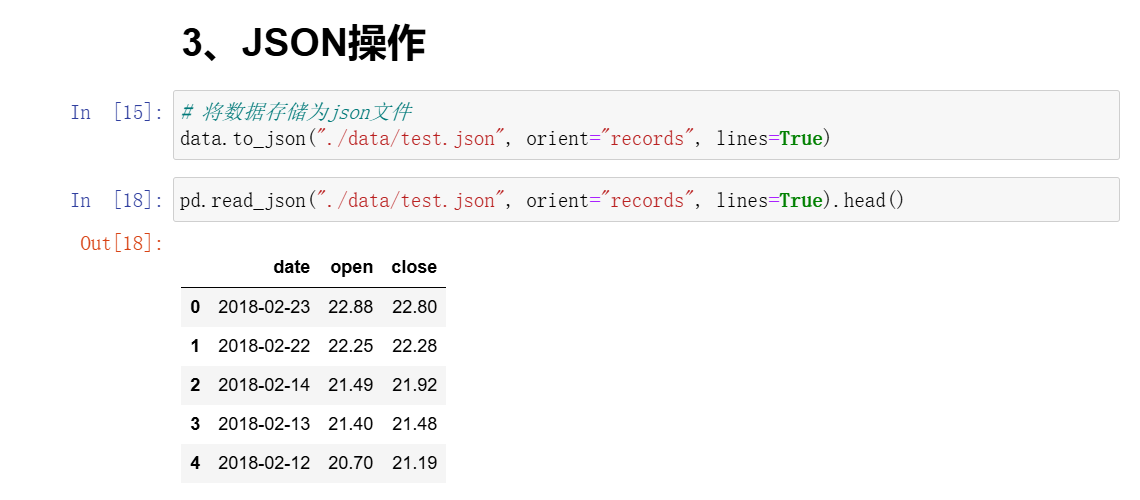
3、JSON

6、使用pandas连接数据库
1、安装sqlalchemy
2、使用read_sql()函数读取数据

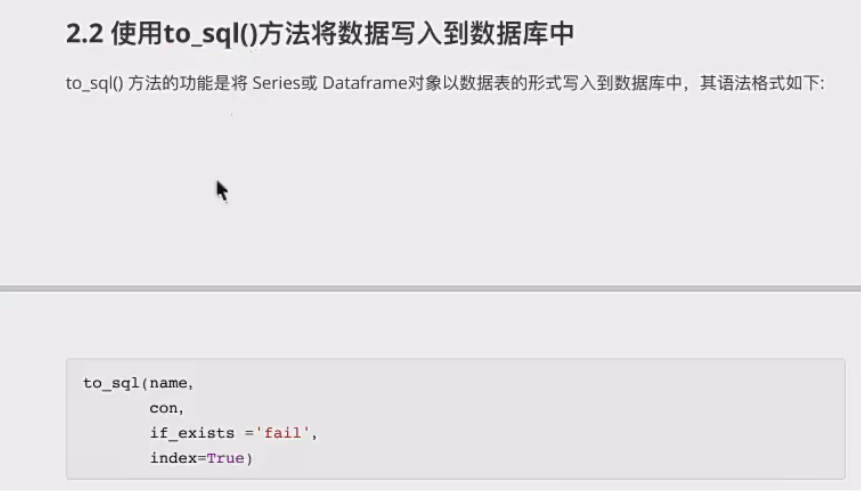
7、pandas高级用法
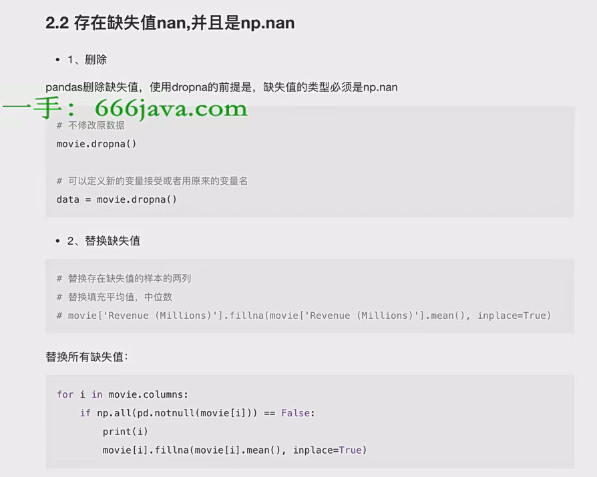
1、缺失值处理



2、数据离散化
-
1、为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数,离散化方法经常作为数据挖掘的工具 -
2、什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
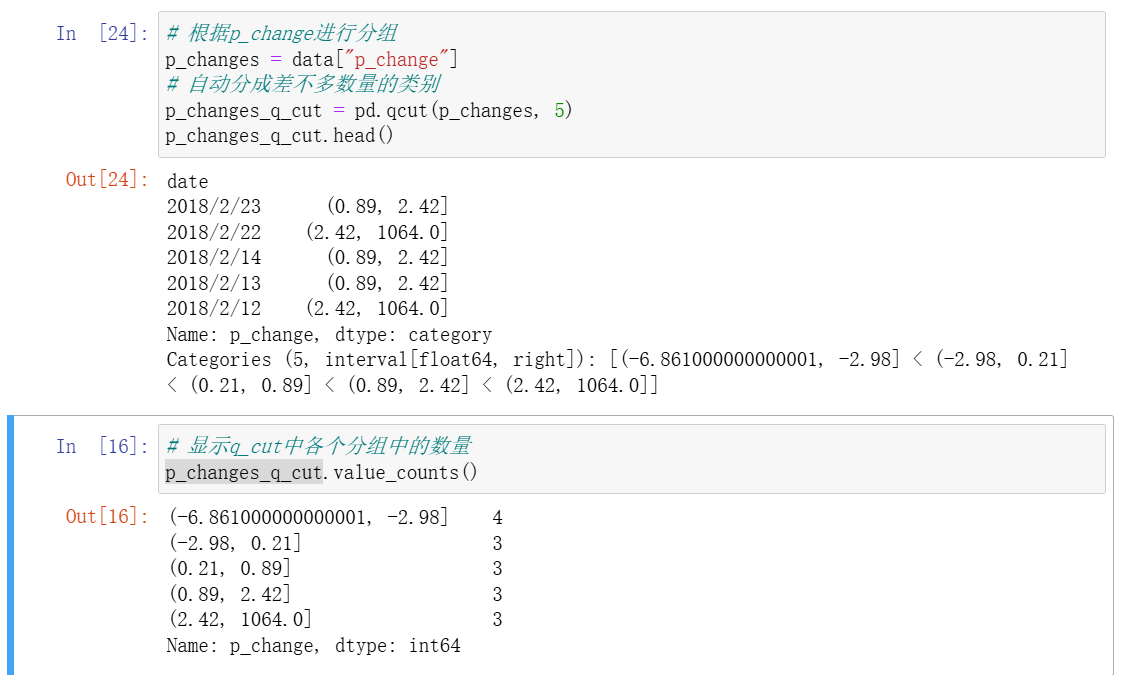
离散化有很多种方法,这使用一种最简单的方式去操作- 原始人的身高数据:165、174、160、180、159、163、192、184
- 假设我们按照身高分几个区间:150-165、165-180、180-195
这样我们将数据分到三个区间段,我们可以对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"的矩阵
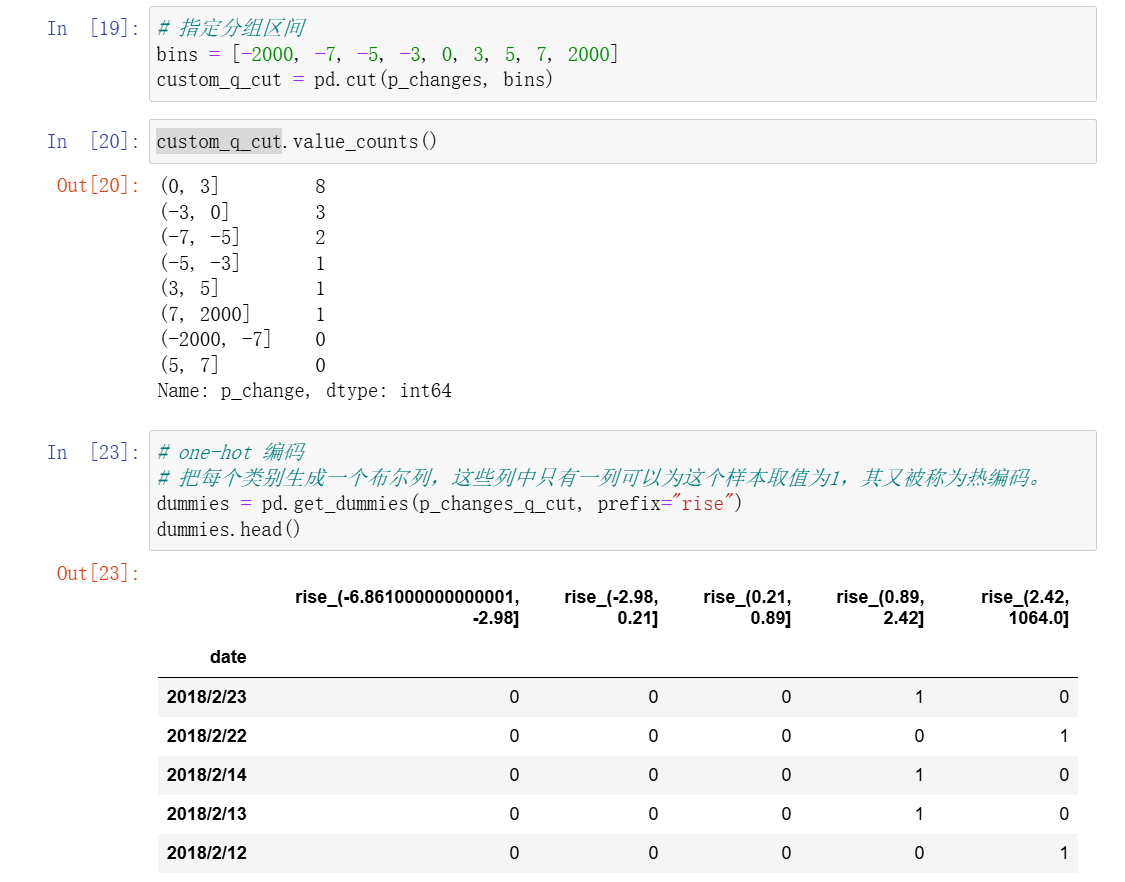
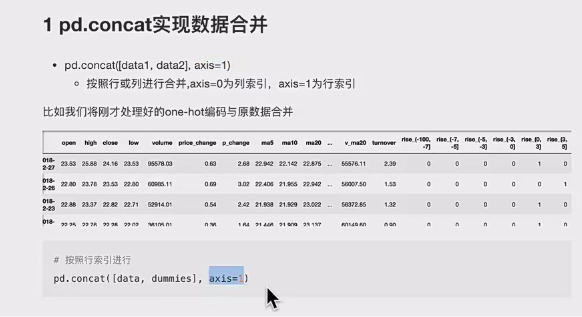
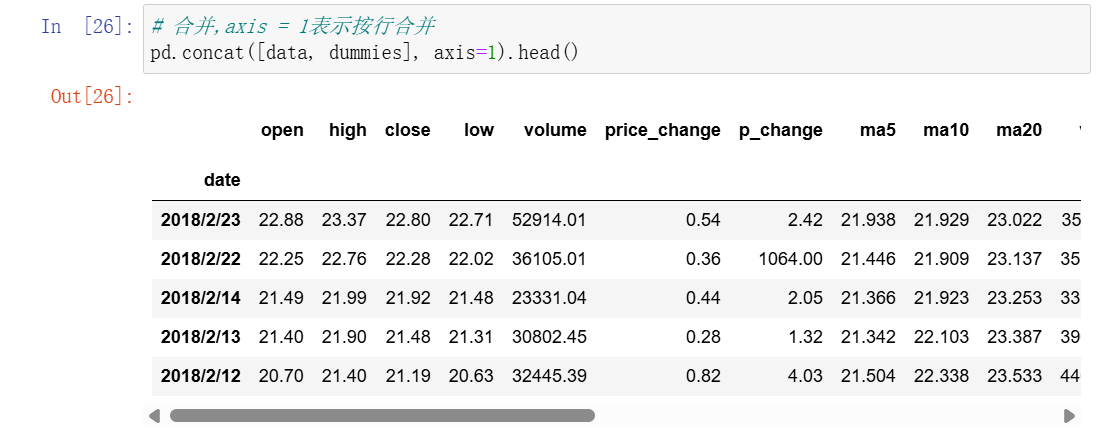
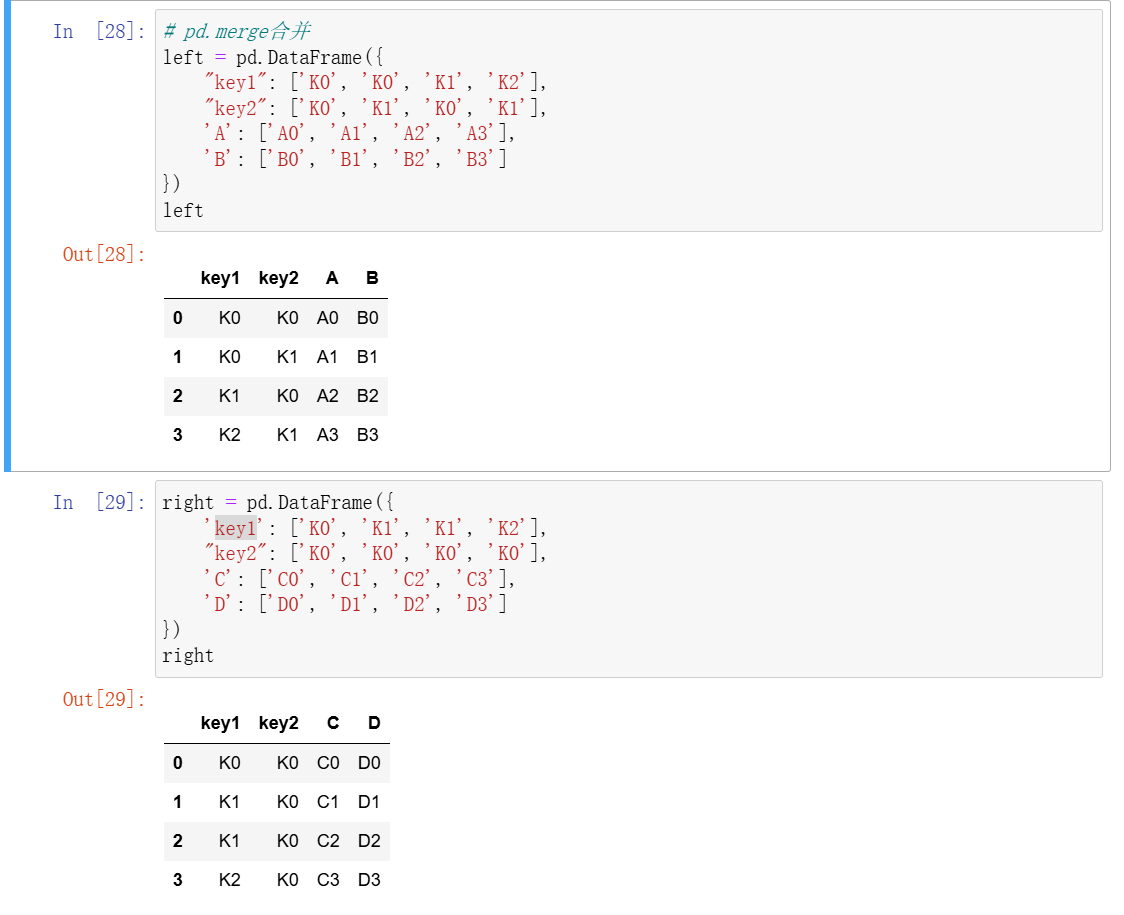
3、合并


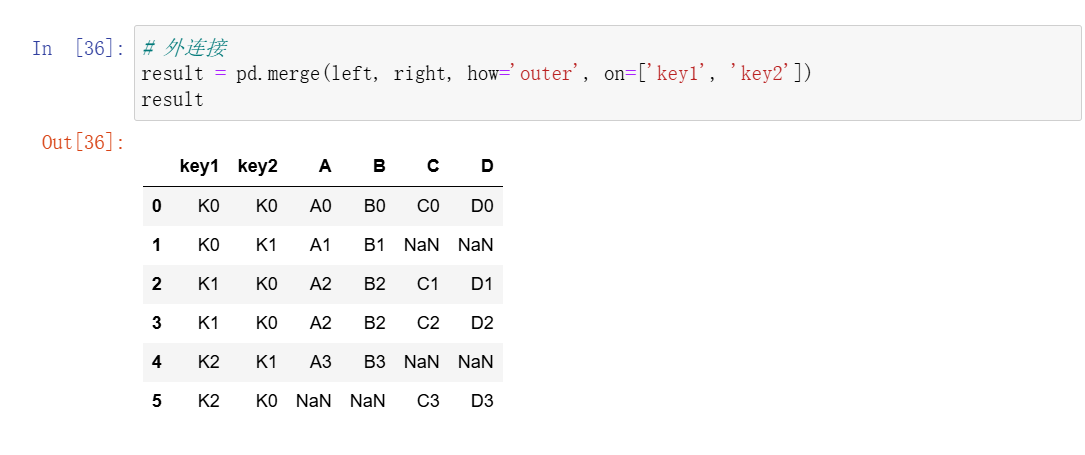
4、交叉表和透视表
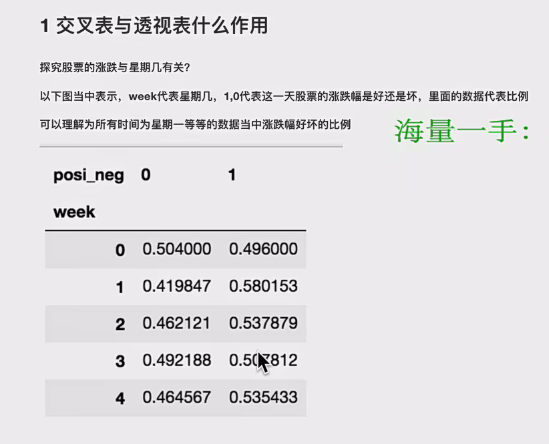
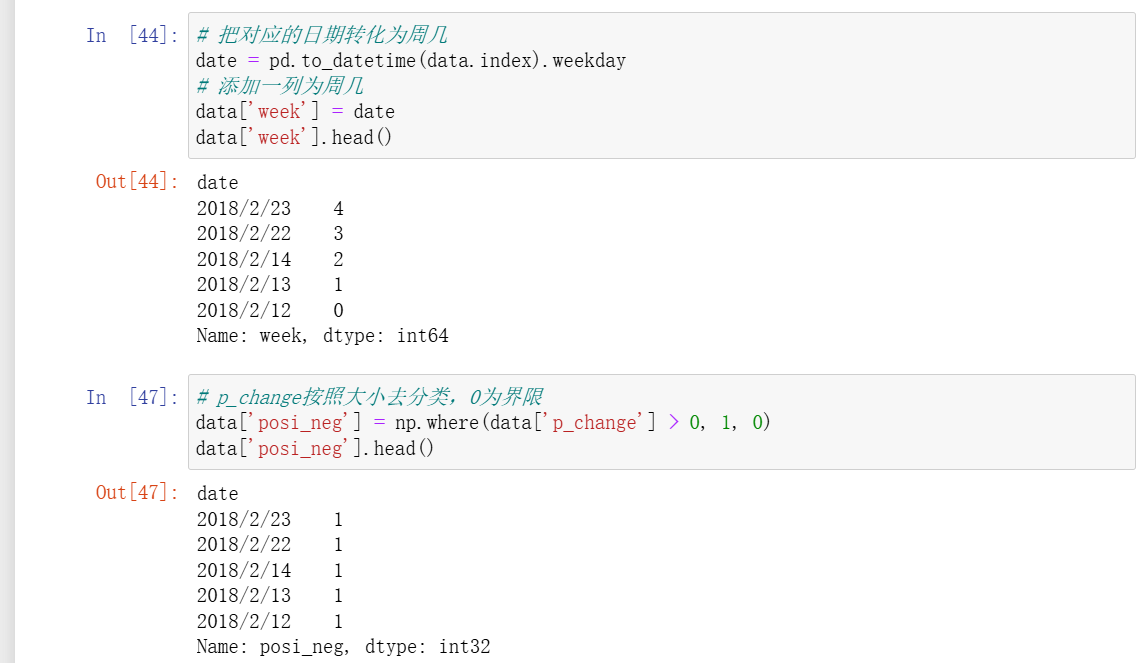
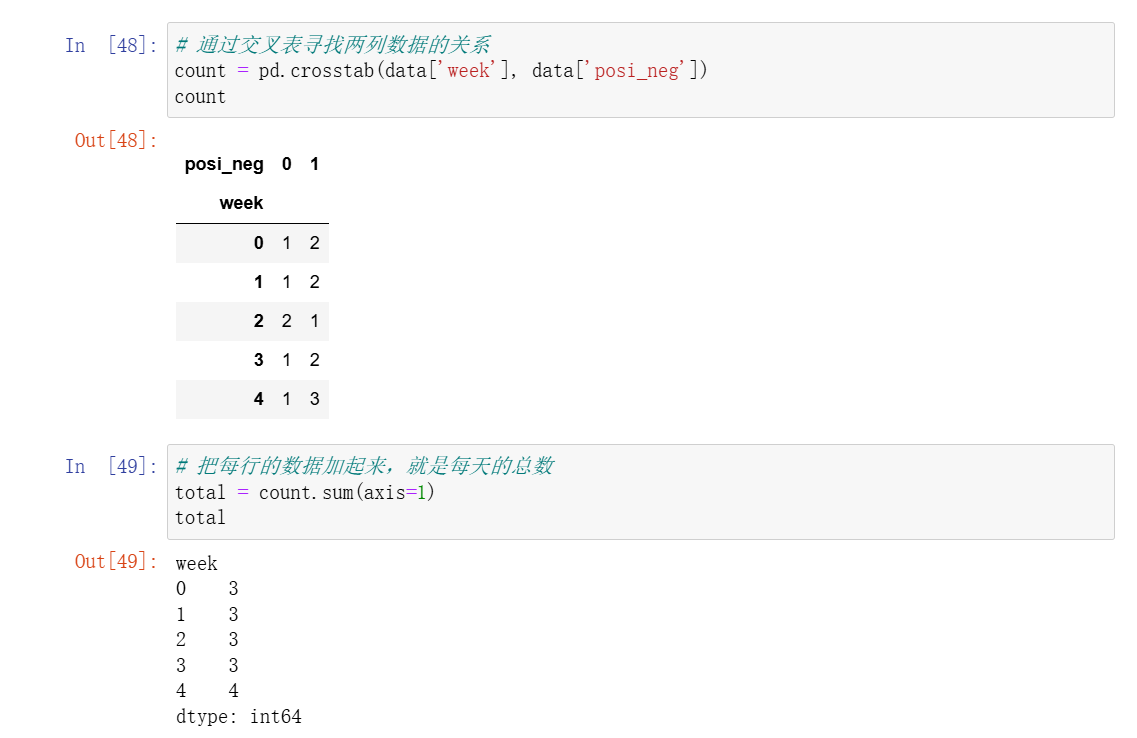
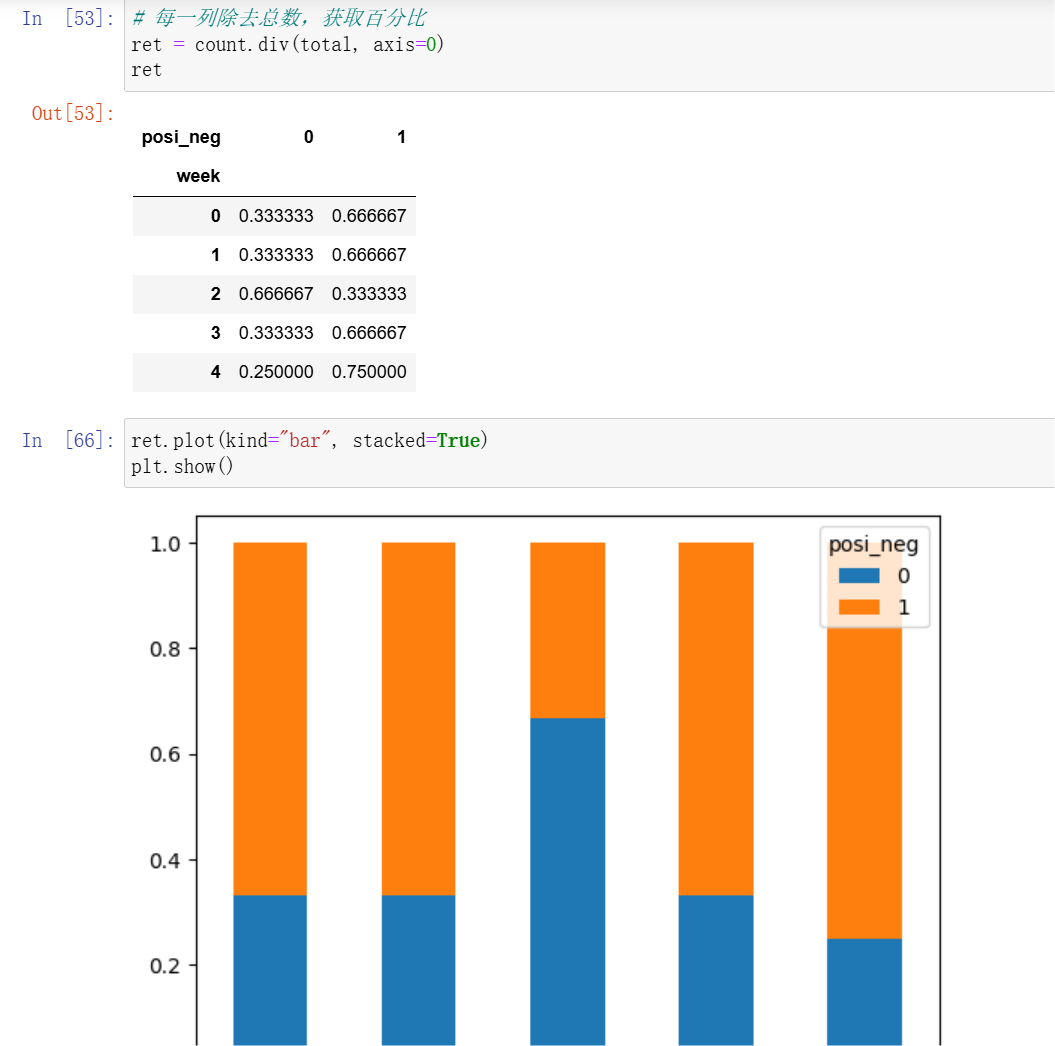
- 上面获取这个透视表的步骤,可以用一个函数代替
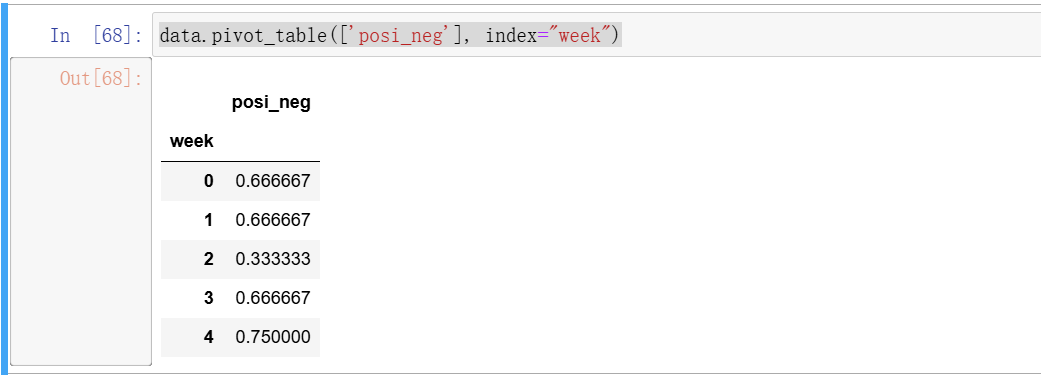
5、分组与聚合