大家好,我是铭毅天下,一名专注于 Elasticsearch (以下简称ES)技术栈的技术爱好者。

今天我们来聊聊球友提出的一个实际问题:
ES分页查询性能很差,使用from/size方式检索居然需要10分钟!

这是一个非常典型的问题,尤其在大数据量、多索引场景下特别常见。
我会从问题根源出发,逐步分析原因,并给出详细的优化方案和实现代码,希望能帮到遇到类似问题的朋友。
一、问题引出:为什么查询这么慢?
球友的场景是这样的:
他们通过ES的范围查询(range query)和排序(sort)从多个索引(applcation*)中分页检索数据,DSL如下:
curl -X POST "http://elasticsearch.elastic:9201/applcation*/_search" -H 'Content-Type: application/json' -d '
{
"from": 0,
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"from": "1743609600000",
"include_lower": true,
"include_upper": false,
"to": "1744214400000"
}
}
}
}
},
"size": 100,
"sort": [
{
"timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" }
},
{
"_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" }
}
]
}'这个查询的目标很简单:
从多个索引中查询时间戳在
1743609600000到1744214400000之间(约7天)的记录。按
timestamp和_uuid_降序排序。每次返回100条数据(
size=100),从第0条开始(from=0)。
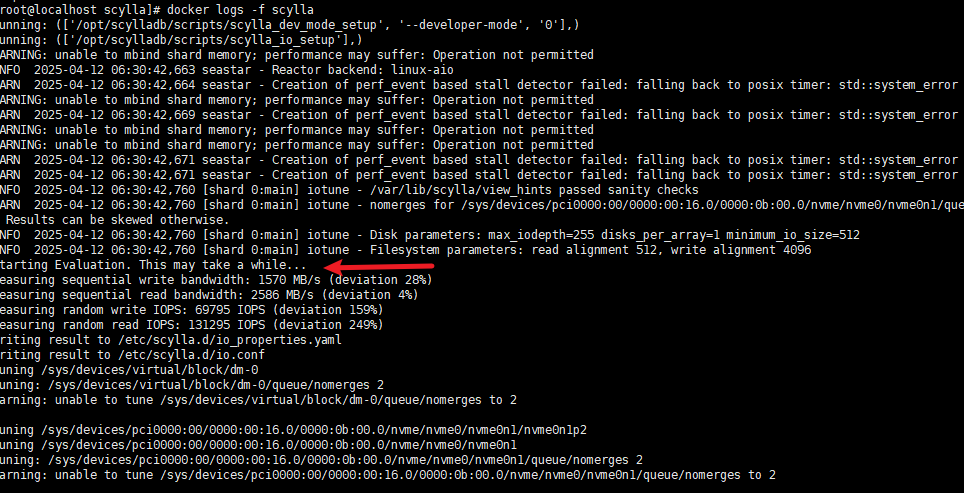
但问题来了:查询耗时高达10分钟(磁盘原因如下图说明,可以降到2分钟,但依然有很大优化空间)!

——铭毅补充说明:Elastic 集群最好独立部署!
更夸张的是,命中数据量达到了6亿多条 。这显然不是正常现象,我们得找到性能瓶颈。
二、问题分析:性能瓶颈在哪里?
通过DSL和聊天记录,我梳理出以下几个关键问题:
2.1 分页方式问题:from/size的深分页缺陷
ES的from/size分页是通过跳过前from条记录来实现的。当from很大时(比如翻到第10000页),ES需要在所有匹配的6亿条数据中排序后跳过大量记录,这会导致内存和计算资源的极大浪费。
干货 | 全方位深度解读 Elasticsearch 分页查询
当前from=0还不算深分页,但size=100结合6亿条命中数据,依然会触发大量数据扫描和排序。
2.2 数据范围过大:7天的数据量爆炸
时间戳范围从1743609600000(2025-03-01)到1744214400000(2025-03-08),整整7天。
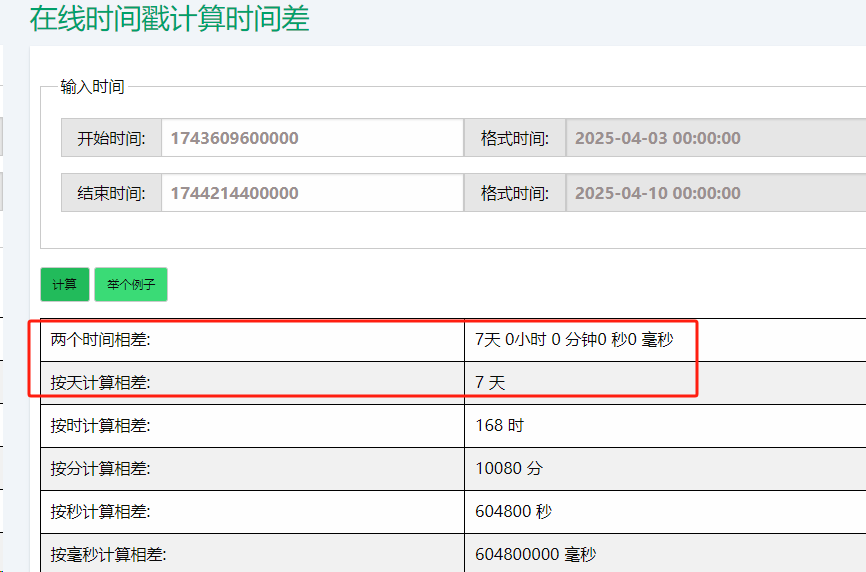
以6亿条命中数据计算,每天平均约8571万条,数据量非常恐怖。
ES需要扫描整个范围内的数据,即使加了filter,依然要处理海量记录。
2.3 多索引查询:通配符的性能隐患
使用applcation*通配符查询多个索引,可能涉及几十甚至上百个索引。
每个索引都需要独立扫描、分片计算,最终再合并结果,性能开销自然翻倍。
2.4 单次返回数据量:size=100的影响
每次返回100条数据不算多,但如果单条数据体积较大(比如包含复杂嵌套字段或大文本),网络传输和序列化开销会显著增加。
2.5 排序开销:双字段排序的代价
按timestamp和_uuid_排序需要对所有命中数据构建排序堆,
尤其在数据量大时,内存和CPU消耗会非常高。
总结一下:深分页+大范围数据+多索引+排序 ,这几大因素叠加,导致查询性能崩盘。接下来,我们探讨优化方案。
三、方案探讨:如何破局?
针对上述问题,我提出了三大优化方向,并结合ES的最佳实践,逐步解决问题:
3.1. 减少单次返回数据量
问题 :
size=100可能过大,尤其是单条数据体积大时。优化思路 :将
size调整为更小的值,比如10条(企业常见分页需求) ,减少每次返回的数据量。效果 :降低网络传输和序列化开销,同时减少排序堆的压力。
3.2. 缩小查询时间范围
问题 :7天的数据量高达6亿条,扫描范围过大。
优化思路 :引导用户缩短查询时间范围,比如从7天改为1天或几小时 。
效果 :大幅减少命中数据量,从根本上降低计算成本。
3.3. 替换分页方式:从from/size到search_after
问题 :
from/size不适合大数据量场景。优化思路 :使用
search_after,基于上一页的最后一条记录的排序值进行分页,避免深分页的性能问题。
效果 :查询时间从分钟级降到秒级,特别适合连续翻页场景。
3.4. 优化索引管理:引入别名机制
问题 :多索引通配符查询效率低,和“缩小查询时间范围”一致。。
优化思路 :为不同时间段的数据创建别名 (比如按天或按月),查询时指定具体别名而不是通配符。
效果 :减少扫描的索引数量,提升查询效率。
综合来看,这四个方向是层层递进的:先从简单调整(size和时间范围)入手,再到技术升级(search_after和别名)。
下面是具体实现。
四、方案实现:优化后的DSL与步骤
步骤1:调整size和时间范围
先尝试最简单的优化,将size从100改为10,时间范围从7天缩小到1天:
POST /applcation*/_search
{
"from": 0,
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"from": "1743609600000",
"include_lower": true,
"include_upper": false,
"to": "1743696000000" // 缩短为1天
}
}
}
}
},
"size": 10, // 减少返回条数
"sort": [
{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },
{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }
]
}效果推论:假设1天数据量为8571万条,命中量减少到原来的1/7,性能会有明显提升。
步骤2:切换到search_after
如果用户必须查询 7 天数据,且需要翻页,我们改用search_after。首次查询如下:
POST /applcation*/_search
{
"from": 0,
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"from": "1743609600000",
"include_lower": true,
"include_upper": false,
"to": "1743696000000" // 缩短为1天
}
}
}
}
},
"size": 10, // 减少返回条数
"sort": [
{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },
{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }
]
}返回结果中,记录最后一条数据的排序值,比如:
{
"hits": {
"hits": [
{"_source": {...}, "sort": ["1744214399999", "uuid123"]},
...
{"_source": {...}, "sort": ["1744214380000", "uuid456"]} // 最后一条
]
}
}下一页查询使用search_after:
POST /applcation*/_search
{
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"from": "1743609600000",
"include_lower": true,
"include_upper": false,
"to": "1744214400000"
}
}
}
}
},
"size": 10,
"search_after": ["1744214380000", "uuid456"], // 使用上一页最后一条的sort值
"sort": [
{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },
{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }
]
}注意 :search_after要求排序字段具有唯一性,这里用timestamp和_uuid_组合,确保结果稳定。
步骤3:引入别名机制
假设数据按天分索引(如applcation-2025-03-01),我们可以创建按天的别名:

POST /_aliases
{
"actions": [
{ "add": { "index": "applcation-2025-03-01", "alias": "applcation-day-20250301" } },
{ "add": { "index": "applcation-2025-03-02", "alias": "applcation-day-20250302" } }
]
}查询时指定别名:
POST /applcation-day-20250301/_search
{
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"from": "1743609600000",
"include_lower": true,
"include_upper": false,
"to": "1743696000000"
}
}
}
}
},
"size": 10,
"sort": [
{ "timestamp": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } },
{ "_uuid_": { "missing": "_last", "order": "desc", "unmapped_type": "keyword" } }
]
}效果 :只查询单日索引,扫描范围大幅缩小。
五、总结
从10分钟到秒级的蜕变通过以上优化,我们从多个角度解决了性能问题:
减少数据量——
size从100降到10,降低传输和计算压力。缩小时间范围——从7天到1天,命中数据量减少到1/7。
切换分页方式——
search_after替代from/size,彻底解决深分页问题。优化索引管理——别名机制减少多索引扫描开销。
实际效果如何?以6亿条数据为例:
原查询:扫描6亿条,排序后返回100条,耗时10分钟。
优化后:扫描单日8571万条,使用
search_after返回10条,耗时可能降到几秒。
最后给球友的建议:
如果用户需求固定,可以先尝试调整
size和时间范围。如果需要大数据量翻页,果断上
search_after。长远来看,优化索引设计(按时间分片+别名)是根本之道。
希望这篇文章能帮到大家,有问题欢迎随时交流!
我是铭毅天下,咱们下期见!
Composite 聚合——Elasticsearch 聚合后分页新实现
干货 | 全方位深度解读 Elasticsearch 分页查询
Elasticsearch聚合后分页深入详解

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!