以某线上集群为例,数据规模:每天写入 5TB,数据储存 30 天,热数据储存一周,节点数量:5 个热节点,15 个冷节点。
采用 JuiceFS 后,热节点保持不变,冷节点从 15 个降到了 10 个,同时我们用了一个 1TB 的机械硬盘做给 JuiceFS 来做缓存。

可以看到在凌晨的时候会有大量对象存储调用,这因为我们把整个的生命周期的管理操作放到了低峰期来运行。

JuiceFS 内存占用通常会在几百 MB,它在高峰期调用的时候会在不到 1.5G 以及它的 CPU 的占用,表现无异常。
以下是 JuiceFS 的使用注意事项: 第一:不共用文件系统。 因为我们把 JuiceFS 挂载到冷节点上,那么每一台机器上所看到的是一个全量的数据,更友好的方式是采用多个文件系统,每一个 ES 节点采用一个文件系统,这样能做到隔离,但是会带来相应的管理问题。
我们最终选定的是一套 ES 对应一个文件系统的模式,这个实践带来的问题是:每一个节点都会看到全量数据,这时候就会容易有一些误操作。如果用户要在上面做一些 rm ,有可能会把其他机器上的数据删掉了,但是综合考虑我们是在不同集群之间不共享文件系统,而在同一个集群里,我们还是应该平衡管理和运维,所以采用了一套 ES 对应一个 JuiceFS 文件系统 的模式。
第二: 手动迁移数据到 warm 节点。 在索引生命周期管理,ES 会有一些策略,会把热节点的数据迁到冷节点。策略在执行时,有可能是在业务高峰期,这时候会对热节点产生 IO, 然后把数据 copy 到冷节点,再把热节点的数据删除,整个热节点的系统的代价是比较大的,所以我们是采用的手动,来控制哪些索引什么时间迁移到冷节点。
第三:低峰错期进行索引迁移。
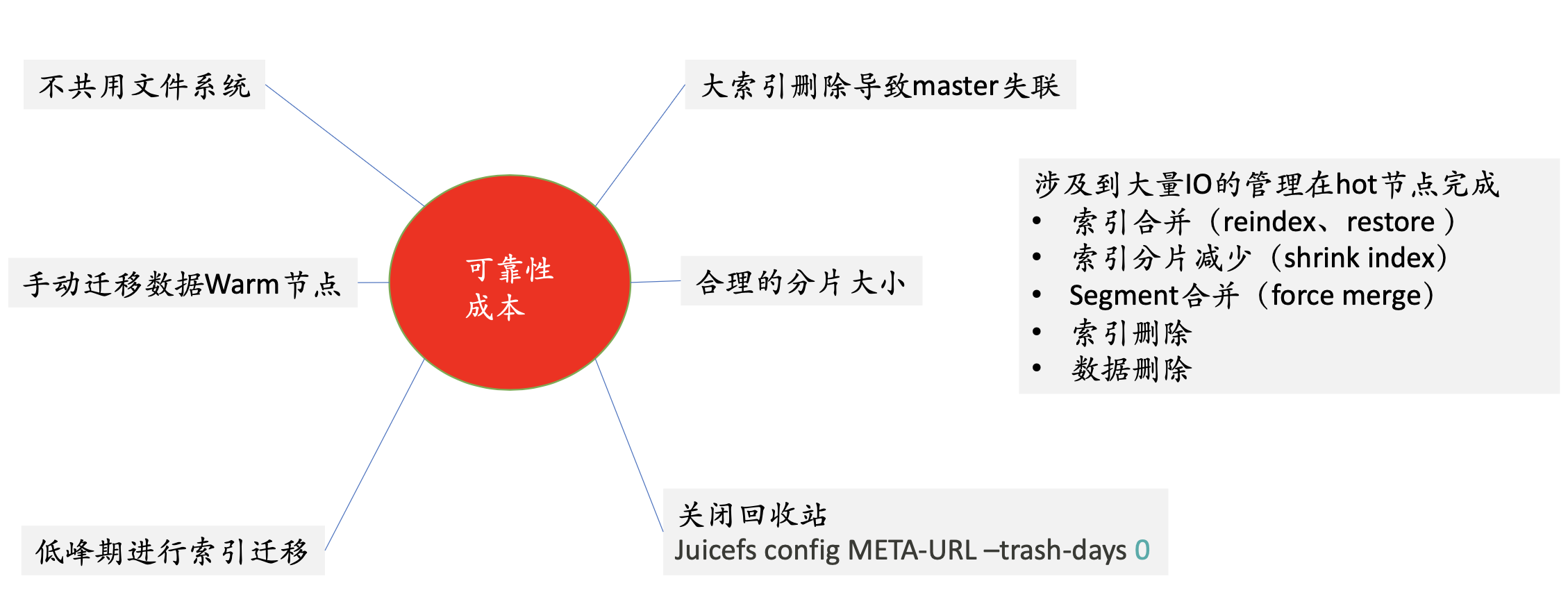
第四: 避免大索引。 在删除大索引时,它的 CPU 以及 IO 性能要比热节点要差一些,这时候会导致冷节点和 master 失联,失联以后就会出现了重新加载数据,然后重新恢复数据,整个就相当于 ES 故障了,节点故障了,这个代价是非常大的。
第五:合理的分片大小。
** 第六: 关闭回收站。** 在对象存储上, JuiceFS 默认保存一天的数据,但在 ES 的场景下是不需要的。
还有一些其他涉及到一些大量 IO 的操作,要在 hot 节点完成。比如索引的合并、快照的恢复、以及分片的减少、索引以及数据的删除等,这些操作如果发生在冷节点,会导致 master 节点失联。 虽然对象存储成本比较低,但是频繁的 IO 调用成本会升高,对象存储会要按照 put 和 get 的调用次数来收费,因此需要把这些大量的操作来放到热节点上,只供业务侧冷节点来做一些查询。
![[b01lers2020]Life on Mars (难发现的sql注入)](https://img-blog.csdnimg.cn/818bb79614354d28ab0c617ea0961c93.png)



![[附源码]java毕业设计校医院病人跟踪治疗信息管理系统](https://img-blog.csdnimg.cn/4b98914287204203bcabdea263ee6563.png)