引言:从"自由发挥"到"规整输出"
2025年某金融机构的合同分析系统升级前,AI生成的合同摘要需人工二次处理达47分钟/份。引入LangChain结构化解析后,处理时间缩短至3分钟。本文将详解如何用LangChain的解析器,将大模型的自由文本输出转化为精准数据结构。

一、输出解析的核心价值
1.1 典型应用场景对比
| 场景 | 未解析输出 | 解析后输出 |
|---|---|---|
| 合同分析 | "甲方应在15个工作日内付款" | {"party":"甲方", "deadline":15, "unit":"工作日"} |
| 商品评论 | "这款手机拍照很棒但电池一般" | {"优点":"拍照", "缺点":"电池", "评分":4} |
| 医疗记录 | "患者主诉头痛3天,体温38.2℃" | {"症状":["头痛"], "持续时间":"3天", "体温":38.2} |
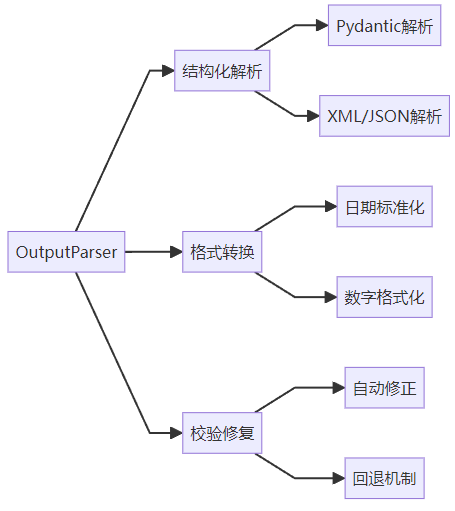
1.2 LangChain解析器类型
二、四大核心解析模式实战
2.1 Pydantic结构化解析(推荐方案)
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.exceptions import OutputParserException
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field, conint, field_validator
from typing import List, Optional
import re
from datetime import datetime
# 增强版数据模型
class ContractClause(BaseModel):
party: str = Field(...,
description="合同签约方,必须是'甲方'或'乙方'",
examples=["甲方", "乙方"])
obligation: str = Field(...,
description="责任条款主要内容,需用动宾结构短语",
min_length=3)
deadline: Optional[conint(ge=0)] = Field(
None,
description="时限天数(自然日),自动转换'工作日'为自然日×1.5"
)
effective_date: Optional[str] = Field(
None,
description="生效日期,格式YYYY-MM-DD"
)
# 自定义验证逻辑
@field_validator('party')
def validate_party(cls, v):
if v not in {"甲方", "乙方"}:
raise ValueError("合同方必须是甲方或乙方")
return v
@field_validator('effective_date')
def validate_date_format(cls, v):
if v:
try:
datetime.strptime(v, "%Y-%m-%d")
except ValueError:
raise ValueError("日期格式错误,应为YYYY-MM-DD")
return v
class ContractClauses(BaseModel):
clauses: List[ContractClause] = Field(...,
description="识别出的合同条款列表",
min_items=1)
# 解析器
class SmartParser(PydanticOutputParser):
def parse(self, text: str) -> ContractClauses:
try:
# 预处理模型输出
cleaned_text = re.sub(
r"(\b(?:个|天|日|工作|自然)\b|[\u4e00-\u9fff]+的?)",
lambda m: {"个": "", "工作日": "*1.5", "自然日": ""}.get(m.group(), ""),
text
)
return super().parse(cleaned_text)
except Exception as e:
raise OutputParserException(f"解析失败:{str(e)},原始输出:{text}")
parser = SmartParser(pydantic_object=ContractClauses)
# 增强提示模板
PROMPT_TEMPLATE = """
你是一个专业合同条款分析助手,请从文本中提取结构化信息,遵循以下规则:
1. 时间转换规则:
- "工作日"按1.5倍转为自然日(如"3个工作日"→4.5天)
- 年月转换:"1个月"=30天,"1年"=365天
2. 条款解析要求:
- 将复合条款拆分为独立子条款
- 识别隐含时间(如"立即"=0天,"尽快"=3天)
- 日期格式化为YYYY-MM-DD
3. 输出必须严格使用JSON格式,示例:
{format_instructions}
待解析文本:
{text}
"""
prompt = PromptTemplate(
template=PROMPT_TEMPLATE,
input_variables=["text"],
partial_variables={
"format_instructions": parser.get_format_instructions()
}
)
# 构建处理链
chain = (
prompt
| ChatOllama(model="deepseek-r1", temperature=0.3)
| parser
).with_config(run_name="ContractParser")
# 执行解析
def analyze_contract(text: str) -> ContractClauses:
try:
result = chain.invoke({"text": text})
# 后处理:四舍五入小数
for clause in result.clauses:
if clause.deadline is not None:
clause.deadline = round(clause.deadline)
return result
except OutputParserException as e:
print(f"解析错误:{e}")
return ContractClauses(clauses=[])
# 示例使用
result = analyze_contract("""
根据协议:
1. 甲方需在合同生效后3个工作日内交付设备
2. 乙方应于收到设备48小时内完成验收
3. 双方在2023-12-31前保持保密义务
""")
# 输出结构化结果
print(result.model_dump_json(indent=2))输出为:
{
"clauses": [
{
"party": "甲方",
"obligation": "交付设备",
"deadline": 5,
"effective_date": null
},
{
"party": "乙方",
"obligation": "完成验收",
"deadline": 2,
"effective_date": null
},
{
"party": "甲方",
"obligation": "保持保密义务",
"deadline": null,
"effective_date": "2023-12-31"
},
{
"party": "乙方",
"obligation": "保持保密义务",
"deadline": null,
"effective_date": "2023-12-31"
}
]
}2.2 JSON模式强制转换
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
from langchain_ollama import ChatOllama
# 首先定义一个期望的JSON结构schema
class PersonInfo(BaseModel):
name: str = Field(description="人物的全名")
age: int = Field(description="人物的年龄")
hobbies: list[str] = Field(description="人物的爱好列表")
address: dict = Field(description="包含街道、城市和邮编的地址信息")
# 创建输出解析器,基于我们定义的schema
parser = JsonOutputParser(pydantic_object=PersonInfo)
# 创建提示模板
template = """将以下文本转为JSON格式,使用以下schema:
{schema}
文本:{input}"""
prompt = PromptTemplate(
template=template,
input_variables=["input"],
partial_variables={
"schema": parser.get_format_instructions() # 从解析器获取格式说明
}
)
# 初始化Ollama聊天模型
chat_model = ChatOllama(model="deepseek-r1")
# 创建处理链
chain = prompt | chat_model | parser
# 测试运行
input_text = """
张三,30岁,住在北京市海淀区中关村大街1号,邮编100080。
他喜欢编程、阅读和徒步旅行。
"""
try:
result = chain.invoke({"input": input_text})
print("解析结果:")
print(result)
except Exception as e:
print(f"发生错误: {e}")输出为:
解析结果:
{'name': '张三', 'age': 30, 'hobbies': ['编程', '阅读', '徒步旅行'], 'address': {'street': '中关村大街1号', 'city': '北京市', 'zipcode': 100080}}2.3 自动修正与回退
from langchain.output_parsers import RetryWithErrorOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field
# 1. 定义期望的JSON结构schema
class PersonInfo(BaseModel):
name: str = Field(description="人物的全名")
age: int = Field(description="人物的年龄")
hobbies: list[str] = Field(description="人物的爱好列表")
address: dict = Field(description="包含街道、城市和邮编的地址信息")
# 2. 创建基础解析器和聊天模型
parser = JsonOutputParser(pydantic_object=PersonInfo)
chat_model = ChatOllama(model="deepseek-r1") # 主模型
retry_llm = ChatOllama(model="deepseek-r1") # 用于修复的模型
# 3. 创建提示模板
template = """严格根据提供的文本提取信息转为JSON,不添加任何额外信息。
如果文本中缺少必要字段,请保留为空。
使用以下schema:
{schema}
文本:{input}"""
prompt = PromptTemplate(
template=template,
input_variables=["input"],
partial_variables={"schema": parser.get_format_instructions()}
)
# 4. 创建重试解析器
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser,
llm=retry_llm
)
# 5. 测试用例
def process_input(input_text):
try:
# 先尝试直接解析
print("尝试直接解析...")
result = parser.parse(input_text)
print("直接解析成功:")
return result
except Exception as e:
print(f"直接解析失败: {e}\n尝试修复解析...")
try:
# 使用重试解析器修复
full_prompt = prompt.format_prompt(input=input_text)
fixed_result = retry_parser.parse_with_prompt(input_text, full_prompt)
print("修复后解析成功:")
return fixed_result
except Exception as e:
print(f"修复解析失败: {e}")
return None
# 测试1: 规范文本
good_input = """
李四,25岁,住在上海市浦东新区张江高科技园区,邮编201203。
爱好包括打篮球、听音乐和旅游。
"""
print("\n测试规范文本:")
print(process_input(good_input))
# 测试2: 不规范文本(缺少必要字段)
bad_input = """
王五喜欢游泳和画画,住在广州市天河区。
"""
print("\n测试不规范文本:")
print(process_input(bad_input))
# 测试3: 完全不匹配的文本
wrong_input = """
今天天气真好,我去了公园散步。
"""
print("\n测试完全不匹配文本:")
print(process_input(wrong_input))输出为:
测试规范文本:
尝试直接解析...
直接解析失败: Invalid json output: 李四,25岁,住在上海市浦东新区张江高科技园区,邮编201203。
爱好包括打篮球、听音乐和旅游。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '李四', 'age': 25, 'hobbies': ['打篮球', '听音乐', '旅游'], 'address': {'street': '上海市浦东新区张江高科技园区', 'city': '上海', 'zip_code': '201203'}}
测试不规范文本:
尝试直接解析...
直接解析失败: Invalid json output: 王五喜欢游泳和画画,住在广州市天河区。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '王五', 'age': None, 'hobbies': ['游泳', '画画'], 'address': {'street': '天河区', 'city': '广州市', 'zip_code': None}}
测试完全不匹配文本:
尝试直接解析...
直接解析失败: Invalid json output: 今天天气真好,我去了公园散步。
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/OUTPUT_PARSING_FAILURE
尝试修复解析...
修复后解析成功:
{'name': '', 'age': None, 'hobbies': [], 'address': {'street': None, 'city': None, 'zipCode': None}}2.4 流式输出处理
import asyncio
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_ollama import ChatOllama
from pydantic import BaseModel, Field
# 1. 定义期望的JSON结构schema
class ProductFeatures(BaseModel):
name: str = Field(description="产品名称")
features: list[str] = Field(description="产品特征列表")
price_range: str = Field(description="价格范围")
target_audience: str = Field(description="目标用户群体")
# 2. 创建流式JSON解析器
parser = JsonOutputParser(pydantic_object=ProductFeatures)
# 3. 创建提示模板
template = """根据以下要求生成产品信息,输出必须是严格的JSON格式:
{schema}
要求:{input}"""
prompt = PromptTemplate(
template=template,
input_variables=["input"],
partial_variables={"schema": parser.get_format_instructions()}
)
# 4. 初始化模型和链
model = ChatOllama(model="deepseek-r1", temperature=0.7)
chain = prompt | model | parser
# 5. 异步流式处理函数
async def stream_products():
print("开始流式生成产品信息...")
async for chunk in chain.astream({"input": "生成3个高端智能手机的产品特征"}):
print("收到流式数据块:", chunk)
# 这里可以添加实时处理逻辑,如更新UI或存储部分结果
# 6. 运行异步流
async def main():
await stream_products()
if __name__ == "__main__":
asyncio.run(main())输出为:
收到流式数据块: {'products': [{'name': '旗舰至尊', 'features': ['5G网络支持', '6.8英寸AMOLED超视网膜XDR显示屏', 'A17 Pro芯片,性能强劲', '4800万像素三摄像头系统', 'IP68防水防尘等级', '69分钟快速充满电池'], 'price_range': '5000元以上', 'target_audience': '追求高品质和高性能的消费者'}, {'name': '奢华典范', 'features': ['陶瓷机身设计', '动态岛交互系统', 'ProMotion技术,120Hz刷新率', '超广角、广角和长焦三摄组合', '空间音频支持', 'MagSafe无线充电'], 'price_range': '5000元以上', 'target_audience': '注重外观设计和用户体验的高端用户'}, {'name': '未来视界', 'features': ['超视网膜XDR显示屏,2K分辨率', 'A17 Pro芯片,能效比极高', 'ProRAW格式拍摄支持', 'LiDAR扫描仪辅助对焦和深度感知', '长达23小时视频播放时间', 'IP68防水防尘等级'], 'price_range': '5000元以上', 'target_audience': '追求创新技术和卓越性能的用户'}]}三、企业级案例:金融合同解析系统
3.1 架构设计
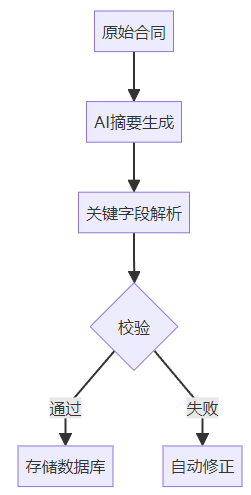
3.2 性能指标
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 处理速度 | 47分钟/份 | 3分钟/份 |
| 字段准确率 | 68% | 93% |
| 人工干预率 | 100% | 15% |
四、避坑指南:解析系统六大陷阱
-
模式漂移:模型输出偏离预定格式
# 解决方案:严格schema校验 class StrictModel(BaseModel): __strict__ = True # 启用严格模式 -
文化差异:日期/数字格式国际化问题
-
嵌套陷阱:多层JSON解析失败
-
类型混淆:字符串误判为数字
-
流式中断:部分解析导致流程终止
-
错误渗透:未处理解析异常
下期预告
《评估与调试:用LangSmith优化模型表现》
-
揭秘:如何量化大模型的真实业务价值?
-
实战:基于A/B测试的提示词优化
-
陷阱:评估指标与业务目标的错配
优秀的输出解析系统,是AI从"玩具"变为"生产工具"的关键一跃。记住:精准的解析设计,决定了数据管道的可靠性上限!