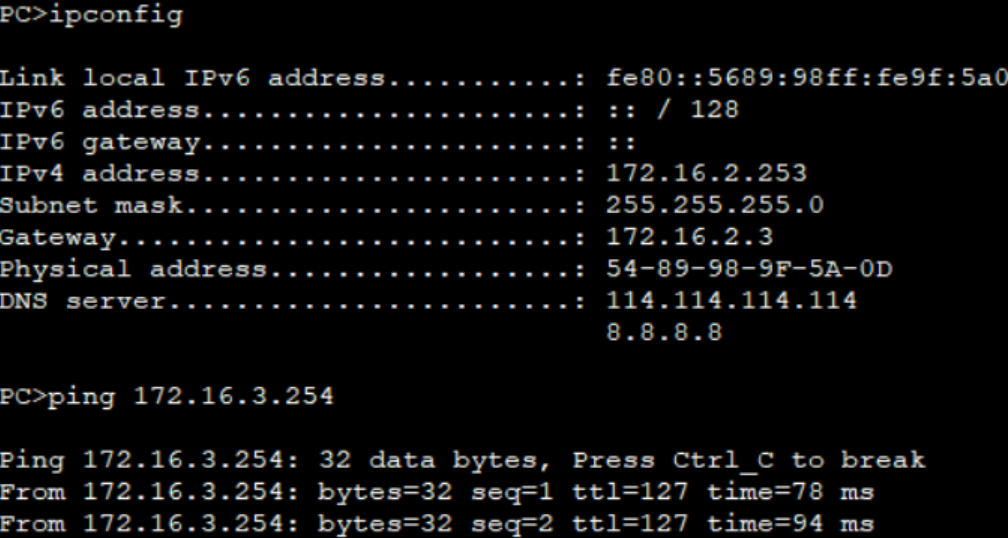
文章目录
- 一、引言
- 二、主流产品与方案对比表
- 三、自建方案 vs. 开源产品集成:技术路径对比
- 3.1 自建方案
- 3.2 开源产品集成方案
- 四、结论与个人观点
一、引言
在当今数据驱动的商业环境中,构建高质量的知识库已成为企业数字化转型的关键一环。本博客分别从产品经理、CTO 及 CDO(首席数据官,参照 DAMA 数据管理框架)角色去讨论企业级知识库建设。企业在选择技术路线时必须权衡实际需求、研发资源、数据治理及未来扩展性。本文将结合技术细节和工具实践,对自建方案与开源产品集成两大路径进行深入对比和解析,并以大表格形式直观呈现当前主流产品的特点,供企业在产品选择时参考。
二、主流产品与方案对比表
下表汇总了当前较为成熟的几套产品及相关开源项目,从产品功能模块、优势、劣势、适用场景及技术要求等多维度进行对比,直观展示各产品的特点与局限。
| 产品/项目 | 功能模块概览 | 优势 | 劣势 | 适用场景 | 技术要求及备注 |
|---|---|---|---|---|---|
| Haystack | 数据采集、预处理、嵌入生成、向量索引(FAISS/Milvus)、问答与重排序 | 模块化管道设计,集成多预训练模型,快速原型开发,社区活跃 | 多模态支持较弱,定制化扩展需额外开发 | 企业内部文档搜索、客户支持、知识问答系统 | Python 环境,依赖 spaCy、NLTK、sentence-transformers 等 |
| Jina AI | 多模态数据采集、数据流(Flow)定义、嵌入生成、分布式向量检索、重排序 | 全流程支持多模态数据,高并发分布式部署,灵活定制,扩展性强 | 技术门槛较高,定制复杂业务逻辑时需深度定制开发 | 大规模实时搜索、跨媒体数据检索、复杂业务场景 | Python 环境,支持容器化部署,依赖自定义 Executor |
| Milvus | 专注向量数据库,提供大规模高效向量检索 | 高效向量检索性能,支持海量数据,易于集成至各类知识库方案 | 仅专注于向量检索,不涉及数据采集与预处理 | 高维向量搜索、推荐系统、智能检索模块 | 独立部署服务,可与 Haystack、Jina AI 等产品无缝对接 |
| Weaviate | 向量搜索引擎,内置自动化元数据管理与数据连接器 | 语义搜索能力强,自动化元数据管理,支持多数据源集成 | 社区和生态相对较新,稳定性与文档支持有待完善 | 语义搜索、知识图谱构建、企业级数据集成 | 容器化部署,RESTful API 接口,适合快速集成 |
| ElasticSearch/Vespa | 全文检索与向量搜索混合,支持实时大数据处理 | 成熟稳定,功能全面,强大的全文检索及聚合分析能力,扩展插件丰富 | 对语义搜索支持较弱,向量检索性能需依赖外部插件 | 传统搜索引擎场景、日志分析、复杂查询以及部分语义搜索需求 | 企业级搜索解决方案,需额外接入向量化模块(如加入 Milvus 或自研模型) |
说明: 表中列举的技术方案均为开源产品,企业可根据自身业务特点及技术储备,从中挑选或组合适合自身需求的产品。
三、自建方案 vs. 开源产品集成:技术路径对比
在产品经理、CTO 与 CDO 多重视角下,企业在构建知识库系统时往往面临两大路径选择:完全自建或基于开源产品集成。以下从具体实施流程、技术难点、数据治理及长期发展等方面进行深入对比分析。
3.1 自建方案
实施流程
-
需求调研与规划
- 定义业务场景、数据量、访问频率及响应时间要求。
- 编制详细系统架构设计文档,涵盖数据采集、清洗、转换、嵌入、索引与重排序全流程。
-
研发团队组建与技术攻关
- 建立跨部门协同机制(研发、数据、业务)确保各环节无缝对接。
- 针对数据清洗、OCR 提取、嵌入模型微调及大规模向量检索核心技术开展专项攻关。
-
系统开发、测试与部署
- 采用 Python 及相关工具(spaCy、NLTK、pdfplumber、python-docx 等)实现数据处理模块。
- 利用 FAISS/Milvus 搭建向量索引,设计重排序算法并进行模型验证。
- 采用容器化(Docker、Kubernetes)实现分布式部署,确保系统高可用性与扩展性。
-
数据治理与质量控制
- 建立数据质量指标(准确率、完整率、及时性),实施持续监控与优化。
- 按 DAMA 框架制定元数据管理标准、数据安全与合规策略,确保系统稳定迭代。
技术难点与应对
- 定制化开发难度大:需深入理解业务需求,进行高度定制化开发与调优。
- 数据治理挑战:数据多源、格式多样,必须构建严格的数据清洗与质量检测机制。
- 系统维护成本高:后续版本迭代与技术支持需持续投入大量资源。
3.2 开源产品集成方案
实施流程
-
产品选择与组合
- 根据表格对比,选择合适的开源产品(如 Haystack 或 Jina AI 作为主框架,配合 Milvus/Weaviate 作为向量检索引擎)。
- 明确每个组件的责任与接口,设计标准化数据交换协议。
-
快速原型开发与验证
- 利用开源产品的标准 API 快速构建原型,验证各模块的有效性与兼容性。
- 在 Jupyter Notebook 中开展代码实践,及时调试并形成文档化流程。
-
二次开发与定制扩展
- 针对企业特定需求,进行预处理、重排序算法及数据治理模块的二次开发。
- 引入微服务架构,实现各模块独立升级、弹性扩展。
-
系统集成与运维监控
- 建立集中式监控系统,实时跟踪数据处理与检索性能,确保系统稳定运行。
- 依托开源社区的活跃生态,持续关注新功能更新与安全补丁。
技术优势与治理
- 快速部署与成本节约:基于成熟开源产品,开发周期缩短,研发投入大幅降低。
- 高扩展性与灵活性:模块化设计支持灵活组合,便于后续业务需求的快速响应。
- 数据治理与安全合规:结合 DAMA 数据管理理念,利用开源产品内置的元数据管理与日志审计模块,强化数据质量管控和安全保障。
四、结论与个人观点
经过综合分析,自建方案与开源产品集成各有优劣。作为产品经理,应从业务需求出发,明确核心价值点,选择最符合企业战略的方案;作为 CTO,则更看重系统的技术架构、可扩展性和稳定性,倾向于借助开源生态快速落地,并在关键技术环节进行自主创新;而 CDO,则要求整个系统在数据质量、元数据治理及安全合规方面达标,确保知识库在全生命周期内的数据可靠性和业务价值。
最终,企业可采取混合策略:在对核心竞争力要求较高的领域自主研发,同时在标准化模块上充分利用开源产品的成熟解决方案,既保证定制化需求,又能缩短上线周期,降低整体研发与运维成本。正是这种前瞻性思维和跨部门协同,才能在激烈的市场竞争中占据智能信息处理的制高点。


![[ C语言 ] | 从0到1?](https://i-blog.csdnimg.cn/direct/13d60a32caec4649aefe75c708efe0ca.png)
![[Mac]利用Hexo+Github Pages搭建个人博客](https://i-blog.csdnimg.cn/direct/4cd015aa99d0421f8087b872b9ea6170.png)