FutureTask.get方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
- FutureTask.get()方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
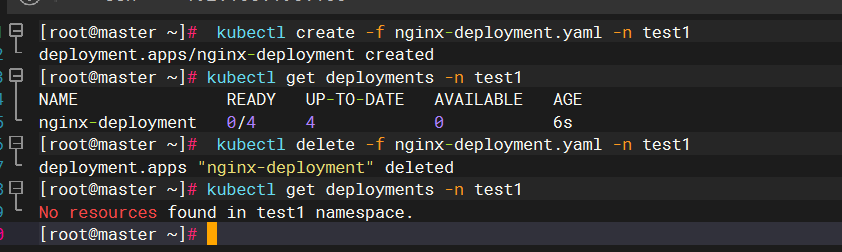
- 1、情景复现
- 1.1 线程池工作原理
- 1.2 业务场景模拟
- 1.3 运行结果
- 1.4 发现问题:线程池没有被关闭
- 1.5 引发思考
- 2、结合源码剖析 get 方法阻塞原因
- 2.1 submit()方法提交任务
- 2.2 FutureTask
- 局部变量
- 构造方法
- FutureTask的run方法
- FutureTask的get方法
- FutureTask的get(timeout)方法
- FutureTask的 awaitDone方法(核心)
- FutureTask的report 方法
- 2.3 解决方案
FutureTask.get()方法阻塞陷阱:深度解析线程池CPU飚高问题排查与解决方法
FutureTask的get()方法在多线程并发编程中应用场景还是蛮多的,作用是通过get方法阻塞直到获取到结果为止,而FutureTask一般是结合线程池来运行任务的,目的是由线程池统一管理和复用线程的资源。但是如果使用不当则会引发CPU飙升的问题? 接下来我们结合源码底层来剖析下到底会不会引发CPU飙升呢?
1、情景复现
1.1 线程池工作原理

1.2 业务场景模拟
结合上图线程池工作原理进行模拟场景:最大线程数为1,核心线程数为1,队列大小为1,也就是说当前线程池最多可以处理两个任务,如果大于两个任务,那么就会执行拒绝策略(注意此处是自定义拒绝策略,这里设置为打印日志,为FutureTask的get阻塞陷阱埋下伏笔)。
- 自定义线程池配置
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
1, // 核心线程数为1
1, // 最大线程数为1
2, // 非核心线程不工作时,存活的时间 2s
TimeUnit.SECONDS,// 非核心线程不工作时,存活时间对应的时间单位
new ArrayBlockingQueue<>(1), // 阻塞队列 容量大小为1
new RejectedExecutionHandler() { // 自定义拒绝策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("====任务丢失啦啦啦===="); // 打印一行日志
// throw new RejectedExecutionException("任务丢失啦啦啦"); // 或抛出异常提示
}
});
- 提交任务执行
try {
// 模拟任务执行
List<Future<Integer>> futureList = Stream.of(2, 4, 6).map(num -> {
System.out.println(Thread.currentThread().getName() + "<>>>>>> , 添加数字num(Begin):" + num);
Future<Integer> future = poolExecutor.submit(() -> {
System.out.println(Thread.currentThread().getName() + ":=====任务开始执行=====Start!");
try {
// 模拟任务执行逻辑
TimeUnit.SECONDS.sleep(num);
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + ">>任务被中断了,中断原因:" + e.getMessage());
}
System.out.println(Thread.currentThread().getName() + "=====任务执行完毕=====End!");
return num;
});
System.out.println(Thread.currentThread().getName() + "<>>>>>> , 添加数字num(End):" + num);
return future;
}).collect(Collectors.toList());
// 获取任务执行结果
for (Future<Integer> future : futureList) {
try {
System.out.println(">>:" + future.get());
} catch (InterruptedException | ExecutionException e) {
System.out.println("=====获取任务执行结果失败=====,原因:" + e.getMessage());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
poolExecutor.shutdown();
}
1.3 运行结果
根据线程池的配置,最多处理的任务数量=最大线程数+阻塞队列 = 2,所以任务2和任务4会被处理,而任务6会根据拒绝策略输出一行日志。

1.4 发现问题:线程池没有被关闭
根据 1.3 输出的日志和运行结果截图分析可得:都是按照预想结果执行的,但问题是:为什么主线程任务为什么没有停止运行呢?因为业务逻辑使用了try…finally包裹,其中finally会关闭线程池的,按照正常执行逻辑是一定会关闭线程池的(因为我们代码中没有任何地方使用System.exit() 强制终止JVM)

结合以上运行截图可以发现,是由于拒绝策略中仅仅是打印了一行日志,导致FutureTask一直以为任务6还存活着,所以在调用futureTask的get方法时一直处于阻塞中,这是导致线程池没有关闭的直接原因。
1.5 引发思考
试想下,如果是在多线程环境下出现这种情况,那么线程池的CPU岂不是会持续飚高运行,从而直接影响服务器的处理性能(此时让我想到工作中有个万能公式:没有什么问题是重启解决不了的呢)。
既然我们已经清楚是因为 futureTask的get方法导致线程阻塞,下面我们继续结合源码来进行验证为什么会被阻塞?
2、结合源码剖析 get 方法阻塞原因
2.1 submit()方法提交任务
public <T> Future<T> submit(Callable<T> task) {
// 若任务为空时,抛出空指针异常
if (task == null) throw new NullPointerException();
// 创建一个FutureTask对象
RunnableFuture<T> ftask = newTaskFor(task);
// 将该任务添加线程池中
execute(ftask);
// 返回FutureTask对象
return ftask;
}
- submit执行原理图

2.2 FutureTask

局部变量
/**
* Possible state transitions(可能的状态转换):
NEW -> COMPLETING -> NORMAL(业务逻辑执行正常时)
NEW -> COMPLETING -> EXCEPTIONAL(业务逻辑执行异常时)
NEW -> CANCELLED
NEW -> INTERRUPTING -> INTERRUPTED
*/
private volatile int state; // 被volatile关键字修饰,确保线程可见
private static final int NEW = 0; // 首次submit方法提交任务时,初始化值为NEW
private static final int COMPLETING = 1; //
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
构造方法
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
FutureTask的run方法
如果业务逻辑call执行分为两种:1、执行异常(NEW -> COMPLETING -> EXCEPTIONAL);2、正常执行(NEW -> COMPLETING -> NORMAL)
public void run() {
// 若state不等于NEW 或 CAS 将期望值null设置为当前线程失败时,直接return
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
// 当前state等于NEW 或 CAS占用为当前线程成功
Callable<V> c = callable;
if (c != null && state == NEW) {
// c代表当前Task,不等于空且state等于NEW
V result;
boolean ran;
try {
// 执行Task的业务逻辑
result = c.call();
// task执行成功,则将ran变量设置为true
ran = true;
} catch (Throwable ex) {
// 如果Task执行异常,则将结果result置为空,ran变量设置为false
result = null;
ran = false;
// 状态变更: NEW -> COMPLETING -> EXCEPTIONAL
setException(ex);
}
// ran变量为true时, 状态变更为:NEW -> COMPLETING -> NORMAL
if (ran)
set(result);
}
} finally {
runner = null;
int s = state;
// INTERRUPTING值等于5
// 若state 大于或等于 5 ,此时state状态为 INTERRUPTING 或 INTERRUPTED
if (s >= INTERRUPTING)
// 如果 state等于INTERRUPTING(5)时,调用 Thread.yield() 方法,让出CPU的使用权
// 当前线程状态由 运行状态(Running) 转化为 就绪状态(Runnable)。
handlePossibleCancellationInterrupt(s);
}
}
FutureTask的get方法
public V get() throws InterruptedException, ExecutionException {
int s = state; // 获取当前任务的 state 变量
// 如果 state 变量的值 小于或等于 COMPLETING(1) 则进入 awaitDone (翻译为:等待完成)
if (s <= COMPLETING)
s = awaitDone(false, 0L);
// 此处表示s 大于COMPLETING(1)
return report(s);
}
FutureTask的get(timeout)方法
public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
if (unit == null)
throw new NullPointerException();
int s = state;
if (s <= COMPLETING &&
(s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING)
throw new TimeoutException();// 超时会抛出异常TimeoutException
return report(s);
}
FutureTask的 awaitDone方法(核心)
/**
* <p>等待完成</p>
* 根据 timed 参数分为两种情况:
* 1、如果timed为true时,调用LockSupport.parkNanos(this, nanos);// 表示仅等待nanos时间
* 2、如果timed为false时,则调用LockSupport.park(this); // 表示一直等待
*/
private int awaitDone(boolean timed, long nanos) throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;// 默认为false
// 进入死循环
for (;;) {
// 当前线程被中断
if (Thread.interrupted()) {
// q不为空时移除waiter
removeWaiter(q);
// 抛出中断异常InterruptedException
throw new InterruptedException();
}
// 表示当前线程未被中断
int s = state;
// 如果 state 大于 COMPLETING(1) 时,
// 则代表此时的state值为NORMAL、EXCEPTIONAL、CANCELLED、INTERRUPTING、INTERRUPTED
if (s > COMPLETING) {
// waitNode不为空时,将thread置为null
if (q != null)
q.thread = null;
// 返回当前的state值
return s;
}
// 如果 state 值为COMPLETING时,则让出CPU的使用权
else if (s == COMPLETING)
Thread.yield();// 让出CPU的使用权
else if (q == null)
q = new WaitNode(); // 如果q等于空时,创建一个WaitNode节点
else if (!queued)
// 通过CAS(Compare-And-Swap)操作将当前线程的等待节点q插入到waiters链表中
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
// timed 为 true 时,调用LockSupport.parkNanos(this, nanos);
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
// 如果小于或等于0,则表示等待时间到了
removeWaiter(q);
// 此时返回 state
return state;
}
LockSupport.parkNanos(this, nanos);
}
else
// 表示当前线程一直等待完成, 一直阻塞
LockSupport.park(this);
}
}
- 引发阻塞的核心原因(LockSupport.park(this))
如果使用的get(timeout)方法,则使用 LockSupport.parkNanos(this, nanos); 会阻塞 nanos 时间后会释放锁;反之使用 get()方法,则使用LockSupport.park(this); 会一直阻塞
FutureTask的report 方法
private V report(int s) throws ExecutionException {
Object x = outcome;
// 如果 state 变量 等于 NORMAL,则返回结果值 Value
if (s == NORMAL)
return (V)x;
// state 大于或等于 CANCELLED,则state可能的值为:CANCELLED、INTERRUPTING、INTERRUPTED
if (s >= CANCELLED)
throw new CancellationException();// 抛出异常
// 抛出异常ExecutionException
throw new ExecutionException((Throwable)x);
}
2.3 解决方案

重要事情讲三遍,注意、注意、注意:在使用get方法时首先需要结合线程池的拒绝策略,避免直接 使用get方法(导致线程一直阻塞中,进而引发服务器CPU飚高)。
综上所述是对FutureTask的get方法阻塞陷阱问题结合源码底层进行深度剖析,是我自己在工作中遇到的坑,如果你有用到这块知识,希望可以帮你避坑,当然如果有理解不到的地方望指正哟。





![NSSCTF(MISC)—[justCTF 2020]pdf](https://i-blog.csdnimg.cn/direct/dcd18c0b76a34fbc8cdbd641a5ae75d7.png)