3.内存管理
3.1 实验目的
对内存进一步的管理,实现动态的分配和释放。
-
实现 Page 级别的内存分配和释放。
-
在 page 分配的基础上实现更细颗粒度的,精确到字节为单位的内存管理。 (练习8.1)
void *malloc(size_t size); void free(void *ptr);
3.2 内存管理分类
- 自动管理内存 - 栈(stack)
- 静态内存 - 全局变量/静态变量
- 动态管理内存 - 堆(heap)
回看1.0里面为os添加的栈:
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
3.3 Linker Script 链接脚本
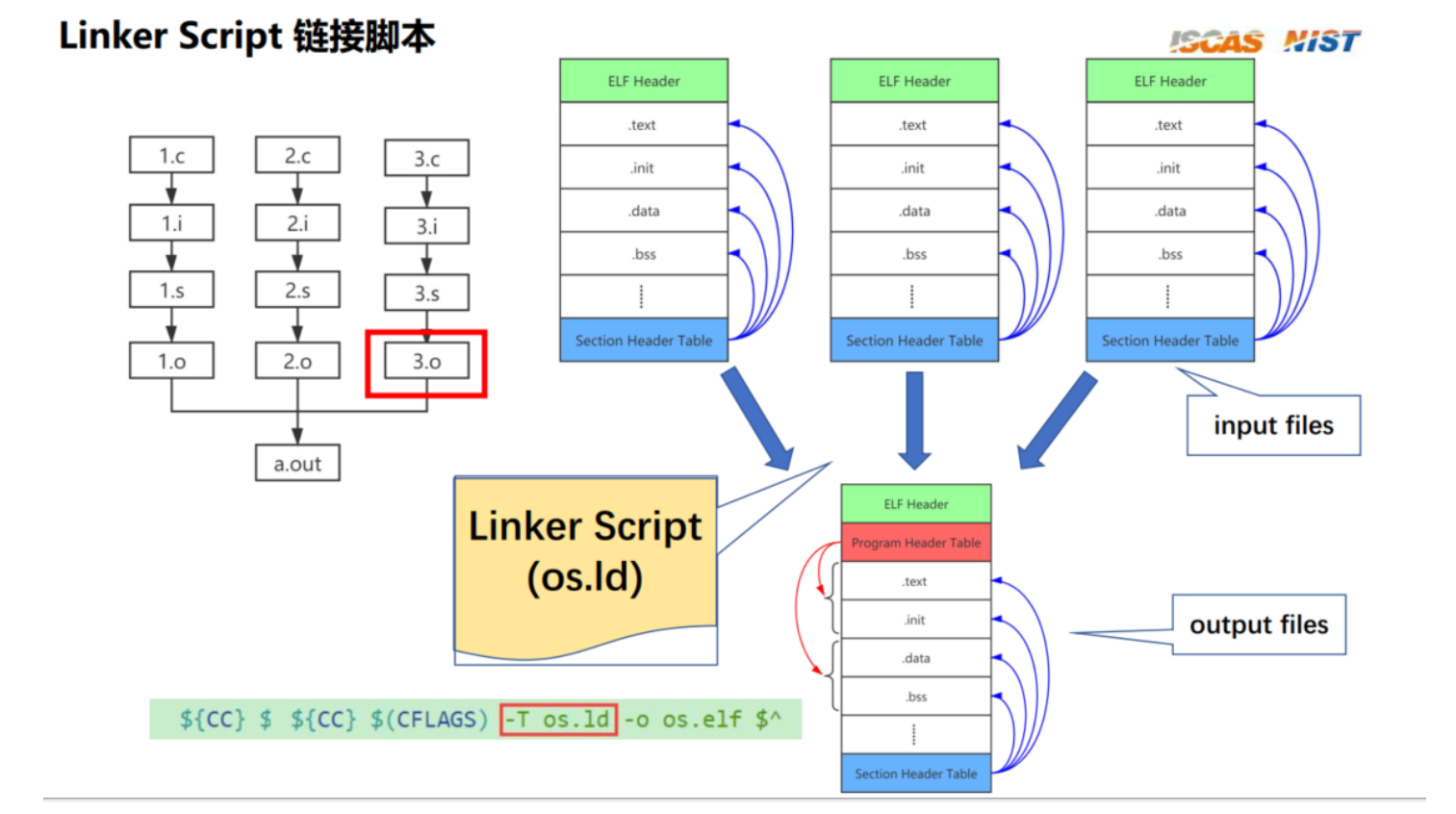
链接脚本的工作
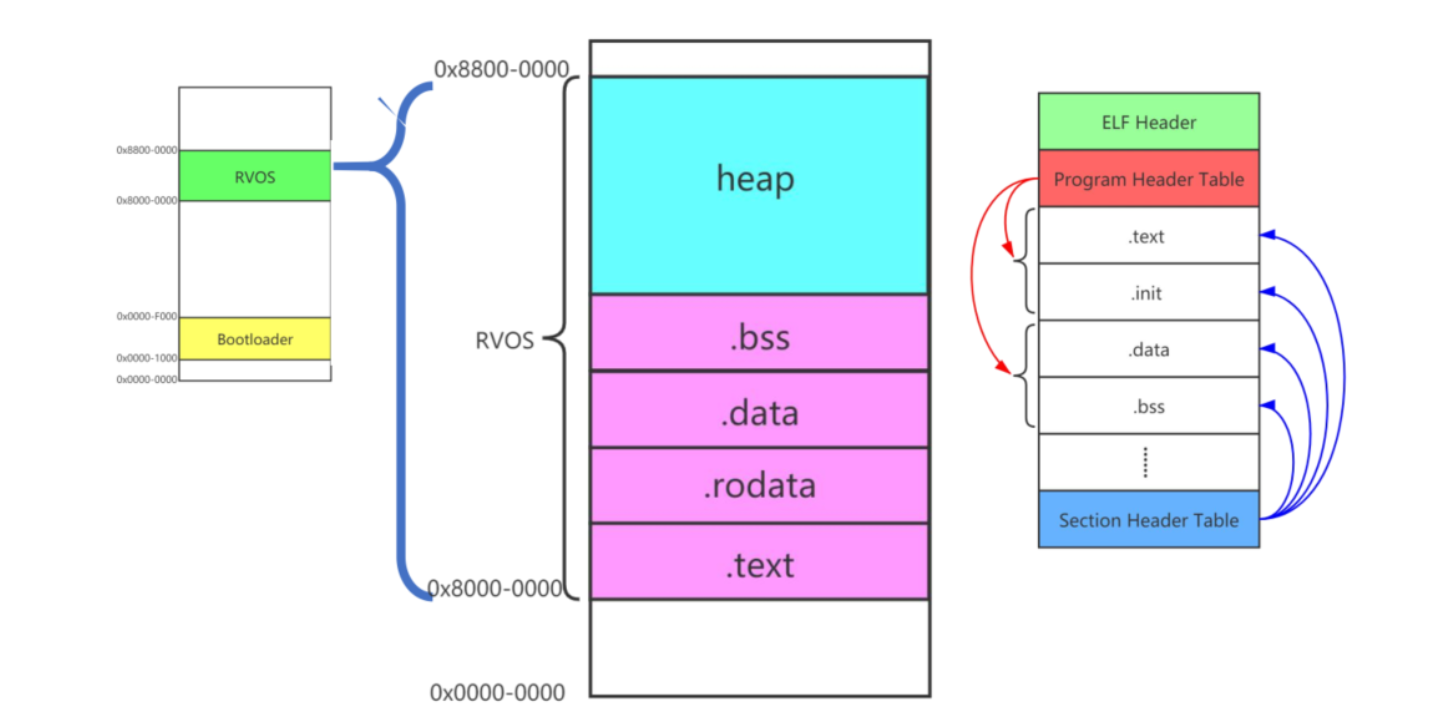
链接脚本在编译过程的主要任务:定义如何将多个目标文件(.o文件)合并成一个可执行文件或库文件。链接脚本通过指定输入文件的布局和输出文件的格式来控制链接器的行为。它定义了各个段(如.text、.data、.bss等)在最终输出文件中的排列和位置。此外,链接脚本还可以指定符号的地址、初始化代码的执行顺序等。通过编写链接脚本,开发者可以精细控制程序的内存布局,优化程序的性能和安全性。
从多个.o文件到最终的elf文件的过程:
从多个目标文件(.o文件)到最终的可执行文件(elf文件)的过程可以分为以下几个步骤:
-
编译源代码:首先,源代码文件(如.c文件)被编译器编译成目标文件(.o文件)。每个目标文件包含了源代码编译后的机器指令和数据。
-
链接目标文件:接下来,链接器将多个目标文件合并成一个单一的可执行文件。在这个过程中,链接器会解析目标文件中的符号引用,将它们解析为具体的地址,并解决符号之间的依赖关系。
-
使用链接脚本:链接器使用链接脚本来指导目标文件的合并过程。链接脚本定义了最终可执行文件的内存布局,包括各个段(如.text、.data、.bss等)的位置和大小。
-
生成可执行文件:经过链接和布局后,链接器生成最终的可执行文件(elf文件)。这个文件包含了程序的机器指令、数据、符号表等信息,可以被操作系统加载和执行。
ELF文件简介
ELF(Executable and Linkable Format)文件是Linux系统中常用的可执行文件格式。它由以下几个主要部分组成:
-
ELF Header:这是文件的头部,包含了文件的基本信息,如文件类型、架构、入口点地址、程序头表和节头表的位置等。
-
Program Header Table(程序头表):这个表描述了文件中各个段的布局信息,包括段的类型、文件偏移、内存偏移、大小等。操作系统使用这个表来加载程序。
-
Section Header Table(节头表):这个表描述了文件中各个节的布局信息,包括节的名称、大小、地址、类型等。链接器和调试器使用这个表来访问文件中的特定节。
-
.text段:这个段包含了程序的可执行代码。操作系统在加载程序时,会将这个段的内容复制到内存中。
-
.data段:这个段包含了程序的已初始化全局变量和静态变量。操作系统在加载程序时,会将这个段的内容复制到内存中,并初始化变量的值。
-
.bss段:这个段包含了程序的未初始化全局变量和静态变量。操作系统在加载程序时,会为这个段分配内存,但不初始化变量的值。
-
.init段:这个段包含了程序的初始化代码。在程序启动时,操作系统会执行这个段中的代码来初始化程序。
通过这些部分的协同工作,ELF文件能够被操作系统正确加载和执行,从而实现程序的功能。
3.4 Linker Script 链接脚本语法
| 指令 | 语法 | 例子 | 说明 |
|---|---|---|---|
| ENTRY | ENTRY(symbol) | ENTRY(_start) | ENTRY 命令用于设置“入口点 (entry point)”,即程序中执行的第一条指令。ENTRY 命令的参数是一个符号(symbol)的名称。 |
| OUTPUT_ARCH | OUTPUT_ARCH(bfdarch) | OUTPUT_ARCH(“riscv”) | OUTPUT_ARCH 命令指定输出文件所适用的计算机体系架构。 |
| MEMORY | MEMORY { name [( attr )] : ORIGIN = origin, LENGTH = len } | MEMORY { rom (rx) : ORIGIN = 0, LENGTH = 256K ram (!rx) : org = 0x40000000, l = 4M } | MEMORY 用于描述目标机器上内存区域的位置、大小和相关属性。 |
| SECTIONS | SECTIONS { sections-command sections-command } | SECTIONS { . = 0x10000; .text : { *(.text) } . = 0x8000000; .data : { *(.data) } .bss : { *(.bss) } } > ram | SECTIONS 告诉链接器如何将 input sections 映射到 output sections,以及如何将 output sections 放置在内存中。section-command 除了可以是对 out section 的描述外还可以是符号赋值命令等其他形式。 |
| PROVIDE | PROVIDE(symbol = expression) | PROVIDE(_text_start = .) | 可以在 Linker Script 中定义符号(Symbols),每个符号包括一个名字(name)和一个对应的地址值(address),在代码中可以访问这些符号,等同于访问一个地址。 |
3.5 获得各个sections在内存中的地址
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
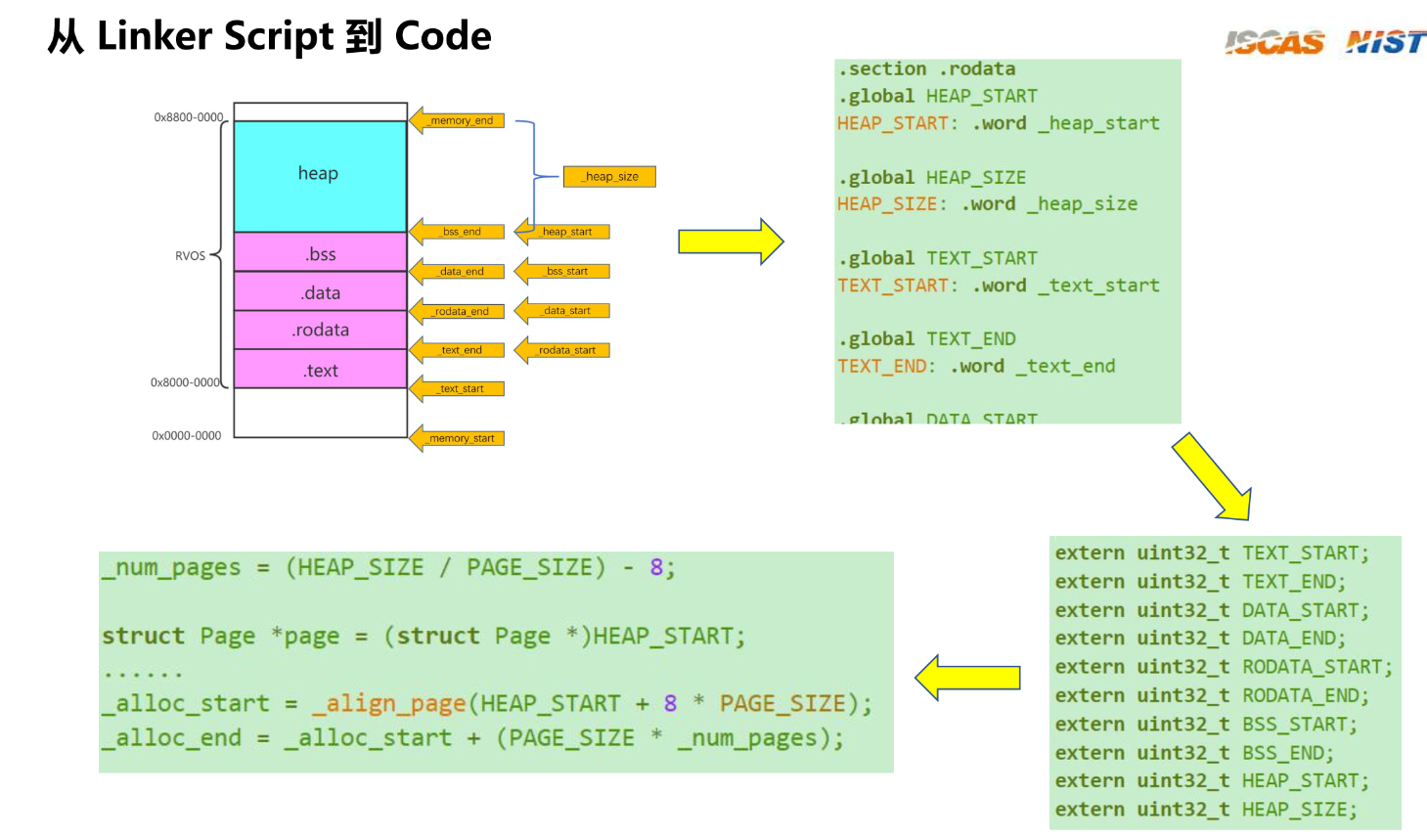
/*
* rvos.ld
* Linker script for outputting to RVOS
*/
#include "platform.h"
OUTPUT_ARCH( "riscv" )
ENTRY( _start )
MEMORY
{
ram (wxa!ri) : ORIGIN = 0x80000000, LENGTH = LENGTH_RAM
}
SECTIONS
{
/*
* We are going to layout all text sections in .text output section,
* starting with .text. The asterisk("*") in front of the
* parentheses means to match the .text section of ANY object file.
*/
.text : {
PROVIDE(_text_start = .);
*(.text .text.*) /* 将所有名为 .text 的段以及所有以 .text 开头的命名段从输入文件中选取出来,
并按它们在输入文件中的原始顺序将它们放置到输出文件的 .text 段中*/
PROVIDE(_text_end = .);
} >ram
.rodata : {
PROVIDE(_rodata_start = .);
*(.rodata .rodata.*) /* 将所有名为 .rodata 的段以及所有以 .rodata 开头的命名段从输入文件中选取出来,
并按它们在输入文件中的原始顺序将它们放置到输出文件的 .rodata 段中*/
PROVIDE(_rodata_end = .);
} >ram
.data : {
. = ALIGN(4096);
PROVIDE(_data_start = .);
/*
* sdata and data are essentially the same thing. We do not need
* to distinguish sdata from data.
*/
*(.sdata .sdata.*)
*(.data .data.*)
PROVIDE(_data_end = .);
} >ram
.bss :{
/*
* https://sourceware.org/binutils/docs/ld/Input-Section-Common.html
* In most cases, common symbols in input files will be placed
* in the ‘.bss’ section in the output file.-->全局变量
*/
PROVIDE(_bss_start = .);
*(.sbss .sbss.*)
*(.bss .bss.*)
*(COMMON)
PROVIDE(_bss_end = .);
} >ram
PROVIDE(_memory_start = ORIGIN(ram));
PROVIDE(_memory_end = ORIGIN(ram) + LENGTH(ram));
PROVIDE(_heap_start = _bss_end);
PROVIDE(_heap_size = _memory_end - _heap_start);
}
/*
* mem.S
*/
#define SIZE_PTR .word
.section .rodata
.global HEAP_START
HEAP_START: SIZE_PTR _heap_start
.global HEAP_SIZE
HEAP_SIZE: SIZE_PTR _heap_size
.global TEXT_START
TEXT_START: SIZE_PTR _text_start
.global TEXT_END
TEXT_END: SIZE_PTR _text_end
.global DATA_START
DATA_START: SIZE_PTR _data_start
.global DATA_END
DATA_END: SIZE_PTR _data_end
.global RODATA_START
RODATA_START: SIZE_PTR _rodata_start
.global RODATA_END
RODATA_END: SIZE_PTR _rodata_end
.global BSS_START
BSS_START: SIZE_PTR _bss_start
.global BSS_END
BSS_END: SIZE_PTR _bss_end
顺序和链接过程
- 汇编汇编代码:首先,汇编器处理
mem.S文件,生成一个目标文件(.o 文件)。在这个过程中,.global关键字使得HEAP_START、HEAP_SIZE等符号在链接时对链接器可见。- 链接目标文件:然后,链接器处理所有目标文件,包括
mem.S生成的目标文件和其他目标文件。链接器使用链接脚本rvos.ld来确定如何将这些目标文件中的段合并成最终的可执行文件。- 符号解析:在链接过程中,链接器解析
mem.S中引用的符号(如_heap_start),并将其替换为链接脚本中定义的实际地址。- 生成可执行文件:最终,链接器生成一个包含所有段和符号的可执行文件。在这个文件中,
.rodata段包含了HEAP_START、HEAP_SIZE等符号的值,这些值是在链接脚本中定义的。
3.6 实现 Page 级别的内存分配和释放
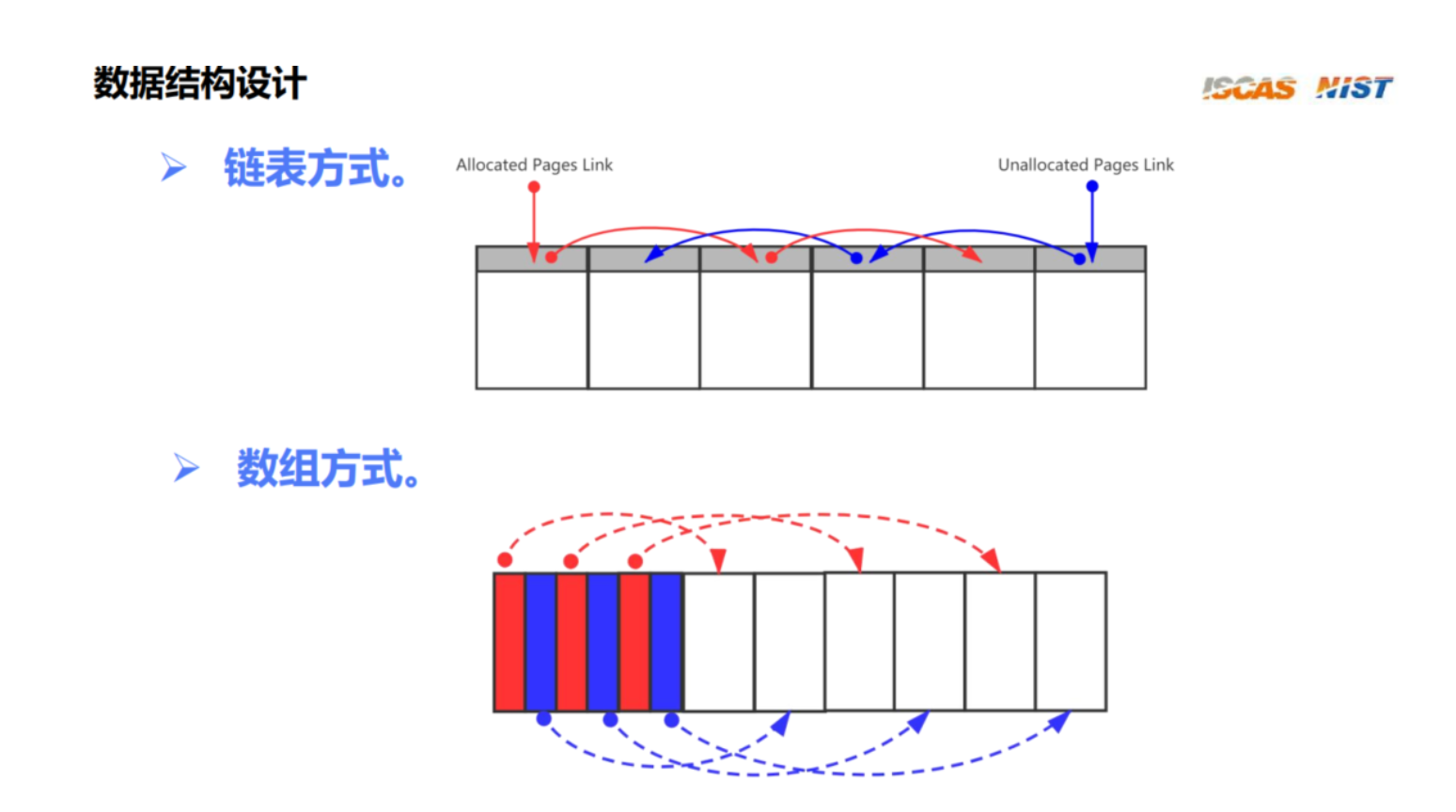
• 数据结构设计
• Page 分配和释放接口设计
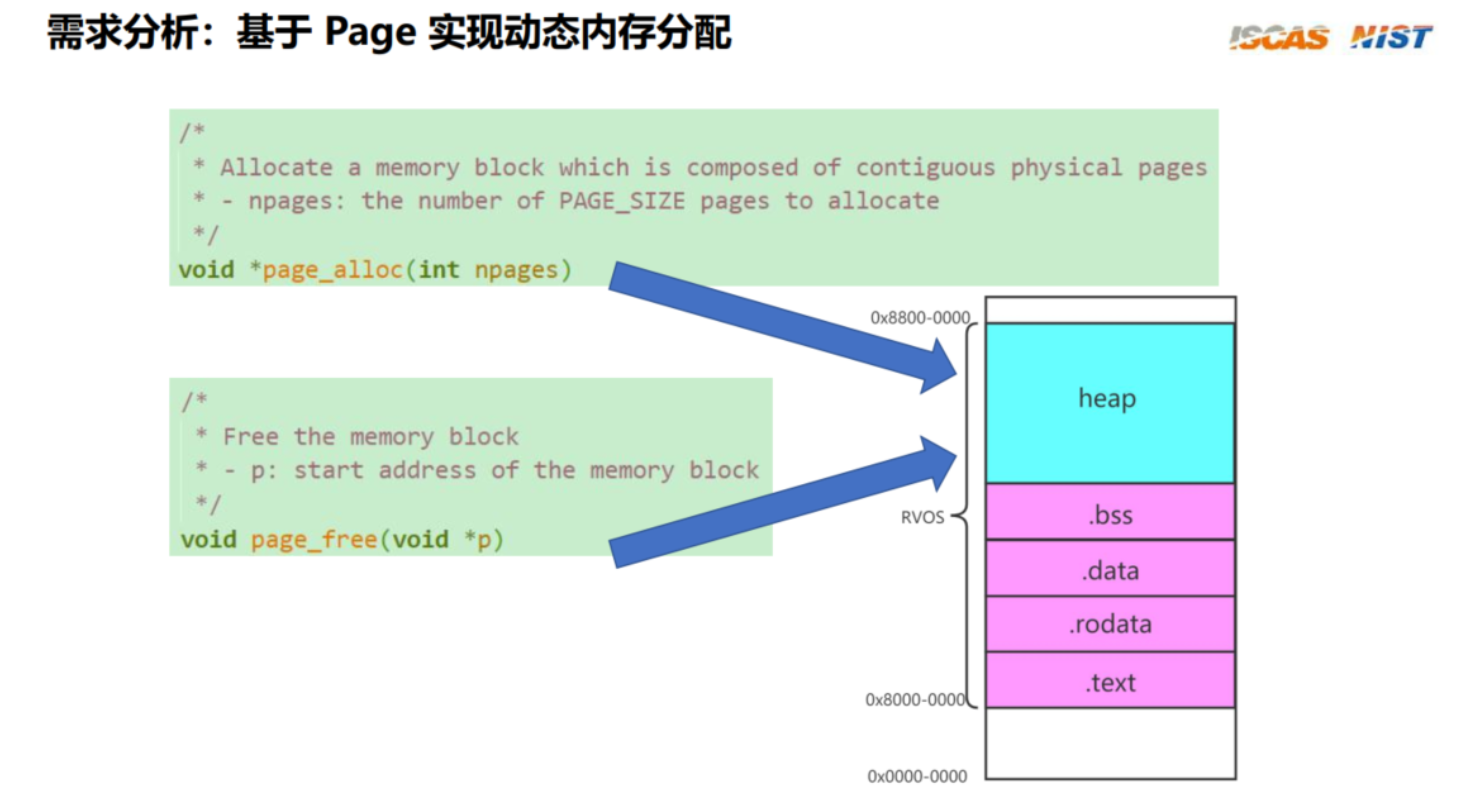
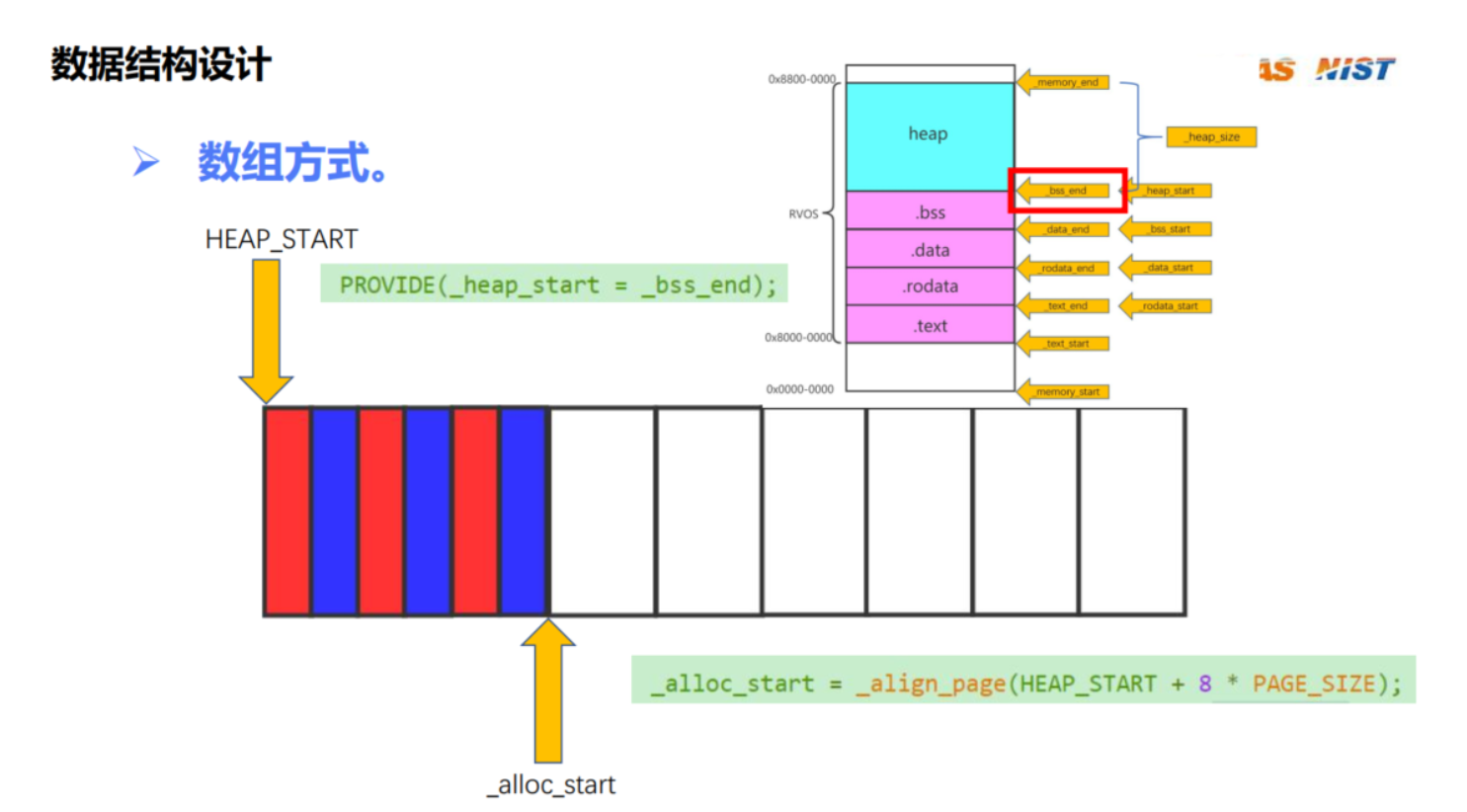
#include "os.h"
extern ptr_t TEXT_START;
extern ptr_t TEXT_END;
extern ptr_t DATA_START;
extern ptr_t DATA_END;
extern ptr_t RODATA_START;
extern ptr_t RODATA_END;
extern ptr_t BSS_START;
extern ptr_t BSS_END;
extern ptr_t HEAP_START;
extern ptr_t HEAP_SIZE;
/*
* _alloc_start points to the actual start address of heap pool
* _alloc_end points to the actual end address of heap pool
* _num_pages holds the actual max number of pages we can allocate.
*/
static ptr_t _alloc_start = 0;
static ptr_t _alloc_end = 0;
static uint32_t _num_pages = 0;
#define PAGE_SIZE 4096
#define PAGE_ORDER 12
/*
* Page Descriptor
* flags:
* - bit 0: flag if this page is taken(allocated)
* - bit 1: flag if this page is the last page of the memory block allocated
*/
#define PAGE_TAKEN (uint8_t)(1 << 0)
#define PAGE_LAST (uint8_t)(1 << 1)
struct Page {
uint8_t flags;
};
/* inline内联函数,建议编译器在编译时将函数的定义直接插入
* 到每个函数调用的地方,而不是进行常规的函数调用。
* 这样可以减少函数调用的开销,提高程序的执行效率。
* 但是,内联函数的使用也有一些限制和注意事项:
* 1. 内联函数的代码会被插入到每个调用的地方,这可能会导致代码膨胀,增加可执行文件的大小。
* 2. 内联函数不能包含循环、递归或复杂的控制结构,因为这些结构可能导致编译器无法确定内联的边界。
* 3. 内联函数不能有静态变量,因为静态变量在每个调用中都需要保持状态,而内联函数的代码在每个调用中都是独立的。
* 4. 内联函数不能有可变参数列表,因为编译器无法确定参数的数量和类型。
*/
static inline void _clear(struct Page *page)
{
page->flags = 0;
}
static inline void _set_flag(struct Page *page, uint8_t flags)
{
page->flags |= flags;
}
static inline int _is_free(struct Page *page)
{
if (page->flags & PAGE_TAKEN) {
return 0;
} else {
return 1;
}
}
static inline int _is_last(struct Page *page)
{
if (page->flags & PAGE_LAST) {
return 1;
} else {
return 0;
}
}
/*
* align the address to the border of page(4K)
*/
static inline ptr_t _align_page(ptr_t address)
{
ptr_t order = (1 << PAGE_ORDER) - 1;
return (address + order) & (~order);
}
/*
* ______________________________HEAP_SIZE_______________________________
* / ___num_reserved_pages___ ______________num_pages______________ \
* / / \ / \ \
* |---|<--Page-->|<--Page-->|...|<--Page-->|<--Page-->|......|<--Page-->|---|
* A A A A A
* | | | | |
* | | | | _memory_end
* | | | |
* | _heap_start_aligned _alloc_start _alloc_end
* HEAP_START(BSS_END)
*
* Note: _alloc_end may equal to _memory_end.
*/
void page_init()
{
ptr_t _heap_start_aligned = _align_page(HEAP_START);
/*
* We reserved some Pages to hold the Page structures.
* The number of reserved pages depends on the LENGTH_RAM.
* For simplicity, the space we reserve here is just an approximation,
* assuming that it can accommodate the maximum LENGTH_RAM.
* We assume LENGTH_RAM should not be too small, ideally no less
* than 16M (i.e. PAGE_SIZE * PAGE_SIZE).
*/
uint32_t num_reserved_pages = LENGTH_RAM / (PAGE_SIZE * PAGE_SIZE);
_num_pages = (HEAP_SIZE - (_heap_start_aligned - HEAP_START))/ PAGE_SIZE - num_reserved_pages;
printf("HEAP_START = %p(aligned to %p), HEAP_SIZE = 0x%lx,\n"
"num of reserved pages = %d, num of pages to be allocated for heap = %d\n",
HEAP_START, _heap_start_aligned, HEAP_SIZE,
num_reserved_pages, _num_pages);
/*
* We use HEAP_START, not _heap_start_aligned as begin address for
* allocating struct Page, because we have no requirement of alignment
* for position of struct Page.
* 初始化范围为HEAP_START---> num_pages * sizeof(struct Page)
*/
struct Page *page = (struct Page *)HEAP_START;
for (int i = 0; i < _num_pages; i++) {
_clear(page);
page++;
}
_alloc_start = _heap_start_aligned + num_reserved_pages * PAGE_SIZE;
_alloc_end = _alloc_start + (PAGE_SIZE * _num_pages);
printf("TEXT: %p -> %p\n", TEXT_START, TEXT_END);
printf("RODATA: %p -> %p\n", RODATA_START, RODATA_END);
printf("DATA: %p -> %p\n", DATA_START, DATA_END);
printf("BSS: %p -> %p\n", BSS_START, BSS_END);
printf("HEAP: %p -> %p\n", _alloc_start, _alloc_end);
}
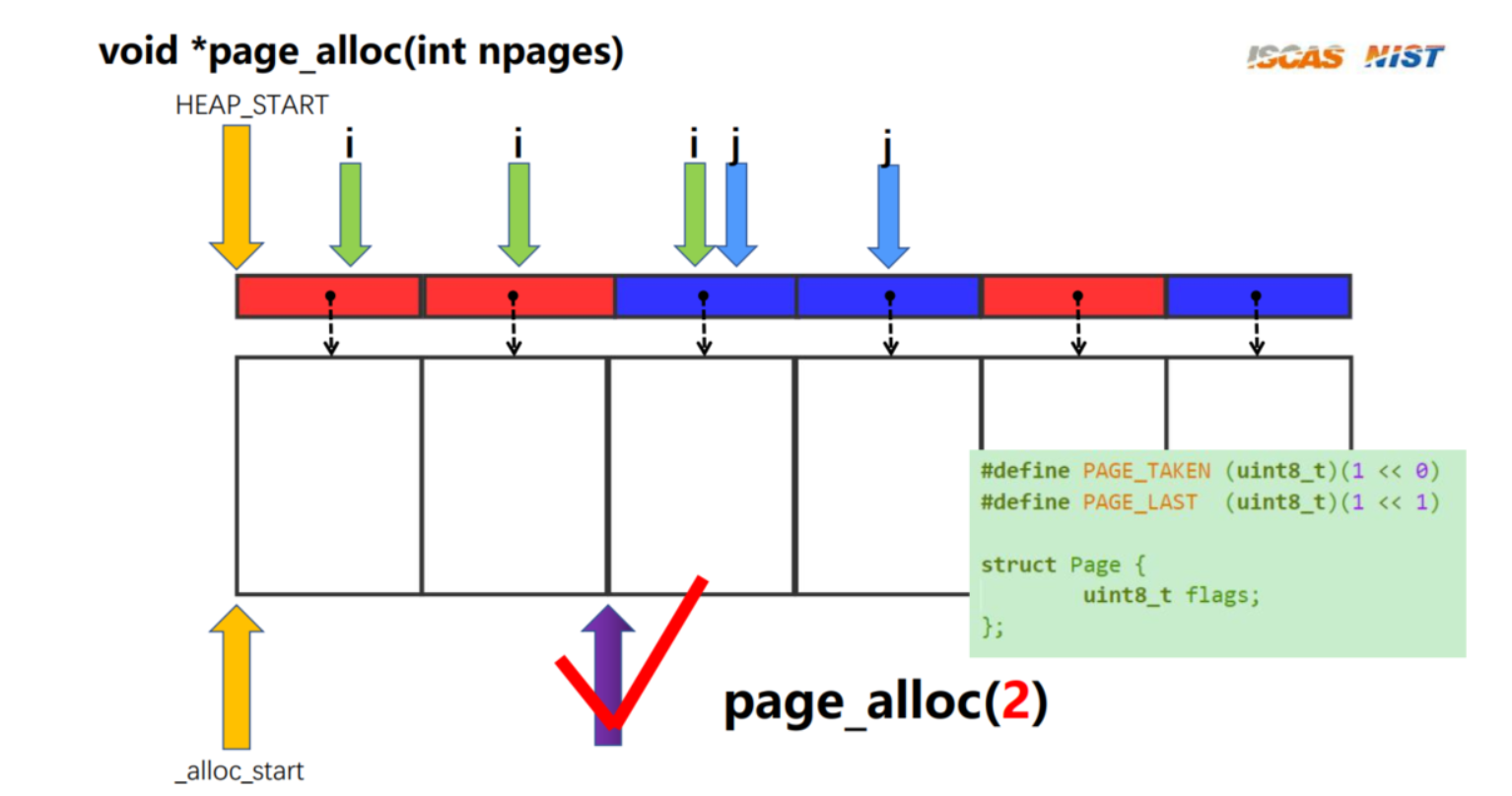
下面实现Page 级别的内存分配和释放:**void** *page_alloc(**int** npages)、**void** page_free(**void** *p):
/*
* Allocate a memory block which is composed of contiguous physical pages
* - npages: the number of PAGE_SIZE pages to allocate
*/
void *page_alloc(int npages)
{
/* Note we are searching the page descriptor bitmaps. */
int found = 0;
struct Page *page_i = (struct Page *)HEAP_START;
for (int i = 0; i <= (_num_pages - npages); i++) {
if (_is_free(page_i)) {
found = 1;
/*
* meet a free page, continue to check if following
* (npages - 1) pages are also unallocated.
*/
struct Page *page_j = page_i + 1;
for (int j = i + 1; j < (i + npages); j++) {
if (!_is_free(page_j)) {
found = 0;
break;
}
page_j++;
}
/*
* get a memory block which is good enough for us,
* take housekeeping, then return the actual start
* address of the first page of this memory block
*/
if (found) {
struct Page *page_k = page_i;
for (int k = i; k < (i + npages); k++) {
_set_flag(page_k, PAGE_TAKEN);
page_k++;
}
page_k--;
_set_flag(page_k, PAGE_LAST);
return (void *)(_alloc_start + i * PAGE_SIZE);
}
}
page_i++;
}
return NULL;
}
/*
* Free the memory block
* - p: start address of the memory block
*/
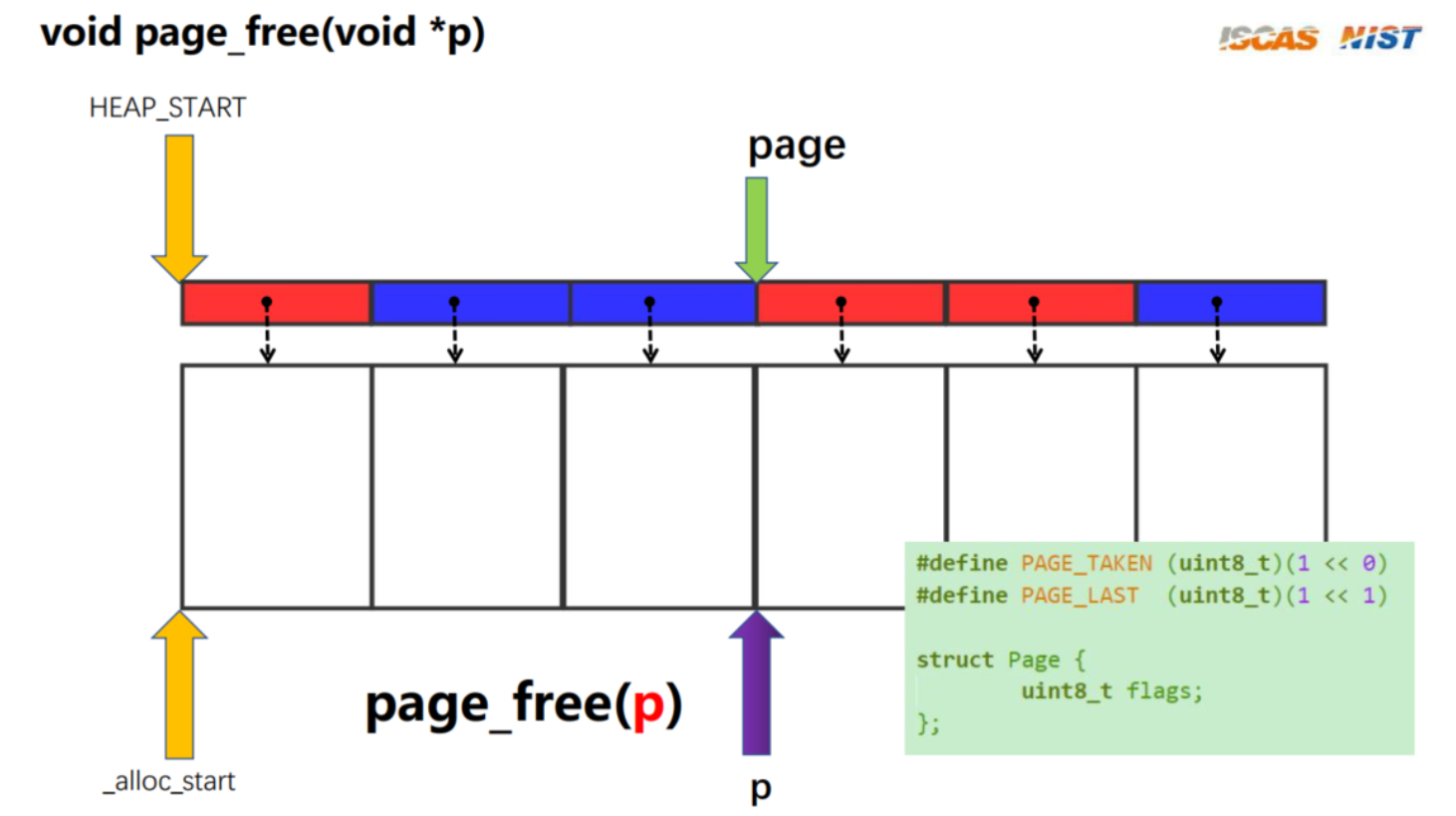
void page_free(void *p)
{
/*
* Assert (TBD) if p is invalid
*/
if (!p || (ptr_t)p >= _alloc_end) {
return;
}
/* get the first page descriptor of this memory block */
struct Page *page = (struct Page *)HEAP_START;
page += ((ptr_t)p - _alloc_start)/ PAGE_SIZE;
/* loop and clear all the page descriptors of the memory block */
while (!_is_free(page)) {
if (_is_last(page)) {
_clear(page);
break;
} else {
_clear(page);
page++;;
}
}
}
这里写的都非常简单且没有优化,后续有时间试着再改一下吧。
3.7 实现字节为单位的内存管理
- 需求:
- 实现字节级的内存管理,允许动态分配和释放任意大小的内存块,减少内存碎片。
- 策略:
- 对齐:为了避免未对齐访问问题,分配的内存块大小对齐到 8 字节。
- 块头部:每个内存块前有一个
BlockHeader,记录块的大小、状态和链表指针。 - 分割块:当找到的空闲块比请求的大小大时,将其分割为两个块。
- 合并块:在释放内存时,尝试合并相邻的空闲块以减少碎片化。
- 首次适配算法:遍历空闲链表,找到第一个满足条件的块。
/*
* 字节为单位的内存管理策略:
* 该策略通过将内存划分为固定大小的块,
* 并使用链表来管理这些块的分配和释放。
* 每个块包含一个头部(BlockHeader),用于记录块的大小、是否空闲以及指向下一个块的指针。
* 内存分配时,会从空闲块链表中查找合适的块,并在必要时分割块以满足请求。
* 释放内存时,会将块标记为“空闲”,并尝试合并相邻的空闲块以减少内存碎片。
* 整个内存管理以字节为单位进行操作,确保内存的高效利用。
*/
#define ALIGNMENT 8
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~(ALIGNMENT - 1))
typedef struct BlockHeader {
size_t size; // 块大小(包括头部)
struct BlockHeader *next; // 指向下一个块
int free; // 是否空闲
} BlockHeader;
static BlockHeader *heap_start = NULL; // 堆的起始地址
static BlockHeader *free_list = NULL; // 空闲块链表
// 初始化堆
static void heap_init() {
if (!heap_start) {
// 分配一个初始页面
heap_start = (BlockHeader *)page_alloc(1);
if (!heap_start) {
printf("Heap initialization failed!\n");
return;
}
heap_start->size = PAGE_SIZE;
heap_start->next = NULL;
heap_start->free = 1;
free_list = heap_start;
}
}
// 分配内存
void *malloc(size_t size) {
if (size == 0) {
return NULL;
}
size = ALIGN(size + sizeof(BlockHeader)); // 对齐并加上头部大小
if (!heap_start) {
heap_init();
}
BlockHeader *current = free_list;
BlockHeader *prev = NULL;
// 首次适配算法
while (current) {
if (current->free && current->size >= size) {
// 如果块足够大,分割块
if (current->size > size + sizeof(BlockHeader)) {
BlockHeader *new_block = (BlockHeader *)((char *)current + size);
new_block->size = current->size - size;
new_block->free = 1;
new_block->next = current->next;
current->size = size;
current->next = new_block;
}
current->free = 0;
return (void *)((char *)current + sizeof(BlockHeader));
}
prev = current;
current = current->next;
}
// 如果没有找到合适的块,分配新的页面
BlockHeader *new_block = (BlockHeader *)page_alloc(1);
if (!new_block) {
return NULL;
}
new_block->size = PAGE_SIZE;
new_block->free = 0;
new_block->next = NULL;
if (prev) {
prev->next = new_block;
}
return (void *)((char *)new_block + sizeof(BlockHeader));
}
// 释放内存
void free(void *ptr) {
if (!ptr) {
return;
}
BlockHeader *block = (BlockHeader *)((char *)ptr - sizeof(BlockHeader));
block->free = 1;
// 合并相邻的空闲块
BlockHeader *current = free_list;
while (current) {
if (current->free && current->next && current->next->free) {
current->size += current->next->size;
current->next = current->next->next;
}
current = current->next;
}
}
// 测试 malloc 和 free
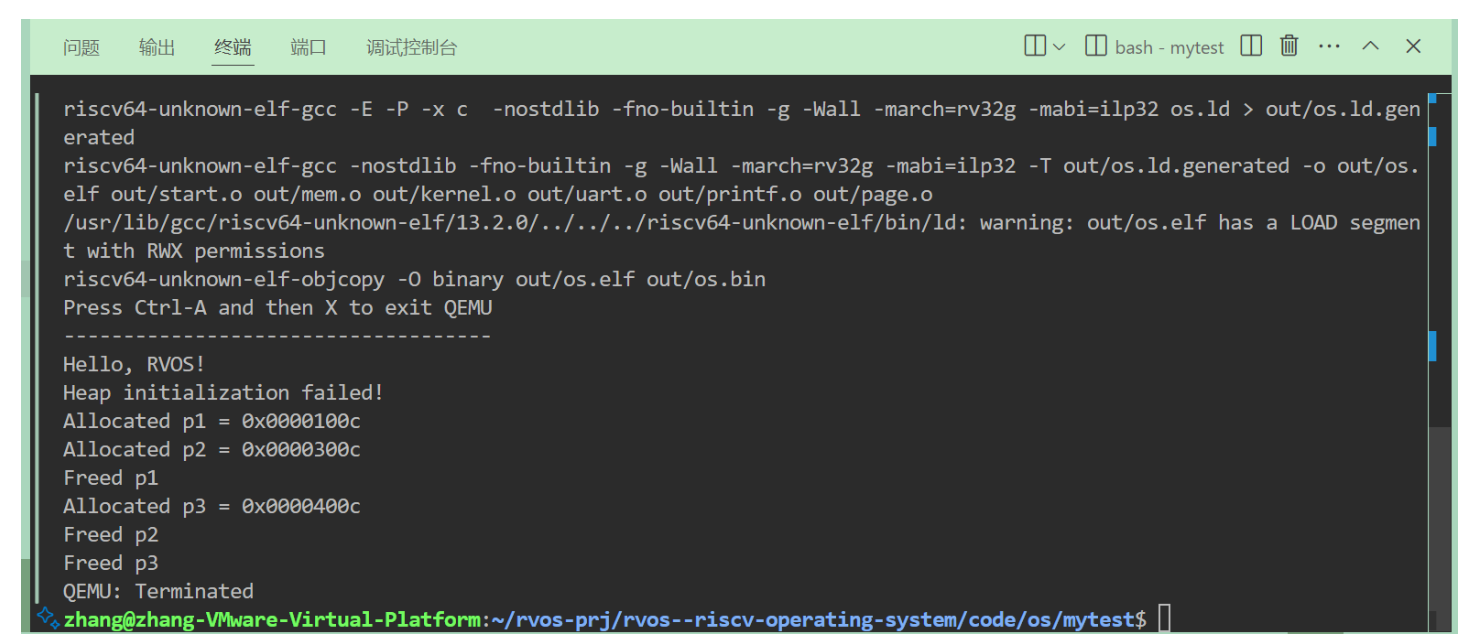
void malloc_test(void) {
void *p1 = malloc(100);
printf("Allocated p1 = %p\n", p1);
void *p2 = malloc(200);
printf("Allocated p2 = %p\n", p2);
free(p1);
printf("Freed p1\n");
void *p3 = malloc(50);
printf("Allocated p3 = %p\n", p3);
free(p2);
printf("Freed p2\n");
free(p3);
printf("Freed p3\n");
}
总结:
虽然汪老师说剩下的练习以字节为单位的内存分配比较简单,但是仍然是研究了两天(当然自己也有锅,被我的老铁蛊惑着play了三晚上游戏,罪孽啊!!!)