记录刷题的过程、感悟、题解。
希望能帮到,那些与我一同前行的,来自远方的朋友😉
大纲:
1、日期统计-(解析)-暴力dfs(😉蓝桥专属
2、01串的熵-(解析)-不要chu,认真读题,并且知道log()怎么用就OK
3、冶炼金属-(解析)-其实推理极限,用数学知识就能OK😊
4、飞机降落-(解析)-暴力搜索dfs(😉蓝桥专属
5、接龙数列-(解析)-字典dp(😎就是名字高大上点,只是一道dp
6、岛屿个数-(解析)-bfs+dfs,重点在于会染色+会读题(广搜深搜一起整
7、子串简写-(解析)-一道简单的前缀和
8、整数删除-(解析)-优先队列+双向链表(😎模拟)
9、10 是lca类型的题目,这类题型,攒着。到时候出个专题,一块搞。😎
知识点:
1、二分查找
2、emplace
3、log() ::cmath::
1、日期统计
问题描述
小蓝现在有一个长度为 100100 的数组,数组中的每个元素的值都在 00 到 99 的范围之内。数组中的元素从左至右如下所示:
5 6 8 6 9 1 6 1 2 4 9 1 9 8 2 3 6 4 7 7 5 9 5 0 3 8 7 5 8 1 5 8 6 1 8 3 0 3 7 9 2 7 0 5 8 8 5 7 0 9 9 1 9 4 4 6 8 6 3 3 8 5 1 6 3 4 6 7 0 7 8 2 7 6 8 9 5 6 5 6 1 4 0 1 0 0 9 4 8 0 9 1 2 8 5 0 2 5 3 3现在他想要从这个数组中寻找一些满足以下条件的子序列:
- 子序列的长度为 88;
- 这个子序列可以按照下标顺序组成一个 yyyymmddyyyymmdd 格式的日期,并且要求这个日期是 20232023 年中的某一天的日期,例如 2023090220230902,2023122320231223。yyyyyyyy 表示年份,mmmm 表示月份,dddd 表示天数,当月份或者天数的长度只有一位时需要一个前导零补充。
请你帮小蓝计算下按上述条件一共能找到多少个不同的 20232023 年的日期。对于相同的日期你只需要统计一次即可。
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
/*
其实本题非常简单,因为它体现了蓝桥杯可以 暴力(dfs)的点:
首先,以2023开头是固定的,你可以在前方,先把这个给枝剪掉
然后再剩下mmdd这四位中爆搜(dfs,当然多层for循环也行)就行,把所有可能给列举出来
切记,一定要防止日期重复,这点很细节。
*/
C++题解
#include <iostream>
#include <vector>
using namespace std;
vector<int> vec{ // 年份剔除,已经存储完毕
3,8, 5 ,1, 6, 3, 4, 6, 7, 0, 7, 8, 2, 7, 6, 8, 9, 5, 6, 5, 6, 1, 4, 0, 1,
0, 0, 9, 4, 8, 0, 9, 1, 2, 8, 5, 0, 2, 5, 3, 3
};
vector<vector<bool>> ymd(13,vector<bool>(32,false)); // 已经非常确定了
void t(int mm, int dd){ // 检测
if(mm==1||mm==3||mm==5||mm==7||mm==8||mm==10||mm==12){ // 31天
if(0<dd&&dd<=31) ymd[mm][dd]=true;
}else if(mm==2){ // 28天
if(0<dd&&dd<=28) ymd[mm][dd]=true;
}else if(mm==4||mm==6||mm==9||mm==11){ // 30天
if(0<dd&dd<=30) ymd[mm][dd]=true;
}
}
void dfs(int cur, int pla, string str){
if(cur==4){ // 判断
int mm = stoi(str.substr(0,2));
int dd = stoi(str.substr(2,2));
t(mm,dd);
return;
}
for(int i=pla+1; i<vec.size(); ++i){
dfs(cur+1,i,str+ to_string(vec[i]));
}
}
int main()
{
dfs(0,0,"");
int sum = 0;
for(int i=0; i<ymd.size(); ++i){
for(int j=0; j<32; ++j){
if(ymd[i][j]) sum++;
}
}
cout<<sum<<endl;
return 0;
}Java题解
import java.util.ArrayList;
import java.util.List;
public class Main {
// 年份剔除,已经存储完毕
static List<Integer> vec = List.of(
3, 8, 5, 1, 6, 3, 4, 6, 7, 0, 7, 8, 2, 7, 6, 8, 9, 5, 6, 5, 6, 1, 4, 0, 1,
0, 0, 9, 4, 8, 0, 9, 1, 2, 8, 5, 0, 2, 5, 3, 3
);
// 已经非常确定了
static boolean[][] ymd = new boolean[13][32];
// 检查日期是否合法并标记
static void t(int mm, int dd) {
if (mm == 1 || mm == 3 || mm == 5 || mm == 7 || mm == 8 || mm == 10 || mm == 12) {
// 31 天的月份
if (0 < dd && dd <= 31) {
ymd[mm][dd] = true;
}
} else if (mm == 2) {
// 28 天的月份
if (0 < dd && dd <= 28) {
ymd[mm][dd] = true;
}
} else if (mm == 4 || mm == 6 || mm == 9 || mm == 11) {
// 30 天的月份
if (0 < dd && dd <= 30) {
ymd[mm][dd] = true;
}
}
}
// 深度优先搜索
static void dfs(int cur, int pla, String str) {
if (cur == 4) {
// 判断
int mm = Integer.parseInt(str.substring(0, 2));
int dd = Integer.parseInt(str.substring(2, 4));
t(mm, dd);
return;
}
for (int i = pla + 1; i < vec.size(); ++i) {
dfs(cur + 1, i, str + vec.get(i));
}
}
public static void main(String[] args) {
dfs(0, 0, "");
int sum = 0;
for (int i = 0; i < ymd.length; ++i) {
for (int j = 0; j < 32; ++j) {
if (ymd[i][j]) {
sum++;
}
}
}
System.out.println(sum);
}
}2、01串的熵

// 只要你不chu,认真读题,仔细观察,还是能做本题的
/*
但是前提条件之一是,你要知道log的用法 =底数;<cmath>
C++中,log默认是 ln(..) ,要做到log(真数,指数的底数),这一步,
需要用换底公式:=ln(真数)/ln(指数的底数)
这涉及到,数学中的指数式 与 对数的转换
细节:log(float/double) 内部只能传递这两种类型,传出也是,否则也会被隐式转换
*/
/*
本题的式子,都给的这么明显了,怎么可能还搞不出来?
H(S)= 首先是负号、然后观察 100,一个1,两个0。看出什么没?
当然是后面的对应顺序呀。共3个(1个1 1/3) (2个0 2/3)还有个数。
“ 0 出现次数比 1 少 ”
根据题意:所以0的个数一定1~23333333/2,之间的某个数字。
*/
C++版
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
int N = 23333333;
for(int i=1; i<=N/2; ++i){
int n0 = i; // 0的个数;
int n1 = N-i; // 1的个数;
double sum = 0;
sum-=(double)n0/N*log((double)n0/N)/ log(2)*n0;
sum-=(double)n1/N*log((double)n1/N)/ log(2)*n1;
if(fabs(sum-11625907.5798)<1e-4){
cout<<n0<<endl;
break;
}
}
return 0;
}Java版
import java.lang.Math;
public class Main {
public static void main(String[] args) {
int N = 23333333;
for (int i = 1; i <= N / 2; ++i) {
int n0 = i; // 0的个数
int n1 = N - i; // 1的个数
double sum = 0;
sum -= (double) n0 / N * Math.log((double) n0 / N) / Math.log(2) * n0;
sum -= (double) n1 / N * Math.log((double) n1 / N) / Math.log(2) * n1;
if (Math.abs(sum - 11625907.5798) < 1e-4) {
System.out.println(n0);
break;
}
}
}
}3、冶炼金属
问题描述
小蓝有一个神奇的炉子用于将普通金属 OO 冶炼成为一种特殊金属 XX。这个炉子有一个称作转换率的属性 VV,VV 是一个正整数,这意味着消耗 VV 个普通金属 OO 恰好可以冶炼出一个特殊金属 XX,当普通金属 OO 的数目不足 VV 时,无法继续冶炼。
现在给出了 NN 条冶炼记录,每条记录中包含两个整数 AA 和 BB,这表示本次投入了 AA 个普通金属 OO,最终冶炼出了 BB 个特殊金属 XX。每条记录都是独立的,这意味着上一次没消耗完的普通金属 OO 不会累加到下一次的冶炼当中。
根据这 NN 条冶炼记录,请你推测出转换率 VV 的最小值和最大值分别可能是多少,题目保证评测数据不存在无解的情况。
输入格式
第一行一个整数 NN,表示冶炼记录的数目。
接下来输入 NN 行,每行两个整数 AA、BB,含义如题目所述。
输出格式
输出两个整数,分别表示 VV 可能的最小值和最大值,中间用空格分开。
样例输入
3 75 3 53 2 59 2样例输出
20 25样例说明
当 V=20V=20 时,有:⌊7520⌋=3⌊2075⌋=3,⌊5320⌋=2⌊2053⌋=2,⌊5920⌋=2⌊2059⌋=2,可以看到符合所有冶炼记录。
当 V=25V=25 时,有:⌊7525⌋=3⌊2575⌋=3,⌊5325⌋=2⌊2553⌋=2,⌊5925⌋=2⌊2559⌋=2,可以看到符合所有冶炼记录。
且再也找不到比 2020 更小或者比 2525 更大的符合条件的 VV 值了。
评测用例规模与约定
对于 3030% 的评测用例,1≤N≤1021≤N≤102。
对于 6060% 的评测用例,1≤N≤1031≤N≤103。
对于 100100% 的评测用例,1≤N≤1041≤N≤104,1≤B≤A≤1091≤B≤A≤109。
// 本题为贪心算法-从局部推至整体、
// 我看网上,其他人用了很多复杂的方法,什么差分呐...
// 好像用不到耶,只需要,推逼一下极限就行
/*
听好喽,这几部很关键。
什么是转化率消耗的最小值? 极限就是你刚好能转化 B+1块,
但因为是推理出来的极限,实际上是不存在的,也就是差一点点。所以要再结果上在+1块
(例:75/4=18,18+1=19,19就是此时的极限)
同样什么是转化率消耗的最大值?你的所有金属A,刚好转哈为B块。A/B
*/
// 希望对你有帮助
C++版
#include <iostream>
#define ll long long
using namespace std;
const ll maxl = 0x3f3f3f3f3f3f3f3f; // 伪最大值
int main()
{
int t;
cin>>t;
int maxV=maxl,minV=0; // 涉及一个极端情况。
int A,B;
while(t--){
cin>>A>>B;
minV=max((A/(B+1)+1),minV); // 最小值
maxV=min((A/B),maxV); // 最大值
}
cout<<minV<<" "<<maxV;
return 0;
}Java版
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
long maxV = Long.MAX_VALUE; // 初始化为最大可能值
long minV = 0; // 初始化为最小可能值
int t = scanner.nextInt();
for (int i = 0; i < t; i++) {
long A = scanner.nextLong();
long B = scanner.nextLong();
// 计算当前测试用例的最小和最大值
long currentMin = (A / (B + 1)) + 1;
long currentMax = A / B;
// 更新全局的最小和最大值
if (currentMin > minV) {
minV = currentMin;
}
if (currentMax < maxV) {
maxV = currentMax;
}
}
System.out.println(minV + " " + maxV);
}
}4、飞机降落
问题描述
NN 架飞机准备降落到某个只有一条跑道的机场。其中第 ii 架飞机在 TiTi 时刻到达机场上空,到达时它的剩余油料还可以继续盘旋 DiDi 个单位时间,即它最早可以于 TiTi 时刻开始降落,最晚可以于 Ti+DiTi+Di 时刻开始降落。降落过程需要 LiLi 个单位时间。
一架飞机降落完毕时,另一架飞机可以立即在同一时刻开始降落,但是不能在前一架飞机完成降落前开始降落。
请你判断 NN 架飞机是否可以全部安全降落。
输入格式
输入包含多组数据。
第一行包含一个整数 TT,代表测试数据的组数。
对于每组数据,第一行包含一个整数 NN。
以下 NN 行,每行包含三个整数:TiTi,DiDi 和 LiLi。
输出格式
对于每组数据,输出 YESYES 或者 NONO,代表是否可以全部安全降落。
样例输入
2 3 0 100 10 10 10 10 0 2 20 3 0 10 20 10 10 20 20 10 20样例输出
YES NO样例说明
对于第一组数据,可以安排第 33 架飞机于 00 时刻开始降落,2020 时刻完成降落。安排第 22 架飞机于 2020 时刻开始降落,3030 时刻完成降落。安排第 11 架飞机于 3030 时刻开始降落,4040 时刻完成降落。
对于第二组数据,无论如何安排,都会有飞机不能及时降落。
评测用例规模与约定
对于 3030% 的数据,N≤2N≤2。
对于 100100% 的数据,1≤T≤101≤T≤10,1≤N≤101≤N≤10,0≤Ti,Di,Li≤1050≤Ti,Di,Li≤105。
// 我当时写的时候,一直轮询检测超时。我还以为是太暴力了(┬┬﹏┬┬),结果...是蓝桥杯官网出问题了,提交不了,可恶。
// 人家都给你飞机了,而且最多不会超过10架
// 题都给到这种程度了,还犹豫什么???直接爆搜,把所有情况给枚举出来。(最多10!)
// 所以说好听点,本题本质上就是一道组合题目
/*
你要先创建一个数组used[N],这台飞机你遍历过没
然后在爆搜期间,维持一个cnt(原count、简写),去记录到底停了几架飞机
---以上,这些只是方便缕清思路的一环,接下来才是关键---
咱假设cur_start是你的最晚开始落下时间、cur_last 其他飞机能开始落下的时间。
cur_start=Ti+Di 是你的最晚开始落下时间、
而cur_last=Ti+Di+Li 才是你最晚落下后,并且能让其他飞机降落的时间。
也就是 cur_last = cur_start+Li;
但是认真读过题的都知道!
开始降落的时间,不一定非要是Ti+Di,
他取决于2点:
- 上一架飞机,是啥时候落下的(other_last)
- 能不能在Ti(最早)时刻落下(Ti)。
此刻if(other_last>Ti) cur_last = other_last;
if(other_last<Ti) cur_last = Ti;
(确切的是,画个图就知道了)
OK,知道这些了,你确定你还会做不出来吗?
爆搜开始
*/
C++版
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e1+5;
int t,n;
vector<bool> used(N,false); // 是否已经降落
vector<vector<int>> res(N,vector<int>(3,0));
int flag = false;
void dfs(int cur ,int tim){ // n
if(cur==n){ // 成功的条件
flag=true;
return;
}
for(int i=0; i<n; ++i){
// 标准回溯
if(!used[i] && tim<=(res[i][0]+res[i][1])){ // tim>vec[i][1] 超过了最晚截止时间
used[i]=true;
// cout<<i<<" "<<used[i]<<" "<<tim<<" "<<res[i][0]<<" "<<res[i][1]<<endl;
int cur_start = max(res[i][0],tim);
dfs(cur+1,cur_start+res[i][2]);
used[i]=false;
}
}
}
int main()
{
cin>>t;
while(t--){
for(int i=0; i<n; ++i) used[i]=false;
cin>>n;
for(int i=0; i<n; ++i){
cin>>res[i][0]>>res[i][1]>>res[i][2]; // 存
}
dfs(0,0);
if(flag) cout<<"YES"<<endl;
else cout<<"NO"<<endl;
flag = false;
}
return 0;
}
Java版
import java.util.Scanner;
import java.util.ArrayList;
public class Main {
static final int N = 105;
static int t, n;
static boolean[] used = new boolean[N];
static int[][] res = new int[N][3];
static boolean flag = false;
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
t = scanner.nextInt();
while (t-- > 0) {
for (int i = 0; i < N; i++) {
used[i] = false;
}
n = scanner.nextInt();
for (int i = 0; i < n; i++) {
res[i][0] = scanner.nextInt();
res[i][1] = scanner.nextInt();
res[i][2] = scanner.nextInt();
}
flag = false;
dfs(0, 0);
if (flag) {
System.out.println("YES");
} else {
System.out.println("NO");
}
}
scanner.close();
}
static void dfs(int cur, int tim) {
if (cur == n) {
flag = true;
return;
}
for (int i = 0; i < n; i++) {
if (!used[i] && tim <= (res[i][0] + res[i][1])) {
used[i] = true;
int cur_start = Math.max(res[i][0], tim);
dfs(cur + 1, cur_start + res[i][2]);
used[i] = false;
}
}
}
}5、接龙数列
问题描述
对于一个长度为 KK 的整数数列:A1,A2,…,AKA1,A2,…,AK,我们称之为接龙数列当且仅当 AiAi 的首位数字恰好等于 Ai−1Ai−1 的末位数字 (2≤i≤K)(2≤i≤K)。例如 12,23,35,56,61,1112,23,35,56,61,11 是接龙数列;12,23,34,5612,23,34,56 不是接龙数列,因为 5656 的首位数字不等于 3434 的末位数字。所有长度为 11 的整数数列都是接龙数列。
现在给定一个长度为 NN 的数列 A1,A2,…,ANA1,A2,…,AN,请你计算最少从中删除多少个数,可以使剩下的序列是接龙序列?
输入格式
第一行包含一个整数 NN。
第二行包含 NN 个整数 A1,A2,…,ANA1,A2,…,AN。
输出格式
一个整数代表答案。
样例输入
5 11 121 22 12 2023样例输出
1样例说明
删除 2222,剩余 11,121,12,202311,121,12,2023 是接龙数列。
评测用例规模与约定
对于 2020% 的数据,1≤N≤201≤N≤20。
对于 5050% 的数据,1≤N≤100001≤N≤10000。
对于 100100% 的数据,1≤N≤1051≤N≤105,1≤Ai≤1091≤Ai≤109。所有 AiAi 保证不包含前导 00。
// 有很多,特殊的案例的,11 12 13 35
// 额,字典dp这玩意... 我真的还是第一次听说耶,
// 挺值得思考的,为什么我在第一次做本题的时候,咋就没有往动态规划上想
// 他们都是这样解释字典dp的:利用(哈希表)来储存和管理状态的优化方式
// 简而言之,就是通过,键值对储存最优解,适用于不连续的场景,或范围较大的场景
/*
好啦、知道啥是字典序了,就来解决一下本题 -->
肯定很多人,在一开始,直接想到贪心、局部最优 推导 全局最优。
于是就吓唬乱删一通。
举个例子: 11 12 13 35;
你能乱删吗?
删 13、35 -> 你就会得到 11 12
删 12 -> 你就会得到 11 13 15
那?该怎么做?难道是将所有的可能,都给枚举出来删一遍?
额、包超时的。
这个时候,你仔细观察就会发现一个很有趣的现象。
毕竟题目就叫做接龙了。
不论你删谁,都跟你的上一个以本首字母,为结尾的字母的状态有关。
这不就是 动态规划,能推导的前提吗?
原顺序 13 35 34 45 56
__34-45
举个列子:13- -56 (56你接在谁后面?
--35
这个时候,35经过判断,会接在56后边
所以,这个时候维护一个dp[0~9]之后,dp[i]的含义就是,以i为起始位置的串的长度
递归公式 dp[last]=max(dp[start]+1,dp[last]);
*/
C++版
#include <iostream>
using namespace std;
int main()
{
int dp[10]={0};
int n;
cin>>n;
for(int i=0; i<n; ++i){
string str;
cin>>str;
int i1 = str[0]-'0';
int i2 = str[str.size()-1]-'0';
dp[i2] = max(dp[i1]+1,dp[i2]);
}
int maxn=0;
for(int i=0; i<10; ++i) maxn=max(maxn,dp[i]);
cout<<n-maxn<<endl;
return 0;
}
Java版
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int[] dp = new int[10]; // 初始化动态规划数组
int n = scanner.nextInt();
for (int i = 0; i < n; i++) {
String str = scanner.next();
int i1 = str.charAt(0) - '0'; // 首字符转数字
int i2 = str.charAt(str.length() - 1) - '0'; // 尾字符转数字
// 更新动态规划状态
if (dp[i1] + 1 > dp[i2]) {
dp[i2] = dp[i1] + 1;
}
}
int maxn = 0;
for (int num : dp) {
if (num > maxn) {
maxn = num;
}
}
System.out.println(n - maxn);
}
}6、岛屿个数
问题描述
小蓝得到了一副大小为 M×NM×N 的格子地图,可以将其视作一个只包含字符 '0'(代表海水)和 '1'(代表陆地)的二维数组,地图之外可以视作全部是海水,每个岛屿由在上/下/左/右四个方向上相邻的 '1' 相连接而形成。
在岛屿 AA 所占据的格子中,如果可以从中选出 kk 个不同的格子,使得他们的坐标能够组成一个这样的排列:(x0,y0),(x1,y1),…,(xk−1,yk−1)(x0,y0),(x1,y1),…,(xk−1,yk−1),其中 (xi+1modk,yi+1modk)(xi+1modk,yi+1modk) 是由 (xi,yi)(xi,yi) 通过上/下/左/右移动一次得来的 (0≤i≤k−1)(0≤i≤k−1),此时这 kk 个格子就构成了一个“环”。如果另一个岛屿 BB 所占据的格子全部位于这个“环”内部,此时我们将岛屿 BB 视作是岛屿 AA 的子岛屿。若 BB 是 AA 的子岛屿,CC 又是 BB 的子岛屿,那 CC 也是 AA 的子岛屿。
请问这个地图上共有多少个岛屿?在进行统计时不需要统计子岛屿的数目。
输入格式
第一行一个整数 TT,表示有 TT 组测试数据。
接下来输入 TT 组数据。对于每组数据,第一行包含两个用空格分隔的整数 MM、NN 表示地图大小;接下来输入 MM 行,每行包含 NN 个字符,字符只可能是 '0' 或 '1'。
输出格式
对于每组数据,输出一行,包含一个整数表示答案。
样例输入
2 5 5 01111 11001 10101 10001 11111 5 6 111111 100001 010101 100001 111111样例输出
1 3样例说明
对于第一组数据,包含两个岛屿,下面用不同的数字进行了区分:
01111 11001 10201 10001 11111岛屿 22 在岛屿 11 的“环”内部,所以岛屿 22 是岛屿 11 的子岛屿,答案为 11。
对于第二组数据,包含三个岛屿,下面用不同的数字进行了区分:
111111 100001 020301 100001 111111注意岛屿 33 并不是岛屿 11 或者岛屿 22 的子岛屿,因为岛屿 11 和岛屿 22 中均没有“环”。
评测用例规模与约定
对于 3030 的评测用例,1≤M,N≤101≤M,N≤10。
对于 100100 的评测用例,1≤T≤101≤T≤10,1≤M,N≤501≤M,N≤50。
// 注:在上网了解一下,emplace的作用。
// 搜索一下,fill的作用
// 可恶啊,预处理数组大小开小了。(┬┬﹏┬┬)
// 本题是一道典型的搜索类型题目,不论你是用dfs、还是用bfs,还是俩个结合着用,不论如何这都是非常酷的。
// 我非常确定,肯定有些人,一上来就直接被(x0,y0) (x1,y1)...(xi+1modk,yi+1modk) 给整成小迷糊
// 这样会导致失去很多细节
// 仔细审题,最好在纸上,画出来
// 就像本题、通过 上/下/左/右 移动得来的,才算围成环,画图时,就会发现左上呢?右下呢?...等等等
/*
作为一道经典的板子题(套路题)
做这类型的题目,一般就是现在外层围一圈海
简而言之,就是在最外围,多铺垫一层'0';
本题最大的左右就是,在左上角,(0,0)的位置,首先将所有外海染色,
为啥(⊙_⊙)?要染色呢,因为没有染色的,必然有两种情况
1、是岛屿
2、是内海
这时,思路就清晰了,只要岛屿在内海中,他就是子岛屿,不用计数,但是也要染色,方便继续搜索。
*/
// 拓展一下,就是emplace家族的用法。(emplace_back、emplace)
// 优点是能直接在容器内,构建元素,避免不必要的拷贝,提高性能
// vector用emplace_back(); list、map等,可用emplace
// 使用方法与insert、push类似。不过是传入构造元素所需参数。所需参数。
C++版
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
const int N = 1e2+5;
int T,m,n; // 组 行 列
vector<vector<int>> arr(N,vector<int>(N,0));
struct node{
int x; // 行
int y; // 列
node(int cx,int cy):x(cx),y(cy){}
};
// 一共8个方向
int fa1[]={0,0,1,-1,1,1,-1,-1};
int fa2[]={1,-1,0,0,-1,1,-1,1};
queue<node> q;
void bfs(){ // 广搜,用于起始时将外海染色,这个用深搜不太行,因为没法地毯式染色
while(!q.empty()){
int x = q.front().x, y = q.front().y;
q.pop();
if(arr[x][y]!=0) continue; // 不是外海水
if(x<0||x>m+1||y<0||y>n+1) continue; // 越界
arr[x][y]=2;
for(int i=0; i<8; ++i){ // 标准格式,应该不是这样的
if(x+fa1[i]<0||x+fa1[i]>m+1||y+fa2[i]<0||y+fa2[i]>n+1) continue; // 越界
q.emplace(x+fa1[i], y+fa2[i]);
}
}
}
void dfs(int x, int y){ // 深搜,用来将岛屿染色
if(arr[x][y]!=1) return; // 不是岛屿
if(x<0||x>m+1||y<0||y>n+1) return; // 越界
arr[x][y]=3;
for(int i=0; i<4; ++i){
dfs( x+fa1[i], y+fa2[i] );
}
}
int main()
{
cin>>T;
while(T--){
for(int i=0; i<N; i++)
for(int j=0; j<N; ++j) arr[i][j]=0;
cin>>m>>n;
for(int i=1; i<=m; ++i){
string str;
cin>>str;
for(int j=1; j<=n; ++j) arr[i][j] = str[j-1]-'0';
}
q.emplace(0,0); // 广搜
bfs();
int sum=0;
for(int i=1; i<=m; ++i){
for(int j=1; j<=n; ++j){
if(arr[i][j]!=1||arr[i+1][j]!=2) continue; // 跳过
sum++;
dfs(i,j); // 将这个岛屿统一染色。染成2
}
}
cout<<sum<<endl;
}
return 0;
}
Java版
import java.util.LinkedList;
import java.util.Queue;
import java.util.Scanner;
public class Main {
static final int N = 102;
static int T, m, n;
static int[][] arr = new int[N][N];
static int[] fa1 = {0, 0, 1, -1, 1, 1, -1, -1};
static int[] fa2 = {1, -1, 0, 0, -1, 1, -1, 1};
static Queue<node> q = new LinkedList<>();
static class node {
int x;
int y;
node(int cx, int cy) {
x = cx;
y = cy;
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
T = scanner.nextInt();
while (T-- > 0) {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
arr[i][j] = 0;
}
}
m = scanner.nextInt();
n = scanner.nextInt();
for (int i = 1; i <= m; i++) {
String str = scanner.next();
for (int j = 1; j <= n; j++) {
arr[i][j] = str.charAt(j - 1) - '0';
}
}
q.add(new node(0, 0));
bfs();
int sum = 0;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (arr[i][j] != 1 || arr[i + 1][j] != 2) {
continue;
}
sum++;
dfs(i, j);
}
}
System.out.println(sum);
}
scanner.close();
}
static void bfs() {
while (!q.isEmpty()) {
int x = q.peek().x;
int y = q.peek().y;
q.remove();
if (arr[x][y] != 0) {
continue;
}
if (x < 0 || x > m + 1 || y < 0 || y > n + 1) {
continue;
}
arr[x][y] = 2;
for (int i = 0; i < 8; i++) {
if (x + fa1[i] < 0 || x + fa1[i] > m + 1 || y + fa2[i] < 0 || y + fa2[i] > n + 1) {
continue;
}
q.add(new node(x + fa1[i], y + fa2[i]));
}
}
}
static void dfs(int x, int y) {
if (arr[x][y] != 1) {
return;
}
if (x < 0 || x > m + 1 || y < 0 || y > n + 1) {
return;
}
arr[x][y] = 3;
for (int i = 0; i < 4; i++) {
dfs(x + fa1[i], y + fa2[i]);
}
}
}7、子串简写
问题描述
程序猿圈子里正在流行一种很新的简写方法:对于一个字符串,只保留首尾字符,将首尾字符之间的所有字符用这部分的长度代替。例如 internation-alization 简写成 i18n,Kubernetes (注意连字符不是字符串的一部分)简写成 K8s, Lanqiao 简写成 L5o 等。
在本题中,我们规定长度大于等于 KK 的字符串都可以采用这种简写方法(长度小于 KK 的字符串不配使用这种简写)。
给定一个字符串 SS 和两个字符 c1c1 和 c2c2 ,请你计算 SS 有多少个以 c1c1 开头 c2c2 结尾的子串可以采用这种简写?
输入格式
第一行包含一个整数 KK。
第二行包含一个字符串 SS 和两个字符 c1c1 和 c2c2。
输出格式
一个整数代表答案。
样例输入
4 abababdb a b样例输出
6样例说明
符合条件的子串如下所示,中括号内是该子串:
[abab][abab]abdb
[ababab][ababab]db
[abababdb][abababdb]
ab[abab][abab]db
ab[ababdb][ababdb]
abab[abdb][abdb]
评测用例规模与约定
对于 2020 的数据,2≤K≤∣S∣≤100002≤K≤∣S∣≤10000。
对于 100100 的数据,2≤K≤∣S∣≤5×1052≤K≤∣S∣≤5×105。SS 只包含小写字母。c1c1 和 c2c2 都是小写字母。
∣S∣∣S∣ 代表字符串 SS 的长度。
// 注:查看二分解法lower_bound()..
// 我看网上很多人都用的是二分解法,这让我迷惑不已,二分???
// 这道题目,用前缀和解决他不香吗??
/*
其实,本题只需要维护一个数组vec[N]
N表示,截止到这个位置,包括这个位置,到底有几个字符c1,
----------
abababdb
11223333 - 数字代表该下标之前有几个C1,包括自己
----------
在遍历第二遍,从k-1开始,当遇到b时,直接arr(下标-k+1),求这个位置,有几个能匹配成a--b;然后累加。
没喽
*/
C++版
#include <iostream>
#include <vector>
#define ll long long
using namespace std;
const ll N = 5e5+5;
int main()
{
int k;
cin>>k;
string str;
char c1,c2;
cin>>str;
cin>>c1>>c2;
vector<ll> vec(N,0);
if(str[0]==c1) vec[0]++;
ll sum=0;
for(int i=1; i<str.size(); ++i){
if(str[i]==c1) vec[i]=vec[i-1]+1;
else vec[i]=vec[i-1];
}
for(int i=k-1; i<str.size(); ++i){
if(str[i]==c2) sum+=vec[i-(k-1)];
}
cout<<sum<<endl;
return 0;
}Java版
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 读取间隔长度 k
int k = scanner.nextInt();
// 读取字符串
String str = scanner.next();
// 读取两个字符 c1 和 c2
char c1 = scanner.next().charAt(0);
char c2 = scanner.next().charAt(0);
scanner.close();
long[] vec = new long[str.length()];
// 初始化前缀和数组的第一个元素
if (str.charAt(0) == c1) {
vec[0] = 1;
}
// 计算前缀和数组
for (int i = 1; i < str.length(); i++) {
if (str.charAt(i) == c1) {
vec[i] = vec[i - 1] + 1;
} else {
vec[i] = vec[i - 1];
}
}
long sum = 0;
// 遍历字符串,统计满足条件的组合数量
for (int i = k - 1; i < str.length(); i++) {
if (str.charAt(i) == c2) {
sum += vec[i - (k - 1)];
}
}
System.out.println(sum);
}
}8、整数删除
问题描述
给定一个长度为 NN 的整数数列:A1,A2,…,ANA1,A2,…,AN。你要重复以下操作 KK 次:
每次选择数列中最小的整数(如果最小值不止一个,选择最靠前的),将其删除。并把与它相邻的整数加上被删除的数值。
输出 KK 次操作后的序列。
输入格式
第一行包含两个整数 NN 和 KK。
第二行包含 NN 个整数,A1,A2,A3,…,ANA1,A2,A3,…,AN。
输出格式
输出 N−KN−K 个整数,中间用一个空格隔开,代表 KK 次操作后的序列。
样例输入
5 3 1 4 2 8 7样例输出
17 7样例说明
数列变化如下,中括号里的数是当次操作中被选择的数:
[1][1] 44 22 88 77
55 [2][2] 88 77
[7][7] 1010 77
1717 77
评测用例规模与约定
对于 2020 的数据,1≤K<N≤100001≤K<N≤10000。
对于 100100 的数据,1≤K<N≤5×1051≤K<N≤5×105,0≤Ai≤1080≤Ai≤108。
// 悠悠的叹息声?为何?先敬罗衣,后敬魂
// 说实话,本题一看,我就知道,本题跟优先队列有关,但是有一件挺无奈的事情是他要不停的删除东西...
// 众多周知,priority_queue内部就是一个黑盒(会用就行-其实内部是堆heap)
// 所以本题的难度就是,如何将priority_queue内部的东西,边用边删除
// 当然,这里面,也有一个非常重要的细节!!!priority_queue重载的时候,要分情况重载,因为这是一个有序数组。
/*
其实也不难的,有人说用并查集,其实链表就能解决
只能说,这道题,你知道大概解法,你就能做,不知道,你肯定不会
本题需要维护一个 双向链表(可不是标准链表)是用两个数组模拟一个链表pre[N],ne[N];
然后在维护一个数组(sum[i]),去记录那些值改变了
切记,设置链表的时候,最开始位置,从1开始。方便 减1 or 加1
假设,删掉下标为cur的值(num)的时候
pre[ne[y]]=pre[y]; ne[pre[y]]=ne[y]; 切记(不是!不是!sum[cur-1]+=num,sum[cur+1]+=num;,导致链接错误
既然删掉该值了,呐本坐标,也就不再存在了,所以接下来 要改变坐标。
这时,你要将cur储存的 下一位的坐标--传给左边
将cur储存的上一个位置---传递给右边
------------
pre 0 1 2 3
val 1 2 3 4
ne 2 3 4 5
------------
删掉val值2之后,1和3的pri与ne都回改变
------------
pre 0 1 1 3
val 1 2 3 4
ne 3 3 4 5
------------
OK了,其他的,想必大家就清楚了
切接,priority_queue默认大堆顶
*/
C++版
#include <iostream>
#include <vector>
#include <queue>
#define ll long long
const ll N = 1e6+5;
ll n,k;
using namespace std;
vector<ll> pre(N, 0);
vector<ll> ne(N, 0);
vector<ll> sum(N,0);
vector<ll> a(N,0);
// 重载
struct cmp{ // !!!
bool operator() (const pair<ll,ll>& p1, const pair<ll,ll>& p2){
if(p1.first == p2.first) return p1.second > p2.second; // 值相同选下标小的
return p1.first > p2.first;
}
};
int main() // 天呐,这些都是什么东西 ·
{
cin>>n>>k;
priority_queue<pair<ll,ll>,vector<pair<ll,ll>>,cmp> p;
ne[0]=1;
for(int i=1; i<=n; ++i){
ll val;
cin>>val;
p.emplace(val,i);
//
pre[i]=i-1;
ne[i] =i+1;
}
while(k--){ // 进行k次操作
ll val = p.top().first;
ll y = p.top().second;
while(sum[y]){
val += sum[y];
p.pop();
p.emplace(val,y);
sum[y]=0;
// 更新
val = p.top().first;
y = p.top().second;
}
// 链表更新错误
sum[pre[y]]+=val;
sum[ne[y]]+=val;
// 更新
pre[ne[y]]=pre[y];
ne[pre[y]]=ne[y];
p.pop();
}
// 提取出来
while(!p.empty()){
a[p.top().second]=p.top().first;
p.pop();
}
for(int i=1; i<=n; i++)
if(a[i]+sum[i]) cout<<a[i]+sum[i]<<" ";
return 0;
}
Java版
import java.util.PriorityQueue;
import java.util.Scanner;
// 自定义比较器,用于优先队列
class PairComparator implements java.util.Comparator<Pair> {
@Override
public int compare(Pair p1, Pair p2) {
if (p1.val == p2.val) {
return Long.compare(p1.index, p2.index);
}
return Long.compare(p1.val, p2.val);
}
}
// 定义 Pair 类,用于存储值和索引
class Pair {
long val;
long index;
Pair(long val, long index) {
this.val = val;
this.index = index;
}
}
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
long n = scanner.nextLong();
long k = scanner.nextLong();
long[] pre = new long[(int) (n + 2)];
long[] ne = new long[(int) (n + 2)];
long[] sum = new long[(int) (n + 2)];
long[] a = new long[(int) (n + 2)];
// 优先队列,使用自定义比较器
PriorityQueue<Pair> p = new PriorityQueue<>(new PairComparator());
ne[0] = 1;
for (int i = 1; i <= n; i++) {
long val = scanner.nextLong();
p.offer(new Pair(val, i));
pre[i] = i - 1;
ne[i] = i + 1;
}
// 进行 k 次操作
for (long i = 0; i < k; i++) {
Pair top = p.poll();
long val = top.val;
long y = top.index;
while (sum[(int) y] != 0) {
val += sum[(int) y];
sum[(int) y] = 0;
p.offer(new Pair(val, y));
top = p.poll();
val = top.val;
y = top.index;
}
sum[(int) pre[(int) y]] += val;
sum[(int) ne[(int) y]] += val;
pre[(int) ne[(int) y]] = pre[(int) y];
ne[(int) pre[(int) y]] = ne[(int) y];
}
// 提取优先队列中的元素
while (!p.isEmpty()) {
Pair pair = p.poll();
a[(int) pair.index] = pair.val;
}
// 输出结果
boolean first = true;
for (int i = 1; i <= n; i++) {
if (a[i] + sum[i] != 0) {
if (!first) {
System.out.print(" ");
}
System.out.print(a[i] + sum[i]);
first = false;
}
}
System.out.println();
scanner.close();
}
}后面的两道题,咱时间有限,就先跳过啦(~ ̄▽ ̄)~
要学会做减法。
当然大家有好的代码、解析,也可以发给我,让我瞅瞅。( •̀ ω •́ )✧,我贴上去。
知识点
1、二分查找
二分查找主要位于<algorithmn>头文件中。常用的有lower_bound、upper_bound、binary_bound
lower_bound
查找第一个大于lower_bound的元素
auto it = lower_bound(vec.begin(),vec.end(),num);
int place = it-vec.begin();upper_bound
查找最后一个大于lower_bound的元素
auto it = upper_bound(vec.begin(),vec.end(),num);
int place = it-vec.begin();
cout<<*it<<(it-vec.begin())<<endl; // 两者皆可binary_bound
判断目标值,是否存在
bool t = binary_bound(vec.begin(),vec.end(),num); 2、emplace
C++中,emplace是 C++11引入的,用于在容器中构建元素,避免复制/移动操作,提高效率。
基本用法
container.emplace(args...);与push的区别
push: 先构造对象,可能会传递。
emplace:传参、直接构造。
(具体用法的话,就是原本push怎么用,emplace就代替成push。
如:push_back--emplace_back)
(push--emplace)
std::vector<std::pair<int, int>> vec;
// 传统 push_back
vec.push_back(std::make_pair(1, 2));
vec.push_back({3, 4}); // C++11后可简化
// 使用 emplace_back
vec.emplace_back(5, 6); // 直接构造 pair,更高效适用容器
-
支持
emplace的容器:- 序列容器:
vector、deque、list - 关联容器:
map、set、unordered_map、unordered_set - 适配器:
priority_queue(底层容器支持即可)
- 序列容器:
-
不支持
emplace的容器:queue、stack等适配器(接口限制)。
3、log() ::cmath::
在 C++ 里,log() 函数一般是指 <cmath> 头文件里用于进行对数运算的函数。下面会详细介绍 log() 函数的具体用法。
log() 函数原型
<cmath> 头文件里定义了几个不同版本的 log() 函数,常用的有:
// 计算自然对数(以 e 为底)
double log(double x);
float log(float x);
long double log(long double x);
这些函数接收一个浮点数参数 x,并返回 x 的自然对数(以自然常数 e 为底)。
以其他底数计算
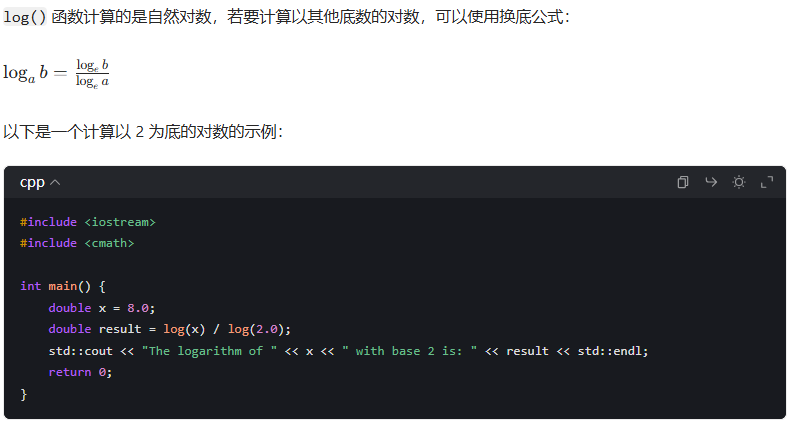
其他对数函数
除了 log() 函数,<cmath> 头文件还提供了其他对数相关的函数:(C++11及之后适用)