Python Note 2
- 1. Python 慢的原因
- 2. 三个元素
- 3. 标准数据类型
- 4. 字符串
- 5. 比较大小: 富比较方法 rich comparison
- 6. 数据容器 (支持*混装* )
- 一、允许重复类 (list、tuple、str)
- 二、不允许重复类 (set、dict)
- 1、集合(set)
- 2、字典(dict)
- 3、特殊: 双端队列 deque
- 三、数据容器的共性
- 四、生成器 (推导式 + yield关键字)
- 7. 方法
- 一、4种方法参数 (「位置参数 `/`、`*` 关键字参数」、不定长参数、缺省参数)
- 二、方法本身作为参数
- 三、lambda 函数
- 四、实例方法,静态方法,类方法
- 五、函数参数 与 闭包 (Closure)
- 六、装饰器 (Decorator, 切面作用, 本质是特殊的闭包)
- 七、property 属性
- 8. 文件
- 9. 异常
- 10. 模块
- 11. 下划线
- 12. Typing 模块
- 13. Python 并发编程
- 协程 (Coroutine: 协同程序)
- 信号量 Semaphore
1. Python 慢的原因
- 动态类型语言, 边解释边执行
- GIL (Global Interpreter Lock, 全局解释器锁)
- 为了规避并发问题引入GIL
- 引用计数器
2. 三个元素
变量、标识符 identifiers (变量名 函数名 类名)、字面量 (被写在代码中固定的值, 常用: 整数 浮点数 字符串)
- 不允许使用关键字作为标识符. 如 raise、elif、in、as、except、assert、from、nonlocal
- 不允许使用自带函数名作为标识符, 会顶替掉函数功能. 如 sum、len
python 是动态类型强类型语言. 决定了变量名没有类型, 类型是运行决定的
- 强弱: 类型隐式自动转换
- 动静: 类型检查, 动:运行期or静:编译期
# 30个关键字
and exec not assert finally or break for pass class
from print continue global raise def if return del import
try elif in while else is with except lambda yield
3. 标准数据类型
-
Python 的标准数据类型有:
- Boolean(布尔值)
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
-
Golang 不是面向对象的语言, 没有关键字 Class, 通过 struct、interface 类型实现 OOP 编程风格
- boolean(布尔值)
- numeric(数字)
- string(字符串)
- 数组(数组)
- slice(切片:不定长数组)
- map(字典)
- struct(结构体)
- pointer(指针)
- function(函数)
- interface(接口)
- channel(通道)
-
多变量赋值
a = b = c = 1 -
判断相等
a == b值相等a is bid 相等id(a) == id(b)isinstance(a, int)issubclass(int, object)
4. 字符串
-
单引号方式、双引号方式、三引号方式:
" ‘会显示单引号’ “、 ’ “会显示双引号” '、 “”“字符串3"”” -
字符串的输出:
- 加号拼接方式: “会返回” + “新的字符串”
- 百分号占位符方式: “%s %d %f” % (str(a), int(b), float©)
- 占位符精度控制 m.n (注意: 超过 m 会忽略、在 n 处会四舍五入)
- 快速格式化方式: f"{name} {variable}" # 不会理会类型, 全转为字符串, 不做精度控制
-
字符串输入:
- input(“提示信息!”) # 获得的永远都是字符串类型 str
-
字符串比较, 头到尾 ->, 其中一位大, 后面就无须比较
-
True、False 产生: 字面量, 比较运算
-
函数没有 return 语句也会返回值: 字面量 None (类型为: <class ‘NoneType’>, 使用场景有: if 判断、变量定义)
5. 比较大小: 富比较方法 rich comparison
__gt__(相反__lt__)
- 当都定义时, 分别调用.
- 当另一个未定义时, 未定义的操作会调用已定义的方法取反.
__le__和__ge__
- 当都定义时, 分别调用.
- 当另一个未定义时, 未定义的操作会调用已定义的方法取反.
__eq__和__ne__
- 在自定义类中实现了
__eq__和__ne__这两个方法,则==和!=的两个对象比较分别调用了这两个方法进行比较. - 当实现了
__eq__方法,未实现__ne__方法时, 未定义的操作会调用__eq__方法取反. - 但实现了
__ne__方法,未实现__eq__方法, 则!=调用__ne__方法,而__eq__调用系统内置的==对应的方法
isvs==- is 表示的是对象标示符(object identity)
相当于id(a) == id(b), 是检查两个对象是否指向同一块内存空间 - == 表示的是相等(equality)
相当于a.__eq__(b), 是检查他们的值是否相等 - Python 里和
None比较是is None
因为None是个单例类型,True和False也是.
is比==更严格的检查
- is 表示的是对象标示符(object identity)
6. 数据容器 (支持混装 )
- python中的数据容器支持混装: str、int、bool
- map、list、set、都可以放入不同类型的变量
- 5类数据容器
- list
[1,2]tuple(1,2)str"12"set{1,2}dict - 字符串也可以作为容器, 支持下标索引
forinorstr.split(" ") # 返回list
- list
一、允许重复类 (list、tuple、str)
- 打磨:
new_str = my_str.strip("12")# 表示前后的 两个字串 1 和 2 都会被去除 - 统计:
my_str.count("it")# 因为允许重复, 所以可统计出现次数 - 不变类型: 字符串只可以存储字符、不可以修改
- 序列: 三个 (列表、元组、字符串) 都可被视为 序列
- 序列可以进行n切片
[start:end:step]step 默认为1 可以为负倒序执行左闭右开 - 可以连续切片
a[:8][2:5][-1:] # [:8]就是0取到8 在从其中取2到5 最后取-1位 [4] - 切片操作的时候, 超出下标不会报错, 相互矛盾的话不会报错, 返回为空
- 取反操作
[::-1]可取代reverse()
- 序列可以进行n切片
- 批量追加:
list.extend(seq)扩展原来的列表- 在列表末尾一次性追加另一个序列中的值
- 无返回值,但会在已存在的列表中添加新的列表内容
- 元祖在只有一个元素时必须加逗号
(1,)记住元祖是不可变对象, 定义是什么就是什么- 只有这样才保证没有歧义
- python 在打印时也会加上
- 另外, 空的元祖不需要加逗号
()
二、不允许重复类 (set、dict)
1、集合(set)
- 特点:
- 无序存储
- 不支持下标
- 不允许重复数据存在 (重要的去重功能)
- 不支持while循环
- 常用方法:
- set1.union(set2) 不变, 返回并集
- set1.difference(set2) 不变, 返回差集
- set1.difference_update(set2) set2不变, set1去掉set2中的元素
2、字典(dict)
- 特点:
- key不重复
- 不支持下标
- key 和 value 支持任意类型, 但 key 不可为字典类型和可变类型
- 使用:
- 存放:
字典[key] = value - 取出:
字典.pop(key)(对应 value 删除) - 清空:
字典.clear() - 获取所有key:
字典.keys()- 可用于 for 循环
for f in futures默认就等于for f in futures.keys()
- 长度:
len(字典) - 是否包含:
字典.__contains__(key)orif xx in 字典:
- 存放:
- 特殊:
- 元祖的key可以是元祖 (包含不可变对象)
- 元组只有在其元素是可散列的(不可变类型)情况下,才可以作为字典的key值
- e.g. (“unhashable type: ‘list’”, [1, 2, 3], “unhashable type ‘dict’”, {})
3、特殊: 双端队列 deque
- 引入:
from collections import deque - 使用:
- append pop extend [+ left]
- index, insert(1, ?), count(“a”)
- remove, reverse, rotate, copy
三、数据容器的共性
- 都支持 for 循环遍历
- 函数:
len(容器)、max(容器)、min(容器)、sorted(容器, [reverse=True])
四、生成器 (推导式 + yield关键字)
补充:
range()函数
1. 语法:range(start, stop[, step])orrange(stop)# default: start=0, step=1
2. 区分:
1. python3range()返回的是一个可迭代对象 (类型是对象) 打印的时候不会打印列表.
2. python2range()返回 列表类型(整数列表)
为什么要使用生成器: 生成器的数据是: 使用一个, 再生成一个, 可以节约大量内存
-
生成器的使用记住:
next(生成器对象)方法 -
推导式是一种数据处理方式, 类似于stream流. (从一个数据序列构建另一个新的数据序列)
- 列表推导式语法:
[表达式 for 变量 in 列表 [if 条件]]其中:- 迭代 列表 将 变量 传入到 表达式 中.
- 表达式可以是有返回值的函数也可以是固定值
- if 条件语句, 可以过滤列表中不符合条件的值
- 字典推导式语法:
{ key_expr: value_expr for value in collection [if condition ]} - 集合推导式语法:
{ expression for item in Sequence [if conditional]} - 生成器推导式语法:
(expression for item in Sequence if conditional )- 生成推导式返回的结果是一个生成器对象, 不是元祖
<generator object <genexpr> at 0x1074abac0> - 使用 tuple 函数:
tuple(a), 可以将生成器对象转换成元组 - 获取下一个值, 使用
next(genertor)函数 - 遍历生成器中的每一个值. 使用
for i in genertor:循环
- 生成推导式返回的结果是一个生成器对象, 不是元祖
- yield 关键字
- 特征: 在 def 中具有 yield 关键字
- 定义:
- 函数要有 yield 关键字, 那函数就是生成器了(变成生成器了) ;
- yield 可以把一个对象返回出去;
- 特点: 保存计算状态 (执行状态); 当然还有节约内存资源!! 每次调用只生成一个数据
- 注意点:
- 赋值时不会运行函数, 调用时才会进入 for 循环, 并停在 yield 关键字处
- 代码执行到 yield 会暂停, 然后把结果返回出去, 下次启动生成器会在暂停的位置继续往下执行
- 如果生成器把数据生成完成, 再次获取生成器中的下一个数据会抛出 StopIteration 异常, 表示停止迭代异常
- while 循环内部没有处理异常操作, 需要手动添加处理异常操作
- for 循环内部自动处理了停止迭代异常, 使用起来更方便, 推荐使用
# yield 生成式
def generator(num):
for i in range(num):
print("start")
yield i # stop
print("next generator")
g = generator(100)
print(next(g))
print(next(g))
for i in g:
print(i)
# 简写
for i in generator(100):
print(i)
- 生成器应用: 斐波那契数列
def fb(num):
a, b = 0, 1
# 记录生成了几个数字
index = 0
while index < num:
result = a
a, b = b, a + b
yield result # yield
index += 1
f = fb(5)
for i in f:
print(i)
# 简写
for i in fb(5):
print(i)
- 深拷贝和浅拷贝 import copy
- 浅: copy.copy 函数, 浅拷贝最多只拷贝一层
- 深: copy.deepcopy 函数, 深拷贝可拷贝多层, 直到遇到不可变对象
- 两种拷贝, 成功都会开辟新的空间存储拷贝的对象, 都不会拷贝不可变对象 (数据安全)
7. 方法
一、4种方法参数 (「位置参数 /、* 关键字参数」、不定长参数、缺省参数)
- 位置参数顺序必须一致, 和关键字参数混用: 位置参数必须在前面. 因为关键字参数不存在前后顺序
- 不定长参数:
*位置传递:def user(*args):所有参数都会被 args 变量收集, 根据位置顺序合并为一个元祖, args 是元祖类型. 一般命名为 args**关键字传递:def user(**kwargs):参数是 标识符=值 形式的情况下, 所有键值对都会组成字典类型(注意 key 只能是标识符, 所以不能数字开头). 一般命名为 kwargs (keyword arguments)
- 缺省参数: 定义时, 写在后面
def twoSum(self, target: int = 6, /) -> list: - 方法参数里有
/和*:/之前的参数, 调用时必须都用args方式的位置参数*之后的参数, 调用时必须都用kwargs方式的关键字传递 (指定命名调用)
def test1(a, b, /, *, c, d):
pass
test1(1, 2, c=3, d=4)
二、方法本身作为参数
- 本质是计算逻辑的传递, 而非数据的传递
- 任何逻辑都可以自行定义并作为函数传入
三、lambda 函数
- lambda 关键字和 def 对应, 只不过没有名称和括号, 只能临时使用一次
- 语法: lambda 传入参数: 函数体(一行代码)
- 函数体只能写一行, 无法写多行代码
- 函数赋值给一个变量:
dequeue = deque.popleft调用: greet()
四、实例方法,静态方法,类方法
-
实例方法 (方法本身带
self参数)
既可以获取构造函数定义的变量,也可以获取类的属性值
非本类中, 调用实例方法和实例变量, 需要先实例化类对象, 然后才能调用
本类中, 调用实例方法通过self.func_name()self 就是本类的实例引用 -
静态方法 (需要加
@staticmethod装饰器)
不能获取构造函数定义的变量,也不可以获取类的属性
静态方法不能调用 类变量,类方法,实例变量 及 实例方法, 需要实例化对象, 然后通过对象去调取
但是实例方法可以调用静态方法, 通过self.static_func()调用, 类方法也需要实例化后才能调用静态方法. -
类方法 (需要加
@classmethod装饰器)
无需实例化, 不能获取构造函数定义的变量,可以获取类的属性
在类中, 类方法调用类变量, 通过cls.cls_param的方式直接调用 -
属性方法 (需要加
@property装饰器)
类属性方法无传参且必须有返回值, 实例化对象调用的时候通过调取属性的方式进行调用 -
构造函数和析构函数
- 构造函数, 实例化自动调用该方法, 一般放些属性及初始化的内容
- 析构函数, 类实例被销毁的时自动执行
class Person(): #定义类
date = '20201215' # 类变量
def __init__(self, weather = 0): # self 本类, this对象
self.name = 'Stephen' # 实例变量
self._weather = weather
def __str__(self):
return self.date + ' ' + self.name
def info(self): # 实例方法
self.name='xiaoming'
@property
def weather(self): # 属性方法
print("getting")
return self._weather
@weather.setter
def weather(self, value):
print("setting")
if not isinstance(value, int):
raise ValueError("weather must be an integer!")
if value < 0 or value > 100:
raise ValueError('weather must between 0 ~ 100!')
self._weather = value
@staticmethod # 静态方法:校验输入值类型和大小是否符合咱们的类型。
def var_str(date_str):
year, month, day = tuple(date_str.split("-"))
if 0 < int(year) and 0 < int(month) <= 12 and 0 < int(day) < 32:
return True
else:
return False
@classmethod # 类方法
def class_method(cls, date_str):
if cls.var_str(date_str): # 这里是调用静态方法,注意要用 cls.静态方法,原理和实例方法中的self一样,自己可以试试,否则是不能读取的。
year, month, day = tuple(date_str.split("-"))
return cls(int(year), int(month), int(day))
def __del__(self): # 析构函数,类销毁自动执行
print("类销毁的时候就执行")
- 拆包
def a(*arg):
print(*args) # *args 相当于 print(a, b)
def run(**kwargs):#传来的 key = value 类型的实参会映射成kwargs里面的键和值
# kwargs是一个字典,将未命名参数以键值对的形式
print(kwargs)
print("对kwargs拆包")
# 此处可以把**kwargs理解成对字典进行了拆包,{"a":1,"b":2}的kwargs字典又
# 被拆成了a=1,b=2传递给run1,但是**kwargs是不能像之前*args那样被打印出来看的
run1(**kwargs)
#print(**kwargs)
def run1(a,b): #此处的参数名一定要和字典的键的名称一致
print(a,b)
-
- *args作为形参时是用来接收多余的未命名参数,而**kwargs是用来接收key=value这种类型的命名参数,args是元组,kwargs是字典。
- *和 ** 在函数体中除了拆包之外,并没有什么卵用。
- 装包的含义就是把未命名参数和命名参数分别放在元组或者字典中
- 类似的有 js 中的解构
import X, { myA as myX, Something as XSomething } from './A'
// X: export default 42
// {}: export const A=42
let obj = {a: 1, b: 2};
let {x, y} = obj;
//x undefined
//y undefined
let {a, b} = obj;
//a 1
//b 2
let {b, a} = obj;
//b 2
//a 1
let {a: x, b: y, c: z = {num: 1}} = obj; //a 报错 //b 报错 //x 1 //y 2
// z 有默认值
五、函数参数 与 闭包 (Closure)
-
函数参数 (函数可以像普通变量一样作为参数使用)
- 函数名 存放的是: 函数所在空间的地址
- 函数名 也可以像普变量一样赋值, 两者等价
- 函数名() 执行的是函数名背后存放空间地址中的代码
-
闭包 (Closure 暂时封锁, function closures, 内部函数)
- 函数用完, 局部变量都会被销毁, 但有时我们需要保留…
- 闭包就是能够读取其他函数内部变量的函数(函数嵌套)
- javascript中,只有函数内部的子函数才能读取 局部变量 ,所以闭包可以理解成“定义在一个 函数内部 的函数 - 闭包的作用: 保存函数内的变量, 不会随着函数调用完而销毁, 提高代码复用性.
- 在本质上,闭包是将函数内部和函数外部连接起来的桥梁 - 闭包的定义 (3个):
-
- 函数嵌套的前提下
-
- 内部函数使用了外部函数的变量 (自由变量)
-
- 且外部函数返回了内部函数 (函数被当成对象返回, 闭包则实际上是一个函数的实例,也就是说它是存在于内存里的某个结构体),
- final: 我们把这个
使用外部函数变量的内部函数称为闭包
-
- 两个关键元素: 闭包意味着同时包括 函数指针 和 环境
- 关键字 (必须在使用之前声明)
nonlocal非局部变量关键字, 声明是 外部嵌套函数 的变量 (并且不是全局变量)global全局变量关键字, 如果局部 不声明不修改 全局变量, 也可以不用
- 支持函数参数赋值的语言一般都支持闭包
- 函数用完, 局部变量都会被销毁, 但有时我们需要保留…
def normalFunc(num1):
def closure(num2):
nonlocal num1 # 只有使用关键字nonlocal后, 修改才会生效.
num = num1 + num2
print("now value", num)
# num1 += 10 # 直接修改外部变量(环境)实际只是内部重新声明了一个num1和外部无关
# nonlocal num1 # 必须在所有使用之前声明!! 不能在中途声明
num1 += 10
return closure
func = normalFunc(10) # actually: func = (closure + 环境)
func(1) # actually: func() = closure()
func(2)
- 闭包的原理:
- 闭包函数相对与普通函数会多出一个
__closure__的属性, 里面定义了一个元组用于存放所有的cell对象, 每个cell对象 (元祖)一一保存了这个闭包中所有的外部变量
- 闭包函数相对与普通函数会多出一个
printer = make_printer('Foo', 'Bar') # 形成闭包
printer.__closure__ # 返回cell元组
# (<cell at 0x03A10930: str object at 0x039DA218>, <cell at 0x03A10910: str object at 0x039DA488>)
printer.__closure__[0].cell_contents # 第一个外部变量
# 'Foo'
六、装饰器 (Decorator, 切面作用, 本质是特殊的闭包)
早期函数添加额外功能是这样的: 在函数下方紧接着替换函数签名
def debug(func): # func: 被装饰的目标函数
def wrapper(): # 装饰器的本质是闭包, 只不过外部函数入参是函数
print "[DEBUG]: enter {}()".format(func.__name__)
"""函数执行前"""
result = func()
"""函数执行后"""
return result
return wrapper
def say_hello():
print "hello!"
say_hello = debug(say_hello) # 使用装饰器装饰函数
- 装饰器语法糖:
@装饰器名称
@debug # 外部函数的名字 (注意一定是闭包), 等于 say_hello = debug(say_hello)
def say_hello():
print "hello!"
- 装饰带有参数的函数
- 内部函数应该和 被装饰函数 参数一样多
- 外部函数的 入参函数 也应该和 被装饰函数 一致
- 装饰带有不定长参数的函数 (特例: 通用装饰器)
def inner(*args, **kwargs): fn(*args, **kwargs)
- 多个装饰器使用: 越靠近函数名的越先包装(靠近的在内层)
- 带参数的装饰器: 使用时指定参数
@getTime(参数, ...)- 装饰器的外部函数只能有一个参数
- 实际是先执行装饰器函数, 然后再返回装饰器 (中间没有任何执行逻辑)
def decorator(fn, flag): # 错误
def inner(num1, num2):
if flag == "+":
print("addition")
elif flag == "-":
print("subtraction")
result = fn(num1, num2)
return result
return inner
def logging(flag): # 正确装饰器
def decorator(fn): # 外部函数
def inner(num1, num2):
if flag == "+":
print("addition")
elif flag == "-":
print("subtraction")
result = fn(num1, num2)
return result
return inner
return decorator # 返回装饰器
@loggin("+")
def add(a, b): # 实际: 1. logging("+") 2. add = decorator(add)
- 类装饰器
__call__方法
一个类里面一旦实现了该方法, 那么这个类创建的对象就是一个可调用的对象, 可以像调用函数一样进行调用
class Check(object):
def __call__(self, *args, **kwds):
print("I'm call method")
c = Check()
c()
- 类装饰器的定义
class CheckI:
def __init__(self, func) -> None: # func = comment
self.__fn = func
def __call__(self, *args: Any, **kwds: Any) -> Any:
print("登陆")
self.__fn(*args, **kwds) # comment()
@CheckI # comment = Check(comment)
def comment():
print("发表评论")
comment() # comment() 其实就是上面的 c()
"""
登陆
发表评论
"""
- 带参数的类装饰器
class logging(object):
def __init__(self, level='INFO'):
self.level = level
def __call__(self, func): # 接受函数
def wrapper(*args, **kwargs):
print "[{level}]: enter function {func}()".format(
level=self.level,
func=func.__name__)
func(*args, **kwargs)
return wrapper #返回函数
@logging(level='INFO')
def say(something):
print "say {}!".format(something)
- 类装饰器总结
- 想要让类实例对象能够像函数一样调用, 需要在类使用call方法, 把类实例变成可调用对象
- 类装饰器 装饰 函数功能, 是在call方法里面进行添加的
- 类装饰器最重要的就是 可继承
七、property 属性
定义property属性有两种方式: 装饰器方式、类属性方式
注意: 属性必须先在 __init__ 里面声明, 不然: "XX" object has no attribute "_XX__age"
- 装饰器方式 Decorator
@property表示把方法当作属性使用, 表示获取属性时会执行下面修饰的方法方法名.setter表示把方法当作属性使用, 表示设置属性时会执行下面修饰的方法- 装饰器方式的 property 属性修饰的方法名一定要一样
class Person:
def __init__(self) -> None:
self.__age = 0
# 装饰器方式
@property # @property 表示把方法当作属性使用, 表示获取属性时会执行下面修饰的方法
def age(self): # 装饰器方式的 property 属性修饰的方法名一定要一样
return self.__age
@age.setter # 方法名.setter 表示把方法当作属性使用, 表示设置属性时会执行下面修饰的方法
def age(self, new_age):
if new_age >= 150:
print("???")
else:
self.__age = new_age
p = Person()
# age = p.age()
print(p.age) # 自动调用 @property
p.age = 100 # 自动调用 @setter
- 类属性方式 Class
- 语法:
property属性 = property(获取值方法, 设置值方法) - 第一个参数时获取属性时要执行的方法
- 第二个参数时设置属性时要执行的方法
- 语法:
class ClassPerson:
"""类属性方式
"""
def __init__(self) -> None:
self.__age = 0
def get_age(self):
return self.__age
def set_age(self, age):
if age >= 150:
print("???")
else:
self.__age = age
age = property(get_age, set_age)
8. 文件
文件的4种操作: 打开、关闭、读、写 常用步骤: open -> read/write -> close
python 内置了文件操作函数
- open()
- 语法:
f = open("python.txt", "r", encoding="UTF-8")# encoding 顺序不是第三位, 只能用关键字参数- name: 文件名或路径名
- mode: 文件打开模式 (只读 r、写入 w(原有删除、会创建文件)、追加 a (会创建文件)、etc.)
- encoding: 文件编码格式 (推荐使用 UTF-8)
- open() 方法返回的是文件对象, 拥有属性和方法
- 语法:
- read()
- 语法: 文件对象.read(num) # 不填, 表示读取所有数据
- readlines() 方法: 一次性读取, 每行数据合成列表
- 注意文件指针的位置
- readline() 方法: 一次只读取一行
- for 遍历:
for line in open("README.md", "r"):orfor line in f:# for 遍历和 readline() 有关
- close() 关闭文件对象
- with open 语法:
with open("READEME.md", "r") as f:在 with open 块中对文件进行操作, 结束后自动close文件
- with open 语法:
- write()
- mode 必须有 w, f = open(“xx.txt”, “w”) # 在写入模式下文件不存在会自动创建 (反面: x 新建存在会报错)
- 语法1: f.write(“hello world”) # 文件写入
语法2: f.flush() # 内容刷新. close() 内置了flush() // 作用: 多次写入, 一次输出
time.sleep(5) # 5s
9. 异常
- 处理异常 (异常可以传递)
try:
print(name)
except [NameError as e]:
print("occur except")
print(e) # name 'name' is not defined
try:
print(1/0) # ZeroDivisionError: division by zero
except (NameError, ZeroDivisionError) as e:
print("ZeroDivision or Name Error")
# 完整语法
try:
print(1/0)
except Exception as e:
print("出现异常, 原因: ", e)
else: # 可选
print("没有发生任何异常")
finally: # 可选
f.close()
# 简洁语法
import sys
for line in sys.stdin:
try:
a = line.split()
print(int(a[0]) + int(a[1]))
except:
continue
- 抛出异常
if current is None:
raise ValueError("是你下标过了头")
# or
assert current is not None, "你下标过头了" # 该异常是 AssertionError
10. 模块
- 只能找到当前目录, 以及子目录的包, 找不到上层目录
- 导入语法:
[from 模块名] import [模块|类|变量|函数|*] [as 别名]
- case:
from time import time as ti, sleep
- 使用语法: 模块名.功能名()
- case:
sleep(0.5)、now = ti()
- 自定义模块: 每个python 文件都可以作为一个模块, 模块的名字就是 文件名
- 自定义模块名必须符合标识符命名规则
注意:
- 导入多个模块, 模块内有同名功能时, 调用到的是: 后导入的模块的功能
- 可以使用 as 区分同名模块
- 测试模块: 导入模块的单元测试要写:
if __name__ == "__main__":因为在导入时会自动调用该模块, 无论是导入其中的函数还是变量都会执行 (__name__变量执行本文件时为main, 模块调用时为文件名)
__name__变量. 当 Python 解释器读取一个源文件时,它首先定义了一些特殊的变量。在这种情况下,我们关心__name__变量。当你的模块是主程序时, 解释器会将硬编码的字符串分配给"__main__"变量__name__. 当您的模块被另一个模块导入时, 解释器将搜索您的foo.py文件 (以及搜索其他一些变体),并且在执行该模块之前,它会将"foo"导入语句中的名称分配给__name__变量.
__all__变量 (列表类型). 当该变量存在时,import *只能导入这个列表中的元素.
注:__all__未限制 单独指定 的方式
11. 下划线
非官方
- 前置单下划线:
_var(仅在内部使用, 变量或方法, 只有约定含义) - 后置单下划线:
var_(绕过命名冲突, 规避关键字占用, 只有约定含义) - 常量: CONST_VAR (使用全大写, 只有约定含义)
官方 - 前置双下划线:
__var(私有, 变量会被名称改写 (name mangling),__baz -> _Test__baz防止变量在子类中被重写, 子类的子类_ExtendedTest__baz) - 前后置双下划线:
__var__(一般 python 内置函数保留) - 单下划线:
_- 代表不关心, 循环中不需要访问正在运行的索引,可以使用 " _ " 来表示它只是一个临时值:
for _ in range(32):. - Python REPL中的一个特殊变量,表示由解释器最近一个表达式的结果. 获取命令行上一条语句执行的结果
- 代表不关心, 循环中不需要访问正在运行的索引,可以使用 " _ " 来表示它只是一个临时值:
12. Typing 模块
Python是一种动态类型语言,这意味着我们在编写代码的时候更为自由,运行时不需要指定变量类型, 但是同时 IDE 也无法像静态类型语言那样分析代码,及时给出相应提示,如字符串的 split() 方法提示.
作用: 帮助 IDE 为我们提供更智能的提示. 特性不会影响语言本身, 是一个规范约束,不是语法限制
- Union vs TypeVar
U = Union[int, str]
def union_func(arg1: U, arg2: U) -> U:
union_func(1, “s”) # all right
result: Any = union_func(1, 2) # correct, but return int? or str?
T = TypeVar("T", int, str)
def typevar_func(arg1: T, arg2: T) -> T:
typevar_func(1, “s”) # error
result: int = typevar_func(1, 2) # correct, and return always int
- Optional
必须跟一个参数, 且只能是一个参数. 给个提示作用, 代表可以不传 (实际必须使用 None 占位)
def foo_func(arg: Optional[int] = None):
等效于:def foo_func(arg: int = None):
- 类中:
class BasicStarship:
captain: str = 'Picard' # 实例变量,有默认值
damage: int # 实例变量,没有默认值
stats: ClassVar[Dict[str, int]] = {} # 类变量,有默认值
- ClassVar
是 typing 模块的一个特殊类. 向静态类型检查器指示, 不应在类实例上设置此变量
13. Python 并发编程
多线程和多进程两者的 API 几乎一致
![[多进程.png]]
-
多进程适合 cpu 密集型计算
-
多线程适合 io 密集型计算
-
线程池不适合长时间占用
-
可等待的对象分为三种类型:协程、任务 和 Future.
- 当遇到可等待对象,进程会发生上下文切换(任务调度)
-
CPU 密集型使用多进程实例:
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from util.Util import timesum
PRIMIES = [112272535095293] * 100
def is_prime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
@timesum
def single_thread():
for number in PRIMIES:
# print(is_prime(number))
is_prime(number)
@timesum
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMIES) # 多线程甚至拖慢了速度
@timesum
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMIES) # 提升了 6 倍
if __name__ == '__main__':
single_thread()
multi_thread()
multi_process()
""">>开始计时!
<<耗时 23.292997 s
>>开始计时!
<<耗时 23.495053 s
>>开始计时!
<<耗时 4.086435 s"""
协程 (Coroutine: 协同程序)
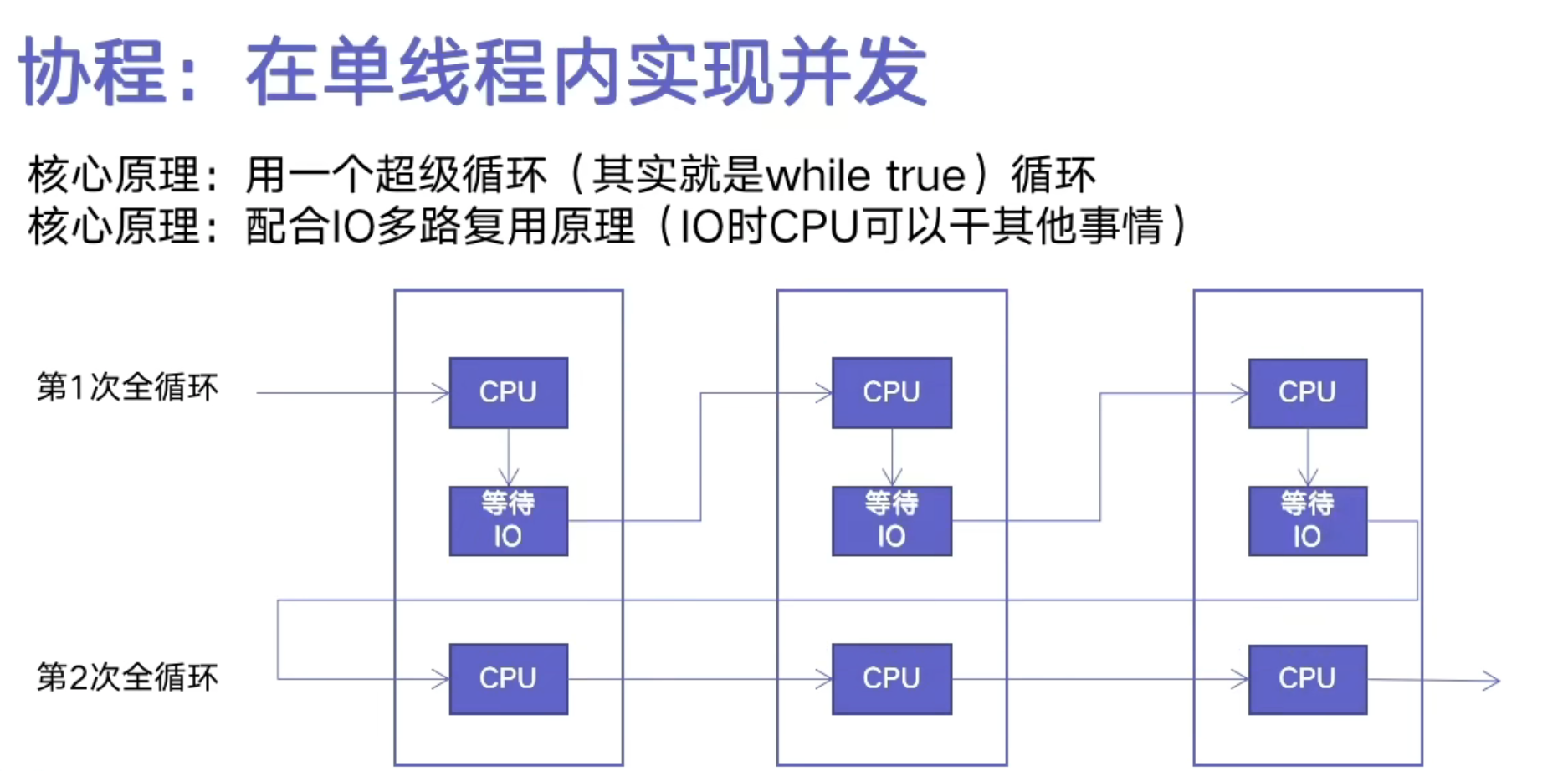
- 在单线程内实现并发
- 核心原理1: 用一个超级循环 (其实就是while true:) The one loop
- 核心原理2: 配合 I/O 多路复用原理 (IO时 CPU 可以干其他事情)
- 单线程异步爬虫, 很多时候是快于多线程的
- 多线程不同线程调度的切换, 本身是耗费时间的
- 没有上下文切换的开销, 相对来说更快
import asyncio
# 获取事件循环
loop = asyncio.get_event_loop()
# 定义协程
async def myfunc(url): # async 说明函数是一个协程
await get_url(url) # await 对应 IO, 执行到这里不进行阻塞, 超级循环直接进入下一个程序的执行
# 创建task列表
tasks = [loop.create_task(myfunc(url))]
# 执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks)) # 执行直到完成/ 等待任务的完成
# 补充
## 运行
asyncio.run(main())
asyncio.run(asyncio.gather(main(),main2()))
- 协程异步注意事项:
-
要用在异步IO编程中, 依赖的库必须支持异步IO特性
-
到达await关键字,发生上下文切换
-
不使用 await 函数不会暂定现场,不会再回到该调用点
-
当一个协程通过 asyncio.create_task() 等函数被封装为一个 任务, 该协程会被自动调度执行
-
通常情况下 没有必要 在应用层级的代码中创建 Future 对象。这是一种特殊的 低层级 可等待对象
信号量 Semaphore
- 异步IO中使用信号量控制爬虫并发度
- Semaphore 信号量、旗语
- 是一个同步对象, 用于保持在 0 至 指定最大值之间的一个计数值
- 完成一个对该 semaphore 对象的等待 (wait) 时, 该计数值减一 (进入并发处理)
- 完成一个对该 semaphore 对象的释放 (release) 时, 该计数值加一 (完成 释放)
- 当计数值为 0, 则线程等待该 semaphore 对象不再能成功, 直至该 semaphore 对象变为 signaled 状态 (为0等待, signaled: 已发信号状态)
- semaphore 对象的计数值大于 0, 为 signaled 状态, 计数值等于 0, 为 nonsignaled 状态,
- Semaphore 信号量、旗语

爬虫引用中的 requests 不支持异步, 需要使用 aiohttp
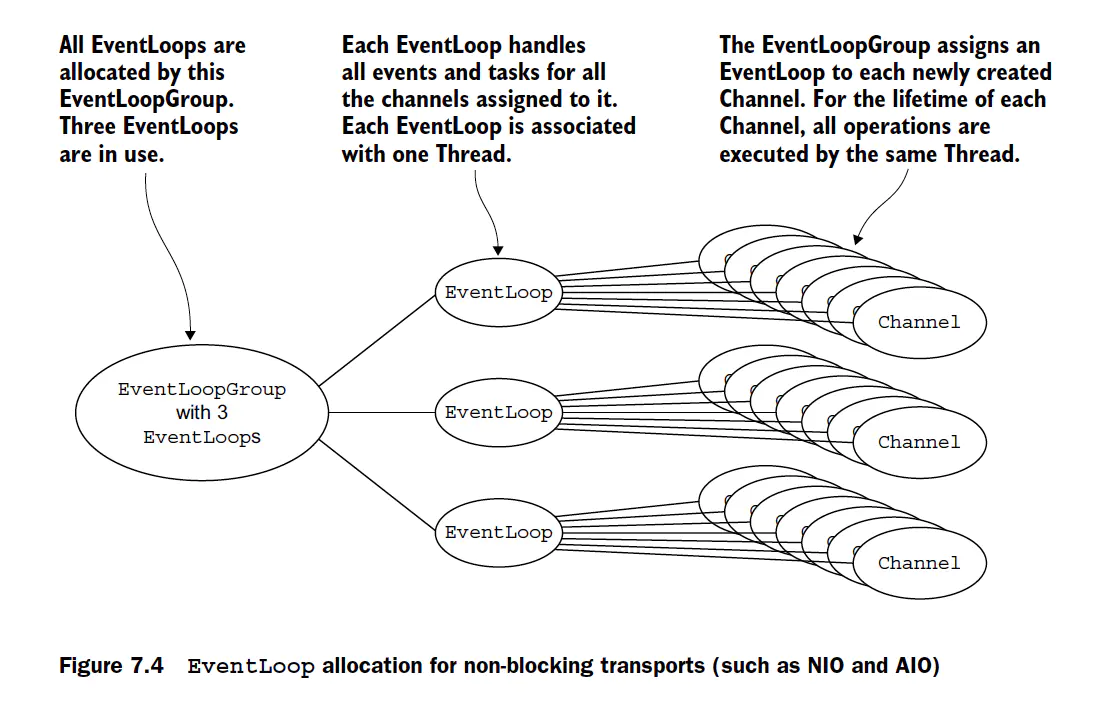
每个eventloop就是1个thread, 每个channel类似于1个协程.
进一步思考, 这跟Linux的epoll模型是否很类似