
前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!
欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!
本文目录:
- 一、ShuffleNet架构详解
- 1. 通道混合机制(Channel Shuffle)
- 2. 深度可分离卷积(Depthwise Separable Convolution)
- 3. 轻量化设计
- 4. 自适应平均池化(Adaptive Average Pooling)
- 二、ShuffleNet架构
- 1.网络结构概述
- 2.代码实现
- 2.1 ChannelShuffleModule 详解
- 初始化方法 `__init__`
- 前向传播方法 `forward`
- 2.2 ShuffleNet 网络结构详解
- 初始化方法 `__init__`
- 前向传播方法 `forward`
- 完整代码
- 三、网络结构特点
- 1. 深度可分离卷积:高效计算的核心
- 2. 通道数的变化:动态调整通道数以优化性能
- 3. 批量归一化和 ReLU:提升训练效率和稳定性
- 4. 通道混合:增强通道间的信息流动
- 5. 自适应平均池化:适应不同输入尺寸
- 四、ShuffleNet 的优势总结
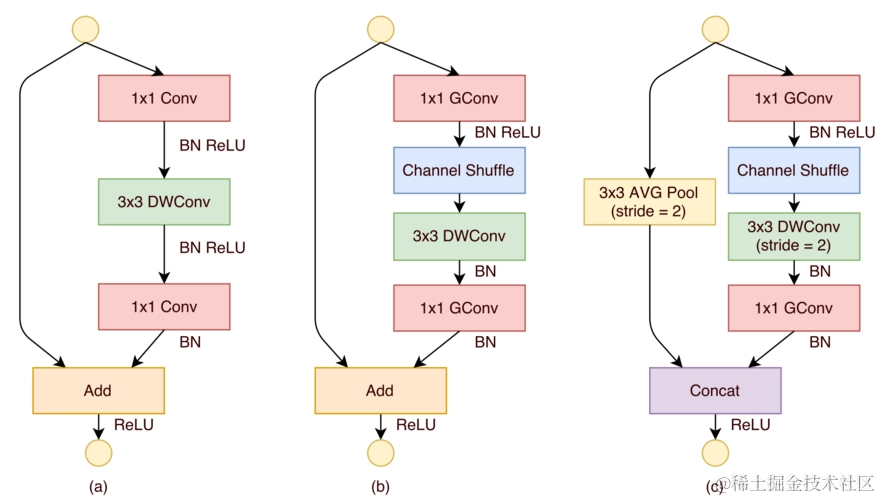
ShuffleNet是一种轻量级的深度学习模型,它在保持MobileNet的Depthwise Separable Convolution(深度可分离卷积)的基础上,引入了通道混合(Channel Shuffle)机制,以进一步提升模型的性能和效率。
一、ShuffleNet架构详解
1. 通道混合机制(Channel Shuffle)
通道混合是 ShuffleNet 的核心创新之一。在传统的深度学习模型中,卷积层的输出通道通常在空间上是高度相关的,这种相关性限制了模型的表示能力。ShuffleNet 通过通道混合机制打破了这种限制。具体来说,通道混合通过在组间重新排列通道,增强了通道间的信息流动,从而提高了模型的性能。
在实际应用中,通道混合模块的工作原理如下:假设输入张量的通道数为 C,我们将这些通道分成 G 个组,每个组包含 C/G 个通道。然后,我们在每个组内对通道进行重新排列,使得不同组的通道能够相互“交流”。这种重新排列的操作类似于洗牌,因此得名“通道混合”。
2. 深度可分离卷积(Depthwise Separable Convolution)
ShuffleNet 继承了 MobileNet 的深度可分离卷积技术。深度可分离卷积将标准的卷积操作分解为两个步骤:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。深度卷积为每个输入通道单独应用一个卷积核,而逐点卷积则通过 1×1 卷积核将深度卷积的输出通道进行组合。这种分解方式显著减少了模型的参数数量和计算量,使得 ShuffleNet 能够在计算资源受限的设备上高效运行。
3. 轻量化设计
ShuffleNet 的设计目标是实现轻量化,以便在移动和嵌入式设备上高效运行。为了达到这一目标,ShuffleNet 在多个方面进行了优化。首先,它通过深度可分离卷积减少了参数数量和计算量。其次,ShuffleNet 采用了通道混合机制,进一步提高了模型的效率。此外,ShuffleNet 还引入了自适应平均池化(Adaptive Average Pooling),允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出,为后续的全连接层提供了便利。
4. 自适应平均池化(Adaptive Average Pooling)
自适应平均池化是 ShuffleNet 的一个重要组成部分。它允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出。这种灵活性使得 ShuffleNet 能够适应不同的输入尺寸,而无需对模型结构进行调整。在实际应用中,自适应平均池化通常用于将特征图的尺寸调整为 1×1,以便为全连接层提供输入。
二、ShuffleNet架构
1.网络结构概述
ShuffleNet主要由以下几个部分组成:
- 输入层:接收输入数据。
- 深度可分离卷积层:减少参数数量和计算量。
- 批量归一化层:提高训练效率和稳定性。
- ReLU激活函数:引入非线性。
- 通道混合模块:增强通道间的信息流动。
- 自适应平均池化层:适应不同尺寸的输入。
- 全连接层:输出分类结果。
这种结构设计使得 ShuffleNet 在保持高效性的同时,也具备了较强的特征提取能力。
2.代码实现
2.1 ChannelShuffleModule 详解
ChannelShuffleModule 是 ShuffleNet 中用于增强通道间信息流动的关键组件。它通过将输入张量的通道分成多个组,并在组内进行洗牌,从而实现通道间的信息重组。
初始化方法 __init__
在初始化方法中,我们接收两个参数:channels 和 groups。channels 是输入张量的通道数,而 groups 是我们想要将这些通道分成的组数。我们通过一个断言来确保 channels 可以被 groups 整除,以保证每个组内的通道数是均匀的。
assert channels % groups == 0
接着,我们存储这些值,并计算每个组应有的通道数。
self.channel_per_group = self.channels // self.groups
前向传播方法 forward
在前向传播方法中,我们首先获取输入张量的尺寸,这包括批量大小 batch、通道数 _、序列长度 series 和模态数 modal。
batch, _, series, modal = x.size()
然后,我们将输入张量重新排列成 groups 个组,每组包含 self.channel_per_group 个通道。这一步通过 reshape 方法实现。
x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)
接下来是洗牌操作,这是通过 permute 方法实现的。我们交换 permute 方法中指定维度的顺序,从而在组内打乱通道的顺序。
x = x.permute(0, 2, 1, 3, 4)
最后,我们再次使用 reshape 方法将张量恢复到原始的形状,并将其返回。
x = x.reshape(batch, self.channels, series, modal)
return x
2.2 ShuffleNet 网络结构详解
ShuffleNet 类定义了整个网络的结构,它由多个组件组成,包括卷积层、批量归一化层、ReLU 激活函数、通道混合模块、自适应平均池化层和全连接层。
初始化方法 __init__
在初始化方法中,我们接收三个参数:train_shape 表示训练样本的形状,category 表示类别的数量,kernel_size 表示卷积核的尺寸。
def __init__(self, train_shape, category, kernel_size=3):
我们使用 nn.Sequential 来组织网络中的多个层,包括卷积层、批量归一化层、ReLU 激活函数和通道混合模块。
self.layer = nn.Sequential(
# 第一个卷积层,用于减少输入通道并进行空间维度的下采样
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
# ...
)
这里,我们首先使用一个深度可分离卷积来减少输入通道,并进行空间维度的下采样。然后,我们添加一个1x1的卷积层来扩展通道数,接着是批量归一化层、ReLU 激活函数和通道混合模块。
我们还添加了一个自适应平均池化层,它可以根据输入特征图的实际尺寸动态调整池化尺寸,以确保输出尺寸的一致性。
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
最后,我们添加一个全连接层,它将展平的特征图映射到最终的分类结果。
self.fc = nn.Linear(512*train_shape[-1], category)
前向传播方法 forward
在前向传播方法中,我们首先将输入数据 x 通过 self.layer 中定义的卷积层和通道混合模块。
x = self.layer(x)
然后,我们将结果通过自适应平均池化层,以获得固定尺寸的特征图。
x = self.ada_pool(x)
接下来,我们将特征图展平,以适配全连接层。
x = x.view(x.size(0), -1)
最后,我们通过全连接层 self.fc 得到最终的分类结果,并将其返回。
x = self.fc(x)
return x
完整代码
import torch.nn as nn
class ChannelShuffleModule(nn.Module):
def __init__(self, channels, groups):
super().__init__()
assert channels % groups == 0
self.channels = channels
self.groups = groups
self.channel_per_group = self.channels // self.groups
def forward(self, x):
'''
x.shape: [b, c, series, modal]
'''
batch, _, series, modal = x.size()
x = x.reshape(batch, self.groups, self.channel_per_group, series, modal)
x = x.permute(0, 2, 1, 3, 4)
x = x.reshape(batch, self.channels, series, modal)
return x
class ShuffleNet(nn.Module):
def __init__(self, train_shape, category, kernel_size=3):
super(ShuffleNet, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1, 1, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=1),
nn.Conv2d(1, 64, 1, 1, 0),
nn.BatchNorm2d(64),
nn.ReLU(),
ChannelShuffleModule(channels=64, groups=8),
nn.Conv2d(64, 64, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=64),
nn.Conv2d(64, 128, 1, 1, 0),
nn.BatchNorm2d(128),
nn.ReLU(),
ChannelShuffleModule(channels=128, groups=8),
nn.Conv2d(128, 128, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=128),
nn.Conv2d(128, 256, 1, 1, 0),
nn.BatchNorm2d(256),
nn.ReLU(),
ChannelShuffleModule(channels=256, groups=16),
nn.Conv2d(256, 256, (kernel_size, 1), (2, 1), (kernel_size // 2, 0), groups=256),
nn.Conv2d(256, 512, 1, 1, 0),
nn.BatchNorm2d(512),
nn.ReLU(),
ChannelShuffleModule(channels=512, groups=16)
)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512*train_shape[-1], category)
def forward(self, x):
x = self.layer(x)
x = self.ada_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
在 ShuffleNet 的初始化方法中,我们定义了一个包含多个卷积层、批量归一化层、ReLU 激活函数和通道混合模块的序列。每个卷积层都使用了深度可分离卷积技术,以减少参数数量和计算量。自适应平均池化层用于将不同尺寸的特征图转换为固定尺寸的输出,最后通过全连接层输出分类结果。
三、网络结构特点
1. 深度可分离卷积:高效计算的核心
深度可分离卷积 是 ShuffleNet 的关键特性之一,它将传统的卷积操作分解为两个独立的步骤:深度卷积(Depthwise Convolution) 和 逐点卷积(Pointwise Convolution) 。这种分解方式极大地减少了模型的参数数量和计算量。
- 深度卷积:深度卷积为每个输入通道单独应用一个卷积核,而不涉及通道间的交互。这种方式显著减少了卷积操作的计算复杂度。
- 逐点卷积:逐点卷积使用 1×1 的卷积核对深度卷积的输出进行组合,增加了通道间的交互。这种组合方式不仅减少了参数数量,还保留了模型的表达能力。
在 ShuffleNet 中,深度可分离卷积被广泛应用于多个卷积层中。例如,在第一个卷积层中,深度可分离卷积将输入通道数减少到 1,然后通过 1×1 卷积将通道数扩展到 64。这种设计不仅减少了参数数量,还为后续的卷积层提供了足够的通道数。
2. 通道数的变化:动态调整通道数以优化性能
ShuffleNet 在网络的不同阶段动态调整通道数,以优化性能和计算效率。通过 1×1 卷积层,模型能够灵活地增加或减少通道数。例如,在第一个卷积层中,输入通道数被扩展到 64,为后续的深度可分离卷积提供了足够的输入通道。这种动态调整通道数的设计不仅提高了模型的灵活性,还减少了计算量。
此外,ShuffleNet 在后续的卷积层中逐步增加通道数,以适应更复杂的特征提取需求。例如,在第二个卷积层中,通道数从 64 增加到 128;在第三个卷积层中,通道数进一步增加到 256。这种逐步增加通道数的设计使得模型能够在不同阶段提取不同层次的特征,从而提高了模型的性能。
3. 批量归一化和 ReLU:提升训练效率和稳定性
在深度学习模型中,批量归一化(Batch Normalization) 和 ReLU 激活函数 是两个重要的组件,它们能够显著提高模型的训练效率和稳定性。
- 批量归一化:批量归一化通过归一化每个特征的输入,减少了内部协变量偏移(Internal Covariate Shift),从而加快了模型的收敛速度。在 ShuffleNet 中,每个卷积层后都添加了批量归一化层,以提高训练效率和模型的稳定性。
- ReLU 激活函数:ReLU 激活函数通过引入非线性,使得模型能够学习复杂的特征表示。在 ShuffleNet 中,ReLU 激活函数被广泛应用于每个卷积层后,以提高模型的非线性表达能力。
4. 通道混合:增强通道间的信息流动
通道混合(Channel Shuffle) 是 ShuffleNet 的核心创新之一。在传统的卷积神经网络中,卷积层的输出通道通常在空间上是高度相关的,这种相关性限制了模型的表示能力。ShuffleNet 通过通道混合机制打破了这种限制。
通道混合模块的工作原理如下:假设输入张量的通道数为 C,我们将这些通道分成 G 个组,每个组包含 C/G 个通道。然后,我们在每个组内对通道进行重新排列,使得不同组的通道能够相互“交流”。这种重新排列的操作类似于洗牌,因此得名“通道混合”。
通道混合机制不仅增强了通道间的信息流动,还提高了模型的特征提取能力。在 ShuffleNet 中,通道混合模块被广泛应用于每个深度可分离卷积块后,以增强通道间的信息交互。
5. 自适应平均池化:适应不同输入尺寸
自适应平均池化(Adaptive Average Pooling) 是 ShuffleNet 的一个重要组成部分。它允许模型接受任意尺寸的输入,并将其转换为固定尺寸的输出。这种灵活性使得 ShuffleNet 能够适应不同的输入尺寸,而无需对模型结构进行调整。
在实际应用中,自适应平均池化通常用于将特征图的尺寸调整为 1×1,以便为全连接层提供输入。在 ShuffleNet 中,自适应平均池化层被放置在卷积层之后,以确保模型能够处理不同尺寸的输入数据。
ShuffleNet 的设计哲学在于通过 轻量化的设计 实现高效的特征提取。它通过 深度可分离卷积 和 通道混合技术 减少了模型的参数数量和计算量,同时保持了较高的性能。这种设计使得 ShuffleNet 非常适合在计算资源受限的移动和嵌入式设备上部署,用于图像识别和处理任务。
具体来说,ShuffleNet 的轻量化设计主要体现在以下几个方面:
- 深度可分离卷积:通过将卷积操作分解为深度卷积和逐点卷积,显著减少了参数数量和计算量。
- 通道混合:通过在组内重新排列通道,增强了通道间的信息流动,提高了模型的特征提取能力。
- 自适应平均池化:通过将特征图的尺寸调整为固定尺寸,使得模型能够适应不同尺寸的输入数据。
- 动态调整通道数:通过 1×1 卷积层动态调整通道数,优化了模型的性能和计算效率。
这种轻量化设计不仅提高了 ShuffleNet 的计算效率,还使得它能够在移动和嵌入式设备上高效运行。ShuffleNet 的高效性和灵活性使其成为一种理想的轻量级深度学习模型,适用于各种资源受限的场景。
四、ShuffleNet 的优势总结
ShuffleNet 的设计哲学和轻量化设计使其具有以下优势:
- 高效性:通过 深度可分离卷积 和 通道混合技术,ShuffleNet 显著减少了参数数量和计算量,提高了模型的计算效率。
- 灵活性:通过 自适应平均池化 和动态调整通道数,ShuffleNet 能够适应不同尺寸的输入数据,具有很强的灵活性。
- 高性能:尽管参数数量和计算量减少,但 ShuffleNet 通过通道混合机制增强了通道间的信息流动,保持了较高的性能。
- 适用性:ShuffleNet 的轻量化设计使其能够在移动和嵌入式设备上高效运行,适用于各种资源受限的场景。
尽管 ShuffleNet 在轻量级深度学习模型中已经取得了显著的成果,但仍有进一步优化的空间。未来,随着技术的不断发展,ShuffleNet 可以在更多领域进行应用,如 自动驾驶、医疗影像分析 和 自然语言处理 等。



![oracl:多表查询>>表连接[内连接,外连接,交叉连接,自连接,自然连接,等值连接和不等值连接]](https://i-blog.csdnimg.cn/direct/9f8178958b3846c89be661ef7fc83c12.png)















