文章目录
- 面向预测分析的神经网络简介
- 神经网络模型
- 1. 基本概念
- 2. 前馈神经网络
- 3. 常见激活函数
- 4. 循环神经网络(RNN)
- 5. 卷积神经网络(CNN)
- MPL
- 结构
- 工作原理
- 激活函数
- 训练方法
- 基于神经网络的回归——以钻石为例
- 构建预测钻石价格的MLP
- 训练 M L P MLP MLP
- 基于神经网络的分类
面向预测分析的神经网络简介
神经网络模型
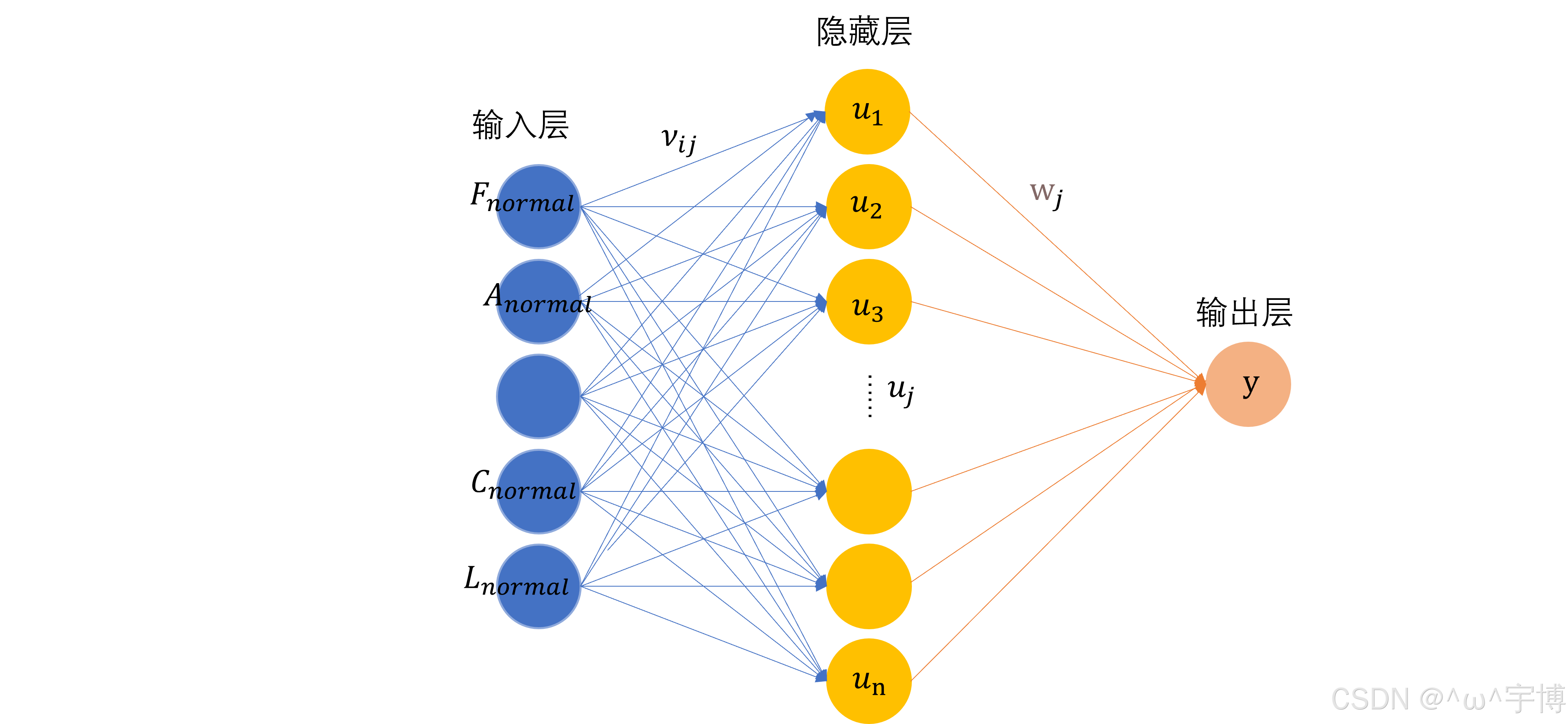
神经网络(Neural Network),也被称为人工神经网络(Artificial Neural Network,ANN),是一种模仿人类神经系统的计算模型,在机器学习和深度学习领域应用广泛。
1. 基本概念
- 神经元:神经网络的基本计算单元,接收多个输入信号,通过激活函数对输入进行非线性变换后输出结果。一个简单的神经元可以表示为 y = f ( ∑ i = 1 n w i x i + b ) y = f(\sum_{i = 1}^{n}w_{i}x_{i}+b) y=f(∑i=1nwixi+b),其中 x i x_i xi 是输入, w i w_i wi 是对应的权重, b b b 是偏置, f f f激活函数。
- 层:多个神经元组成一层,常见的层包括输入层、隐藏层和输出层。输入层接收原始数据;隐藏层对输入数据进行特征提取和转换;输出层给出最终的预测结果。
- 网络结构:不同层之间相互连接形成神经网络的结构,常见的有前馈神经网络(Feed - Forward Neural Network),信息只能从输入层依次向前传递到输出层;还有循环神经网络(Recurrent Neural Network,RNN),它允许信息在网络中循环流动,适合处理序列数据。
2. 前馈神经网络
- 工作原理:输入数据从输入层进入,经过隐藏层的一系列计算和变换,最终在输出层得到预测结果。每一层的神经元将上一层的输出作为输入,通过加权求和和激活函数处理后传递给下一层。
- 训练过程
- 定义损失函数:用于衡量预测结果与真实标签之间的差异,常见的损失函数有均方误差(Mean Squared Error,MSE)用于回归问题,交叉熵损失(Cross - Entropy Loss)用于分类问题。
- 前向传播:将输入数据传入网络,计算得到预测结果。
- 反向传播:根据损失函数的梯度,从输出层开始反向计算每个参数(权重和偏置)的梯度,以确定如何调整参数来减小损失。
- 参数更新:使用优化算法(如随机梯度下降,SGD)根据计算得到的梯度更新网络中的参数。
3. 常见激活函数
- Sigmoid函数:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1 + e^{-x}} f(x)=1+e−x1
将输入值映射到 (0, 1) 区间,常用于二分类问题的输出层。但它存在梯度消失问题,即当输入值过大或过小时,梯度趋近于 0,导致训练速度变慢。
- ReLU函数:
f ( x ) = max ( 0 , x ) f(x)=\max(0,x) f(x)=max(0,x)
计算简单,能有效缓解梯度消失问题,在隐藏层中应用广泛。
- Softmax函数:
常用于多分类问题的输出层,将输入值转换为概率分布,所有输出值之和为 1。
4. 循环神经网络(RNN)
- 特点:RNN 引入了循环结构,允许信息在不同时间步之间传递,因此能够处理序列数据,如自然语言处理中的文本序列、时间序列分析中的股票价格数据等。
- 局限性:传统的 RNN 存在长期依赖问题,即难以捕捉序列中相隔较远的信息之间的关系。为了解决这个问题,出现了长短期记忆网络(LSTM)和门控循环单元(GRU)等改进模型。
5. 卷积神经网络(CNN)
- 原理:CNN 主要用于处理具有网格结构的数据,如图像。它通过卷积层、池化层和全连接层组成。卷积层使用卷积核在输入数据上滑动进行卷积操作,提取局部特征;池化层用于降低特征图的维度,减少计算量;全连接层将卷积和池化得到的特征进行整合,输出最终的预测结果。
- 优势:CNN 具有参数共享和局部连接的特点,大大减少了模型的参数数量,降低了计算复杂度,同时提高了模型的泛化能力。
MPL
MLP通常指多层感知机(Multilayer Perceptron),它是一种基础且经典的人工神经网络模型,下面从结构、工作原理、激活函数、训练方法、优缺点和应用场景等方面为你详细介绍:
结构
MLP由输入层、一个或多个隐藏层以及输出层组成。
- 输入层:负责接收原始数据,神经元的数量通常等于输入特征的数量。
- 隐藏层:可以有一层或多层,每一层包含多个神经元。隐藏层通过非线性变换对输入数据进行特征提取和转换,是MLP学习复杂模式的关键部分。
- 输出层:输出模型的预测结果,神经元的数量根据具体的任务而定。例如,在二分类问题中,输出层可能只有一个神经元;在多分类问题中,输出层的神经元数量等于类别数。
工作原理
MLP的工作过程分为前向传播和反向传播。
- 前向传播:输入数据从输入层传入,依次经过各个隐藏层,最终到达输出层。在每一层中,神经元会对输入进行加权求和,并通过激活函数进行非线性变换,将结果传递给下一层。
- 反向传播:根据输出层的预测结果与真实标签之间的误差,计算误差关于每个神经元权重的梯度,然后使用优化算法(如梯度下降法)更新权重,以减小误差。
激活函数
激活函数为MLP引入非线性特性,使其能够学习复杂的非线性关系。常见的激活函数有:
- Sigmoid函数:将输入映射到(0, 1)区间,常用于二分类问题的输出层。
- ReLU函数:当输入大于0时,输出等于输入;当输入小于等于0时,输出为0。它计算简单,能有效缓解梯度消失问题,是隐藏层中常用的激活函数。
- Softmax函数:常用于多分类问题的输出层,将输出转换为概率分布。
训练方法
MLP通常使用误差反向传播算法(Backpropagation)进行训练,具体步骤如下:
- 初始化权重:随机初始化MLP中所有神经元之间的连接权重。
- 前向传播:将输入数据传入网络,计算输出结果。
- 计算误差:根据输出结果与真实标签之间的差异,计算损失函数的值。
- 反向传播:计算误差关于每个权重的梯度。
- 更新权重:使用优化算法(如随机梯度下降、Adam等)根据梯度更新权重。
- 重复步骤2 - 5:直到损失函数收敛或达到预设的训练轮数。
基于神经网络的回归——以钻石为例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
%matplotlib inline
DATA_DIR = '../data'
FILE_NAME = 'diamonds.csv'
data_path = os.path.join(DATA_DIR, FILE_NAME)
diamonds = pd.read_csv(data_path)
# 数据预处理
diamonds = diamonds.loc[(diamonds['x'] > 0) | (diamonds['y'] > 0)]
diamonds.loc[11182, 'x'] = diamonds['x'].median()
diamonds.loc[11182, 'z'] = diamonds['z'].median()
diamonds = diamonds.loc[~((diamonds['y'] > 30) | (diamonds['z'] > 30))]
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['cut'], prefix='cut', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['color'], prefix='color', drop_first=True)], axis=1)
diamonds = pd.concat([diamonds, pd.get_dummies(diamonds['clarity'], prefix='clarity', drop_first=True)], axis=1)
# 分割数据集
X = diamonds.drop(['cut', 'color', 'clarity', 'price'], axis=1)
y = diamonds['price']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=123)
# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=1, random_state=123)
pca.fit(X_train[['x', 'y', 'z']])
X_train['dim_index'] = pca.transform(X_train[['x', 'y', 'z']]).flatten()
X_train.drop(['x', 'y', 'z'], axis=1, inplace=True)
# 标准化数值特征
numerical_features = ['carat', 'depth', 'table', 'dim_index']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train[numerical_features])
X_train.loc[:, numerical_features] = scaler.transform(X_train[numerical_features])
现在我们完成了神经网络的建模工作。
构建预测钻石价格的MLP
如前面所述,神经网络模型由一系列的层组成,因此Keras有一个类称为Sequential这个类可以用来实例化神经网络模型:
from keras.models import Sequential
nn_reg = Sequential()
现在需要为它添加层——奖使用的层名为全连接层或者稠密层:
from keras.layers import Dense
接下来添加第一层:
n_input=X_train.shape[1]
n_hidden1=32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1,activation='relu',input_shape=(n_input,)))
units:这是层中神经元的个数activation:这是每个神经元的激活函数,这里选用:ReLuinput_shape:这是网络接受的输入个数,其值等于数据集合中预测特征的个数。
接下来我们可以添加更多的隐藏层:
n_hidden2=16
n_hidden3=8
nn_reg.add(Dense(units=n_hidden2,activation='relu'))
nn_reg.add(Dense(units=n_hidden3,activation='relu'))
......
注意:这里使用各层的单元个数以
2
2
2的乘方逐次减少。
我们现在还需要添加一个最终层——输出层。对于每个样本来说,这是一个回归问题,需要的结果只有一个。因此添加最后一层:
nn_reg.add(Dense(units=1,activation=None))
接下来就要训练 M L P MLP MLP了,修正这些随机的权重和偏置。
训练 M L P MLP MLP
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, r2_score
# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...
# 训练MLP模型
mlp = MLPRegressor(hidden_layer_sizes=(100, 50), # 两个隐藏层,分别有100和50个神经元
activation='relu', # 使用ReLU激活函数
solver='adam', # 使用Adam优化器
random_state=123,
max_iter=500) # 最大迭代次数
mlp.fit(X_train, y_train)
# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = mlp.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")
all
import numpy as np
import pandas as pd
import os
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import mean_squared_error, r2_score
# 假设之前的数据预处理代码已经执行,这里接着进行模型训练
# ...之前的数据预处理代码...
# 创建Sequential模型
nn_reg = Sequential()
# 获取输入特征的数量
n_input = X_train.shape[1]
n_hidden1 = 32
# 增加第一个隐藏层
nn_reg.add(Dense(units=n_hidden1, activation='relu', input_shape=(n_input,)))
# 添加更多的隐藏层
n_hidden2 = 16
n_hidden3 = 8
nn_reg.add(Dense(units=n_hidden2, activation='relu'))
nn_reg.add(Dense(units=n_hidden3, activation='relu'))
# 添加输出层
nn_reg.add(Dense(units=1, activation=None))
# 编译模型
nn_reg.compile(optimizer='adam', # 使用Adam优化器
loss='mse', # 使用均方误差作为损失函数
metrics=['mse']) # 监控均方误差
# 训练模型
history = nn_reg.fit(X_train, y_train,
epochs=50, # 训练的轮数
batch_size=32, # 每个批次的样本数
validation_split=0.1, # 用于验证集的比例
verbose=1)
# 对测试集进行预测
X_test['dim_index'] = pca.transform(X_test[['x', 'y', 'z']]).flatten()
X_test.drop(['x', 'y', 'z'], axis=1, inplace=True)
X_test.loc[:, numerical_features] = scaler.transform(X_test[numerical_features])
y_pred = nn_reg.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"均方误差 (MSE): {mse}")
print(f"决定系数 (R²): {r2}")
# 绘制训练和验证损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
基于神经网络的分类
类似的,这里先水一下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 数据预处理
# 数据标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 标签编码
encoder = OneHotEncoder(sparse_output=False)
y = encoder.fit_transform(y.reshape(-1, 1))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
model = Sequential()
model.add(Dense(16, activation='relu', input_shape=(X_train.shape[1],)))
model.add(Dense(8, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=16, validation_split=0.1)
# 评估模型
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_test_classes = np.argmax(y_test, axis=1)
accuracy = accuracy_score(y_test_classes, y_pred_classes)
print(f"模型准确率: {accuracy}")