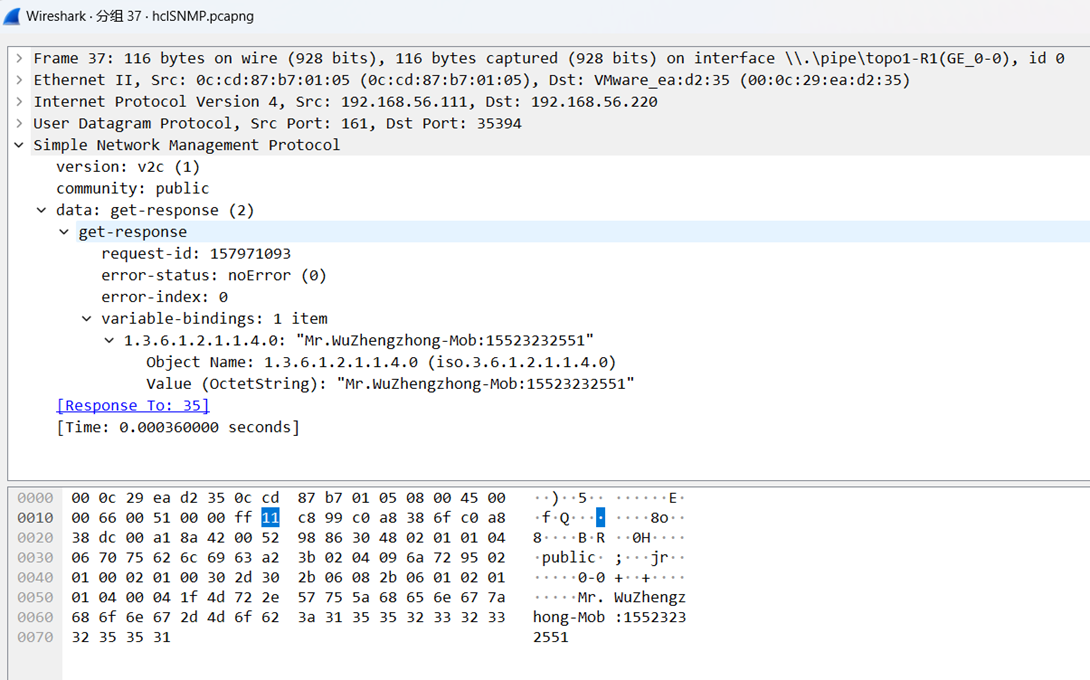
介绍
传统的 MySQL 架构中,所有的数据库操作(包括读操作和写操作)都在同一个数据库实例上进行。随着应用程序的规模增长,单一数据库实例可能会成为瓶颈,无法满足高并发的需求。为了优化性能,可以将数据库的读操作和写操作分开。
写操作(Write):所有的写操作(如 INSERT、UPDATE、DELETE 等)都在主数据库(Master)上进行。
读操作(Read):所有的读操作(如 SELECT)在从数据库(Slave)上进行。
这种方式被称为“读写分离”,它可以通过将负载分散到多个数据库实例上,减少主数据库的。
依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.23</version>
</dependency>
<!-- ShardingSphere JDBC -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
Druid介绍 是阿里巴巴开源的数据库连接池。具有高性能、稳定性好、支持监控等特点
ShardingSphere介绍 分布式数据库中间件,提供了数据库分片、读写分离、数据加密、事务管理等功能。
配置文件
spring:
main:
# 允许覆盖 Spring 中的 Bean 定义
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 定义数据源的名称,这里包含两个数据源,分别为 'm' 和 's1'
names: m, s1
# 主数据库数据源配置(m)
m:
# 数据库驱动类
driver-class-name: com.mysql.cj.jdbc.Driver
# 数据源类型,使用 Druid 连接池
type: com.alibaba.druid.pool.DruidDataSource
# 数据库连接 URL,指定连接 MySQL 服务器,使用 3306 端口
url: jdbc:mysql://172.23.4.128:3306/goods?useUnicode=true
# 数据库用户名
username: root
# 数据库密码
password: 123456
# 从数据库数据源配置(s1)
s1:
# 数据源类型,使用 Druid 连接池
type: com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类
driver-class-name: com.mysql.cj.jdbc.Driver
# 数据库连接 URL,指定连接 MySQL 服务器,使用 3307 端口
url: jdbc:mysql://172.23.4.128:3307/goods?useUnicode=true
# 数据库用户名
username: root
# 数据库密码
password: 123456
masterslave:
# 设置负载均衡算法类型为 'RANDOM',即随机选择主从库
load-balance-algorithm-type: RANDOM
# 设置数据源的名称,这里指定为 'dataSource'
name: dataSource
# 设置主库数据源名称,使用之前配置的数据源 'm' 作为主库
master-data-source-name: m
# 设置从库数据源的名称,使用 's1' 作为从库
slave-data-source-names: s1
props:
# 设置 SQL 输出日志显示开关,开启 SQL 语句显示
sql:
show: true
负载均衡算法
RANDOM: 随机选择从库。
ROUND_ROBIN: 轮询选择从库。
LEAST_CONNECTIONS: 选择连接数最少的从库。
SNAPPY: 通过负载均衡算法动态选择最适合的从库。