引言
近年来,大模型的参数规模不断攀升,如何在保证性能的前提下降低计算成本和显存消耗,成为业界关注的重点问题。混合专家模型(Mixture of Experts, MoE)应运而生,通过“分而治之”的设计理念,利用条件计算实现部分参数激活,从而在大容量模型中实现高效推理。本文将详细介绍MoE的核心原理、技术演进、实现细节,并通过一个通俗易懂的智能翻译系统案例,展示其在实际应用中的优势。
一、MoE的核心原理与架构设计
1.1 稀疏专家层:分而治之的基础
传统的前馈网络(FFN)通常采用固定参数矩阵处理所有输入,而MoE通过引入多个独立的专家网络,将整个模型分解为若干小型模块。每个专家(如多层感知机,MLP)负责处理特定的输入子集,模型只在推理时激活少量专家,从而实现“稀疏计算”。这种设计不仅在参数规模上可以突破瓶颈(例如实现万亿级参数),同时每次仅激活3%~5%的参数,有效降低了计算资源的消耗。
1.2 动态路由机制:条件计算的范式突破
MoE的另一大核心在于动态路由机制。通过门控网络(Router),系统根据每个输入 token 的特征分配不同专家的权重,通常只选择 Top-K 个专家(例如K=1或2)。数学上,我们可以将MoE层的输出表达为:
𝑦 = ∑₍𝑖=1₎ᴷ gᵢ(x) ⋅ Eᵢ(x)
其中:
-
gᵢ(x) 表示为第i个专家分配的权重;
-
Eᵢ(x) 为对应专家对输入x的处理结果。
这种基于条件计算的设计,使得模型在保持大容量的同时,只计算关键部分,极大提高了效率。
1.3 参数共享与模型扩展性
除专家层外,其它组件(如自注意力层)依然采用参数共享机制,进一步节省显存并降低计算开销。此外,通过增加专家数量,MoE模型的能力可以近似线性扩展,为构建超大规模模型提供了灵活且高效的路径。
二、技术演进与创新细节
2.1 从早期探索到工业级落地
-
早期探索:2017年,Google提出Sparsely-Gated MoE,奠定了稀疏计算和条件路由的理论基础。
-
规模扩展:2021年推出的Switch Transformer成功实现了万亿参数级模型,并在实际应用中展现出高效计算能力。
-
工业级应用:2024年,DeepSeek-R1通过优化负载均衡和并行训练策略,将MoE从实验室原型推向商业应用。
2.2 最新进展:Expert Choice 路由与量化压缩
2025年,Google推出的Expert Choice路由技术结合了动态路由与量化压缩技术,不仅在训练过程中大幅提升效率(训练效率可提升2倍),而且在推理时进一步降低了硬件要求。这种创新使得MoE架构更适合大规模部署,为未来的AGI(人工通用智能)铺平了道路。
三、技术实现细节
3.1 实现
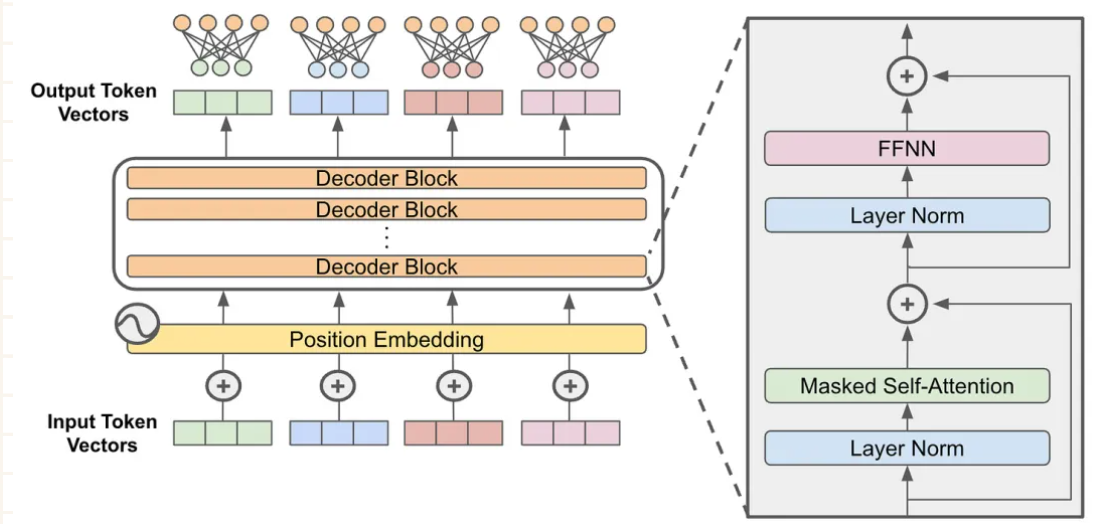
上图展示了大多数生成式 LLM 使用的标准解码器专用 Transformer 架构。在 LLM 的背景下,MoE 对该架构做了简单改动——我们将前馈子层替换为 MoE 层!这个 MoE 层由多个专家构成(专家数量从几位 [13] 到数千位 [5] 不等),每位专家本质上是一个独立的前馈子层,拥有独立参数。
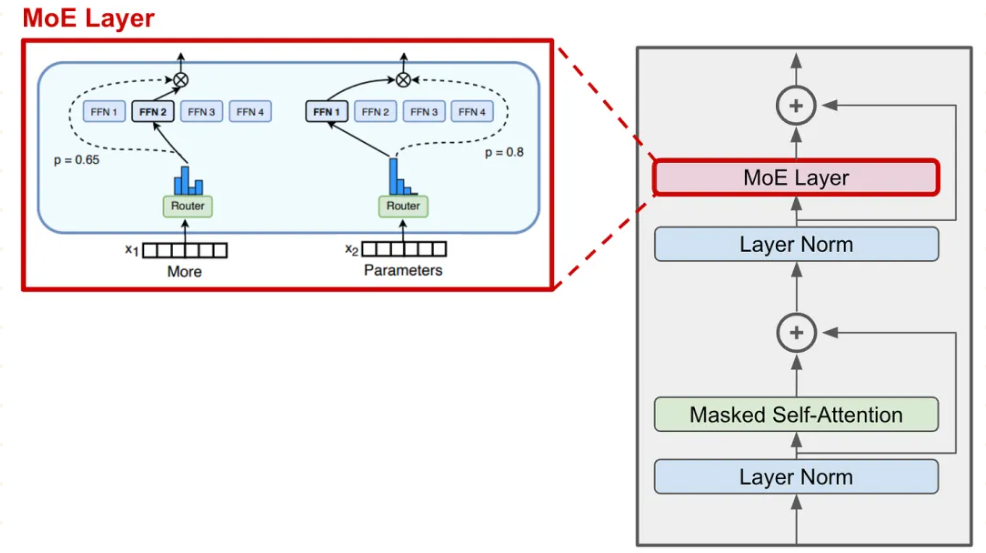
我们同样可以将编码器-解码器转换器转换成 MoE 模型,方法是将编码器和解码器中的前馈子层替换为 MoE 层。但通常只替换其中的一部分(例如每隔一层替换一次)。本文主要概述基于编码器-解码器转换器的 MoE 模型。
稀疏专家方法看似会为模型增加大量参数,因为在 Transformer 的每个前馈子层内,MoE 模型都包含多个独立神经网络(而非单一前馈神经网络)。不过,在前向传递时仅激活每个 MoE 层中的一小部分专家!对于给定的 token 序列,我们使用路由机制稀疏地选择一组专家来处理每个 token。因此,MoE 模型的前向计算成本远低于参数量相同的密集模型。
当应用于 Transformer 模型时,MoE 层主要由两个部分构成:
-
稀疏 MoE 层:使用多个结构类似的“专家”构成稀疏层,取代 Transformer 中的密集前馈层。
-
路由器(Router):负责确定哪些 token 发送到 MoE 层中的哪些专家。
在稀疏 MoE 层中,每个专家只是一个前馈神经网络,拥有独立参数,其架构模仿标准 Transformer 前馈子层。路由器以每个 token 为输入,生成一组专家概率分布,从而确定该 token 应发送给哪位专家。
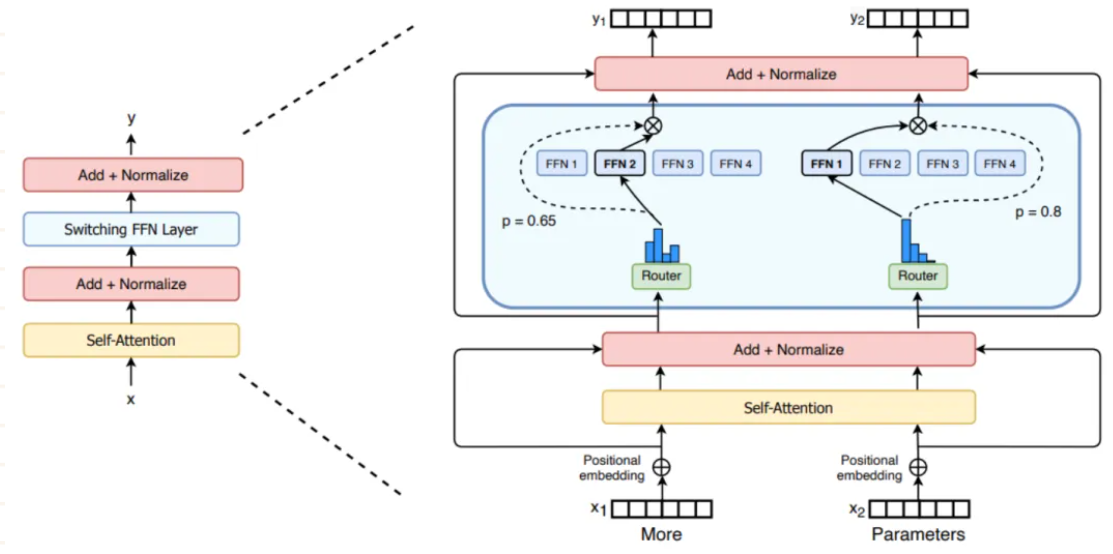
路由器自身具有独立参数,并与网络其他部分共同训练。每个 token 可以发送给多个专家,但通常只选取顶级 K 个专家以保持稀疏性。例如,许多模型设定 k=1 或 k=2,即每个 token 分别由一位或两位专家处理。
3.2 路由算法:Top-K选择与Expert Choice
目前主流的路由算法基于Top-K选择机制,但也存在专家负载不均的问题。为了解决这一瓶颈,Expert Choice(EC)路由技术引入了反向路由机制,即让专家主动选择与之匹配的token,这不仅提高了负载均衡效率,同时使得整个训练过程更加稳定。此外,COMET算法通过树状稀疏选择将计算复杂度降至 O(logN),使得大规模专家网络的部署变得更为高效。
3.3 训练优化:负载均衡与混合精度
-
负载均衡损失:在训练过程中,辅助损失函数被用来强制专家的利用率均衡,防止某些专家过载而其他专家闲置。
-
混合精度训练:采用低精度(如FP8)训练,不仅降低了显存占用,还加速了整个训练过程。
-
专家并行与数据并行:通过结合专家并行和数据并行技术,MoE模型在千卡级分布式训练中表现出色,有效缩短了训练时间。
四、应用场景与直观案例
4.1 典型应用领域
-
自然语言处理(NLP):在机器翻译、代码生成、对话系统等任务中,通过针对不同语言或任务特性分配专家,MoE显著提高了系统的鲁棒性和精确度。
-
计算机视觉:在图像分类、目标检测等任务中,基于ViT的V-MoE模型通过激活针对性专家,实现了准确率的显著提升。
-
多模态应用:在视频理解和设备控制等场景下,MoE模型通过专家协作,实现了多任务处理和端侧高效部署。
4.2 通俗易懂案例——智能翻译系统
假设我们要构建一个智能翻译系统,支持多语言翻译。传统系统需要为所有语言训练统一的翻译模型,而MoE架构可以为不同语言对设计专门的专家:
-
专家分工:针对英语-法语、英语-中文、英语-日语等不同语言对,各自分配独立的小型专家。
-
动态路由:当用户输入一段英语文本时,路由器会根据输入的语境和特征,选择最合适的语言专家进行翻译。
-
效率提升:尽管系统总体参数量可能达到数百亿甚至上千亿,但每次翻译过程中仅激活一两个专家,大幅降低了计算资源消耗,同时提高翻译质量(实验数据显示质量提升约15%)。
这种“专家分工、按需激活”的机制,使得系统在处理多语言任务时既能保持高效计算,又能针对性地提高翻译精度。
五、挑战与未来展望
5.1 当前挑战
-
训练不稳定性:由于路由震荡和专家负载不均,MoE模型在训练初期可能面临不稳定问题。
-
显存占用:所有专家参数需要常驻内存,部分MoE模型在部署时显存需求极高(如45B参数模型)。
-
专家专业化不足:部分专家可能在实际任务中未能充分发挥作用,存在冗余问题。
5.2 优化方向
-
动态专家剪枝:通过MoE-Pruner移除低贡献专家,可减少约30%的参数,降低计算和存储资源的需求。
-
量化与蒸馏:采用1比特量化技术(QMoE)在降低显存占用的同时,依然保持模型推理性能。
-
多任务预训练:让各专家专注于特定领域(例如法律、医学),增强模型专业化能力,从而提升各领域任务的表现。