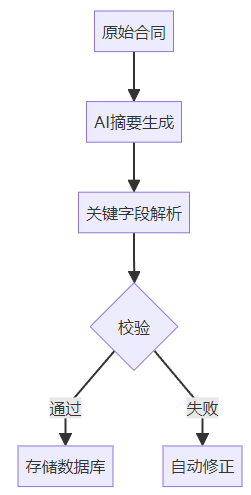
BPE:NLP 界的“变形金刚”,从零开始的奇幻之旅
在自然语言处理(NLP)的世界里,有一个古老而神秘的传说,讲述着一种强大的魔法——Byte Pair Encoding(BPE)。它能够将普通的文本“变形”成机器能够理解的神奇符号,就像《变形金刚》里的汽车人和霸天虎一样,瞬间从一个形态切换到另一个形态,瞬间从“人类语言”变成“机器语言”。
本文我们将一步步实现 BPE 的魔法,从零开始,不借助任何现成的工具,就像一个勇敢的探险家,用最原始的方式探索未知的世界。我们会详细地解释每一步的原理,展示代码的实现,还会用幽默的语言让这个过程变得轻松有趣。
所以,准备好你的魔法棒(键盘),穿上你的冒险装备(编程环境),和我一起踏上这场 BPE 的奇幻之旅吧!
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
文章目录
- 🧠 向所有学习者致敬!
- 🌐 欢迎[点击加入AI人工智能社区](https://bbs.csdn.net/forums/b8786ecbbd20451bbd20268ed52c0aad?joinKey=bngoppzm57nz-0m89lk4op0-1-315248b33aafff0ea7b)!
- 为何需要子词分词与 BPE
- 什么是分词?
- Byte Pair Encoding(BPE)算法:
- BPE 的主要步骤:
- 本文的实现方式:
- 第 0 步:准备——导入库和定义语料库
- 第 0.1 步:导入库
- 第 0.2 步:定义训练语料库
- 第 1 步:预处理与初始化
- 第 1.1 步:将语料库转换为小写
- 第 1.2 步:初始单词/词元分割
- 第 1.3 步:计算单词/词元频率
- 第 1.4 步:初始语料库表示(字符分割与`</w>`)
- 第 1.5 步:构建初始字符词汇表
- 第 2 步:BPE 训练——迭代合并
- 第 2.1 步:初始化训练状态变量
- 第 2.2 步:主训练循环结构
- 第 3 步:检查训练结果
- 第 3.1 步:最终词汇表大小
- 第 3.2 步:按优先级排序的学习合并规则
- 第 3.3 步:训练语料库中示例单词的最终表示
- 第 4 步:使用学习到的规则对新文本进行分词
- 第 4.1 步:定义新文本输入
- 第 4.2 步:预处理新文本
- 第 4.3 步:准备分词输出
- 第 4.4 步:遍历新文本中的单词(第 4.5 步到第 4.7 步将放入此循环中)
- 第 4.8 步:显示最终分词结果
- 第 5 步:总结
为何需要子词分词与 BPE
什么是分词?
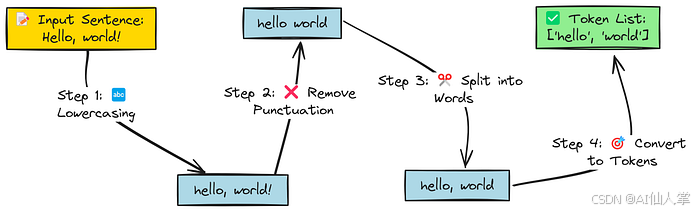
在自然语言处理(NLP)中,分词是处理文本的第一步,它将原始文本分解为更小的单元,称为“词元”(tokens)。这些词元是机器学习模型处理的基本构建块(例如单词、标点符号)。
简单单词分词的局限性:
单纯按照空格或标点符号分割文本看似直观,但存在重大挑战:
• 词汇爆炸问题:如果每个独特的单词都是一个词元,词汇表的大小可能会变得巨大,尤其是当语料库包含许多单词变体时(例如“run”、“runs”、“running”、“ran”、“runner”)。这需要大量的内存和计算资源。
• 词汇外问题(OOV):在固定词汇表上训练的模型无法处理训练期间未见过的单词(例如新专有名词、技术术语、拼写错误、新造词)。这些 OOV 单词通常会被映射到一个通用的<UNK>(未知)词元,从而丢失有价值的信息。
• 形态关系被忽略:单词级别的分词忽略了共享共同词根或词缀的单词之间的关系(例如“running”和“runner”)。
子词分词的解决方案:
子词分词算法旨在找到字符级别(词汇表小,但序列过长)和单词级别分词之间的平衡。它们将单词分解为更小的、有意义的单元(子词或词素)。
• 常见单词可能仍然是单个词元(例如“the”)。
• 较不常见的单词会被分解(例如“tokenization”->“token”+“ization”)。
• 稀有或未知单词会被进一步分解,甚至可能分解为单个字符(例如“BPEology”->“B”+“P”+“E”+“ology”,具体取决于训练情况)。
这种方法在保持词汇表大小可控的同时,大幅减少了 OOV 问题,并保留了一些形态学信息。
Byte Pair Encoding(BPE)算法:
BPE 最初是一种数据压缩技术,后来被改编用于 NLP 分词。它的核心思想简单而优雅:迭代合并训练语料库中出现频率最高的相邻符号对(字符或之前合并的子词)。
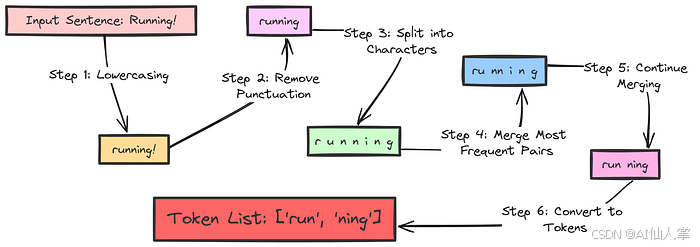
BPE 的主要步骤:
• 初始化:从包含训练文本中所有单独字符的词汇表开始。将文本分割为单词,并将每个单词表示为其字符序列加上一个特殊的单词结束标记(这对于学习单词边界至关重要)。
• 训练(迭代合并):重复以下步骤,直到达到预定义的合并次数:
a.统计整个语料库中所有相邻符号对的频率(考虑单词频率)。
b.找出出现频率最高的符号对。
c.将这对符号合并为一个新的符号(子词)。
d.将这个新符号添加到词汇表中。
e.将语料库中所有原始对的出现替换为新符号。
• 分词(应用学习到的规则):对新文本进行分词时:
a.以与训练数据相同的方式对其进行预处理(分割单词,添加单词结束标记)。
b.按照学习到的顺序(优先级最高在前)应用学习到的合并操作。在每个单词内贪婪地合并对,直到无法再应用学习到的合并为止。
本文的实现方式:
我们将按照步骤逐步实现整个过程,直接在代码中进行,不使用 Python 函数或类。每个概念步骤将被分解为最小的代码块,并附有详细的理论解释,正如所要求的那样。
第 0 步:准备——导入库和定义语料库
目标:准备环境,导入必要的工具,并定义我们将要处理的文本数据。
第 0.1 步:导入库
理论:我们需要一些基本的 Python 库:
• re:正则表达式库,主要用于将原始文本分割成初始单词/词元单元。
• collections:特别是collections.Counter,用于高效地统计单词和符号对的频率,这是 BPE 的核心。
# 导入必要的标准库
import re
import collections
print("已导入 're' 和 'collections' 库。")
第 0.2 步:定义训练语料库
理论:BPE 是一种数据驱动的算法,它根据训练语料库中的模式学习合并规则。我们将使用刘易斯·卡罗尔的《爱丽丝梦游仙境》的一个小节选作为训练数据。更大的、更多样化的语料库将产生更具通用性的分词器,但这个较小的例子可以让我们更容易地跟踪整个过程。
# 定义用于训练 BPE 分词器的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
print(f"已定义训练语料库(长度:{len(corpus_raw)} 个字符)。")
第 1 步:预处理与初始化
目标:将原始文本语料库转换为 BPE 训练算法所需的初始状态。这包括标准化文本、分割成可管理的单元、统计频率、将这些单元表示为符号序列,并定义起始词汇表。
第 1.1 步:将语料库转换为小写
理论:将整个语料库转换为小写,确保在频率统计和合并过程中,相同的单词(无论其大小写如何,例如“Alice”与“alice”)被视为同一个单元。这简化了整个过程,除非特别需要区分大小写(这需要不同的预处理策略)。
# 将原始语料库转换为小写
corpus_lower = corpus_raw.lower()
print("语料库已转换为小写。")
第 1.2 步:初始单词/词元分割
理论:我们需要将文本分割成基本单元。虽然 BPE 在子词级别操作,但它通常从单词级别单元开始(包括标点符号)。我们使用正则表达式r'\w+|[^\s\w]+'通过re.findall:
• \w+:匹配一个或多个字母数字字符(字母、数字和下划线)。这可以捕获标准单词。
• |:作为逻辑“或”运算符。
• [^\s\w]+:匹配一个或多个不是空白符(\s)且不是单词字符(\w)的字符。这可以捕获标点符号,如逗号、句号、冒号、引号、括号等,作为单独的词元。
结果是一个字符串列表,每个字符串要么是一个单词,要么是一个标点符号。
# 定义用于分割单词和标点符号的正则表达式
split_pattern = r'\w+|[^\s\w]+'
# 应用正则表达式到小写的语料库,获取初始词元列表
initial_word_list = re.findall(split_pattern, corpus_lower)
print(f"语料库已分割为 {len(initial_word_list)} 个初始单词/词元。")
print(f"前 3 个初始词元:{initial_word_list[:3]}")
第 1.3 步:计算单词/词元频率
理论:BPE 的核心是合并最频繁的对。因此,我们需要知道每个独特初始单词/词元在语料库中出现的频率。在更频繁的单词中找到的对将对合并决策产生更大的影响。collections.Counter可以高效地创建一个字典,将每个独特项(单词/词元)映射到其计数。
# 使用 collections.Counter 统计 initial_word_list 中各项的频率
word_frequencies = collections.Counter(initial_word_list)
print(f"已计算 {len(word_frequencies)} 个独特单词/词元的频率。")
print("3 个最频繁的词元及其计数:")
for token, count in word_frequencies.most_common(3):
print(f" '{token}': {count}")
第 1.4 步:初始语料库表示(字符分割与</w>)
理论:BPE 训练在符号序列上操作。我们需要将初始的单词/词元列表转换为这种格式。对于每个独特的单词/词元:
• 将其拆分为单个字符的列表。
• 在列表末尾添加一个特殊的单词结束符号(我们使用</w>)。
这个</w>标记非常重要:
• 边界检测:它防止 BPE 跨越不同单词合并字符。例如,“apples”末尾的“s”不应与“and”开头的“a”合并。
• 学习单词结尾:它允许算法将常见的单词结尾作为独立的子词单元学习(例如“ing”、“ed”、“s”)。
我们将这种映射(原始单词->符号列表)存储在一个字典中。
# 定义特殊的单词结束符号
end_of_word_symbol = '</w>'
# 创建一个字典来保存语料库的初始表示
# 键:原始单词/词元,值:字符列表 + 单词结束符号
initial_corpus_representation = {}
# 遍历由频率计数器识别的每个独特单词
for word in word_frequencies:
# 将单词字符串拆分为字符列表
char_list = list(word)
# 在列表末尾添加单词结束符号
char_list.append(end_of_word_symbol)
# 将该列表存储到字典中,原始单词作为键
initial_corpus_representation[word] = char_list
print(f"已为 {len(initial_corpus_representation)} 个独特单词/词元创建初始语料库表示。")
# 示例单词
example_word = 'beginning'
if example_word in initial_corpus_representation:
print(f"'{example_word}' 的表示:{initial_corpus_representation[example_word]}")
example_punct = '.'
if example_punct in initial_corpus_representation:
print(f"'{example_punct}' 的表示:{initial_corpus_representation[example_punct]}")
第 1.5 步:构建初始字符词汇表
理论:BPE 算法从初始语料库表示中所有单独的符号开始构建词汇表。这包括原始文本中的所有独特字符,以及我们添加的特殊</w>符号。使用 Python 的set可以自动处理唯一性——多次添加相同的字符不会产生任何效果。
# 初始化一个空集合来存储独特的初始符号(词汇表)
initial_vocabulary = set()
# 遍历初始语料库表示中的字符列表
for word in initial_corpus_representation:
# 获取当前单词的符号列表
symbols_list = initial_corpus_representation[word]
# 使用 `update` 方法将这些符号添加到词汇表集合中
initial_vocabulary.update(symbols_list)
# 虽然 `update` 应该已经添加了 '</w>',但为了确保万无一失,可以显式添加
# initial_vocabulary.add(end_of_word_symbol)
print(f"初始词汇表已创建,包含 {len(initial_vocabulary)} 个独特符号。")
print(f"初始词汇表符号:{sorted(list(initial_vocabulary))}")
第 2 步:BPE 训练——迭代合并
目标:这是 BPE 学习的核心阶段。我们将迭代地找到当前语料库表示中出现频率最高的相邻符号对,并将它们合并为一个新的符号(子词)。这个过程构建了子词词汇表和有序的合并规则列表。
第 2.1 步:初始化训练状态变量
理论:在开始循环之前,我们需要:
• num_merges:定义要执行的合并操作次数。这直接决定了最终词汇表的大小(初始大小+num_merges)。选择这个值是一个超参数;较大的值可以捕获更复杂的子词,但会增加词汇表的大小。
• learned_merges:一个空字典,用于存储我们学习到的合并规则。键将是符号对元组(例如('t', 'h')),值将是合并优先级(一个整数,从 0 开始,表示合并的学习顺序)。较小的数字表示较高的优先级。
• current_corpus_split:一个变量,用于保存在每次迭代中被修改的语料库表示的状态。我们将其初始化为initial_corpus_representation的副本,以避免修改原始起点。
• current_vocab:一个变量,用于保存随着新合并符号的增加而增长的词汇表。我们将其初始化为initial_vocabulary的副本。
# 定义期望的合并操作次数
# 这决定了将添加到初始字符词汇表中的新子词数量
num_merges = 75 # 在这个例子中,我们使用 75 次合并
# 初始化一个空字典来存储学习到的合并规则
# 格式:{ (symbol1, symbol2): 合并优先级索引 }
learned_merges = {}
# 创建一个工作副本,用于在训练过程中修改语料库表示
# 使用 .copy() 确保不会修改原始的 initial_corpus_representation
current_corpus_split = initial_corpus_representation.copy()
# 创建一个工作副本,用于在训练过程中修改词汇表
current_vocab = initial_vocabulary.copy()
print(f"训练状态已初始化。目标合并次数:{num_merges}")
print(f"初始词汇表大小:{len(current_vocab)}")
第 2.2 步:主训练循环结构
理论:我们现在将迭代num_merges次。在循环内部,我们执行 BPE 的核心步骤:统计对的频率,找到最佳对,存储规则,创建新符号,更新语料库表示,以及更新词汇表。
# 开始主循环,迭代指定的合并次数
print(f"\n--- 开始 BPE 训练循环 ({num_merges} 次迭代) ---")
for i in range(num_merges):
# --- 代码第 2.3 步到第 2.9 步将放入此循环中 ---
# 打印当前迭代编号(从 1 开始)
print(f"\n迭代 {i + 1}/{num_merges}")
# --- 第 2.3 步(在循环内):计算对的统计信息 ---
# 理论:我们必须在每次迭代中重新计算对的频率,因为语料库表示在每次合并后都会发生变化。
# 一个频繁的对在合并后可能会变得不那么频繁。
# 我们遍历每个独特的原始单词及其频率。对于每个单词,我们从当前语料库表示中获取其符号列表,
# 然后遍历这些符号的相邻对,并根据原始单词的频率增加该对的计数。
print(" 第 2.3 步:计算对的统计信息...")
pair_counts = collections.Counter()
# 遍历原始单词及其频率
for word, freq in word_frequencies.items():
# 获取当前单词的符号列表
symbols = current_corpus_split[word]
# 遍历符号列表中的相邻对
for j in range(len(symbols) - 1):
# 形成对(两个相邻符号的元组)
pair = (symbols[j], symbols[j + 1])
# 根据原始单词的频率增加该对的计数
pair_counts[pair] += freq
print(f" 已计算 {len(pair_counts)} 个独特对的频率。")
# 可选:打印本次迭代中找到的前 5 个对
# if pair_counts:
# print(f" 本次迭代的前 5 个对:{pair_counts.most_common(5)}")
# --- 第 2.4 步(在循环内):检查终止条件 ---
# 理论:如果在统计后 `pair_counts` 为空,这意味着语料库中没有更多的相邻对。
# 这可能发生在语料库非常小,或者所有可能的合并都已完成的情况下。
# 在这种情况下,我们无法继续,因此提前退出训练循环。
print(" 第 2.4 步:检查是否存在对...")
if not pair_counts:
print(" 没有更多可合并的对。提前停止训练循环。")
break # 退出 'for i in range(num_merges)' 循环
print(" 找到对,继续训练。")
# --- 第 2.5 步(在循环内):找到最佳对 ---
# 理论:我们需要找到 `pair_counts` 计数器中频率最高的对。
# `max()` 函数可以接受一个 `key` 参数,指定用于确定排序/比较值的函数。
# `pair_counts.get` 是一个函数,它返回计数器中给定键的值。
# 因此,`max(pair_counts, key=pair_counts.get)` 可以找到频率最高的对。
print(" 第 2.5 步:找到最频繁的对...")
try:
best_pair = max(pair_counts, key=pair_counts.get)
best_pair_frequency = pair_counts[best_pair]
print(f" 找到最佳对:{best_pair},频率为 {best_pair_frequency}")
except ValueError:
# 虽然理论上应该会被前面的 `if not pair_counts` 检查捕获,
# 但添加健壮的错误处理总是好的。
print(" 错误:无法在空的 pair_counts 中找到最大值。停止训练。")
break
# --- 第 2.6 步(在循环内):存储合并规则 ---
# 理论:我们记录在本次迭代中选择合并的对。优先级就是迭代索引 `i`。
# 这个有序的合并列表对于后续正确分词新文本至关重要。
print(f" 第 2.6 步:存储合并规则(优先级:{i})...")
learned_merges[best_pair] = i
print(f" 已存储:{best_pair} -> 优先级 {i}")
# --- 第 2.7 步(在循环内):创建新符号 ---
# 理论:通过简单地将对中两个符号的字符串表示拼接起来,
# 创建表示合并后的新符号。
print(" 第 2.7 步:从最佳对创建新符号...")
new_symbol = "".join(best_pair)
print(f" 创建的新符号:'{new_symbol}'")
# --- 第 2.8 步(在循环内):更新语料库表示 ---
# 理论:这是循环中最复杂的一部分。我们需要遍历 `current_corpus_split`
# 中的每个单词表示,并将 *所有* 出现的 `best_pair` 序列替换为 `new_symbol`。
# 重要的是,我们需要创建一个新的字典 `next_corpus_split` 来存储这些结果,
# 而不是在迭代时直接修改 `current_corpus_split`。
# 对于每个单词,我们扫描其当前的符号列表(`old_symbols`),构建一个新的符号列表(`new_symbols`)。
# 如果我们在索引 `k` 处发现 `best_pair`,则将 `new_symbol` 添加到 `new_symbols` 中,
# 并将扫描位置 `k` 向前移动 2 位。否则,我们只将 `old_symbols[k]` 添加到 `new_symbols` 中,
# 并将 `k` 向前移动 1 位。
# 处理完所有单词后,`current_corpus_split` 将被更新为 `next_corpus_split`,
# 以供 *下一次* 训练迭代使用。
print(" 第 2.8 步:更新语料库表示...")
next_corpus_split = {}
# 遍历所有原始单词(`current_corpus_split` 字典中的键)
for word in current_corpus_split:
# 获取该单词在应用当前合并之前的符号列表
old_symbols = current_corpus_split[word]
# 初始化一个空列表,用于构建该单词的新符号序列
new_symbols = []
# 初始化扫描索引
k = 0
# 扫描旧符号列表
while k < len(old_symbols):
# 检查是否不是最后一个符号(以便形成对),并且从索引 k 开始的对是否是最佳对
if k < len(old_symbols) - 1 and (old_symbols[k], old_symbols[k + 1]) == best_pair:
# 如果找到匹配项,则将新合并的符号添加到新列表中
new_symbols.append(new_symbol)
# 将扫描索引向前移动 2 位(跳过合并对的两个部分)
k += 2
else:
# 如果未找到匹配项,则将旧列表中的当前符号添加到新列表中
new_symbols.append(old_symbols[k])
# 将扫描索引向前移动 1 位
k += 1
# 将新构建的符号列表存储到临时字典中
next_corpus_split[word] = new_symbols
# 处理完所有单词后,将 `current_corpus_split` 更新为反映合并操作的新值
current_corpus_split = next_corpus_split
print(" 已更新语料库表示。")
# 可选:展示某个单词在本次合并后的变化
# if 'beginning' in current_corpus_split:
# print(f" 示例 'beginning' 现在:{current_corpus_split['beginning']}")
# --- 第 2.9 步(在循环内):更新词汇表 ---
# 理论:将新创建的 `new_symbol`(合并的结果)添加到 `current_vocab` 集合中。
# 集合会自动处理重复项。
print(" 第 2.9 步:更新词汇表...")
current_vocab.add(new_symbol)
print(f" 已将 '{new_symbol}' 添加到词汇表。当前大小:{len(current_vocab)}")
# --- 第 2.10 步:训练循环结束 ---
# 理论:循环完成(无论是达到 `num_merges` 次迭代还是提前退出)后,
# 训练过程就结束了。最终的学习状态包含在 `learned_merges`、`current_vocab` 和 `current_corpus_split` 中。
print(f"\n--- BPE 训练循环完成,共进行了 {i + 1} 次迭代(或达到目标) ---")
# 为清晰起见,将最终状态变量分配给新的变量名(可选,也可以直接使用 current_*)
final_vocabulary = current_vocab
final_learned_merges = learned_merges
final_corpus_representation = current_corpus_split
print("最终的词汇表、合并规则和语料库表示已准备就绪。")
第 3 步:检查训练结果
目标:检查 BPE 训练过程中产生的结果,以了解算法学到了什么。
第 3.1 步:最终词汇表大小
理论:最终词汇表包含所有初始字符以及在合并过程中创建的所有新子词符号。其大小是训练的一个关键结果。
print("--- 检查训练结果 ---")
print(f"最终词汇表大小:{len(final_vocabulary)} 个词元")
第 3.2 步:按优先级排序的学习合并规则
理论:final_learned_merges字典包含了关于哪些对被合并以及合并的顺序(优先级)的关键信息。为了理解整个过程并在分词时正确应用这些规则,按优先级(即迭代索引i)排序查看这些合并规则会很有帮助。
print("\n按优先级排序的学习合并规则:")
# 将字典项转换为 (对, 优先级) 元组列表
merges_list = list(final_learned_merges.items())
# 根据优先级(元组的第二个元素,索引为 1)对列表进行排序
# `lambda item: item[1]` 告诉排序函数使用优先级值进行排序
sorted_merges_list = sorted(merges_list, key=lambda item: item[1])
# 显示排序后的合并规则
print(f"总共学习到的合并规则数:{len(sorted_merges_list)}")
# 如果列表很长,则只显示部分规则,否则全部显示
display_limit = 20
if len(sorted_merges_list) <= display_limit * 2:
for pair, priority in sorted_merges_list:
print(f" 优先级 {priority}: {pair} -> '{''.join(pair)}'")
else:
print(" (显示前 10 条和最后 10 条合并规则)")
# 显示前 N 条
for pair, priority in sorted_merges_list[:display_limit // 2]:
print(f" 优先级 {priority}: {pair} -> '{''.join(pair)}'")
print(" ...")
# 显示最后 N 条
for pair, priority in sorted_merges_list[-display_limit // 2:]:
print(f" 优先级 {priority}: {pair} -> '{''.join(pair)}'")
第 3.3 步:训练语料库中示例单词的最终表示
理论:查看训练语料库中某些单词在应用所有合并操作后的最终表示会很有用。这展示了根据学习到的 BPE 规则,已知单词的最终词元序列。
print("\n训练语料库中示例单词的最终表示:")
# 列出一些我们期望看到有趣分词的单词
example_words_to_inspect = ['beginning', 'conversations', 'sister', 'pictures', 'reading', 'alice']
for word in example_words_to_inspect:
if word in final_corpus_representation:
print(f" '{word}': {final_corpus_representation[word]}")
else:
print(f" '{word}': 未在原始语料库中找到(如果从语料库中选择,不应发生这种情况)。")
第 4 步:使用学习到的规则对新文本进行分词
目标:应用训练过程中学到的 BPE 规则(final_learned_merges),将一段新的、未见过的文本分割成一系列词元(字符和来自final_vocabulary的子词)。
第 4.1 步:定义新文本输入
理论:我们需要一段样本句子或文本,BPE 模型在训练过程中可能没有见过。这可以用来展示其对新输入的分词能力,可能包含训练中未见过的单词或变体。
# 定义一段新文本,用于使用学到的 BPE 规则进行分词
# 这段文本包含训练中见过的单词(如“alice”、“pictures”),
# 以及可能未见过的单词或变体(如“tiresome”、“thought”)
new_text_to_tokenize = "Alice thought reading was tiresome without pictures."
print(f"--- 对新文本进行分词 ---")
print(f"输入文本:'{new_text_to_tokenize}'")
第 4.2 步:预处理新文本
理论:对新文本进行预处理是绝对关键的,必须与训练数据的预处理步骤完全一致。这包括小写化和使用相同的方法(此处为相同的正则表达式)进行分割。
print("第 4.2 步:对新文本进行预处理...")
# 1. 将新文本转换为小写
new_text_lower = new_text_to_tokenize.lower()
print(f" 小写化:'{new_text_lower}'")
# 2. 使用与训练相同的正则表达式分割成单词/词元
# 回忆:split_pattern = r'\w+|[^\s\w]+'
new_words_list = re.findall(split_pattern, new_text_lower)
print(f" 分割成单词/词元:{new_words_list}")
第 4.3 步:准备分词输出
理论:我们初始化一个空列表,用于存储整个输入文本的最终词元序列,随着对每个单词的处理,逐步填充这个列表。
# 初始化一个空列表,用于存储整个文本的最终词元序列
tokenized_output = []
print("第 4.3 步:已初始化空列表用于存储分词结果。")
第 4.4 步:遍历新文本中的单词(第 4.5 步到第 4.7 步将放入此循环中)
理论:现在,我们逐个处理从预处理步骤(new_words_list)中得到的每个单词/词元。对于每个单词,我们将应用学到的 BPE 合并规则。
print("第 4.4 步:开始遍历新文本中的单词...")
# 遍历新文本中的每个预处理单词/词元
for word in new_words_list:
print(f"\n 处理单词:'{word}'")
# --- 第 4.5 步到第 4.7 步将放入此循环中 ---
# --- 第 4.5 步(在单词循环内):初始化单词符号 ---
# 理论:与训练初始化一样,将当前单词表示为其字符列表加上单词结束符号。
# 这是为这个特定单词应用合并的起点。
print(" 第 4.5 步:初始化该单词的符号...")
word_symbols = list(word) + [end_of_word_symbol] # 回忆:end_of_word_symbol = '</w>'
print(f" 初始符号:{word_symbols}")
# --- 第 4.6 步(在单词循环内):内循环应用合并 ---
# 理论:这是对 *单个* 单词进行分词的核心逻辑。
# 我们需要反复应用 `final_learned_merges` 中学到的合并规则到 `word_symbols` 列表。
# 关键规则是:在每次迭代中,找到当前 *所有* 可应用的合并规则中优先级 *最高*(即合并索引最小)的那一个。
# 应用该合并后,更新 `word_symbols` 列表,然后 *重复* 过程:再次扫描新的列表,寻找下一个最高优先级的可应用合并。
# 这个过程会一直持续,直到完成一次完整的扫描,没有找到任何可应用的合并规则为止。
print(" 第 4.6 步:迭代应用学到的合并规则...")
while True: # 直到无法再对这个单词应用合并规则为止
# --- 找到当前轮次的最佳合并 ---
# 初始化变量,用于跟踪本轮次中找到的最佳合并
best_priority_found_this_pass = float('inf') # 使用无穷大,确保任何有效优先级都更低
pair_to_merge_this_pass = None
merge_location_this_pass = -1
# 扫描当前的 word_symbols 列表,寻找可应用的合并
scan_index = 0
while scan_index < len(word_symbols) - 1:
# 形成当前扫描索引处的相邻对
current_pair = (word_symbols[scan_index], word_symbols[scan_index + 1])
# 检查这对是否存在于我们的合并规则中
if current_pair in final_learned_merges:
# 如果存在,获取其优先级(何时学到的)
current_pair_priority = final_learned_merges[current_pair]
# 检查这对的优先级是否比本轮次中找到的最佳优先级更低
if current_pair_priority < best_priority_found_this_pass:
# 如果是,更新本轮次中找到的最佳合并
best_priority_found_this_pass = current_pair_priority
pair_to_merge_this_pass = current_pair
merge_location_this_pass = scan_index # 记录最佳合并的起始位置
# 移动到下一个位置,检查下一个对
scan_index += 1
# --- 应用本轮次找到的最佳合并(如果有的话),否则退出 ---
# 完成对当前 word_symbols 列表的扫描后:
if pair_to_merge_this_pass is not None:
# 找到了可应用的合并。应用优先级最高的那个。
merged_symbol = "".join(pair_to_merge_this_pass)
print(f" 应用最高优先级的合并:{pair_to_merge_this_pass}(优先级 {best_priority_found_this_pass})在索引 {merge_location_this_pass} -> '{merged_symbol}'")
# 使用合并后的符号重建 word_symbols 列表
# 切片操作:合并前的部分 + 新符号 + 合并后的部分
word_symbols = word_symbols[:merge_location_this_pass] + [merged_symbol] + word_symbols[merge_location_this_pass + 2:]
print(f" 更新后的符号:{word_symbols}")
# 继续下一次 'while True' 循环迭代,扫描 *更新后的* 符号列表
else:
# 在整个扫描过程中没有找到可应用的合并规则
print(" 本轮次未找到可应用的合并规则。")
break # 退出 'while True' 循环,处理下一个单词
# --- 第 4.7 步(在单词循环内):将最终单词词元追加到输出 ---
# 理论:经过内层 'while True' 循环后,`word_symbols` 包含了当前单词的最终词元序列。
# 我们使用 `extend` 将这些词元追加到主 `tokenized_output` 列表中。
print(" 第 4.7 步:将该单词的最终词元追加到总输出...")
tokenized_output.extend(word_symbols)
print(f" 已追加:{word_symbols}")
print("\n已完成对新文本中所有单词的处理。")
第 4.8 步:显示最终分词结果
理论:最后,显示原始输入文本以及应用学到的 BPE 规则后生成的完整词元序列。这展示了整个分词过程的结果。
print("\n--- 最终分词结果 ---")
print(f"原始输入文本:'{new_text_to_tokenize}'")
print(f"分词结果(共 {len(tokenized_output)} 个词元):{tokenized_output}")
第 5 步:总结
这篇文章通过极其详细的步骤,从零实现了 Byte Pair Encoding(BPE)算法,用于文本分词。为了避免使用函数或类,我们直接在代码中暴露了每个阶段的核心逻辑。
我们严格遵循了以下关键阶段:
• 初始化与预处理:对输入文本进行标准化(小写化),执行初始分割(单词和标点符号),计算频率,将单词表示为字符序列,并添加关键的</w>单词结束标记以构建初始词汇表。
• 迭代训练:按照预定义的合并次数进行循环。在每次迭代中,我们精确统计当前语料库中相邻符号对的频率(考虑单词频率),识别出最频繁的符号对,记录这一合并操作及其优先级(基于迭代编号),创建新的子词符号,更新整个语料库表示(将合并后的符号替换为新符号),并将新符号添加到词汇表中。
• 检查结果:我们检查了最终词汇表的大小,按学习顺序排序的合并规则列表,以及训练语料库中示例单词的最终表示形式。
• 对新文本进行分词:我们对一段未见过的文本输入进行了处理,应用了与训练数据完全相同的预处理步骤。对于每个单词,我们迭代地应用学习到的合并规则。在每次分词步骤中,我们找到优先级最高(最早学习到)的可应用合并规则,应用该合并规则,并重复此过程,直到无法再应用任何学习到的合并规则为止。
最终的tokenized_output是一个字符串序列,其中每个字符串要么是原始字符,要么是来自最终 BPE 词汇表的子词。这个序列根据从训练语料库中学习到的模式对原始输入文本进行了分割。这种详细的分解展示了 BPE 的核心机制,为现代 NLP 模型中更优化、更复杂的分词器奠定了基础。