文章目录
- 1. HTTP定义
- 2. HTTP交互
- 3. HTTP报文格式
- 3.1 抓包工具-fiddler
- 3.2 抓包操作
- 3.3 报文格式
- 3.3.1 请求报文
- 3.3.2 响应报文
- 4. URL
- 5. 请求头中的方法
- 6. GET和POST的区别
- 7. HTTP报头
- 7.1 Host
- 7.2 Content_Length
- 7.3 Content_Type
- 7.4 User-Agent(UA)
- 7.5 Referer
- 7.6 Cookie
- 8 状态码
- 9. 构造HTTP请求
- 9.1 PostMan
- 9.2 通过代码
- 10. HTTPS
- 10.1 加密
- 10.2 HTTPS工作流程
- 对称加密
- 非对称加密
- 证书
1. HTTP定义
HTTP(超文本传输协议)是一种工作在应用层的协议,应用场景主要用于网站,即浏览器和服务器之间的数据传输,客户端(手机、PC)和服务器之间的数据传输,也很可能是 HTTP。
超文本传输协议
文本:字符串(能在utf8/gbk码表上找到合法字符)
超文本:不仅可以传输字符串,也可以传输图片,特殊格式等,比如html
富文本:word文档
HTTP版本
HTTP在3.0版本之前,都是基于TCP实现的,而在3.0版本之后是基于UDP实现的,提升了传输效率,安全性也提到了明显的改善,当前使用广泛的是HTTP1.1版本,是基于TCP实现的。
2. HTTP交互
HTTP的交互过程是典型的“一问一答”的形式。

这种交互过程对于网站开发来说已经基本够用,但是,有的网站会弹出广告,点进去服务器会主动先发一条消息,像把QQ这样的聊天窗口搬到网页上来,对方发来消息我们这边还有提示,这种情况HTTP的不能胜任。
上述场景是服务器主动给浏览器发消息,就称为消息推送
应用层这里还提供了一个和 HTTP 搭配的协议,websocket (HTTP 的跟班,针对 HTTP 的能力进行补充的)
3. HTTP报文格式
3.1 抓包工具-fiddler
抓包工具,本质上是一个"代理程序",能够获取到网络上传输的数据,并显示出来,从而给程序员提供一些参考。
wireshark:高大全,可以抓各种协议数据包,TCP、IP、UDP、以太网…(使用起来更复杂一点)
fiddler:专注 HTTP 的抓包----https://www.telerik.com/download/fiddler
抓包工具其实就是一种"代理"程序,能够获取网络上的数据并显示出来给我们一些参考。
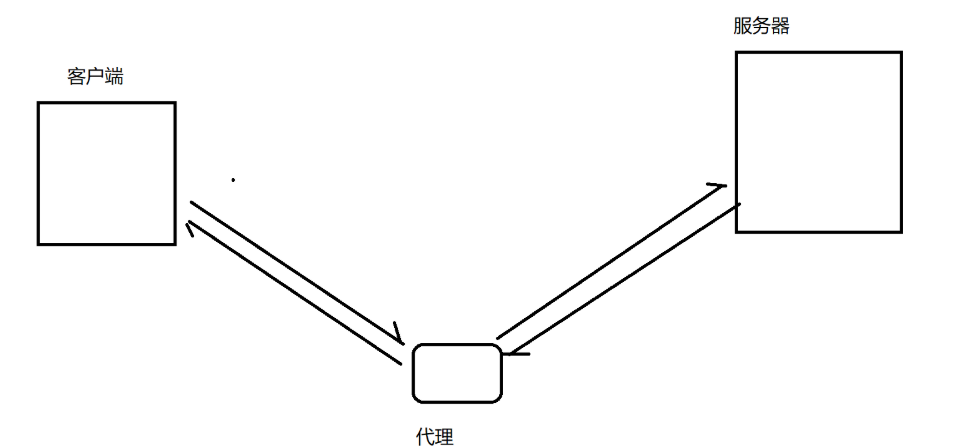 同时,代理分成两种
同时,代理分成两种
1.正向代理(客户端的代言人):比如我会求室友帮我带一份饭,此时室友就是我的代理
2.反向代理(服务器的代言人):比如食堂大妈今天也不想动弹,此时会让他的儿子来卖饭,此时他的儿子就是反向代理
翻墙效果:用来翻墙的代理,本质上是通过一个可以被访问到的境外服务器部署代理服务器的。
3.2 抓包操作
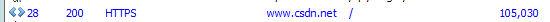
上面蓝色的表示的是返回一个html,表示一个网站的入口请求。
查看明细:
 通过使用该工具查看HTTP交互过程中的请求与交互的详细信息。
通过使用该工具查看HTTP交互过程中的请求与交互的详细信息。
3.3 报文格式
3.3.1 请求报文
HTTP请求的报文格式分为4个部分
1.首行------三部分用空格分开
GET https://www.csdn.net/ HTTP/1.1
GET:表示方法
https://www.csdn.net/:表示URL
HTTP/1.1:表示的是HTTP的版本号
2.请求头(采用键值对的方式)------用空格/冒号分开

3.空行:请求头结束会有一个空行,就是用来表示请求头结束。
4.正文:body(也就是载荷),有的请求有载荷,有的则没有。
3.3.2 响应报文
HTTP的响应报文格式也分为4个部分。
1.首行
HTTP/1.1:表示的是HTTP的版本号
200:状态码
OK:状态码描述

2.响应头(同样也是键值对)
3.空行(标志着响应头结束)
4.正文body(载荷部分)
4. URL
URL用来描述一个网络资源的位置。

http:// :协议,当前使用的是什么协议(HTTP/HTTPS…)
user:pass :登录信息,并不常用,因为不安全
www.example.jp :IP地址,用域名访问,通过地址知道服务器位置
80 :端口号,通过端口知道具体访问服务器的哪个程序
dir/index.htm :路径,通过路径知道访问的是哪个资源(此处可以是一个文件,也可以是一个虚拟文件)
uid=1 :查找字符串(quary string),针对请求做出的补充
ch1 :片段标识符,标识当前页面的某个部分,通过不同的标识可以完成页面的跳转
URL encode
在quary string(查找字符串)中有很多程序员自定义的键值对
在URL中很多字符都有特殊的含义 : / # @等
如果quary string中也有相同的符号怎么办,此时我们就需要转义,当然对于汉字我们也需要转义,通过ASCII进行对应转义
5. 请求头中的方法

标准文档的解释
GET:从服务器获取一个资源(读操作)
POST:往服务器放一个东西(写操作)
GET的使用场景
从服务器获取一个数据,十分常见
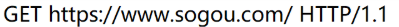
POST的使用场景
大部分用于上传、登录
登录操作使用的是POST方法,登录的用户名使用的是json数据格式组织登录的,密码并不是我们自己设置的密码,而是进行了base64编码(加密),将编码传输到服务器。
密码后面有 == 基本上就是base64编码,Base64 是一种将二进制数据编码为 ASCII 字符串的编码方式,常用于在文本协议(如 HTTP、电子邮件)中安全传输二进制内容。

6. GET和POST的区别
GET和POST的区别(经典面试题)
本质上GET和POST没有区别,使用GET的场景也能用POST,使用POST的场景也能使用GET。
但是在使用习惯上二者还是有区别的:
1.GET习惯把数据放到URL中,POST习惯把数据放到body(载荷)中。
同样GET也可以把数据放到body中,但是有的浏览器会有限制;
POST也可以放到URL中,大多数是没有限制。
2.语义上的区别,标准文档中GET适用于读取数据,POST用于传输数据。
3.关于幂等性,标准文档中,建议GET是幂等的,POST无要求。(幂等就是一个输入只对应一个输出)
4.GET可以被浏览器收藏夹收藏,POST不可以。
一些关于GET和POST的解释也不是很准确,大家理性看待
1.POST比GET更加安全
依据:GET传输的数据是放在URL中的,而POST存放的数据是放在body中的。
登录场景中,如果密码放到URL中可能会被看到,所以不安全,但是POST也是可以被心怀叵测的人抓包得到body。
辟谣:真正保证安全的,不是使用什么方法,而是对数据进行加密。
2.GET传输的数据量很小,POST传输的数据量很大。
以前确实是这样的,但是现在标准文档明确指出对GET的URL不做长度的限制。
3.GET只能携带文本数据,POST只能携带二进制数据。
这个说法不一定完全错,URL是通过quary string来保存数据,quary string是只能包含文本数据的,但是urlencode可以对二进制文件进行编码,自然也就成了文本了。
POST请求中也不是经常携带二进制数据,而是对二进制文件进行urlencode进行转码。
7. HTTP报头

7.1 Host
表示服务器主机的IP地址和端口号,这里的Host和URL中的IP地址、端囗绝大部分情况下都是一样的.

7.2 Content_Length
表示body(正文)中的数据长度,HTTP底层是基于TCP实现的,连续传输多个HTTP数据报,此时接收方这边的接收缓冲区里就会积累多个包的数据,应用程序在读取这些数据的时候就需要明确包之间的边界,以防止出现“粘包问题”。
7.3 Content_Type
表示body(正文)中的数据格式,body可以传输很多种格式的,包括程序员也可以自己约定任意的格式。
请求中的格式
application/json --body就是json的数据格式
application/x-www-form-urlencode --称为form表单,通过HTML中的form标签构造出来的一种格式,特点就是把quary string放到body里。
multipart/form-data --上传文件使用
响应中的格式
text/plain:纯文本
text/html:返回HTML
text/css:返回css
application/Javascript:返回js
application/json:返回json
image/png:返回图片
image/jpg:返回图片
由于浏览器和服务器之间要进行多次网络交互,整体的过程比较低效,为了提升效率,把一些固定不变的内容在浏览器本地的机器硬盘上进行缓存(css,图片,js,很少发生改变的类型)。保存到硬盘上之后,后续再请求,就可以直接从硬盘上读取数据,减少了网络交互的开销。
7.4 User-Agent(UA)
表示当前访问的操作系统的信息以及浏览器信息。
UA在以前是常用的,由于用户的设备存在差异,就可以通过UA区别设备,从而正确返回用户想要的数据。
响应式布局(前端提出的解决上述问题的技术方案),通过一套代码,适应不同尺寸的显示器。也就是 CSS3 提供了一个特性,“媒体查询”,可以感知到当前屏幕的尺寸,根据不同的尺寸,应用不同的样式。
7.5 Referer
表示当前的页面是由哪个页面跳转而来。
浏览器中,直接输入url、点击收藏夹打开的网页,此时是没有referer。
示例:广告业务中,某广告公司在不同的网站部署广告,广告公司有一台服务器来计算来自不同网站的广告的点击量,如果知道该点击来自哪个网站,就需要用到referer。
7.6 Cookie
Cookie就是持久化的保存一些信息,本质上是浏览器这边本地持久化存储数据的机制。
浏览器作为电脑上的一个程序,能否直接读写本地磁盘文件呢?
当然不可以,系统提供了API操作文件,作为一个程序当然可以调用这些API来操作了。理论上完全可行,但是浏览器禁止了这种做法,(浏览器并没有给网页提供这样的API),一个网页不能直接的读写硬盘文件。(为了信息安全以及硬盘安全)
浏览器选择退而求其次,给网页提供了这样的 API,能够有限度的存储数据(按照键值对的格式),但不能随意的访问文件系统。
浏览器提供的网页可以存储数据的机制:Cookie、LocalStorage、IndexDB
Cookie字段的使用
HTTP请求中的Cookie字段,就是把本地存储的Cookie信息发送到服务器这边; HTTP
响应中会有一个Set-Cookie字段,就是服务器告诉浏览器你要在本地保存哪些信息。
结论
Cookie 从哪里来?服务器返回给浏览器的,通常都是首次访问/登录成功之后。
Cookie 到哪里去?Cookie会存储在浏览器本地主机的硬盘上,后续每次访问服务器都会带上Cookie。不同的客户端,保存的Cookie是不同的,即使是同一个主机,使用不同浏览器,Cookie 大概率也不同。
Cookie 中存什么?键值对格式的数据,这里的内容都是程序员自定义的,和 query string 一样外人无从理解。
cookie在浏览器这边如何组织? 在硬盘本地保存,是按照不同的域名为维度分别存储。
Cookie 的用途是什么?用来在客户端保存数据,其中最主要的是保存用户的身份标识,服务器就可以通过标识来区分用户。
- 个人感觉它的作用就是服务器让客户端在预定的位置本地存储部分信息,每次客户端访问服务器,服务器会读取一下在预定的位置本地存储部分信息,从而区分不同客户端
8 状态码

在响应中,上述的200就是一个状态码,HTTP中的状态码都是约定好的。
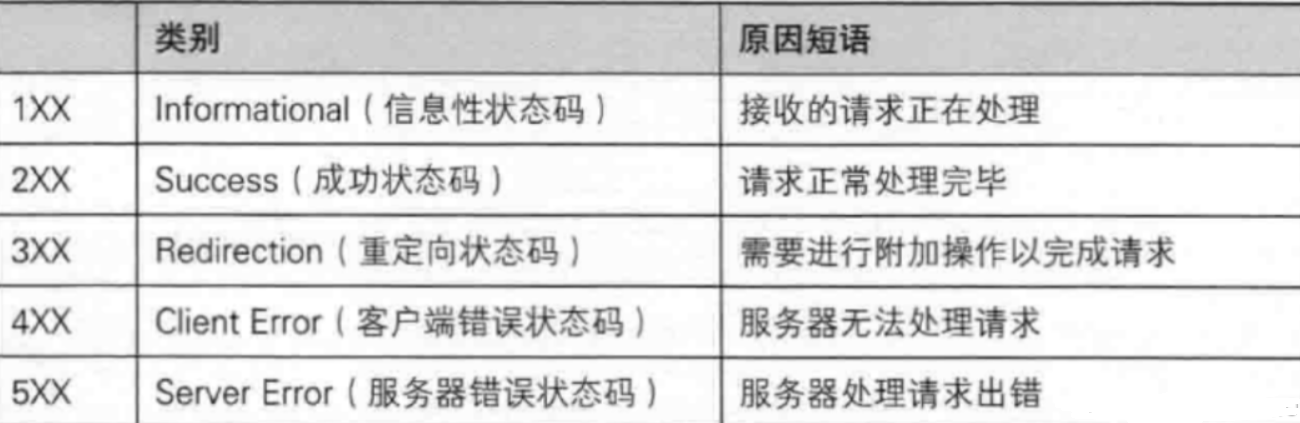
200 OK 表示一切顺利
404 NOT FOUND 访问的资源没有找到
403 Forbidden 表示请求的资源没有权限访问
405 Method Not Allowed 服务器只支持GET,但是你发了个POST
500 Interal Server Error 服务器内部错误,可能是服务器挂了
504 Geteway Timeout 访问服务器超时
302 Move temporarily 临时重定向,如果一个网站更换了新的域名,但是老用户并不知道,此时访问原来的域名就可以跳转到新的域名
301 永久重定向,浏览器会把重定向的结果记录下来,后续再访问就会直接访问重定向的目标地址即可,不用跳转
9. 构造HTTP请求
9.1 PostMan
PostMan是构造HTTP请求的第三方工具。
https://www.postman.com/web
9.2 通过代码
package network;
import jdk.internal.util.xml.impl.Input;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
public class HttpClient {
private Socket socket;
private String ip;
private int port;
public HttpClient(String ip, int port) throws IOException {
this.ip = ip;
this.port = port;
socket = new Socket(ip, port);
}
public String get(String url) throws IOException {
StringBuilder request = new StringBuilder();
//构造首行
request.append("GET " + url + " HTTP/1.1\n");
//构造header
request.append("Host: " + ip + ":" + port + "\n");
//构造空行
request.append("\n");
//发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
//读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public String post(String url, String body) throws IOException {
StringBuilder request = new StringBuilder();
//构造首行
request.append("POST " + url + " HTTP/1.1\n");
//构造header
request.append("Host: " + ip + ":" + port + "\n");
request.append("Conternt-Length: " + body.getBytes().length + "\n");
request.append("Content-Type: text/plain\n");
//构造空行
request.append("\n");
//构造 body
request.append(body);
//发送数据
OutputStream outputStream = socket.getOutputStream();
outputStream.write(request.toString().getBytes());
//读取响应数据
InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024 * 1024];
int n = inputStream.read(buffer);
return new String(buffer, 0, n, "utf-8");
}
public static void main(String[] args) throws IOException {
// HttpClient httpClient = new HttpClient("42.192.83.143", 8080);
// String getResp = httpClient.get("/AjaxMockSever/info");
// System.out.println(getResp);
// String postResp = httpClient.post("/AjaxMockSever/info","this is body");
// System.out.println(postResp);
HttpClient httpClient = new HttpClient("www.sogou.com", 80);
System.out.println(httpClient.get("http://www.sogou.com"));
}
}
10. HTTPS
HTTPS是在HTTP的基础上,引入了一个加密层(SSL)。
HTTP是明文传输的(不安全)
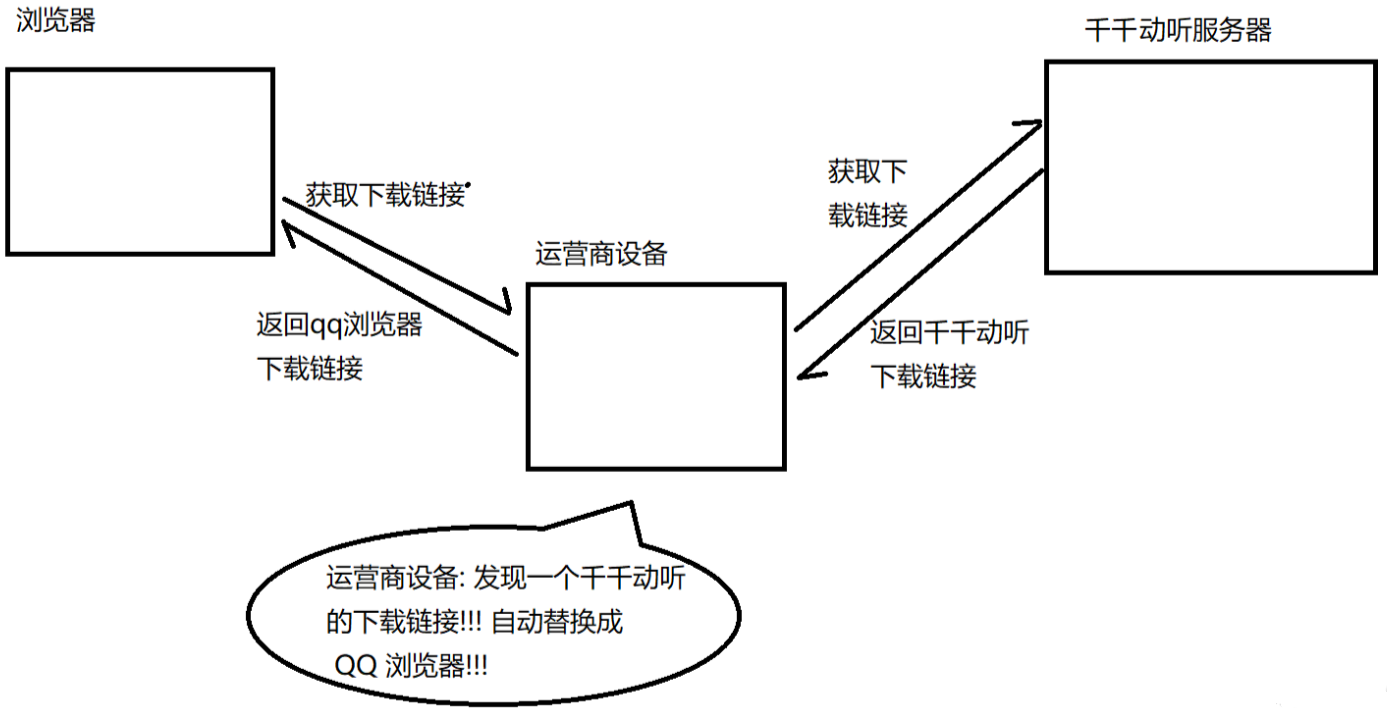
10.1 加密
解决安全问题,最核心的要点,就是"加密"。
介绍密码学中的概念
明文:真正要传输的数据
密文:针对明文进行了加密,得到的结果往往不直观
明文变成密文==>就是加密
密文变成明文==>就是解密
加密和解密的过程中,涉及到一个关键道具,称为“秘钥”
对称加密:加密和解密,使用的是同一个密钥
非对称加密:加密和解密,使用的是两个密钥。这两个密钥k1、k2,是成对的。可以使用k1来加密,此时就是k2解密;也可以使用k2加密,此时就是k1解密。
两个密钥,就可以一个公开出去,称为"公钥",另一个自己保存好,称为"私钥"。
10.2 HTTPS工作流程
引入加密,对HTTP传输的数据进行保护,主要针对 header 和 body 进行加密。
HTTPS = HTTP + SSL(加密层)
对称加密
通过对称加密的方式对传输的数据进行加密的操作。
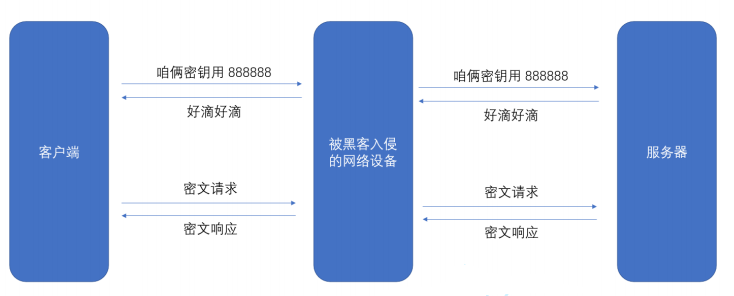
1.对称加密的时候,客户端和服务器使用的是同一个密钥
2.不同的客户端要使用不同的密钥(如果所有的客户端密钥都相同,加密形同虚设,黑客很容易拿到密钥)
每个客户端连接到服务器的时候,都需要自己生成一个随机的密钥,并且把这个密钥告知服务器。密钥需要传输给对方的,一旦黑客拿到了这个密钥,意味着加密操作就无意义。
非对称加密
使用非对称加密,主要是针对对称密钥加密,确保对称密钥的安全性。
非对称加密系统开销,远远大于对称加密。不太适合使用非对称加密针对大规模的数据进行加密。
服务器生成一对非对称密钥,私钥服务器自己持有,公钥则可以告知任何的客户端。
客户端在连上服务器之后,就需要先从服务器这边拿到公钥(公钥本身就可以公开出去,不需要加密传输);然后客户端生成对称密钥,拿着公钥针对对称密钥进行加密。
此时就可以把加密之后的密文进行传输了,由于要想解密,必须通过私钥,而私钥只有服务器自己知道,此时这样的加密的数据就可以比较安全的到达服务器了。
服务器通过私钥解密之后得到了对称密钥,接下来和客户端之间的通信就通过对称加密来完成了。
此时黑客拿到的是一个key加密后的结果,此时黑客要想解密,需要知道PRI,PRI私钥只有服务器自己知道,黑客拿不到(黑客监听中间的通信数据,要比黑入服务器这边容易一些,如果都能黑进服务器了,大概率就可以直接拖数据库了,用户啥信息都被拿到了)。

SSL 内部完成的工作
使用HTTPS的时候,底层也是TCP先进行 TCP三次握手,TCP连接打通之后就要进行 SSL 的握手了(交换密钥的过程),后面才是真正传输业务数据(完整的 HTTPS 的请求/响应了)。
黑客自己也能生成一对公钥和私钥设,公钥为 pub2,私钥为 pri2。黑客不关心服务器的公钥私钥是啥,自己生成一对就行了。生成公钥和私钥的算法都是开放的,服务器能生成,黑客也能生成。
黑客就可以使用 pri2 对上述数据进行解密,因此黑客就拿到了 key 。黑客继续使用从服务器拿到的 pub1 重新对 key 进行加密并且传输给服务器。

证书
如何解决上述问题?
最关键的一点,客户端拿到公钥的时候,要能有办法验证,这个公钥是否是真的,而不是黑客伪造的。
要求服务器这边要提供一个**“证书”**
证书是一个结构化的数据(里面包含很多属性,最终以字符串的形式提供)
证书中会包含一系列的信息,比如服务器的主域名、公钥、证书有效期…
证书是搭建服务器的人,要从第三方的公正机构进行申请的。

一个关键问题:返回证书的时候,证书数据也是经过了黑客的设备,此时黑客是否能修改证书中的公钥?公钥替换成自己的公钥呢?
不行,客户端拿到证书之后,会先针对证书验证真伪。
证书验证的过程
证书中可能会包含这些信息
证书:服务器的域名:……
证书的有效时间:……
服务器的公钥:……
公证机构信息:……
证书的签名:……
其中最重要的就是证书的签名。这个签名并不是真正的签名,而是根据算法将证书的数据算出他的校验和,然后公证机构使用自己的私钥(不是服务器的私钥),针对校验和进行加密,此时就得到了签名。
客户端拿到证书之后主要做两件事:
1.按照同样的校验和算法将证书中的信息进行计算得到校验和val1;
2.通过公证机构在系统中内置的公钥来对证书进行解密,得到校验和val2;
此时就对比看两个校验和是不是一致的
一致就是没被修改过的
不一致就是被修改过的,如果黑客替换成了自己的公钥,此时客户端通过计算就会发现数据错误,此时客户端就能发现错误。
这时候浏览器就会弹出一个告警界面,告诉用户你访问的网站有风险。