目录
前言:
基本查询回顾
笛卡尔积和子查询
笛卡尔积
内外连接
子查询
单行子查询
多行子查询
多列子查询
from中使用子查询
合并查询
前言:
在前文我们学习了MySQL的基本查询,就是简单的套用了select语句,最多不过是加上了一些聚合函数,使用了group by或者是having等。
但是对于MySQL语句来说,查询往往是最复杂的,比如在一次查询中我们可能涉及到多个表的查询,那么我们是如何将这些有关联的表连接在一起的呢?我们是如果将表连接之后使用筛选条件和聚合函数查询出我们想要的内容呢?
以上就是我们今天要解决的问题了,那么废话不多说,我们直接进入主题!
在学习之前,我们使用的是Oracle的9i经典测试表进行讲解的:
CREATE TABLE EMP (
EMPNO INT PRIMARY KEY, -- 雇员编号
ENAME VARCHAR(100), -- 雇员姓名
JOB VARCHAR(100), -- 岗位
MGR INT, -- 上级领导编号
HIREDATE DATE, -- 入职日期
SAL DECIMAL(10, 2), -- 工资
COMM DECIMAL(10, 2), -- 提成
DEPTNO INT -- 部门编号
);
INSERT INTO EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES
(7839, 'KING', 'PRESIDENT', NULL, '1990-06-09', 5000, NULL, 10),
(7566, 'JONES', 'MANAGER', 7839, '1990-04-02', 2975, NULL, 10),
(7698, 'BLAKE', 'MANAGER', 7839, '1990-06-12', 2850, NULL, 30),
(7782, 'CLARK', 'MANAGER', 7839, '1990-05-14', 2450, NULL, 10),
(7788, 'SCOTT', 'ANALYST', 7566, '1990-07-13', 3000, NULL, 20),
(7902, 'FORD', 'ANALYST', 7566, '1990-12-05', 3000, NULL, 20),
(7844, 'TURNER', 'SALESMAN', 7698, '1995-06-04', 1500, 0, 30),
(7900, 'JAMES', 'CLERK', 7698, '1996-06-23', 950, NULL, 30),
(7654, 'MARTIN', 'SALESMAN', 7698, '1998-12-05', 1250, 1400, 30),
(7499, 'ALLEN', 'SALESMAN', 7698, '1998-06-04', 1600, 300, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1996-02-22', 1250, 500, 30),
(7934, 'MILLER', 'CLERK', 7782, '2000-01-21', 1300, NULL, 10);
这是EMP表。
CREATE TABLE DEPT (
DEPTNO INT PRIMARY KEY, -- 部门编号
DNAME VARCHAR(100), -- 部门名称
LOC VARCHAR(100) -- 部门地址
);
INSERT INTO DEPT (DEPTNO, DNAME, LOC) VALUES
(10, 'ACCOUNTING', 'NEW YORK'),
(20, 'RESEARCH', 'DALLAS'),
(30, 'SALES', 'CHICAGO'),
(40, 'OPERATIONS', 'BOSTON');
这是DEPT表。
CREATE TABLE SALGRADE (
GRADE INT PRIMARY KEY, -- 工资等级
LOSAL DECIMAL(10, 2), -- 最低工资
HISAL DECIMAL(10, 2) -- 最高工资
);
INSERT INTO SALGRADE (GRADE, LOSAL, HISAL) VALUES
(1, 700, 1200),
(2, 1201, 1400),
(3, 1401, 2000),
(4, 2001, 3000),
(5, 3001, 9999);
这是SALGRADE表。
好了,有了以上的准备,我们就开始吧!
基本查询回顾
对于基本查询我们简单回顾几个题目就可以了:
显示每个部门的平均工资和最高工资
显示平均工资低于2000的部门号和它的平均工资
显示工资最高的员工的名字和工作岗位
显示每个部门的平均工资和最高工资:
因为我们要求的是每个部门的平均工资,显然我们要将不同部门的人分开来,那么肯定是要用group by分组的,分了组之后,我们可以根据聚合函数avg和max求得我们需要的信息:
select DEPTNO,avg(SAL)平均工资,max(SAL)最高工资 from EMP group by DEPTNO;
显示平均工资低于2000的部门号和它的平均工资:
同样,因为我们是根据部门来确认平均工资,那么聚合函数是跑不掉的,但是这道题和上面的题目不同的是多了一个筛选条件,那么无非是加个having的事儿:
select DEPTNO,AVG(SAL)平均工资 from EMP group by DEPTNO having 平均工资<2000;
显示工资最高的员工的名字和工作岗位:
如果我们读题只读一半的话,那么我们是很容易把前半句查出来的,显示工资最高的,无非就是max一下,找到了我们再用SAL对照看一下,对照出来了之后,我们再从EMP表里面去找即可,那么在这里我们相当于要查询两次,一次查询工资最高是多少,一次通过最高工资查询这个人的名字和工作岗位:
select ENAME,DEPTNO from EMP where sal=(select max(SAL) from EMP);
到这里,已经开始逐渐有了多表查询的影子了,或者说已经有了子表查询的影子了。
那么我们就趁热打铁,直接进入到下一阶段吧!
笛卡尔积和子查询
到这里,肯定有人会好奇说,笛卡尔积不是数学中的东西吗,怎么在MySQL中也有这个东西,那多正常,一个名字多处复用嘛。
好了,对于笛卡尔积我们也不解释,我们就只记住一句话,笛卡尔积是两张表互相乘的结果,这两张表可以是同一张表。
具体的乘法就是A表中的每行和B表中的每行进行逐步相乘,所以假设A表有N行,B表有M行,那么它们的笛卡尔积的结果就是N*M行,那么其中必定伴随了冗余的数据,所以需要我们加入对应的连接条件。其实到笛卡尔积这里我们也就是在学习内外连接,不过欲听后事如何,且看后面。
笛卡尔积
咱们单说概念没有意思,我们直接用题目讲解即可。
显示雇员名、雇员工资以及所在部门的名字:
对于EMP表中明显有的是雇员名,雇员工资,但是并没有所在部门的名字,部门名是DEPT表中才有的,所以明显这个查询结果是要联合两张表查询的。
那么这里因为是第一次见,我就直接给代码然后再解释了:
select ENAME,SAL,DNAME from EMP, DEPT where EMP.DEPTNO=DEPT.DEPTNO;
select EMP.ENAME,EMP.SAL,DEPT.DNAME from EMP, DEPT where EMP.DEPTNO=DEPT.DEPTNO;
NO;

这里可以发现我们有两种写法,一种是类似于C++结构体访问符的写法,一种是直接选择,那么为什么两种写法都可以呢?因为我们要查询的元素在都是独一无二的,也就是在其他表里面没有,比如在EMP表中有ENAME,在SALGRADE和DEPT中都没有,所以我们不用指定。其它同理。
那么当我们给这两个表做了笛卡尔积之后,我们是一定要用where筛选出来结果的,不然数据直接错乱,筛选的条件就是我们通过这两个表共同的数据让它们连接在一起。
这种结果可能更像一种拼接,我们可以用拼接的视角来看待笛卡尔积。
显示部门号为10的部门名,员工名和工资:
对于这道题目来说,我们可以先思考哪些元素是表里面有的,哪些元素是表里面没有的,比如部门名是DEPT里面的,员工名和工资都是EMP里面的,也就是意味着我们要连接这两个表,但是这道题目与上面一道题目不一样的是这道题目多了一个条件,即只要部门号为10的,那么我们将表拼接之后where选择一下就可以了。
select DEPT.DNAME,EMP.ENAME,EMP.SAL from EMP,DEPT
where EMP.DEPTNO=DEPT.DEPTNO and EMP.DEPTNO=10;

显示各个员工的姓名,工资,及工资级别:
这道题目同理,我们经过分析可以知道姓名和工资是EMP独有的,工资级别是SALGRADE独有的,所以我们要连接的两张表就是这两张了,那么它们的连接条件是什么呢?
因为它们看起来好像并没有什么col是一样的,那么就需要我们额外的去筛选了
select GRADE,ENAME,SAL from EMP, SALGRADE where SAL between LOSAL and HISAL;
我们手动筛选,即我们要让工资符合条件即可,不能让工资的档位随意浮动是吧。
(自连接)显示员工WARD的上级领导的编号和姓名
这道题目我们实际上是有两种方式来做的,一种是子查询,即我们先把WARD的领导的编号查到,然后再select他对应的编号和姓名。
但是如果我们将EMP看作两张表,一张表用作员工表,一张表用作领导表,分别查询似乎也是可以的,就像
select leader.EMPNO,leader.ENAME from EMP as worker, EMP as leader
where worker.MGR=leader.EMPNO and worker.ENAME='WARD';
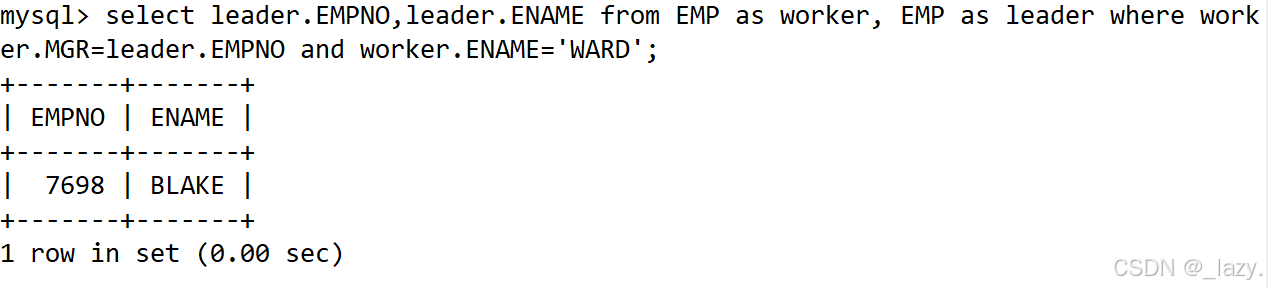
到这里我们算是简单的了解完了笛卡尔积了,而我们还发现了一些有意思的,比如做笛卡尔积的两张表我们可以重命名,这样可以防止命名冲突。
内外连接
对于内外连接来说其实就是做笛卡尔积,不过这个看起来更加的规范,因为本文的主题算是笛卡尔积吧,所以本文的写法除了这里都是笛卡尔积的写法。
对于内外连接来说,内连接就是我们刚才的,不管三七二十一,两张表做一个乘法,不过这里换了关键字,用的是inner join,题目是显示SMITH的名字和部门名称,我们用标准的内连接来写这个的话就是:
select ENAME,DEPT.DNAME from EMP inner join DEPT on EMP.DEPTNO=DEPT.DEPTNO
where EMP.ENAME='SMITH';
我们可以注意到我们是将原本的连接where替换成了on,并且在EMP和DEPT中间加了一个inner join,代表的就是内连接。
同理,外连接分为两种,一种是左外连接,一种是右外连接,它们没有差别,因为这两个外连接可以完美的相互转化,不过是交换一下位置的事儿而已。
语法只是把inner join换成了left join和 right join而已。
查询所有雇员的姓名、工资以及他们所在的部门名称。如果某个雇员没有部门,也需要显示雇员的信息。
通过题目我们可以得知外连接的作用就是让某一张表的信息全部显示,即便连接之后这张表的某行和某列来说都是要完整显示的,所以我们拿这个题举例,代码为
SELECT EMP.ENAME, EMP.SAL, DEPT.DNAME
FROM EMP
LEFT JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO;
当然了,这里的效果不明显,因为数据都是比较完整的,所以没有显示NULL的情况。
当然了,你要想写右外连接也是可以的,咱们直接换个位置,,,对吧,所以内外连接没有那么神奇,就是谁厉害,谁显示的多一点,谁就当主表而已。
子查询
显示员工WARD的上级领导的编号和姓名
没错,还是这道题目,不过我们这道题目可以使用子查询的方法来做,无非就是先查出来WARD的领导是谁,然后再到EMP表中进行查找即可:
select ENAME,EMPNO from EMP where EMPNO=(select MGR from EMP where ENAME='WARD');
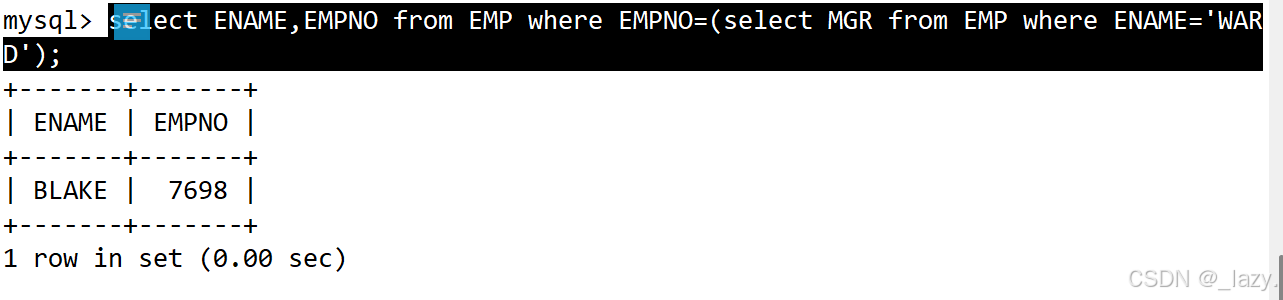
我们的基本思路就是先搞清楚内层select要干嘛,我们得先找到WARD领导的EMPNO才能找到对应的信息吧?而领导的EMPNO恰好是WRAD的MGR,所以我们就能通过子查询找到对应的EMPNO,那这样不就手到擒来了吗?
不过对于子查询来说分为了以下几个部分:
单行子查询
对于单行子查询来说,就是子查询的结果只有一行,比如这道题。
显示SMITH同一部门的员工
我们要知道和SMITH同一部门的员工,我们得知道SMITH是什么员工吧?所以我们先利用子查询把SMITH的部门查出来,就一行,我们利用这行数据,从EMP表里面找一样的即可
select ENAME,DEPTNO from EMP
where DEPTNO=(select DEPTNO from EMP where ENAME='SMITH');

多行子查询
同理,对于多行子查询来说,就是子查询返回的结果有多行,比如这道题:
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
要查询上面的信息,我们就应该查询处10号的工作岗位是什么,可能有多个,所以我们应该使用的关键字是in
select ENAME,JOB,SAL,DEPTNO from EMP
where JOB in (select JOB from EMP whereDEPTNO=10) and DEPTNO<>10;
那么对于多行子查询类似的题目有这几个,大家伙可以自己试试:
all关键字;显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门 的员工)
多列子查询
这个就是子查询返回的结果是多列的,那么有人问了,是否存在有多列多行的呢?有,但是不是很常见,所以这里只演示前面三个。我们还是通过题目来介绍它:
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
select * from EMP
where (DEPTNO,JOB)=(select DEPTNO,JOB from EMP where ENAME='SMITH') and ENAME<>'SMITH';
不过因为这个表里面没有完全相同的,所以查询出来的结果也是空的。
接下来最难的一部分就来了,大家要先有一个概念即MySQL中一切皆表。为什么这么说呢?你看查出来的所有的东西,它难道不是一个表吗?无非是这个表的行和列多与少的关系,那么既然查出来的东西是表,我们是否可以让它和别的表做笛卡尔积?当然是可以的,也可以让它单独作为一张表来查询,那么就引出来了今天的这个话题,from中使用子查询。
from中使用子查询
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
首先我们解析题目,显示每个高于自己部门平均工资的员工的什么什么,那么我们是否应该先把自己部门工资的平均工资求出来,我们才好进行下一步比较。
那么求出来对应的平均工资我们肯定是要通过分组聚合的,有了这个平均工资表之后,我们将这两个表做笛卡尔积,之后我们的条件的是要大于平均工资,所以连接条件写好之后and加上另一个判断也是必不可少的。
这个相对来说是比较难的,所以同学们可能会绕一会儿。
select EMP.ENAME,EMP.DEPTNO,EMP.SAL,平均工资
from EMP, (select DEPTNO,avg(SAL)平均工资 from EMP group by DEPTNO) TMP
where EMP.DEPTNO=TMP.DEPTNO and EMP.SAL>平均工资;

查找每个部门工资最高的人的姓名、工资、部门、最高工资
同理,这个是求的最高工资,我们就直接给代码了,思路和上面的完全一样
select EMP.ENAME,EMP.SAL,EMP.DEPTNO,最高工资
from EMP, (select max(SAL) 最高工资, DEPTNO from EMP group by DEPTNO) TMP
where EMP.DEPTNO=TMP.DEPTNO and EMP.SAL=TMMP.最高工资;
显示每个部门的信息(部门名,编号,地址)和人员数量
既然我们是要求每个部门的人员数量,那么我们不妨先分组聚合,把每个部门的人员数量求出来。
求出来了之后,我们就拥有了一张包含人员数量和对应部门的表,我们可以将这个表作为子表,然后和DEPT表进行笛卡尔积,通过DEPTNO查找即可。
select DEPT.DEPTNO,DEPT.DNAME,DEPT.LOC,人员数量
from DEPT, (select DEPTNO,count(*)nt(*)人员数量 from EMP group by DEPTNO)TMP
where DEPT.DEPTNO=TMP.DEPTNO;

select DEPT.dname, DEPT.deptno, DEPT.loc,count(*) '部门人数' from EMP,
DEPT
where EMP.deptno=DEPT.deptno
group by DEPT.deptno,DEPT.dname,DEPT.loc;这个是多表查询的方法,也是可以的,不过需要注意的是分组的时候应该是部门信息都是一组的。
合并查询
搞了这么多难的,我们终于可以整个轻松的了,就学两个,一个是union,一个是union all,前者在并集的基础上去重,后者在并集的基础上不去重。
将工资大于2500或职位是MANAGER的人找出来
select ename, sal, job from EMP where sal>2500 union select ename, sal, job from EMP where job='MANAG' select ename, sal, job from EMP where sal>2500 union all select ename, sal, job from EMP where job='MANAG没啥好说的,非常非常简单,就是将查询结果并起来就行了。
感谢阅读!