1、VFS写文件到page缓存(vfs_write)
1.1、写裸盘(dd)
使用如下命令写裸盘:
dd if=/dev/zero of=/dev/sda bs=4096 count=1 seek=11.2、系统调用(vfs_write)
系统调用栈如下:

对于调用栈的new_sync_write函数,buf为写磁盘的内容的内存地址,也就是从/dev/zero读取上来的数据(全0),len为数据长度,也就是4096(块大小为4096,共一个块,也就是4096 bytes),*ppos为偏移,也就是跳过1个bs(4096)。
wirte系统调用的数据地址及长度保存到了iovec里面,偏移保存到了kiocb:

1.3、写文件缓存(mapping)
块设备也是一个文件,以4k page为单位对块设备内容进行缓存,页缓存保存在mapping里面,写块设备的时候,如果有对应的缓存则写该page缓存,如果没有则创建page缓存。
1.4、写块设备位置(__generic_file_write_iter)
前面wirte系统调用介绍了,写偏移保存到了kiocb里面,最终在__generic_file_write_iter读取并传递给下一级函数,代码如下:

这个pos的单位是byte,当前dd命令写的4096偏移。
1.5、查找page缓存(find_get_entry)
前面介绍了文件系统以4k page为单位缓存文件内容,将一个物理硬盘划分为n个page,wirte系统调用传递了写偏移,偏移pos除以page大小也就是page索引(内核用移位代替除法),代码如下:

根据page的索引index获取page,代码如下:

函数调用栈如下:

(之前没有读该page也没有写该page,当前返回空指针)
1.6、创建page缓存(add_to_page_cache_lru)
pagecache_get_page获取page缓存失败的情况,会创建一个page,并添加到cache的lru里面,也就是前面的mapping->i_pages,代码如下:

函数调用栈如下:

__add_to_page_cache_locked会将page的index设置为offset,这里的offset是写偏移offset对应的page索引(*ppos对应的page索引,后面不再用pos,写磁盘以页为单位,pos不一定以page对齐,如果pos不以page对齐,并且没有缓存,那么写操作会先从磁盘读取一页上来,与当前写的数据合并),后面内核代码都以page索引来写磁盘。
1.7、写缓存(iov_iter_copy_from_user_atomic)
拷贝比较简单,主要就是将前面传递过来的iov_iter里面的数据拷贝到查找或者创建的page缓存里面,代码如下:

函数调用栈:

2、写page缓存到bio(blkdev_writepage)
写page过程,主要通过PageDirty判断文件的page缓存是否为脏(是否被修改,前面写page的时候会标记对应的page为dirty)
2.1、判断page缓存是否dirty(PageDirty)
write_cache_pages函数主要就是遍历文件缓存,找到dirty的page,然后写磁盘,判断dirty代码如下:

2.2、创建初始化bio(submit_bh_wbc)
(前面写数据的时候,会调用attach_page_private给page设置一个buffer_head,在__block_write_begin_int里面会根据page->index计算page对应的扇区,扇区、块设备相关信息会保存到buffer_head里面,前面忽略了,这里简要解释一下,因为submit_bh_wbc会用到这些信息)
submit_bh_wbc将块设备及扇区信息保存到bio的代码如下:

submit_bh_wbc函数调用栈:
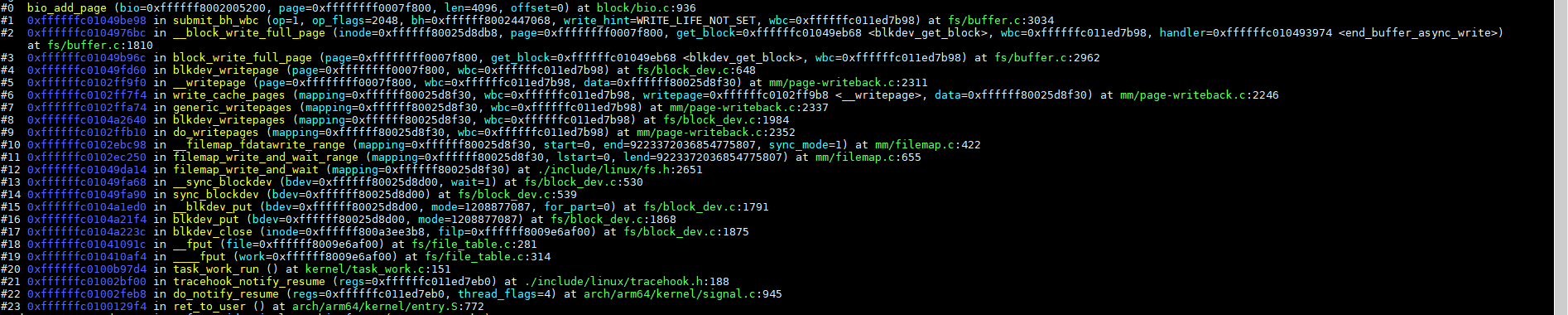
2.3、添加page到bio(__bio_add_page)
添加page过程比较简单,主要就是添加page到bio->bi_io_vec,bio->bi_io_vec是一个数组,一个个page追加到数组末尾,当前只写一个page,不涉及合并操作,__bio_add_page代码如下:

__bio_add_page调用栈如下:
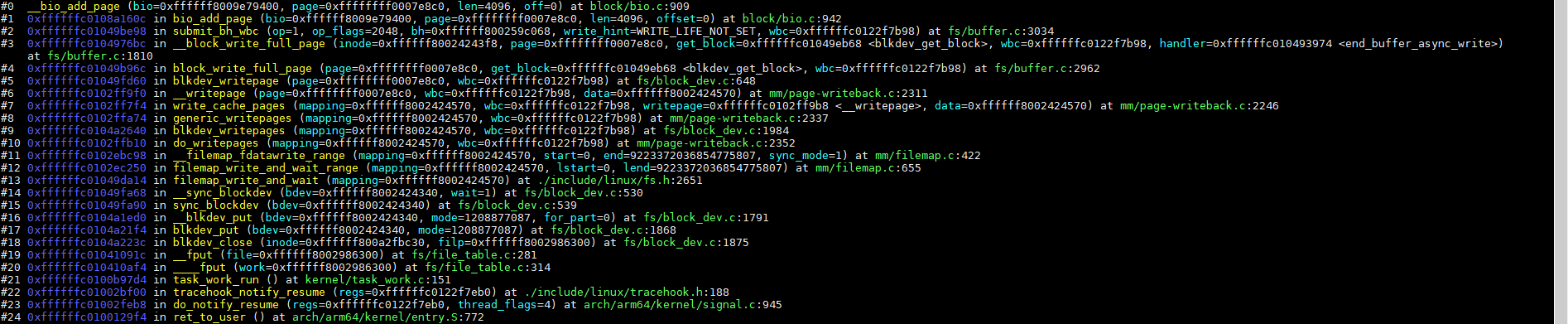
3、提交bio(blk_mq_submit_bio)
3.1、获取request请求(__blk_mq_alloc_request)
__blk_mq_alloc_request调用blk_mq_get_ctx获取当前线程上下文,调用blk_mq_map_queue映射请求到硬件队列,调用blk_mq_get_tag尝试从硬件队列中获取一个可用的标签,用于标识请求,这个tag标签不是硬件相关的,而是一个软件上唯一的tag标签。(这个标签跟/sys/class/block/sda/queue/nr_requests I/O 请求队列中最大并发请求数的值有关,允许最多nr_requests个tag,就是允许最多同时下发nr_requests请求,具体可以查看blk_mq_update_nr_requests、blk_mq_get_tag,__blk_mq_alloc_request函数也可以看到,获取不到tag的时候,__blk_mq_alloc_request重复尝试获取tag)
__blk_mq_alloc_request相关代码如下:

获取到tag之后, __blk_mq_alloc_request调用blk_mq_rq_ctx_init分配并初始化一个request。
3.2、bio转request(blk_mq_bio_to_request)
blk_mq_bio_to_request主要就是将bio的扇区地址以及bio等保存到request里面,代码如下:
3.3、将request添加到plug的mq_list(blk_add_rq_to_plug)
(blk_mq_submit_bio有很多路径,不同场景走的分支不一样,本文仅针对当前实际场景)
blk_mq_submit_bio调用blk_add_rq_to_plug将请求先添加到当前进程的plug队列里面,代码如下:

函数调用栈如下:
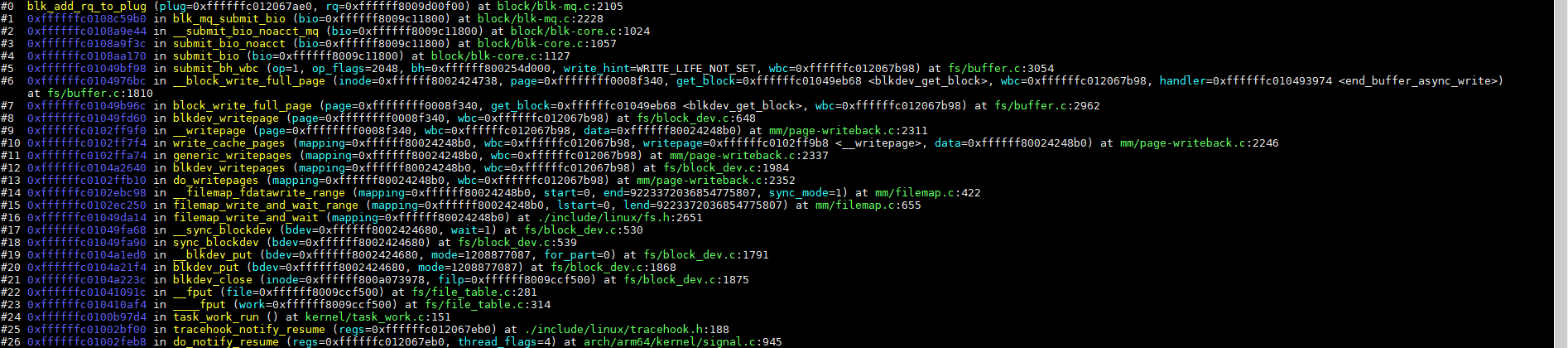
3.4、刷request(blk_finish_plug)
在将所有page经过一系列操作转request保存到plug之后,调用blk_finish_plug,刷当前进程的plug:

blk_finish_plug最终调用blk_mq_flush_plug_list将plug里面的request发送到不同的队列,代码如下:
void blk_mq_flush_plug_list(struct blk_plug *plug, bool from_schedule)
{
// 创建一个临时链表头用于存储任务队列
LIST_HEAD(list);
// 如果当前插件的多队列链表为空,则直接返回
if (list_empty(&plug->mq_list))
return;
// 将插件中的任务队列移动到临时链表中,并清空原链表
list_splice_init(&plug->mq_list, &list);
// 如果任务数量大于2且支持多个队列,则对任务进行排序
if (plug->rq_count > 2 && plug->multiple_queues)
list_sort(NULL, &list, plug_rq_cmp);
// 初始化任务计数器
plug->rq_count = 0;
// 循环处理临时链表中的任务
do {
// 创建一个局部链表头,用于存储当前批次的任务
struct list_head rq_list;
// 获取当前链表的第一个任务,并将其从链表中移除
struct request *rq, *head_rq = list_entry_rq(list.next);
struct list_head *pos = &head_rq->queuelist; /* 跳过第一个任务 */
struct blk_mq_hw_ctx *this_hctx = head_rq->mq_hctx;
struct blk_mq_ctx *this_ctx = head_rq->mq_ctx;
unsigned int depth = 1;
// 遍历剩余的任务,将属于同一硬件上下文和上下文的任务归为一批
list_for_each_continue(pos, &list) {
rq = list_entry_rq(pos);
BUG_ON(!rq->q); // 确保任务队列不为空
if (rq->mq_hctx != this_hctx || rq->mq_ctx != this_ctx)
break;
depth++;
}
// 将当前批次的任务从链表中切分出来
list_cut_before(&rq_list, &list, pos);
// 跟踪任务未插队事件,记录队列、深度以及是否来自调度程序
trace_block_unplug(head_rq->q, depth, !from_schedule);
// 将当前批次的任务插入调度队列
blk_mq_sched_insert_requests(this_hctx, this_ctx, &rq_list,
from_schedule);
} while (!list_empty(&list)); // 如果链表不为空,则继续处理
}
(说明:代码注释由chartGPT自动生成)
4、request插入到调度队列(blk_mq_sched_insert_requests)
(SATA调度的请求没有经过blk_mq_ctx队列,请求直接存入了blk_mq_hw_ctx->queue->elevator->elevator_data里面。)
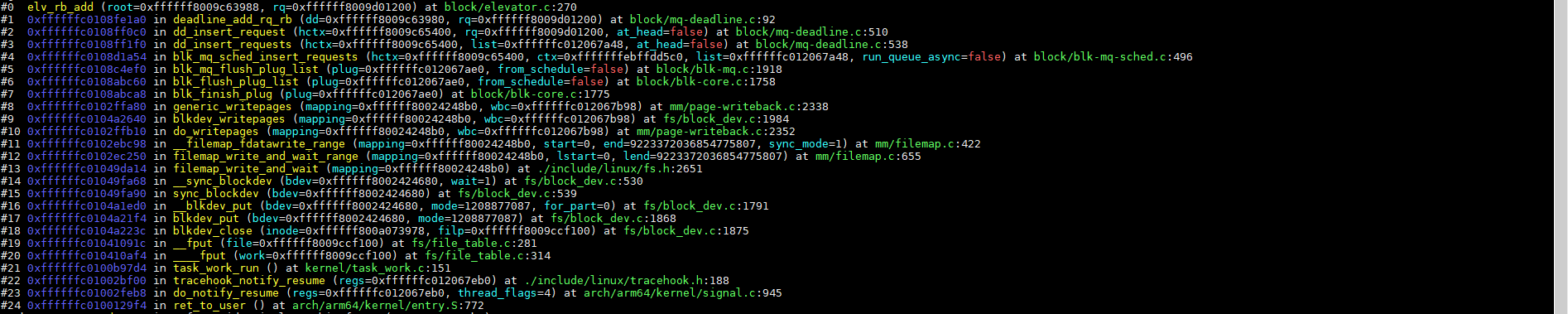
4.1、将request插入到Deadline调度器(deadline_add_rq_rb)
当前dd写的sata硬盘,使用deadline调度算法;deadline_add_rq_rb将前面blk_mq_flush_plug_list获取的request插入到Deadline调度器,elv_rb_add函数代码如下:
/**
* elv_rb_add - 将请求插入到红黑树中,并保持排序顺序。
* @root: 红黑树的根节点指针。
* @rq: 要插入的请求节点。
*
* 该函数实现了一个典型的红黑树插入操作,同时根据请求的位置进行排序。
*/
void elv_rb_add(struct rb_root *root, struct request *rq)
{
// 定义一个指向红黑树根节点的指针变量 p,初始值为 root 的子节点指针。
struct rb_node **p = &root->rb_node;
// 定义一个指向当前父节点的指针变量 parent,用于记录插入位置的上一级节点。
struct rb_node *parent = NULL;
// 定义一个临时变量 __rq,用于存储当前遍历到的红黑树节点对应的请求。
struct request *__rq;
// 开始遍历红黑树,找到合适的插入位置。
while (*p) {
// 将当前节点赋值给 parent,以便后续插入时作为新节点的父节点。
parent = *p;
// 将当前节点转换为请求结构体,方便比较请求的顺序。
__rq = rb_entry(parent, struct request, rb_node);
// 如果当前请求的扇区号小于待插入请求的扇区号,则向左子树继续查找。
if (blk_rq_pos(rq) < blk_rq_pos(__rq))
p = &(*p)->rb_left;
else if (blk_rq_pos(rq) >= blk_rq_pos(__rq))
// 否则,向右子树继续查找。
p = &(*p)->rb_right;
}
/**
* 插入新节点:
* - rb_link_node() 用于将新节点插入到红黑树中,但不调整颜色。
* - rb_insert_color() 用于调整红黑树的颜色属性,确保其仍然是有效的红黑树。
*/
rb_link_node(&rq->rb_node, parent, p);
rb_insert_color(&rq->rb_node, root);
}
(说明:代码注释由chartGPT自动生成;函数里面的blk_rq_pos是获取扇区地址,本质就是按扇区地址对request排序,对于机械硬盘,按扇区顺序写对性能比较友好,避免太频繁来回移动磁头;当前场景下只有一个请求,需要调试排队的情况,可以用fio下发多个随机写请求)
函数调用栈如下:
4.2、将request插入到fifo队列末尾(dd_insert_request)
dd_insert_request插入request的代码如下,会给请求加上一个expire time,jiffies可以理解为当前时间,dd->fifo_expire[data_dir]可以理解为超时时间,也就是从request入队列开始之后的多少时间内应该得到调度,前面的Deadline调度器队列是按扇区排序,一味按扇区顺序下发请求,会导致request长时间得不到调度,所以有一个fifo队列,在不超时的情况下,尽可能按扇区顺序调度request请求,后面可以看到具体的请求过程,这里仅介绍:

函数调用栈如下:

5、调度request(dd_dispatch_request)
5.1、下一个request请求(deadline_latter_request)
下一个request请求为在下发一个请求之后,调度器会选择下一个需要调度的请求放到next_rq里面,对于机械硬盘,应该就是下一个最近的扇区的请求,这样可以避免磁头来回跳转,相关函数如下:
static void
deadline_move_request(struct deadline_data *dd, struct request *rq)
{
const int data_dir = rq_data_dir(rq);
dd->next_rq[READ] = NULL;
dd->next_rq[WRITE] = NULL;
dd->next_rq[data_dir] = deadline_latter_request(rq);
/*
* take it off the sort and fifo list
*/
deadline_remove_request(rq->q, rq);
}
每次下发都需要先清除下一个读写请求,再选择当前请求的下一个请求,并将已经调度的请求从相关队列里面删除。
5.2、批量调度request(__dd_dispatch_request)
__dd_dispatch_request有两种调度,一种是批量调度,另一种是fifo调度。批量调度就是,如果之前是调度的是写请求,那么接下来还是继续调度写请求,如果之前调度的是读请求,那么接下来还是继续调度读请求,除非fifo有请求超时或者批量请求超过上限等其他情况;fifo调度就是请求超过了应该调度的时间,这个时候优先处理超时的fifo请求。
__dd_dispatch_request步骤为获取deadline_latter_request选取的下一个请求(只能是读写请求里面的一个或者空,虽然先查询的是WRITE,不表示优先下发写请求,而是如果READ不为空的情况下,WRITE必然为空,先查询哪个都一样,都是由前一个调度的请求决定),代码如下:
/*
* 批处理当前只允许读或写,不能同时处理
*/
rq = deadline_next_request(dd, WRITE); // 尝试获取下一个写请求
if (!rq) // 如果没有写请求,则尝试获取读请求
rq = deadline_next_request(dd, READ);如果批量调度的请求数量少于批量下发的请求数量,继续调度前面选出的下一个请求,这里是继续前面按扇区排序选择的下一个扇区的请求:
// 如果有请求并且尚未达到批处理限制,则继续批处理
if (rq && dd->batching < dd->fifo_batch)
goto dispatch_request;批量调度次数加1,选择下个需要调度的请求,返回当前调度的请求:
dispatch_request: // 标签:调度请求
/*
* rq 是选定的合适请求
*/
dd->batching++; // 增加批处理计数器
deadline_move_request(dd, rq); // 移动请求到调度队列
done: // 标签:处理完成
/*
* 如果请求需要锁定目标区域,则执行锁定操作
*/
blk_req_zone_write_lock(rq); // 锁定目标区域
rq->rq_flags |= RQF_STARTED; // 设置请求已启动标志
return rq; // 返回选定的请求批量调度超过上限的情况或者没有下一个请求等情况(磁盘没发送过请求,当前为第一个请求),如果读fifo队列不为空,检查写是否被饿死(写操作前面有多个fifo读操作),如果没有被饿死则调度读操作,否则调度写操作:
// 如果有读请求且写请求未被饿死,则选择读请求
if (reads) {
BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ])); // 确保读排序列表不为空
// 如果写请求未被饿死且已经连续等待超过阈值,则跳转到写请求处理
if (deadline_fifo_request(dd, WRITE) &&
(dd->starved++ >= dd->writes_starved))
goto dispatch_writes;
data_dir = READ; // 设置数据方向为读
goto dispatch_find_request; // 跳转到查找请求的标签
}5.3、查找下一个request请求(dispatch_find_request)
批量调度的情况,下发一个请求的时候已经根据磁盘扇区选择好了下一个需要调度的请求,不需要查找,非批量调度的情况下需要选择下一个要调度的请求,前面代码会根据条件选择好是调度读还是调度写,然后从相应队列获取下一个请求。
选择下一个请求,deadline_next_request获取下一个请求(不考虑zone等情况,这里主要是上一次下发请求是选择的下一个请求,按扇区排序的请求),deadline_check_fifo检查fifo最前面的请求是否超时,如果有超时应该从fifo里面调度超时请求,如果没有超时并且deadline_next_request也没有获取到下一个请求,那么也按fifo调度:
/*
* 不在批处理模式下,找到选定数据方向的最佳请求
*/
next_rq = deadline_next_request(dd, data_dir); // 获取下一个请求
if (deadline_check_fifo(dd, data_dir) || !next_rq) { // 检查是否有超时请求或无更多请求
/*
* 如果有超时请求、上次请求方向不同或已无更高扇区的请求,
* 则重新从最早到期时间的请求开始。
*/
rq = deadline_fifo_request(dd, data_dir); // 获取最早的到期请求
} else {没有请求超时,并且按扇区顺序已经选择好了请求的话,调度下一个选择好的请求:
} else {
/*
* 上次请求方向相同且有下一个请求,则继续从这里开始。
*/
rq = next_rq; // 设置当前请求为下一个请求
}从整个代码看Deadline调度,不保证优先处理超时请求,优先批处理,批处理方向一致,性能较好,批量处理一定程度之后才考虑fifo超时,总体就是尽量保证磁头向一个方向转,避免来回转。至于什么时候触发调度,这里暂时忽略。
__dd_dispatch_request函数调用栈:
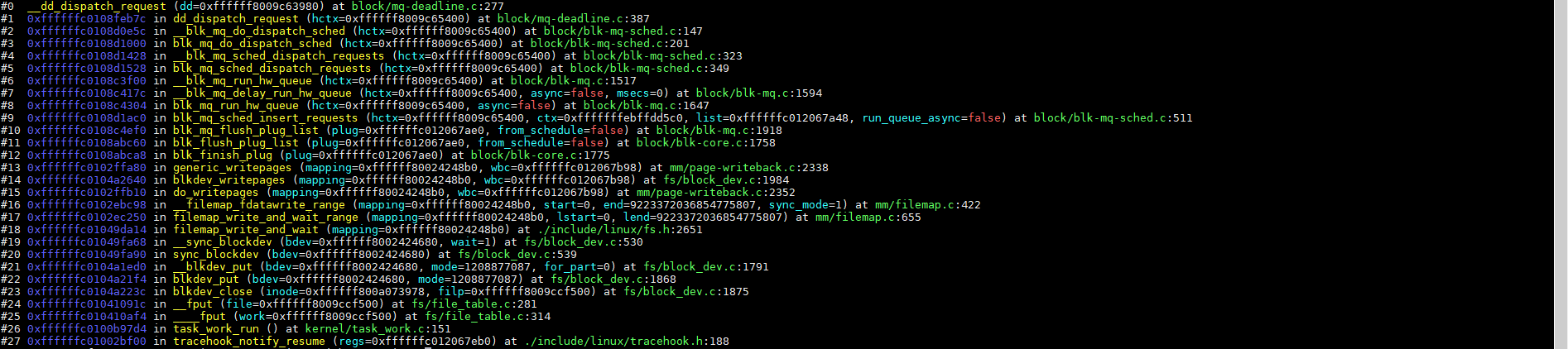
5.4、分发request(__blk_mq_do_dispatch_sched)
前面的代码选择一个个request,这些request先保存到一个请求链表里面,直到没有请求或者超过最大请求数量:
__blk_mq_do_dispatch_sched从调度队列获取reqest请求代码如下:

将调度的request添加到队列:

至此,系统调用的数据从写缓存到入调度队列再到调度出调度队列已经完成了。request调度之后接下来发送到更下一层。
6、下发request(blk_mq_dispatch_rq_list)
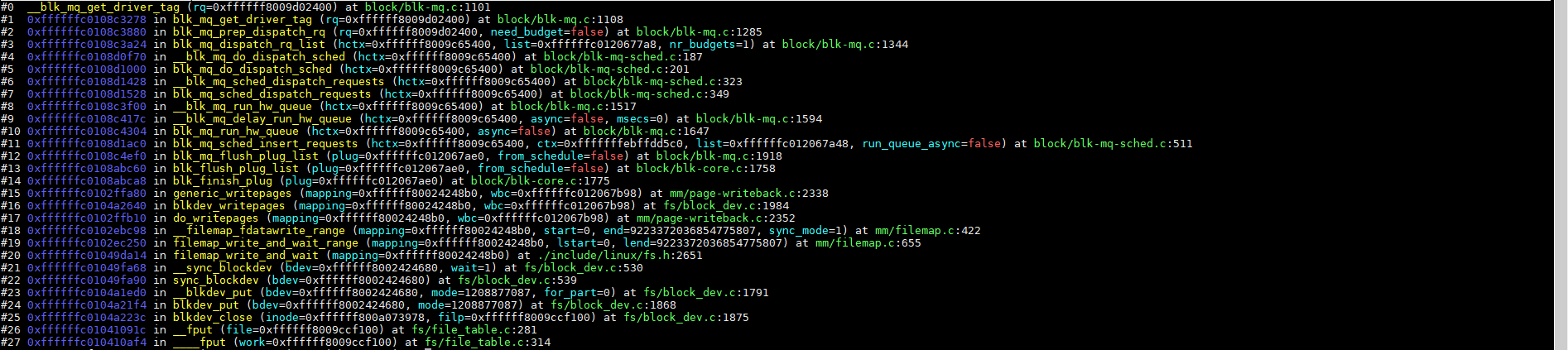
6.1、获取tag(__blk_mq_get_driver_tag)
在前面《linux-5.10.110内核源码分析 - bcm2711 SATA驱动(AHCI)》里面介绍了,AHCI的一定意义上对应一个slot,也就是一个命令通道,下发request需要给request获取一个slot,这个是硬件相关的,与前面的tag不同,前面的tag可以理解为队列里的一个标签。
__blk_mq_get_driver_tag获取tag的代码如下:

函数调用栈:
6.2、request转scsi_cmnd(scsi_prepare_cmd)
将request转换成scsi_cmnd:
6.3、下发scsi命令(scsi_dispatch_cmd)
调度队列的请求request保存到了scsi_cmnd,然后调用scsi_dispatch_cmd下发scsi命令,主要就是根据scsi协议,填充各种字段信息,然后scsi再转换成ahci相关命令,最终下发到ahci控制。
调用栈如下:














![[python]基于yolov8实现热力图可视化支持图像视频和摄像头检测](https://i-blog.csdnimg.cn/direct/7a68af002b83460fa28558704934a264.png#pic_center)




