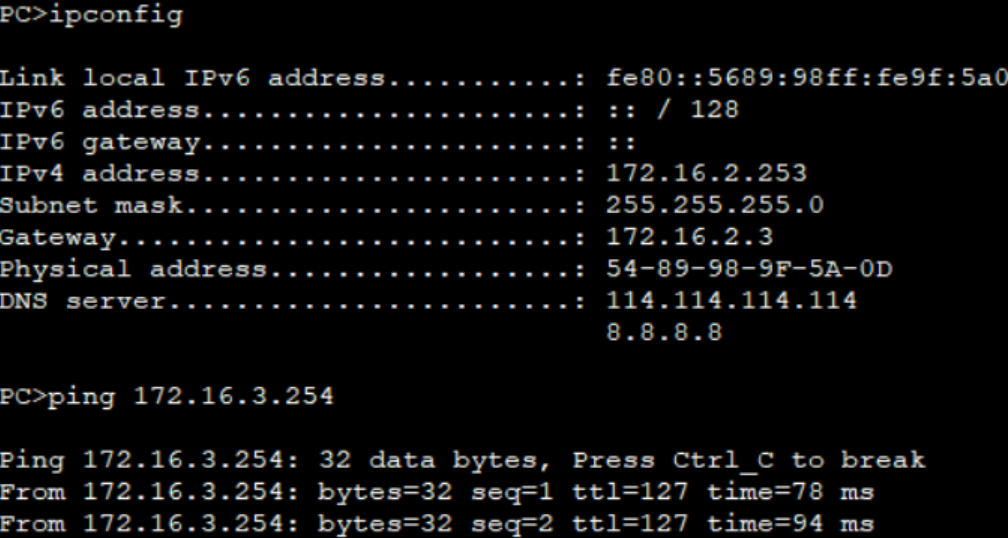
大家好,我是锋哥。今天分享关于【Kafka中的消息是如何存储的?】面试题。希望对大家有帮助;

1000道 互联网大厂Java工程师 精选面试题-Java资源分享网
在 Kafka 中,消息是通过 日志(Log) 的方式进行存储的。Kafka 的存储模型设计非常高效,能够处理大规模的数据流,下面详细介绍 Kafka 中消息的存储方式:
1. 分区(Partition)
Kafka 中的每个 主题(Topic) 可以包含多个 分区(Partition)。每个分区是一个 有序的、不可变的消息序列。Kafka 的消息存储实际上是基于分区的,每个分区是一个独立的日志文件。每个分区内的消息都有一个 顺序的偏移量(offset),这个偏移量是唯一的,可以标识消息在分区中的位置。
- 每个分区是 线性增长的,即新写入的消息会追加到分区日志的末尾。
- 每个消息在 Kafka 中都会有一个唯一的偏移量,它标识该消息在分区中的位置。偏移量是递增的,且不允许重复。
2. 消息存储的文件结构
Kafka 中每个分区都对应于文件系统中的一个目录,该目录下存储着实际的日志文件(日志段文件)。这些日志文件会随着时间的推移而生成。
结构如下:
-
日志段文件(Log Segments):每个分区会生成一个或多个日志段文件,每个文件存储一段时间内的消息。这些文件通常是 append-only 的,即消息会不断地被追加到文件末尾。Kafka 通过这种方式实现高效的磁盘写入。
- 一个日志段文件通常包含一定数量的消息。
- 每个日志段文件通常会以时间戳或大小为阈值分割。
-
索引文件(Index Files):为了快速定位消息,Kafka 会为每个分区的日志段生成一个索引文件。该索引文件存储了消息的偏移量与文件中位置的映射。通过索引文件,消费者可以快速定位到某个特定消息。
3. 消息的存储格式
Kafka 消息的存储格式通常包括以下几个部分:
- 消息头(Header):包括消息的元数据,如时间戳、消息类型等。
- 消息体(Body):这是实际的消息内容。
- 校验和(Checksum):为了保证消息的完整性,Kafka 会对消息进行校验,确保在传输和存储过程中没有数据损坏。
4. 日志的持久化与清理
Kafka 的消息并不是永久存储的。消息会根据配置的 保留策略 进行清理。Kafka 支持两种主要的日志保留策略:
-
基于时间的保留(Time-based retention):消息在 Kafka 中存储一段指定的时间,例如可以配置 Kafka 保留消息 7 天,超过7天的消息将被自动删除。
-
基于大小的保留(Size-based retention):当分区中的日志文件达到某个大小时,旧的消息会被删除或压缩,以释放空间。比如,可以配置保留最多1GB的数据,超过该大小时,最旧的日志会被删除。
Kafka 的日志清理是一个后台任务,它会定期检查日志的大小或存储时间,自动删除过期的消息。这种设计使得 Kafka 在处理海量数据时能够有效管理磁盘空间。
5. 消息的副本(Replication)
为了保证数据的高可用性和容错性,Kafka 支持消息的 副本机制(Replication)。每个分区可以有多个副本(副本数量由配置决定),这些副本存储在不同的 Kafka 节点上。
- 主副本(Leader):每个分区有一个主副本(Leader),所有的生产者和消费者通过主副本来读写数据。
- 副本(Followers):主副本有一个或多个副本,副本同步主副本的消息,确保即使主副本故障,也能从副本恢复数据。
副本机制不仅保证了数据的高可用性,还能提高 Kafka 的容错能力。即使某些 Kafka 节点出现故障,数据依然可以从其他副本恢复。
6. 消费与存储隔离
Kafka 中的消息存储和消费是 解耦的,这意味着消息一旦写入 Kafka 中,就会持续存在于磁盘上,直到它们满足清理条件(例如超过保留时间或达到大小限制)。消费者消费数据时不需要影响消息的存储,消费者可以随时从任何偏移量开始读取数据。这种设计使得 Kafka 能够实现高效的数据存储与消费。
总结
Kafka 中的消息存储基于 分区(Partition) 和 日志文件。每个主题由多个分区组成,分区内部的消息以 顺序追加的方式 存储。每个分区中的消息按偏移量排序,消息会保存在磁盘上,直到满足保留策略(如时间或大小限制)。此外,Kafka 通过 副本机制 提高了数据的容错性和高可用性,确保消息在分布式环境中的可靠存储。




![[ C语言 ] | 从0到1?](https://i-blog.csdnimg.cn/direct/13d60a32caec4649aefe75c708efe0ca.png)
![[Mac]利用Hexo+Github Pages搭建个人博客](https://i-blog.csdnimg.cn/direct/4cd015aa99d0421f8087b872b9ea6170.png)