前言:
在系统开发中经常使用关系型数据库,为了提升关系型数据库的读性能,一般会使用redis加一层缓存,缓存和数据库是分离的两次操作,本文用来分析如何操作能保证缓存和数据库的数据一致性。
一、读场景
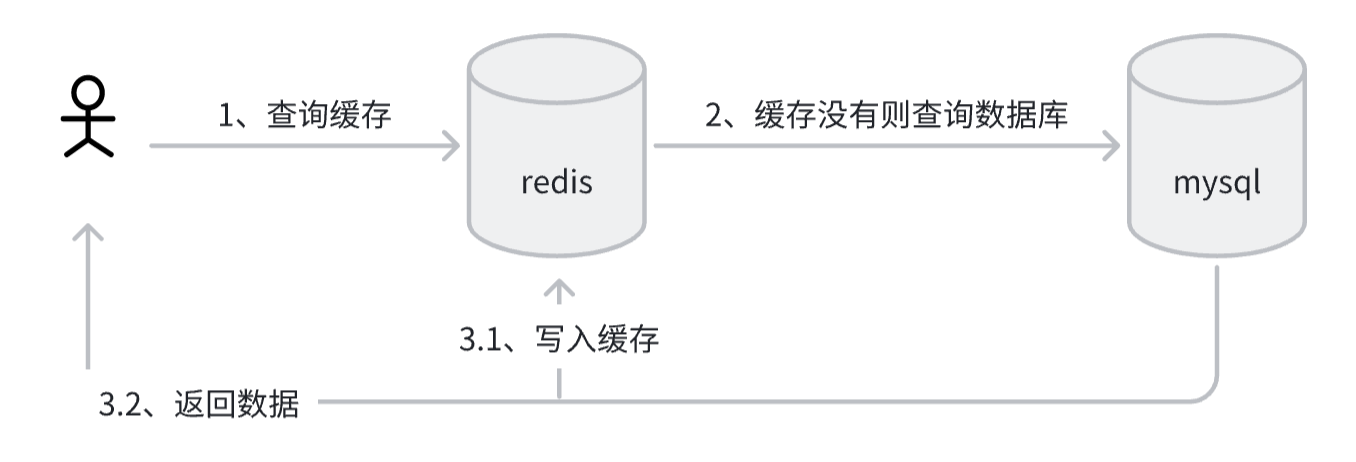
二、写场景
1. 先删除缓存再写数据库
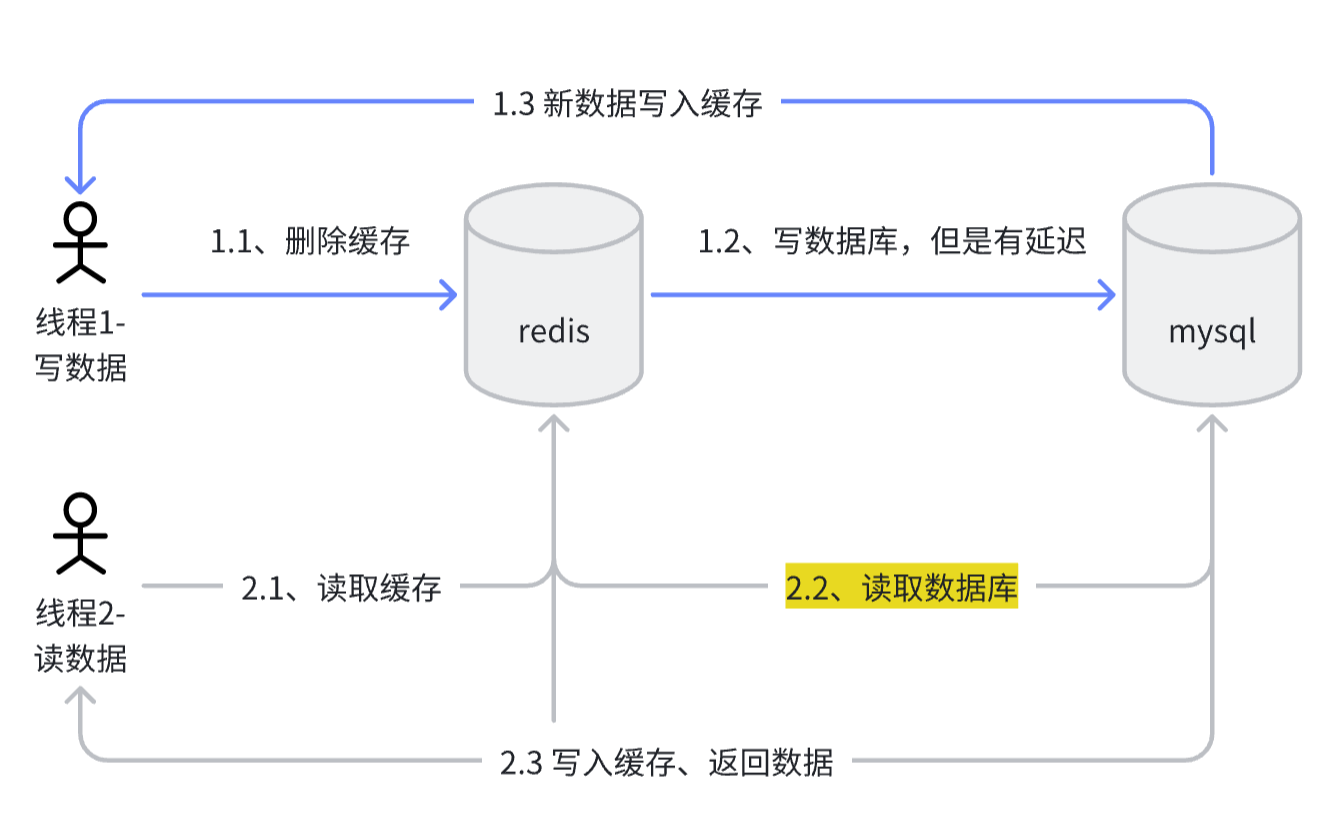
如图所示,同时两个线程操作一条数据,线程1写数据,线程2读数据。
情况1:如果正常顺序线程1先执行线程2后执行,则数据在两个线程中是一致的。
情况2:当线程1在1.2延迟落后于线程2时,redis中就会被放入旧数据,此时在缓存有效期内缓存和数据库中的数据是不一致的。
情况2优化方案:
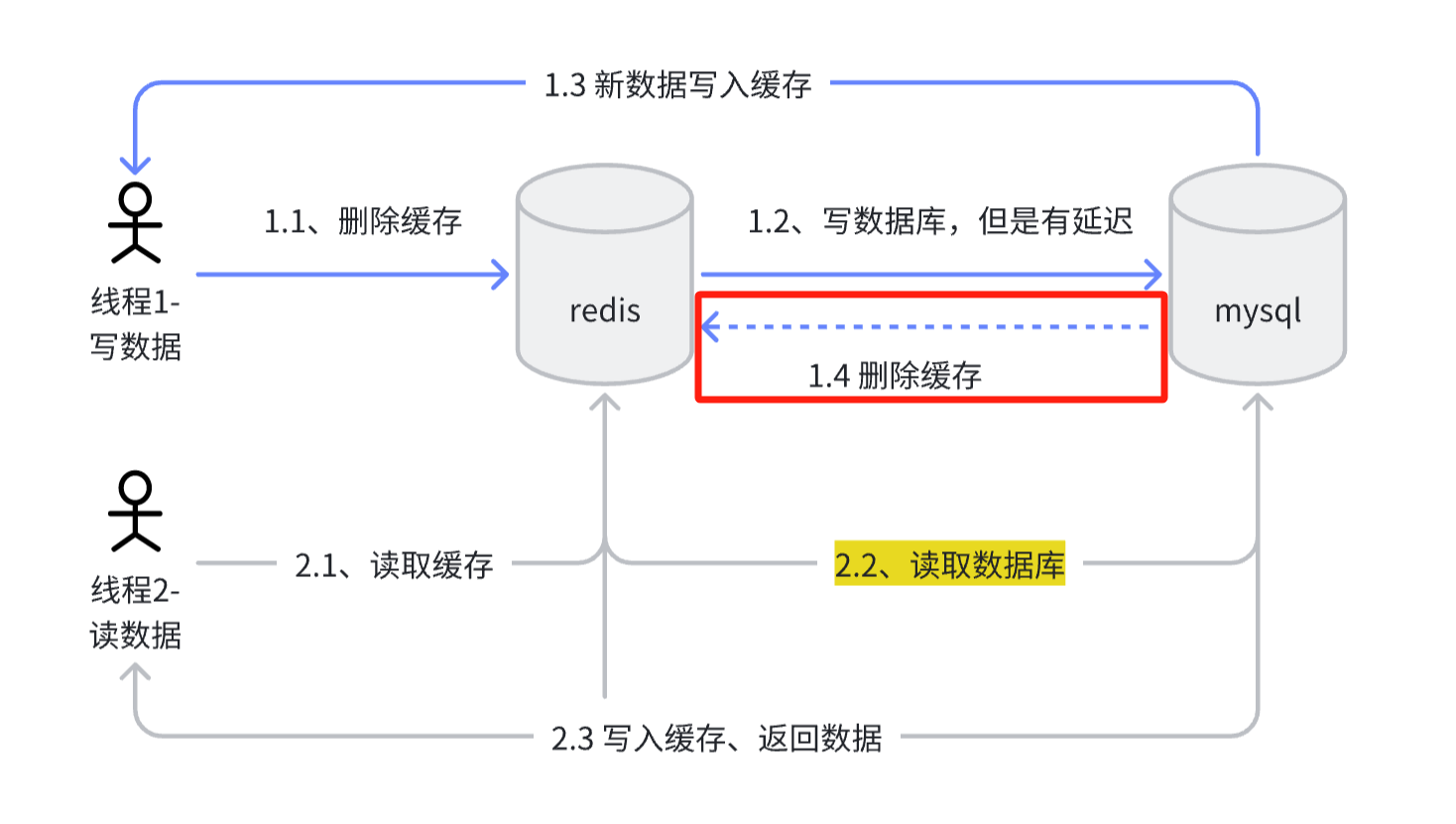
在写线程增加一次删除操作,这样只有两次删除中间的线程读到的数据是不一致的,其它线程可以保证数据一致性。在双删的情况下,如果1.4在2.3之前执行,也是存在数据不一致情况的,所以1.4做延迟删除,延迟几百毫秒(结合自己业务),也可以优化这个问题。
2、先操作数据库(步骤简单成本低,推荐)
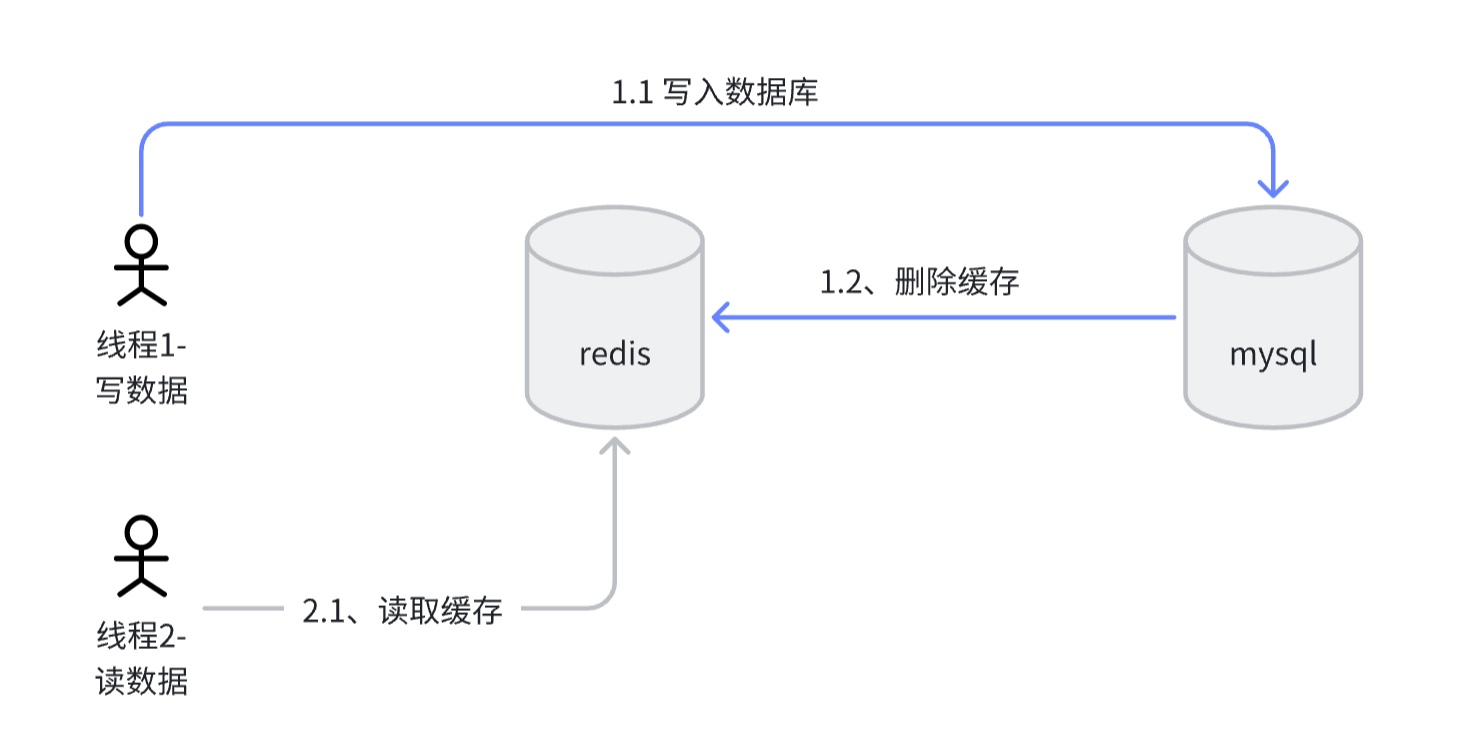
这种情况只会影响线程2这种情况的读线程,2.1可能在1.2之前读到旧数据,不过在1.2执行成功之后,缓存和数据库的数据就是一致的了。
3、强一致性
对缓存和数据库的操作加锁,这样两部分数据就是强一致的,但是会影响系统吞吐性,不建议。
4、删除缓存失败情况
上面1、2两种情况都有删除缓存的操作,如果缓存删除失败缓存和数据库的一致问题就还是没有解决。
这个情况可以通过下面两种方式优化:
4.1 删除缓存加入重试机制,避免影响主流程高并发情况下建议异步重试删除,如果重试后依然失败可以通过报警接入人工处理。
4.2 删除缓存也可以通过监听mysql binlog的方式异步删除+失败报警的方式。
三、最终一致性
除了加锁强一致性的方式,其它两种方式都是只做到了最终一致性,在写的某个时间段内是不一致的,没有最好的方案,选择适合自己业务场景的就好。