接口功能
通用
支持一对一数据结构导出
支持一对多数据结构导出
支持多层嵌套数据结构导出
支持单元格自动合并
原文来自:https://blog.csdn.net/qq_40980205/article/details/136564176
新增及修复
基于我自己的使用场景,新增并能修复一下功能:
- 修复了只有单条一对一数据无法导出问题;
- 修复了多层嵌套数据结构中存在某个嵌套集合为空无法导出问题;
- 修复了只有一条一对多数据导出时报错问题;
完整源码解析
- @MyExcelProperty 作用到导出字段上面,表示这是Excel的一列
- @MyExcelCollection 表示一个集合,主要针对一对多的导出,比如一个老师对应多个科目,科目就可以用集合表示
- @MyExcelEntity 表示一个还存在嵌套关系的导出实体
property为基本数据类型的注解类
package com.example.excel.annotation;
import java.lang.annotation.*;
@Inherited
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelProperty {
String name() default "";
int index() default Integer.MAX_VALUE;
}
property为集合的注解类
package com.example.excel.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelCollection {
String name();
}
property为实体对象的注解类
package com.example.excel.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface MyExcelEntity {
String name() default "";
}
导出参数类
package com.example.excel.excel;
import lombok.Data;
import lombok.experimental.Accessors;
@Data
@Accessors(chain = true)
public class ExportParam {
private String fieldName;
private String columnName;
private Integer order;
}
导出实体类
package com.example.excel.excel;
import lombok.Data;
import java.util.List;
import java.util.Map;
@Data
public class ExportEntity {
/**
* 导出参数
*/
private List<ExportParam> exportParams;
/**
* 平铺后的数据
*/
private List<Map<String,Object>> data;
/**
* 每列的合并行数组
*/
private Map<String, List<Integer[]>> mergeRowMap;
}
导出工具类
package com.example.excel.excel;
import com.alibaba.excel.EasyExcel;
import com.example.excel.annotation.MyExcelCollection;
import com.example.excel.annotation.MyExcelEntity;
import com.example.excel.annotation.MyExcelProperty;
import com.google.common.base.Preconditions;
import com.google.common.collect.Lists;
import jakarta.servlet.http.HttpServletResponse;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import java.io.IOException;
import java.lang.reflect.Field;
import java.lang.reflect.ParameterizedType;
import java.net.URLEncoder;
import java.util.*;
import java.util.stream.Collectors;
public class MyExcelUtil {
private final String DELIMITER = ".";
/**
* @param sourceData 导出数据源
* @param fileName 导出文件名
* @param response
*/
public void exportData(Collection<Object> sourceData, String sheetName, HttpServletResponse response) {
if (CollectionUtils.isEmpty(sourceData)) return;
ExportEntity exportEntity = flattenObject(sourceData);
List<String> columnList = exportEntity.getExportParams().stream()
.sorted(Comparator.comparing(ExportParam::getOrder))
.map(ExportParam::getFieldName)
.collect(Collectors.toList());
List<List<Object>> exportDataList = new ArrayList<>();
//导出数据集
for (Map<String, Object> objectMap : exportEntity.getData()) {
List<Object> data = new ArrayList<>();
columnList.stream().forEach(columnName -> {
data.add(objectMap.get(columnName));
});
exportDataList.add(data);
}
List<List<String>> headList = columnList.stream().map(Lists::newArrayList).collect(Collectors.toList());
try {
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
EasyExcel.write(response.getOutputStream()).sheet(sheetName)
.head(headList)
.registerWriteHandler(new MergeStrategy(exportEntity))
.registerWriteHandler(new HeadHandler(exportEntity))
.doWrite(exportDataList);
} catch (IOException e) {
e.printStackTrace();
}
}
public ExportEntity flattenObject(Collection<Object> sourceData) {
Map<String, List<Integer[]>> mergeMap = new HashMap<>();
Class aClass = sourceData.stream().findFirst().get().getClass();
List<ExportParam> exportParams = getAllExportField(aClass, "");
Preconditions.checkArgument(!exportParams.isEmpty(), "export field not found !");
List<Map<String, Object>> target = new ArrayList<>();
Integer startRow = 0;
for (Object sourceDataLine : sourceData) {
List<Map<String, Object>> flatData = flattenObject(sourceDataLine, "", startRow, mergeMap);
startRow += flatData.size();
target.addAll(flatData);
}
ExportEntity exportEntity = new ExportEntity();
exportEntity.setExportParams(exportParams);
exportEntity.setData(target);
exportEntity.setMergeRowMap(mergeMap);
return exportEntity;
}
/**
* @param data 数据行
* @param preNode 上一层级字段名
* @param startRow 当前数据行所在行数
* @param mergeMap 各字段合并行数组
* @return
*/
private List<Map<String, Object>> flattenObject(Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {
List<Map<String, Object>> flatList = new ArrayList<>();
if (null == data) return flatList;
Class<?> aClass = data.getClass();
//获取不为null的excel导出字段
List<Field> collectionFields = new ArrayList<>();
List<Field> entityFields = new ArrayList<>();
List<Field> propertyFields = new ArrayList<>();
for (Field field : aClass.getDeclaredFields()) {
Object value = getFieldValue(field, data);
if (null == value) continue;
if (isCollection(field)) {
collectionFields.add(field);
} else if (isEntity(field)) {
entityFields.add(field);
} else if (isProperty(field)) {
propertyFields.add(field);
}
}
List<Map<String, Object>> entityFlatData = flattenEntityFields(entityFields, data, preNode, startRow, mergeMap);
List<List<Map<String, Object>>> collectionFlatData = flattenCollectionFields(collectionFields, data, preNode, startRow, mergeMap);
Map<String, Object> objectMap = Collections.emptyMap();
if (collectionFields.isEmpty() && entityFields.isEmpty()) {
objectMap = flattenPropertyFields(propertyFields, data, preNode);
}
if (collectionFlatData.isEmpty() && entityFlatData.isEmpty()) {
objectMap = flattenPropertyFields(propertyFields, data, preNode);
}
if (!objectMap.isEmpty()) {
flatList.add(objectMap);
}
//当前层级所有平铺列表
List<List<Map<String, Object>>> allFlatData = Lists.newArrayList();
if (!entityFlatData.isEmpty()) {
allFlatData.add(entityFlatData);
}
if (!collectionFlatData.isEmpty()) {
allFlatData.addAll(collectionFlatData);
}
List<Map<String, Object>> mergeList = mergeList(data, allFlatData, propertyFields, preNode, startRow, mergeMap);
if (!mergeList.isEmpty()) {
flatList.addAll(mergeList);
}
return flatList;
}
/**
* @param preNode 上一层级字段名
* @param fieldName 当前字段名
* @return
*/
private String buildPreNode(String preNode, String fieldName) {
StringBuffer sb = new StringBuffer();
return StringUtils.isEmpty(preNode) ? fieldName : sb.append(preNode).append(DELIMITER).append(fieldName).toString();
}
/**
* @param mergeFields 需要合并的字段
* @param preNode 上一层级字段名
* @param mergeStartRow 合并开始行
* @param mergeEndRow 合并结束行
* @param mergeMap 各字段合并行数组
*/
private void buildMerge(List<Field> mergeFields, String preNode, Integer mergeStartRow, Integer mergeEndRow, Map<String, List<Integer[]>> mergeMap) {
for (int k = 0; k < mergeFields.size(); k++) {
String fieldName = buildPreNode(preNode, mergeFields.get(k).getName());
List<Integer[]> list = mergeMap.get(fieldName);
if (null == list) {
mergeMap.put(fieldName, new ArrayList<>());
}
Integer[] rowInterval = new Integer[2];
//合并开始行
rowInterval[0] = mergeStartRow;
//合并结束行
rowInterval[1] = mergeEndRow;
mergeMap.get(fieldName).add(rowInterval);
}
}
private List<Map<String, Object>> flattenEntityFields(List<Field> entityFields, Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {
List<Map<String, Object>> entityFlatData = Lists.newArrayList();
for (Field entityField : entityFields) {
entityFlatData = flattenObject(getFieldValue(entityField, data), buildPreNode(preNode, entityField.getName()), startRow, mergeMap);
}
return entityFlatData;
}
private List<List<Map<String, Object>>> flattenCollectionFields(List<Field> collectionFields, Object data, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {
List<List<Map<String, Object>>> collectionFlatData = Lists.newArrayList();
for (Field collectionField : collectionFields) {
Collection collectionValue = (Collection) getFieldValue(collectionField, data);
//当前集合字段平铺而成的数据列表
List<Map<String, Object>> collectionObjectValue = new ArrayList<>();
//间隔行数
Integer row = 0;
for (Object value : collectionValue) {
List<Map<String, Object>> flatData = flattenObject(value, buildPreNode(preNode, collectionField.getName()), startRow + row, mergeMap);
if (!flatData.isEmpty()) {
collectionObjectValue.addAll(flatData);
//下条数据的起始间隔行
row += flatData.size();
}
}
if (!collectionObjectValue.isEmpty()) {
collectionFlatData.add(collectionObjectValue);
}
}
return collectionFlatData;
}
private Map<String, Object> flattenPropertyFields(List<Field> propertyFields, Object data, String preNode) {
Map<String, Object> flatMap = new HashMap<>();
for (Field field : propertyFields) {
flatMap.put(buildPreNode(preNode, field.getName()), getFieldValue(field, data));
}
return flatMap;
}
private List<Map<String, Object>> mergeList(Object data, List<List<Map<String, Object>>> allFlatData, List<Field> propertyFields, String preNode, Integer startRow, Map<String, List<Integer[]>> mergeMap) {
List<Map<String, Object>> flatList = new ArrayList<>();
//当前层级下多个集合字段的最大长度即为当前层级其他字段的合并行数
Integer maxSize = 0;
for (List<Map<String, Object>> list : allFlatData) {
maxSize = Math.max(maxSize, list.size());
}
//记录集合同层级其他字段的合并行数
if (maxSize > 0) {
buildMerge(propertyFields, preNode, startRow, startRow + maxSize, mergeMap);
}
//需要合并
if (maxSize > 1) {
//重新构建平铺的list
List<Map<String, Object>> mergeFlatData = new ArrayList<>(maxSize);
for (int i = 0; i < maxSize; i++) {
mergeFlatData.add(new HashMap<>());
}
for (List<Map<String, Object>> flatData : allFlatData) {
for (int i = 0; i < flatData.size(); i++) {
Map<String, Object> flatMap = new HashMap<>();
flatMap.putAll(flatData.get(i));
//添加同层级字段值
if (CollectionUtils.isNotEmpty(propertyFields)) {
for (Field field : propertyFields) {
flatMap.put(buildPreNode(preNode, field.getName()), getFieldValue(field, data));
}
}
mergeFlatData.get(i).putAll(flatMap);
}
}
flatList.addAll(mergeFlatData);
} else {
for (List<Map<String, Object>> list : allFlatData) {
flatList.addAll(list);
}
}
return flatList;
}
/**
* @param clazz 导出类
* @param preNode 上一层级字段名
* @return
*/
private List<ExportParam> getAllExportField(Class<?> clazz, String preNode) {
List<ExportParam> exportFields = new ArrayList<>();
for (Field declaredField : clazz.getDeclaredFields()) {
MyExcelProperty myExcelProperty = declaredField.getDeclaredAnnotation(MyExcelProperty.class);
MyExcelEntity myExcelEntity = declaredField.getDeclaredAnnotation(MyExcelEntity.class);
MyExcelCollection myExcelCollection = declaredField.getDeclaredAnnotation(MyExcelCollection.class);
String fieldName = buildPreNode(preNode, declaredField.getName());
if (null != myExcelProperty) {
ExportParam exportParam = new ExportParam()
.setFieldName(fieldName)
.setColumnName(myExcelProperty.name())
.setOrder(myExcelProperty.index());
exportFields.add(exportParam);
} else if (null != myExcelEntity) {
exportFields.addAll(getAllExportField(declaredField.getType(), fieldName));
} else if (null != myExcelCollection) {
boolean isCollection = Collection.class.isAssignableFrom(declaredField.getType());
if (!isCollection) continue;
ParameterizedType pt = (ParameterizedType) declaredField.getGenericType();
Class<?> clz = (Class<?>) pt.getActualTypeArguments()[0];
exportFields.addAll(getAllExportField(clz, fieldName));
}
}
return exportFields;
}
private boolean isProperty(Field field) {
return null != field.getDeclaredAnnotation(MyExcelProperty.class) ? true : false;
}
private boolean isEntity(Field field) {
return null != field.getDeclaredAnnotation(MyExcelEntity.class) ? true : false;
}
private boolean isCollection(Field field) {
boolean isCollection = Collection.class.isAssignableFrom(field.getType());
return isCollection && null != field.getAnnotation(MyExcelCollection.class) ? true : false;
}
private Object getFieldValue(Field field, Object sourceObject) {
Object fieldValue;
try {
field.setAccessible(true);
fieldValue = field.get(sourceObject);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
return fieldValue;
}
}
单元格合并策略
```java
package com.example.excel.excel;
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.write.merge.AbstractMergeStrategy;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.util.CellRangeAddress;
import org.springframework.util.CollectionUtils;
import java.util.List;
public class MergeStrategy extends AbstractMergeStrategy {
private ExportEntity exportEntity;
public MergeStrategy(ExportEntity exportEntity) {
this.exportEntity = exportEntity;
}
@Override
protected void merge(Sheet sheet, Cell cell, Head head, Integer relativeRowIndex) {
//mergeMap需要加上head的行数
String fieldName = head.getHeadNameList().get(0);
List<Integer[]> mergeRow = exportEntity.getMergeRowMap().get(fieldName);
if (CollectionUtils.isEmpty(mergeRow)) return;
int currentColumnIndex = cell.getColumnIndex();
int currentRowIndex = cell.getRowIndex();
//表头所占行数
int headHeight = head.getHeadNameList().size();
for (int i = 0; i < mergeRow.size(); i++) {
if (currentRowIndex == mergeRow.get(i)[1] + headHeight - 1) {
sheet.addMergedRegion(new CellRangeAddress(mergeRow.get(i)[0] + headHeight, mergeRow.get(i)[1] + headHeight - 1,
currentColumnIndex, currentColumnIndex));
}
}
}
}
表头导出处理
```java
package com.example.excel.excel;
import com.alibaba.excel.metadata.Head;
import com.alibaba.excel.metadata.data.WriteCellData;
import com.alibaba.excel.write.handler.CellWriteHandler;
import com.alibaba.excel.write.metadata.holder.WriteSheetHolder;
import com.alibaba.excel.write.metadata.holder.WriteTableHolder;
import org.apache.poi.ss.usermodel.Cell;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class HeadHandler implements CellWriteHandler {
private ExportEntity exportEntity;
public HeadHandler(ExportEntity exportEntity) {
this.exportEntity = exportEntity;
}
@Override
public void afterCellDispose(WriteSheetHolder writeSheetHolder, WriteTableHolder writeTableHolder,
List<WriteCellData<?>> cellDataList, Cell cell, Head head, Integer relativeRowIndex, Boolean isHead) {
if (!isHead) return;
List<String> headNameList = head.getHeadNameList();
Map<String, String> collect = exportEntity.getExportParams().stream().collect(Collectors.toMap(ExportParam::getFieldName, ExportParam::getColumnName));
cell.setCellValue(collect.get(headNameList.get(0)));
}
}
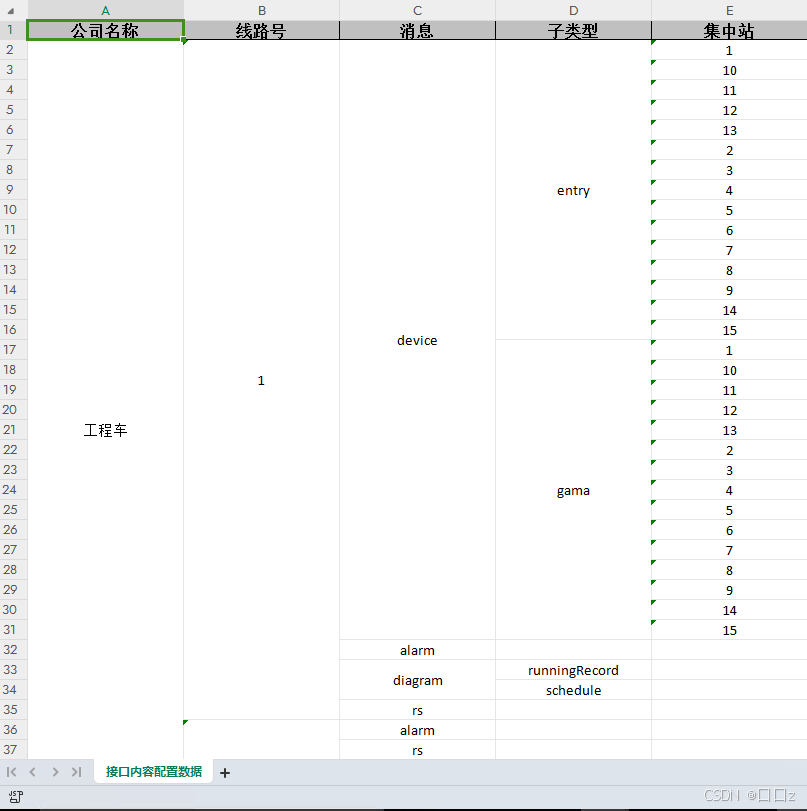
导出示例
被导出实体
public class CompanyConfigEnntity{
@MyExcelProperty(name = "公司名称")
private String companyName;
@MyExcelCollection(name = "线路配置")
private List<LineConfigEntity> lineConfigs;
}
public class LineConfigEntity{
@MyExcelProperty(name = "线路号")
private String lineNumber;
@MyExcelCollection(name = "消息配置")
private List<MsgConfigEntity> msgConfigs;
}
public class MsgConfigEntity{
@MyExcelProperty(name = "消息类型")
private String msgType;
@MyExcelCollection(name = "子类型配置")
private List<SubTypeConfigEntity> subTypeConfigs;
}
public class SubTypeConfigEntity{
@MyExcelProperty(name = "子类型")
private String subType;
@MyExcelCollection(name = "集中站配置")
private List<RtuConfigEntity> rtuConfigs;
}
public class RtuConfigEntity{
@MyExcelProperty(name = "集中站号")
private String rtuNumber;
}接口调用
@RestController
@ReqeutMapping("/companyConfig/companyConfig")
public class CompanyConfigController{
@AutoWired
private CompanyConfigService companyConfigService;
@PostMappinng("/export")
public void expooort(HttpServletResponse response){
List<CompanyConfigEnityt> list = companyConfigService.queryAll();
new MyExcelUtil().exportData(list, "公司配置内容数据", resposne);
}
}效果展示