文章目录
- 一、聚类的性能评价
- 1、聚类性能评价
- (1)聚类性能评价方法:
- 2、参考模型 (reference model)
- (1)数据集:
- (2)聚类结果:
- (3)参考模型:
- (4)标记向量:
- (5)样本对数目计算:
- (6)外部评价指标:
- 3、外部索引
- (1)Jaccard 系数 (JC)
- Fowlkes and Mallows 指数 (FMI)
- (2)Rand 指数 (Rand Index), RI
- 4、无参考模型
- (1)大部分时候只有聚类结果,没有参考模型,只能用内部评价法评估聚类的性能:
- 5、簇内相似度
- (1)平均距离:
- (2)最大距离:
- (3)簇的半径 (diameter):
- 6、簇间相似度/距离
- (1)最小距离:
- (2)类中心之间的距离:
- 7、内部评价指标
- (1)DB 指数 (DBI)
- (2)Dunn 指数 (DI)
- 8、Calinski-Harabaz Index (CHI)
- 9、轮廓指数 (Silhouette Index)
- (1)例:轮廓指数
- (2)例:根据SI选择聚类数目
- 10、聚类小结
- 11、Scikit-Learn中的聚类算法
- (1)Classes sklearn.cluster
- 12、Scikit-Learn中的聚类算法示例
- 13、采用Scikit-Learn进行聚类算法的实例
一、聚类的性能评价
1、聚类性能评价
(1)聚类性能评价方法:
聚类性能评价方法主要分为两种:
- 外部评价法 (external criterion):评估聚类结果与参考结果的相似程度。
- 内部评价法 (internal criterion):评估聚类的本质特征,无需参考结果。
2、参考模型 (reference model)
(1)数据集:
- 数据集: D = { x 1 , x 2 , . . . , x N } D = \{x_1, x_2, ..., x_N\} D={x1,x2,...,xN}
(2)聚类结果:
- 聚类结果: C = { C 1 , C 2 , . . . , C K } C = \{C_1, C_2, ..., C_K\} C={C1,C2,...,CK},其中 C k C_k Ck表示属于类别 k k k的样本的集合。
(3)参考模型:
- 参考模型: C ∗ = { C 1 ∗ , . . . , C K ∗ } C^* = \{C_1^*, ..., C_K^*\} C∗={C1∗,...,CK∗}
(4)标记向量:
- λ \lambda λ 和 λ ∗ \lambda^* λ∗ 分别为 C C C和 C ∗ C^* C∗ 的标记向量。
(5)样本对数目计算:
-
a
=
#
{
(
x
i
,
x
j
)
∣
x
i
,
x
j
∈
C
k
;
x
i
,
x
j
∈
C
l
∗
}
a = \#\{(x_i, x_j) | x_i, x_j \in C_k; \ x_i, x_j \in C_l^*\}
a=#{(xi,xj)∣xi,xj∈Ck; xi,xj∈Cl∗}
- 在两种聚类结果中,两个样本的所属簇相同。
-
d
=
#
{
(
x
i
,
x
j
)
∣
x
i
∈
C
k
1
,
x
j
∈
C
k
2
;
x
i
∈
C
l
1
∗
,
x
j
∈
C
l
2
∗
}
d = \#\{(x_i, x_j) | x_i \in C_{k1}, x_j \in C_{k2}; \ x_i \in C_{l1}^*, x_j \in C_{l2}^*\}
d=#{(xi,xj)∣xi∈Ck1,xj∈Ck2; xi∈Cl1∗,xj∈Cl2∗}
- 在两种聚类结果中,两个样本的所属簇不同。
- b = # { ( x i , x j ) ∣ x i , x j ∈ C k ; x i ∈ C l 1 ∗ , x j ∈ C l 2 ∗ } b = \#\{(x_i, x_j) | x_i, x_j \in C_k; \ x_i \in C_{l1}^*, x_j \in C_{l2}^*\} b=#{(xi,xj)∣xi,xj∈Ck; xi∈Cl1∗,xj∈Cl2∗}
- c = # { ( x i , x j ) ∣ x i ∈ C k 1 , x j ∈ C k 2 ; x i , x j ∈ C l ∗ } c = \#\{(x_i, x_j) | x_i \in C_{k1}, x_j \in C_{k2}; \ x_i, x_j \in C_l^*\} c=#{(xi,xj)∣xi∈Ck1,xj∈Ck2; xi,xj∈Cl∗}
(6)外部评价指标:
利用 ( a , b , c , d ) (a, b, c, d) (a,b,c,d)定义外部评价指标:
| N ( N − 1 ) / 2 N(N-1)/2 N(N−1)/2 | 参考模型 | 相同 | 不同 |
|---|---|---|---|
| 聚类结果 | 相同 | a a a | b b b |
| 不同 | c c c | d d d |
3、外部索引
(1)Jaccard 系数 (JC)
- J C = a a + b + c JC = \frac{a}{a+b+c} JC=a+b+ca
- J C ∈ [ 0 , 1 ] JC \in [0,1] JC∈[0,1], J C ↑ JC \uparrow JC↑,一致性 ↑ \uparrow ↑
Fowlkes and Mallows 指数 (FMI)
- F M I = a a + b ⋅ a a + c FMI = \sqrt{\frac{a}{a+b} \cdot \frac{a}{a+c}} FMI=a+ba⋅a+ca
- F M I ∈ [ 0 , 1 ] FMI \in [0,1] FMI∈[0,1], F M I ↑ FMI \uparrow FMI↑,一致性 ↑ \uparrow ↑
(2)Rand 指数 (Rand Index), RI
- R I = 2 ( a + d ) N ( N − 1 ) RI = \frac{2(a+d)}{N(N-1)} RI=N(N−1)2(a+d)
- R I ∈ [ 0 , 1 ] RI \in [0,1] RI∈[0,1], R I ↑ RI \uparrow RI↑,一致性 ↑ \uparrow ↑
4、无参考模型
(1)大部分时候只有聚类结果,没有参考模型,只能用内部评价法评估聚类的性能:
- 簇内相似度越高,聚类质量越好。
- 簇间相似度越低,聚类质量越好。
5、簇内相似度
(1)平均距离:
-
a
v
g
(
C
k
)
=
1
∣
C
k
∣
(
∣
C
k
∣
−
1
)
∑
x
i
,
x
j
∈
C
k
d
i
s
t
(
x
i
,
x
j
)
avg(C_k) = \frac{1}{|C_k|(|C_k|-1)} \sum_{x_i, x_j \in C_k} dist(x_i, x_j)
avg(Ck)=∣Ck∣(∣Ck∣−1)1∑xi,xj∈Ckdist(xi,xj)
- 其中 ∣ C k ∣ |C_k| ∣Ck∣表示簇 C k C_k Ck中元素的数目。
(2)最大距离:
- d i a m ( C k ) = max x i , x j ∈ C k d i s t ( x i , x j ) diam(C_k) = \max_{x_i, x_j \in C_k} dist(x_i, x_j) diam(Ck)=maxxi,xj∈Ckdist(xi,xj)
(3)簇的半径 (diameter):
-
d
i
a
m
(
C
k
)
=
1
∣
C
k
∣
∑
x
i
∈
C
k
(
d
i
s
t
(
x
i
,
μ
k
)
)
2
diam(C_k) = \sqrt{\frac{1}{|C_k|} \sum_{x_i \in C_k} (dist(x_i, \mu_k))^2}
diam(Ck)=∣Ck∣1∑xi∈Ck(dist(xi,μk))2
- 其中
μ
k
=
1
∣
C
k
∣
∑
x
i
∈
C
k
x
i
\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i
μk=∣Ck∣1∑xi∈Ckxi

- 其中
μ
k
=
1
∣
C
k
∣
∑
x
i
∈
C
k
x
i
\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i
μk=∣Ck∣1∑xi∈Ckxi
6、簇间相似度/距离
(1)最小距离:
-
d
m
i
n
(
C
k
,
C
l
)
=
min
x
i
∈
C
k
,
x
j
∈
C
l
d
i
s
t
(
x
i
,
x
j
)
d_{min}(C_k, C_l) = \min_{x_i \in C_k, x_j \in C_l} dist(x_i, x_j)
dmin(Ck,Cl)=minxi∈Ck,xj∈Cldist(xi,xj)

(2)类中心之间的距离:
-
d
c
e
n
(
C
k
,
C
l
)
=
d
i
s
t
(
μ
k
,
μ
l
)
d_{cen}(C_k, C_l) = dist(\mu_k, \mu_l)
dcen(Ck,Cl)=dist(μk,μl),
- 其中
μ
k
=
1
∣
C
k
∣
∑
x
i
∈
C
k
x
i
\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i
μk=∣Ck∣1∑xi∈Ckxi

- 其中
μ
k
=
1
∣
C
k
∣
∑
x
i
∈
C
k
x
i
\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i
μk=∣Ck∣1∑xi∈Ckxi
7、内部评价指标
(1)DB 指数 (DBI)
D
B
I
=
1
K
∑
k
=
1
K
max
k
≠
l
a
v
g
(
C
k
)
+
a
v
g
(
C
l
)
d
c
e
n
(
C
k
,
C
l
)
DBI = \frac{1}{K} \sum_{k=1}^{K} \max_{k \neq l} \frac{avg(C_k) + avg(C_l)}{d_{cen}(C_k, C_l)}
DBI=K1∑k=1Kmaxk=ldcen(Ck,Cl)avg(Ck)+avg(Cl),
簇内距离/簇间距离
D
B
I
↓
DBI \downarrow
DBI↓,聚类质量
↑
\uparrow
↑
(2)Dunn 指数 (DI)
D
I
=
min
1
≤
k
<
l
≤
K
d
m
i
n
(
C
k
,
C
l
)
max
1
≤
k
≤
K
d
i
a
m
(
C
k
)
DI = \min_{1 \leq k < l \leq K} \frac{d_{min}(C_k, C_l)}{\max_{1 \leq k \leq K} diam(C_k)}
DI=min1≤k<l≤Kmax1≤k≤Kdiam(Ck)dmin(Ck,Cl),
最小簇间距离/最大簇的半径
D
I
↑
DI \uparrow
DI↑,聚类质量
↑
\uparrow
↑
8、Calinski-Harabaz Index (CHI)
C
H
I
=
t
r
(
B
)
t
r
(
W
)
×
N
−
K
K
−
1
CHI = \frac{tr(B)}{tr(W)} \times \frac{N - K}{K - 1}
CHI=tr(W)tr(B)×K−1N−K,
C
H
I
↑
CHI \uparrow
CHI↑,聚类质量
↑
\uparrow
↑ 计算快
其中
W
W
W为簇内散度矩阵:
W
=
∑
k
=
1
K
∑
x
i
∈
C
k
(
x
i
−
μ
k
)
(
x
i
−
μ
k
)
⊤
W = \sum_{k=1}^{K} \sum_{x_i \in C_k} (x_i - \mu_k)(x_i - \mu_k)^\top
W=∑k=1K∑xi∈Ck(xi−μk)(xi−μk)⊤
其中簇中心
μ
k
=
1
∣
C
k
∣
∑
x
i
∈
C
k
x
i
\mu_k = \frac{1}{|C_k|} \sum_{x_i \in C_k} x_i
μk=∣Ck∣1∑xi∈Ckxi
t
r
(
W
)
=
∑
k
=
1
K
∑
x
i
∈
C
k
d
i
s
t
(
x
i
,
μ
k
)
tr(W) = \sum_{k=1}^{K} \sum_{x_i \in C_k} dist(x_i, \mu_k)
tr(W)=∑k=1K∑xi∈Ckdist(xi,μk),为矩阵
W
W
W的迹
B
B
B为簇间散度矩阵:
B
=
∑
k
=
1
K
∣
C
k
∣
(
μ
k
−
μ
)
(
μ
k
−
μ
)
⊤
B = \sum_{k=1}^{K} |C_k|(\mu_k - \mu)(\mu_k - \mu)^\top
B=∑k=1K∣Ck∣(μk−μ)(μk−μ)⊤
其中
μ
=
1
N
∑
i
=
1
N
x
i
\mu = \frac{1}{N} \sum_{i=1}^{N} x_i
μ=N1∑i=1Nxi
t
r
(
B
)
=
∑
k
=
1
K
∣
C
k
∣
d
i
s
t
(
μ
k
,
μ
)
tr(B) = \sum_{k=1}^{K} |C_k|dist(\mu_k, \mu)
tr(B)=∑k=1K∣Ck∣dist(μk,μ)
9、轮廓指数 (Silhouette Index)
对于其中的一个样本点
i
i
i,记:
-
a
(
i
)
a(i)
a(i):样本点
i
i
i到与其所属簇中其它点的平均距离
-
d
(
i
,
C
k
)
‾
\overline{d(i, C_k)}
d(i,Ck):样本点
i
i
i到其他簇
C
k
(
x
i
∉
C
k
)
C_k (x_i \notin C_k)
Ck(xi∈/Ck)内所有点的平均距离
-
b
(
i
)
b(i)
b(i):所有
d
(
i
,
C
k
)
‾
\overline{d(i, C_k)}
d(i,Ck)的最小值
则样本点
i
i
i的轮廓宽度为:
s
(
i
)
=
b
(
i
)
−
a
(
i
)
max
(
a
(
i
)
,
b
(
i
)
)
s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))}
s(i)=max(a(i),b(i))b(i)−a(i)
s
(
i
)
∈
[
−
1
,
1
]
s(i) \in [-1, 1]
s(i)∈[−1,1]
S
I
↑
SI \uparrow
SI↑,聚类质量
↑
\uparrow
↑
平均轮廓值为:
S
I
=
1
N
∑
i
=
1
N
s
(
i
)
SI = \frac{1}{N} \sum_{i=1}^{N} s(i)
SI=N1∑i=1Ns(i)
(1)例:轮廓指数
SI值小的点为边缘点
(2)例:根据SI选择聚类数目
2个簇轮廓分数高,但2个簇的大小不均衡
4个簇轮廓分数高,且每个簇的轮廓大小比较均衡
3个簇和5个簇比较糟糕:因为存在低于平均轮廓分数的聚类,轮廓图的大小波动很大
10、聚类小结
聚类与应用高度相关
聚类很难评估,但实际应用中很有用
聚类方法
- 基于中心的模型:如K均值聚类
- 基于连接性的模型:如层次聚类(BIRCH、CURE、CHAMELEON、GRIN)
- 基于分布的模型:基于数据点的产生分布确定模型,如高斯混合模型
- 基于密度的模型:如DBSCAN、OPTICS、DENCLUE、Mean-shift
- 基于图模型的聚类:谱聚类
- 基于网格的聚类:STING、CLIQUE
- 基于模型的聚类:SOM、基于神经网络的聚类
两个通用工具
- EM
- 图及其拉普拉斯矩阵
11、Scikit-Learn中的聚类算法
(1)Classes sklearn.cluster
| Classes | Description |
|---|---|
| cluster.AffinityPropagation(…) | Perform Affinity Propagation Clustering of data. |
| cluster.AgglomerativeClustering(…) | Agglomerative Clustering. |
| cluster.Birch(…) | Implements the BIRCH clustering algorithm. |
| cluster.DBSCAN(…) | Perform DBSCAN clustering from vector array or distance matrix. |
| cluster.FeatureAgglomeration(…) | Agglomerate features. |
| cluster.KMeans(…) | K-Means clustering. |
| cluster.MiniBatchKMeans(…) | Mini-Batch K-Means clustering. |
| cluster.MeanShift(…) | Mean shift clustering using a flat kernel. |
| cluster.OPTICS(…) | Estimate clustering structure from vector array. |
| cluster.SpectralClustering(…) | Apply clustering to a projection of the normalized Laplacian. |
| cluster.SpectralBiclustering(…) | Spectral biclustering (Kluger, 2003). |
| cluster.SpectralCoClustering(…) | Spectral Co-Clustering algorithm (Dhillon, 2001). |
Scikit-Learn 官方文档
12、Scikit-Learn中的聚类算法示例

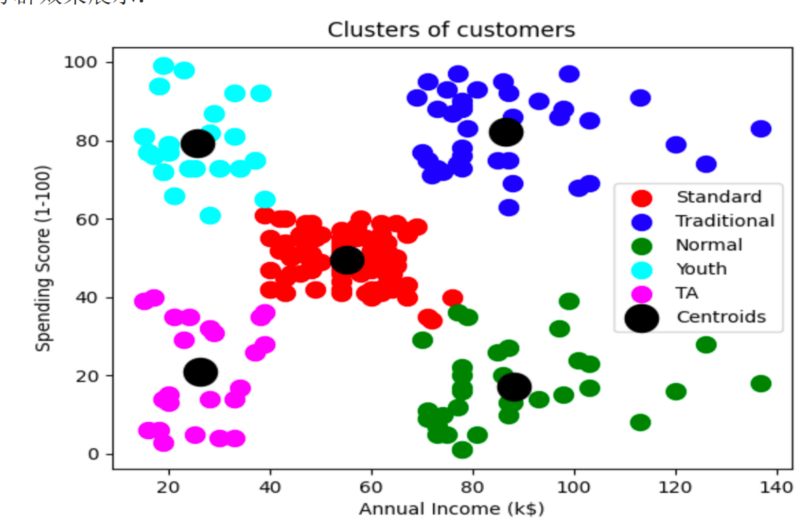
13、采用Scikit-Learn进行聚类算法的实例
- Python Data Science Handbook
- Neptune.ai 聚类算法博客