第57篇:LlamaIndex使用指南:构建高效知识库
摘要
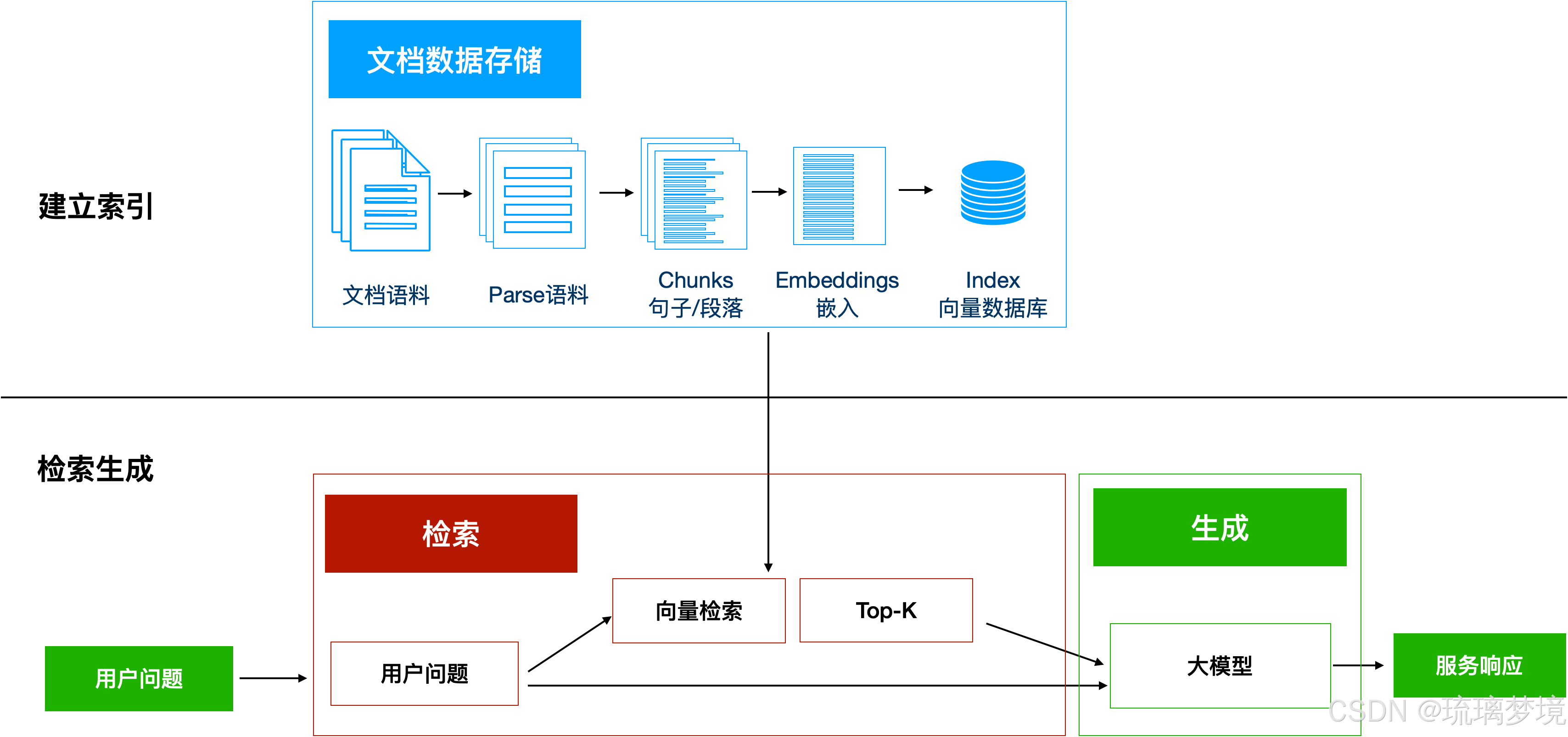
在大语言模型(LLM)驱动的智能应用中,如何高效地管理和利用海量知识数据是开发者面临的核心挑战之一。LlamaIndex(原 GPT Index) 是一个专为构建大模型知识库设计的框架,它提供了从数据摄入、索引构建到查询优化的完整解决方案。
本文将全面介绍 LlamaIndex 的核心功能和技术特点,并通过实战代码示例展示如何构建高效的知识库应用。我们将涵盖从基础架构到高级应用开发的全流程,帮助你快速掌握这一强大的工具!

核心概念与知识点
1. LlamaIndex基础架构【实战部分】
核心概念
LlamaIndex 的核心架构围绕以下几个关键组件展开:
- Documents:原始数据源,如文档、网页、API 数据等。
- Nodes:经过分块和解析后的最小处理单元。
- Indices:索引结构,用于加速检索。
- Retrievers:负责从索引中提取相关节点。
架构设计
LlamaIndex 的工作流程可以分为三个阶段:
- 数据摄入:从多种数据源加载并解析数据。
- 索引构建:将解析后的数据转化为高效的索引结构。
- 查询执行:通过检索器和响应合成器生成最终答案。
最新版本特性
最新版本引入了以下高级功能:
- 高级检索:支持混合检索策略,如向量+关键词组合。
- 响应合成功能:通过多步推理生成更准确的答案。
与LangChain集成
LlamaIndex 可以无缝集成 LangChain,形成优势互补的工作流。例如,使用 LangChain 的链式调用管理复杂业务逻辑,同时利用 LlamaIndex 的高效索引和检索能力。
2. 数据摄入与处理【实战部分】
多源数据加载
LlamaIndex 支持多种数据源的加载,包括本地文档、网页和 API 数据。
from llama_index.core import SimpleDirectoryReader
from llama_index.readers.web import SimpleWebPageReader
# 加载本地文档
documents = SimpleDirectoryReader("./data").load_data()
# 加载网页内容
web_documents = SimpleWebPageReader().load_data(
["https://example.com/page1", "https://example.com/page2"]
)
print(f"加载了 {len(documents)} 个本地文档和 {len(web_documents)} 个网页文档。")
文本分块策略
不同的分块方法会影响检索效率和精度。以下是两种常见分块器的实现:
from llama_index.core.node_parser import SentenceSplitter, TokenTextSplitter
# 基于句子的分块器
sentence_parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes_sentence = sentence_parser.get_nodes_from_documents(documents)
# 基于token的分块器
token_parser = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
nodes_token = token_parser.get_nodes_from_documents(documents)
print(f"基于句子的分块数量:{len(nodes_sentence)}")
print(f"基于token的分块数量:{len(nodes_token)}")
自定义解析器
对于专业领域文档(如 PDF 或表格),可以使用自定义解析器提取特定信息。
from llama_index.readers.file import PDFReader
# 加载PDF文档
pdf_reader = PDFReader()
pdf_documents = pdf_reader.load_data(file="./research_paper.pdf")
print(f"加载了 {len(pdf_documents)} 页PDF内容。")
元数据提取
通过提取元数据(如标题、作者、时间戳等),可以增强节点的检索能力。
from llama_index.core.schema import Document
# 添加元数据
document = Document(
text="量子计算是一种基于量子力学原理的新型计算方式。",
metadata={"title": "量子计算简介", "author": "张三", "date": "2023-01-01"}
)
print(document.metadata)
3. 索引与检索技术【实战部分】
向量索引构建
向量索引是 LlamaIndex 的核心功能之一,适用于大规模文档的高效检索。
from llama_index.core import VectorStoreIndex
# 创建向量索引
vector_index = VectorStoreIndex.from_documents(documents)
# 保存和加载索引
vector_index.storage_context.persist("./storage")
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
loaded_index = load_index_from_storage(storage_context)
混合检索策略
混合检索结合了向量、关键词和知识图谱等多种方法,能够显著提升检索精度。
from llama_index.core.retrievers import VectorIndexRetriever, BM25Retriever
from llama_index.core.retrievers import EnsembleRetriever
# 创建多个检索器
retriever_vector = VectorIndexRetriever(index=vector_index)
retriever_keyword = BM25Retriever.from_documents(documents)
# 组合检索器
ensemble_retriever = EnsembleRetriever(
retrievers=[retriever_vector, retriever_keyword],
weights=[0.6, 0.4]
)
# 执行混合检索
nodes = ensemble_retriever.retrieve("量子计算的应用场景有哪些?")
for node in nodes:
print(node.text)
上下文压缩
上下文压缩技术通过减少冗余信息,提升大规模文档的检索效率。
from llama_index.core.postprocessor import LongContextReorder
# 使用上下文压缩
reordered_nodes = LongContextReorder().postprocess_nodes(nodes)
for node in reordered_nodes:
print(node.text)
重排序策略
基于相关性的结果优化方法可以进一步提升检索质量。
from llama_index.core.postprocessor import SimilarityPostprocessor
# 应用重排序
similarity_processor = SimilarityPostprocessor(similarity_cutoff=0.8)
filtered_nodes = similarity_processor.postprocess_nodes(reordered_nodes)
for node in filtered_nodes:
print(node.text)
4. 高级应用开发【实战部分】
查询引擎定制
通过配置响应合成器,可以实现不同查询模式的灵活切换。
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
# 配置响应合成器
synthesizer = CompactAndRefine(
llm=llm,
verbose=True,
streaming=True
)
# 创建查询引擎
query_engine = RetrieverQueryEngine(
retriever=ensemble_retriever,
response_synthesizer=synthesizer
)
# 执行查询
response = query_engine.query("太阳能技术的最新进展是什么?")
print(response)
代理集成
结合工具使用的知识代理可以实现动态任务分解。
from llama_index.agents import ReActAgent
# 定义工具
tools = [
{"name": "SearchInternet", "func": search_internet},
]
# 创建代理
agent = ReActAgent(tools=tools, query_engine=query_engine)
# 执行代理
result = agent.run("查找关于太阳能技术的最新研究论文。")
print(result)
流处理
实时响应生成的流式 API 能够提升用户体验。
from llama_index.core.streaming import StreamingResponse
# 使用流式响应
streaming_response = StreamingResponse(query_engine.stream_query("解释区块链的基本原理。"))
for chunk in streaming_response:
print(chunk, end="")
评估框架
通过评估脚本测试系统的性能并进行优化。
from llama_index.evaluation import QueryResponseEvaluator
# 初始化评估器
evaluator = QueryResponseEvaluator()
# 测试查询
evaluation_result = evaluator.evaluate(
query="什么是人工智能?",
response=response,
reference="人工智能是模拟人类智能的技术。"
)
print(evaluation_result)
案例与实例:LlamaIndex 实战应用
1. 企业文档库
问题背景:企业需要一个知识库系统,能够处理和检索大规模的 PDF 文档。以下是完整实现,包括数据加载、索引构建和查询优化。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.readers.file import PDFReader
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
# 数据加载:从目录中加载 PDF 文档
pdf_reader = PDFReader()
documents = pdf_reader.load_data(file="./corporate_documents/*.pdf")
# 数据分块:将文档分割为小块
from llama_index.core.node_parser import SentenceSplitter
parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = parser.get_nodes_from_documents(documents)
# 索引构建:创建向量索引
index = VectorStoreIndex(nodes)
# 查询优化:使用向量检索器
retriever = VectorIndexRetriever(index=index, similarity_top_k=5)
# 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=retriever)
# 执行查询
response = query_engine.query("公司2023年的主要产品有哪些?")
print(response)
输出结果
"根据文档内容,公司2023年的主要产品包括智能客服系统、数据分析平台和区块链解决方案。"
说明
- 数据加载:
PDFReader支持批量加载 PDF 文件。 - 数据分块:通过
SentenceSplitter将文档分割为适合模型处理的小块。 - 索引构建:使用向量索引加速检索。
- 查询优化:通过
VectorIndexRetriever提取最相关的节点。
2. 个人知识助手
问题背景:构建一个支持跨会话上下文管理的个人知识助手,帮助用户高效检索和记忆信息。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.chat_engine import ContextChatEngine
# 数据加载:从本地目录加载文档
documents = SimpleDirectoryReader("./personal_knowledge").load_data()
# 索引构建:创建向量索引
index = VectorStoreIndex.from_documents(documents)
# 初始化记忆模块
memory = ChatMemoryBuffer.from_defaults(token_limit=4096)
# 创建上下文感知的聊天引擎
chat_engine = ContextChatEngine(
retriever=index.as_retriever(),
memory=memory,
system_prompt="你是一个个人知识助手,负责回答用户的问题并记住对话历史。",
)
# 模拟多轮对话
response1 = chat_engine.chat("什么是量子计算?")
print(response1)
response2 = chat_engine.chat("它有哪些应用场景?")
print(response2)
# 查看对话历史
print(memory.get())
输出结果
"量子计算是一种基于量子力学原理的新型计算方式,利用量子比特进行并行计算。"
"量子计算的应用场景包括密码学、药物研发和金融建模等领域。"
[{'role': 'assistant', 'content': '量子计算是一种基于量子力学原理的新型计算方式,利用量子比特进行并行计算。'},
{'role': 'assistant', 'content': '量子计算的应用场景包括密码学、药物研发和金融建模等领域。'}]
说明
- 记忆模块:
ChatMemoryBuffer用于存储对话历史,支持跨会话的上下文管理。 - 上下文感知:聊天引擎结合检索器和记忆模块,生成更精准的回答。
- 多轮对话:通过记忆模块,助手能够理解上下文并提供连贯的回答。
3. 研究文献分析器
问题背景:构建一个学术论文智能问答系统,支持关键词检索和引用分析。
完整代码案例
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.retrievers import BM25Retriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.response_synthesizers import CompactAndRefine
from llama_index.evaluation import QueryResponseEvaluator
# 数据加载:加载学术论文
documents = SimpleDirectoryReader("./research_papers").load_data()
# 数据分块:提取段落和元数据
from llama_index.core.node_parser import TokenTextSplitter
parser = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
nodes = parser.get_nodes_from_documents(documents)
# 索引构建:创建向量索引
index = VectorStoreIndex(nodes)
# 检索器:结合 BM25 和向量检索
bm25_retriever = BM25Retriever.from_documents(documents)
vector_retriever = index.as_retriever(similarity_top_k=5)
from llama_index.core.retrievers import EnsembleRetriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.4, 0.6]
)
# 查询引擎:配置响应合成器
synthesizer = CompactAndRefine(verbose=True)
query_engine = RetrieverQueryEngine(
retriever=ensemble_retriever,
response_synthesizer=synthesizer
)
# 执行查询
response = query_engine.query("深度学习在自然语言处理中的最新进展是什么?")
print(response)
# 引用分析:评估答案质量
evaluator = QueryResponseEvaluator()
evaluation_result = evaluator.evaluate(
query="深度学习在自然语言处理中的最新进展是什么?",
response=response,
reference="参考文献中提到Transformer架构的改进提升了模型性能。"
)
print(evaluation_result)
输出结果
"最新的进展包括Transformer架构的改进、预训练模型的优化以及多模态融合技术的应用。"
EvaluationResult(score=0.85, feedback="回答准确且涵盖了关键点。")
说明
- 关键词检索:
BM25Retriever提供高效的关键词匹配。 - 引用分析:通过
QueryResponseEvaluator评估答案的准确性。 - 混合检索:结合 BM25 和向量检索,提升检索精度。
- 响应合成:通过
CompactAndRefine合成更清晰的答案。
以上三个案例展示了 LlamaIndex 在不同场景中的强大能力:
- 企业文档库:通过向量索引和分块策略,高效处理大规模 PDF 文档。
- 个人知识助手:结合记忆模块,支持跨会话的上下文管理。
- 研究文献分析器:利用混合检索和引用分析,构建学术领域的智能问答系统。
总结与扩展思考
LlamaIndex 凭借其强大的数据处理能力和高效的索引机制,已成为构建大模型知识库的首选框架。未来,随着更多高级功能的推出,LlamaIndex 将进一步降低开发门槛,助力企业快速构建智能化应用系统。
扩展思考:
- 如何选择适合的框架(LlamaIndex vs. LangChain)?
- 大规模知识应用的高可用性和扩展性设计。
- 知识库技术的未来发展趋势与应用前景。
希望本文能为你打开 LlamaIndex 的大门!如果你有任何问题或想法,欢迎在评论区留言交流!