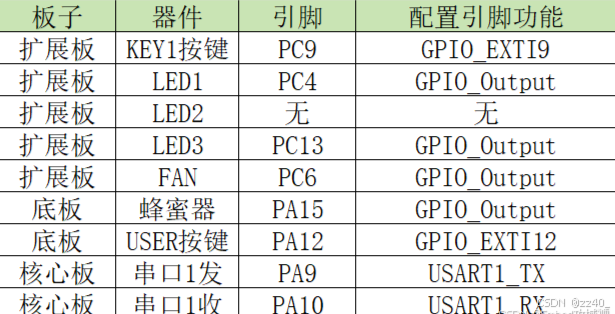
分类错误率
最小错误率贝叶斯决策
样本
x
x
x的错误率: 任一决策都可能会有错误。
P
(
error
∣
x
)
=
{
P
(
w
2
∣
x
)
,
if we decide
x
as
w
1
P
(
w
1
∣
x
)
,
if we decide
x
as
w
2
P(\text{error}|\mathbf{x})=\begin{cases} P(w_2|\mathbf{x}), & \text{if we decide } \mathbf{x} \text{ as } w_1\\ P(w_1|\mathbf{x}), & \text{if we decide } \mathbf{x} \text{ as } w_2 \end{cases}
P(error∣x)={P(w2∣x),P(w1∣x),if we decide x as w1if we decide x as w2
P
(
w
2
∣
x
)
P(w_2|x)
P(w2∣x)即:当我们将样本
x
x
x判定为第一类
w
1
w_1
w1时,这个判定失误的概率为
P
(
w
2
∣
x
)
P(w_2|x)
P(w2∣x);(因为样本以该概率属于第二类)
样本
x
x
x的最小错误率:
P
(
error
∣
x
)
=
min
(
P
(
ω
1
∣
x
)
,
P
(
ω
2
∣
x
)
)
P(\text{error}|\mathbf{x})=\min(P(\omega_1|\mathbf{x}),P(\omega_2|\mathbf{x}))
P(error∣x)=min(P(ω1∣x),P(ω2∣x))
贝叶斯决策的错误率:贝叶斯决策的错误率定义为所有服从独立同分布的样本上的错误率的期望:
P
(
error
)
=
∫
P
(
error
∣
x
)
p
(
x
)
d
x
P(\text{error})=\int P(\text{error}|\mathbf{x})p(\mathbf{x})dx
P(error)=∫P(error∣x)p(x)dx
例:错误率(1D)
关于错误率,以一维为例说明: 考虑一个有关一维样本的两类分类问题。假设决策边界 t t t将 x x x轴分成两个区域 R 1 R_1 R1和 R 2 R_2 R2。 R 1 R_1 R1为 ( − ∞ , t ) (-\infty,t) (−∞,t), R 2 R_2 R2为 ( t , ∞ ) (t,\infty) (t,∞)。

错误情形:样本在 R 1 R_1 R1中,但属于第二类的概率是存在的,即 P ( w 2 ∣ x ) P(w_2|\mathbf{x}) P(w2∣x);样本在 R 2 R_2 R2中,但属于第一类的概率也是存在的,即 P ( w 1 ∣ x ) P(w_1|\mathbf{x}) P(w1∣x);这两种情形就是决策一个给定样本 x x x可能出现错误的概率。
考虑样本自身的分布后的平均错误率计算如下:
P
(
error
)
=
∫
−
∞
t
P
(
w
2
∣
x
)
p
(
x
)
d
x
+
∫
t
∞
P
(
w
1
∣
x
)
p
(
x
)
d
x
=
∫
−
∞
t
P
(
x
∣
w
2
)
P
(
w
2
)
d
x
+
∫
t
∞
=
P
(
x
∈
R
1
,
w
2
)
+
P
(
x
∈
R
2
,
w
1
)
\begin{align}P(\text{error})&=\int_{-\infty}^{t}P(w_2|\mathbf{x})p(\mathbf{x})d\mathbf{x}+\int_{t}^{\infty}P(w_1|x)p(\mathbf{x})d\mathbf{x}\\ &=\int_{-\infty}^{t}P(\mathbf{x}|w_2)P(w_2)d\mathbf{x}+\int_{t}^{\infty}\\ &= P(\mathbf{x}\in R_1,w_2)+P(\mathbf{x}\in R_2,w_1) \end{align}
P(error)=∫−∞tP(w2∣x)p(x)dx+∫t∞P(w1∣x)p(x)dx=∫−∞tP(x∣w2)P(w2)dx+∫t∞=P(x∈R1,w2)+P(x∈R2,w1)
两类情形
平均错分概率:
P
(
error
)
=
P
(
x
∈
R
2
,
w
1
)
+
P
(
x
∈
R
1
,
w
2
)
=
∫
R
2
p
(
x
∣
w
1
)
P
(
w
1
)
d
x
+
∫
R
1
p
(
x
∣
w
2
)
P
(
w
2
)
d
x
=
P
(
x
∈
R
2
∣
w
1
)
P
(
w
1
)
+
P
(
x
∈
R
1
∣
w
2
)
P
(
w
2
)
P(\text{error})=P(\mathbf{x}\in R_2,w_1)+P(\mathbf{x}\in R_1,w_2)\\ =\int_{R_2}p(\mathbf{x}|w_1)P(w_1)d\mathbf{x}+\int_{R_1}p(\mathbf{x}|w_2)P(w_2)d\mathbf{x}\\ =P(\mathbf{x}\in R_2|w_1)P(w_1)+P(\mathbf{x}\in R_1|w_2)P(w_2)
P(error)=P(x∈R2,w1)+P(x∈R1,w2)=∫R2p(x∣w1)P(w1)dx+∫R1p(x∣w2)P(w2)dx=P(x∈R2∣w1)P(w1)+P(x∈R1∣w2)P(w2)
例子
平均错分概率:
P
(
error
)
=
∫
R
2
p
(
x
∣
w
1
)
P
(
w
1
)
d
x
+
∫
R
1
p
(
x
∣
w
2
)
P
(
w
2
)
d
x
P(\text{error})=\int_{R_2}p(\mathbf{x}|w_1)P(w_1)d\mathbf{x}+\int_{R_1}p(\mathbf{x}|w_2)P(w_2)d\mathbf{x}
P(error)=∫R2p(x∣w1)P(w1)dx+∫R1p(x∣w2)P(w2)dx

多类情形
平均错分概率:
P
(
error
)
=
∑
i
=
1
c
∑
j
≠
i
P
(
x
∈
R
j
,
w
i
)
P(\text{error})=\sum_{i = 1}^{c}\sum_{j\neq i}P(x\in R_j,w_i)
P(error)=i=1∑cj=i∑P(x∈Rj,wi)
平均分类精度:
P
(
correct
)
=
∑
i
=
1
c
P
(
x
∈
R
i
,
w
i
)
=
∑
i
=
1
c
P
(
x
∈
R
i
∣
w
i
)
P
(
w
i
)
=
∫
R
i
p
(
x
∣
w
i
)
P
(
w
i
)
d
x
\begin{align} P(\text{correct})&=\sum_{i = 1}^{c}P(\mathbf{x}\in R_i,w_i)\\ & =\sum_{i = 1}^{c}P(\mathbf{x}\in R_i|w_i)P(w_i)\\ & =\int_{R_i}p(\mathbf{x}|w_i)P(w_i)d\mathbf{x} \end{align}
P(correct)=i=1∑cP(x∈Ri,wi)=i=1∑cP(x∈Ri∣wi)P(wi)=∫Rip(x∣wi)P(wi)dx
离散变量bayes决策
概率分布函数: P ( x ∣ w i ) = P ( x 1 , x 2 , … , x d ∣ w i ) P(\mathbf{x}|w_i)=P(\mathbf{x}_1,\mathbf{x}_2,\dots,\mathbf{x}_d|w_i) P(x∣wi)=P(x1,x2,…,xd∣wi)

独立二值特征 (Binary features)
特征独立假设(Naïve Bayes):
P ( x ∣ ω j ) = P ( x 1 , x 2 , … , x d ∣ ω j ) = ∏ j = 1 d P ( x j ∣ ω j ) P(\mathbf{x}|\omega_j)=P(x_1,x_2,\ldots,x_d|\omega_j)=\prod_{j = 1}^{d}P(x_j|\omega_j) P(x∣ωj)=P(x1,x2,…,xd∣ωj)=j=1∏dP(xj∣ωj)
每维特征服从伯努利分布(0/1分布)
| 在类别 w 1 w_1 w1 下,第 i i i 个特征 x i x_i xi 取值为 1 的概率 | 在类别 w 2 w_2 w2 下,第 i i i 个特征 x i x_i xi 取值为 1 的概率 |
|---|---|
| $p_i = P(X_{i}=1 | w_1),\quad i = 1,\ldots,d$ |
| $P(\mathbf{x} | w_1)=\prod_{i = 1}{d}p_i{x_i}(1 - p_i)^{1 - x_i}$ |
似然比:
P
(
x
∣
ω
1
)
P
(
x
∣
ω
2
)
=
∏
i
=
1
d
(
p
i
q
i
)
x
i
(
1
−
p
i
1
−
q
i
)
1
−
x
i
\frac{P(\mathbf{x}|\omega_1)}{P(\mathbf{x}|\omega_2)}=\prod_{i = 1}^{d}\left(\frac{p_i}{q_i}\right)^{x_i}\left(\frac{1 - p_i}{1 - q_i}\right)^{1 - x_i}
P(x∣ω2)P(x∣ω1)=i=1∏d(qipi)xi(1−qi1−pi)1−xi
判别函数(QDF):
g
(
x
)
=
g
1
(
x
)
−
g
2
(
x
)
=
ln
P
(
x
∣
w
1
)
P
(
w
1
)
−
ln
P
(
x
∣
w
2
)
P
(
w
2
)
=
∑
i
=
1
d
[
x
i
ln
p
i
q
i
+
(
1
−
x
i
)
ln
1
−
p
i
1
−
q
i
]
+
ln
P
(
w
1
)
P
(
w
2
)
=
∑
i
=
1
d
ln
p
i
q
i
1
−
q
i
1
−
p
i
x
i
+
∑
i
=
1
d
ln
1
−
p
i
1
−
q
i
+
ln
P
(
w
1
)
P
(
w
2
)
=
∑
i
=
1
d
w
i
x
i
+
w
0
{
w
i
=
ln
p
i
(
1
−
q
i
)
q
i
(
1
−
p
i
)
,
i
=
1
,
…
,
d
w
0
=
∑
i
=
1
d
ln
1
−
p
i
1
−
q
i
+
ln
P
(
w
1
)
P
(
w
2
)
\begin{align} g(\mathbf{x}) &= g_1(\mathbf{x})-g_2(\mathbf{x})=\ln P(\mathbf{x}|w_1)P(w_1)-\ln P(\mathbf{x}|w_2)P(w_2)\\ &=\sum_{i = 1}^{d}\left[x_i\ln\frac{p_i}{q_i}+(1 - x_i)\ln\frac{1 - p_i}{1 - q_i}\right]+\ln\frac{P(w_1)}{P(w_2)}\\ &=\sum^d_{i=1}\ln\frac{p_i}{q_i}\frac{1-q_i}{1-p_i}\mathbf x_i+\sum^d_{i=1}\ln\frac{1-p_i}{1-q_i}+\ln\frac{P(w_1)}{P(w_2)}\\ &=\sum_{i = 1}^{d}w_i x_i+w_0\\ &\begin{cases} w_i&=\ln\frac{p_i(1 - q_i)}{q_i(1 - p_i)},\quad i = 1,\ldots,d\\ w_0&=\sum_{i = 1}^{d}\ln\frac{1 - p_i}{1 - q_i}+\ln\frac{P(w_1)}{P(w_2)} \end{cases} \end{align}
g(x)=g1(x)−g2(x)=lnP(x∣w1)P(w1)−lnP(x∣w2)P(w2)=i=1∑d[xilnqipi+(1−xi)ln1−qi1−pi]+lnP(w2)P(w1)=i=1∑dlnqipi1−pi1−qixi+i=1∑dln1−qi1−pi+lnP(w2)P(w1)=i=1∑dwixi+w0{wiw0=lnqi(1−pi)pi(1−qi),i=1,…,d=∑i=1dln1−qi1−pi+lnP(w2)P(w1)
例子 × 1 \times 1 ×1
例子是基于朴素贝叶斯分类器的二分类问题,并利用独立二值特征(Binary Features)推导出分类的决策边界 g ( x ) = 0 g(x)=0 g(x)=0 的过程。
已知:
P
(
ω
1
)
=
0.5
,
P
(
ω
2
)
=
0.5
p
i
=
0.8
,
q
i
=
0.5
,
i
=
1
,
2
,
3
P(\omega_1)=0.5, P(\omega_2)=0.5\\ p_i = 0.8, q_i = 0.5,\quad i = 1,2,3
P(ω1)=0.5,P(ω2)=0.5pi=0.8,qi=0.5,i=1,2,3
P ( x ∣ ω 1 ) = ∏ i = 1 3 p i x i ( 1 − p i ) 1 − x i P ( x ∣ ω 2 ) = ∏ i = 1 3 q i x i ( 1 − q i ) 1 − x i g ( x ) = ∑ i = 1 3 w i x i + w 0 w i = ln 0.8 ( 1 − 0.5 ) 0.5 ( 1 − 0.8 ) = ln 4 = 1.3863 w 0 = ∑ i = 1 3 ln 1 − 0.8 1 − 0.5 + ln 0.5 0.5 = 3 ln 2 5 = − 2.7489 P(\mathbf{x}|\omega_1)=\prod_{i = 1}^{3}p_i^{x_i}(1 - p_i)^{1 - x_i}\\ P(\mathbf{x}|\omega_2)=\prod_{i = 1}^{3}q_i^{x_i}(1 - q_i)^{1 - x_i}\\ g(\mathbf{x})=\sum_{i = 1}^{3}w_i x_i+w_0\\ w_i=\ln\frac{0.8(1 -0.5)}{0.5(1 -0.8)} =\ln4= 1.3863\\ w_0=\sum_{i = 1}^{3}\ln\frac{1 -0.8}{1 -0.5}+\ln\frac{0.5}{0.5}=3\ln\frac{2}{5}=- 2.7489 P(x∣ω1)=i=1∏3pixi(1−pi)1−xiP(x∣ω2)=i=1∏3qixi(1−qi)1−xig(x)=i=1∑3wixi+w0wi=ln0.5(1−0.8)0.8(1−0.5)=ln4=1.3863w0=i=1∑3ln1−0.51−0.8+ln0.50.5=3ln52=−2.7489

例子 × 2 \times 2 ×2
3D binary data -
P
(
w
1
)
=
0.5
,
P
(
w
2
)
=
0.5
P(w_1)=0.5, P(w_2)=0.5
P(w1)=0.5,P(w2)=0.5 -
p
1
=
p
2
=
0.8
,
p
3
=
0.5
;
q
i
=
0.5
,
i
=
1
,
2
,
3
w
i
=
ln
0.8
(
1
−
0.5
)
0.5
(
1
−
0.8
)
=
ln
4
=
1.3863
,
i
=
1
,
2
w
3
=
0
,
i
=
3
w
0
=
2
ln
1
−
0.8
1
−
0.5
=
−
1.8326
p_1 = p_2 = 0.8, p_3 = 0.5; q_i = 0.5,\quad i = 1,2,3\\ w_i=\ln\frac{0.8(1 -0.5)}{0.5(1 -0.8)} =\ln4= 1.3863,\ i=1,2\\ w_3 = 0,\ i=3\\w_0 = 2\ln\frac{1 -0.8}{1 -0.5}=- 1.8326
p1=p2=0.8,p3=0.5;qi=0.5,i=1,2,3wi=ln0.5(1−0.8)0.8(1−0.5)=ln4=1.3863, i=1,2w3=0, i=3w0=2ln1−0.51−0.8=−1.8326

复合模式分类(Compound Bayesian Decision Theory and Context)
多个样本同时分类 X = [ x 1 , x 2 , … , x n ] w = w ( 1 ) w ( 2 ) ⋯ w ( n ) \mathbf{X}=[x_1,x_2,\ldots,x_n]\quad w=w(1)w(2)\cdots w(n) X=[x1,x2,…,xn]w=w(1)w(2)⋯w(n)
比如:字符串识别
贝叶斯决策:
P
(
w
∣
X
)
=
p
(
X
∣
w
)
P
(
w
)
p
(
X
)
=
P
(
X
∣
w
)
P
(
w
)
∑
w
′
P
(
X
∣
w
′
)
P
(
w
′
)
P(w|\mathbf{X})=\frac{p(\mathbf{X}|w)P(w)}{p(\mathbf{X})} = \frac{P(\mathbf{X} | w) P(w)}{\sum_{w'} P(\mathbf{X} | w') P(w')}
P(w∣X)=p(X)p(X∣w)P(w)=∑w′P(X∣w′)P(w′)P(X∣w)P(w)
其中:
- P ( w ∣ X ) P(w | \mathbf{X}) P(w∣X) 是后验概率,即给定样本序列 X \mathbf{X} X,其属于类别 w w w 的概率。
- P ( X ∣ w ) P(\mathbf{X} | w) P(X∣w) 是类别 w w w 下样本序列 X \mathbf{X} X 的条件概率(似然)。
- P ( w ) P(w) P(w) 是类别$w $的先验概率。
- $P(\mathbf{X}) $是归一化项,用于保证所有类别的后验概率之和为 1。
注意: w w w类别数巨大 ( c n ) (c^n) (cn), p ( X ∣ w ) p(\mathbf{X}|w) p(X∣w)存储和估计困难.
选择后验概率最大的类别:
w
∗
=
arg
max
w
P
(
w
∣
X
)
w^* = \arg\max_{w} P(w | \mathbf{X})
w∗=argwmaxP(w∣X)
条件独立:在已知类别条件下,样本之间相互独立,即:
P
(
X
∣
w
)
=
∏
i
=
1
n
P
(
x
i
∣
w
)
P(\mathbf{X} | w) = \prod_{i=1}^n P(x_i | w)
P(X∣w)=i=1∏nP(xi∣w)
这种假设极大地简化了
P
(
X
∣
w
)
P(\mathbf{X} | w)
P(X∣w) 的计算,但可能会损失精度,因为在实际问题中,序列中的样本通常是相关的(例如时间序列或字符序列)。
先验假设(Prior assumption)
-
马尔可夫链(Markov chain)
- 先验概率可以表示为:
P ( w ) = P [ w ( 1 ) , w ( 2 ) , … , w ( n ) ] = P [ w ( 1 ) ] ∏ j = 2 n P [ w ( j ) ∣ w ( j − 1 ) ] P(w)=P[w(1),w(2),\ldots,w(n)]=P[w(1)]\prod_{j = 2}^{n}P[w(j)|w(j - 1)] P(w)=P[w(1),w(2),…,w(n)]=P[w(1)]j=2∏nP[w(j)∣w(j−1)]
- 先验概率可以表示为:
-
隐马尔可夫模型(Hidden Markov model,第 3 章介绍)
P ( X , w ) = P ( w ( 1 ) ) ∏ j = 2 n P ( w ( j ) ∣ w ( j − 1 ) ) ∏ i = 1 n P ( x i ∣ w ( i ) ) P(\mathbf{X}, w) = P(w(1)) \prod_{j=2}^n P(w(j) | w(j-1)) \prod_{i=1}^n P(x_i | w(i)) P(X,w)=P(w(1))j=2∏nP(w(j)∣w(j−1))i=1∏nP(xi∣w(i))
与复合模式识别类似的问题:多分类器融合
有同一个分类问题的 K K K个分类器,对于样本 x x x,怎样使用 K K K个分类结果得到最终分类结果?
一个分类器的输出:离散变量 e k ∈ { w 1 , … , w c } e_k\in\{w_1,\dots,w_c\} ek∈{w1,…,wc}
多个分类器的决策当作样本 x x x的多维特征,用Bayes方法重新分类:
P ( w i ∣ e 1 , … , e K ) = P ( e 1 , … , e K ∣ w i ) P ( w i ) P ( e 1 , … , e K ) , i = 1 , … , c P(w_i|e_1,\ldots,e_K)=\frac{P(e_1,\ldots,e_K|w_i)P(w_i)}{P(e_1,\ldots,e_K)},\quad i = 1,\ldots,c P(wi∣e1,…,eK)=P(e1,…,eK)P(e1,…,eK∣wi)P(wi),i=1,…,c
需要估计离散空间的类条件概率 :指数级复杂度,需要大量样本
P ( e 1 , … , e K ∣ w i ) P(e_1,\ldots,e_K|w_i) P(e1,…,eK∣wi)
特征独立假设(Naïve Bayes)
P ( e 1 , … , e K ∣ w i ) = ∏ k = 1 K P ( e k ∣ w i ) P(e_1,\ldots,e_K|w_i)=\prod_{k = 1}^{K}P(e_k|w_i) P(e1,…,eK∣wi)=k=1∏KP(ek∣wi)
总结
在已知类条件概率密度 p ( x ∣ w j ) p(\mathbf{x}|w_j) p(x∣wj)和类先验分布 P ( w j ) P(w_j) P(wj)的情况下,如何基于贝叶斯决策理论对样本 x \mathbf{x} x分类的问题
- 单模式分类:连续特征、离散特征
- 复合模式分类
- 多分类器融合
贝叶斯分类器(基于贝叶斯决策的分类器)是最优的吗?
- 贝叶斯分类器是基于贝叶斯决策理论的分类器,其目标是最小化分类的总体风险(即误分类风险)。
- 最小风险:通过最小化条件风险(如 0-1 损失),选择最优分类。
- 最大后验概率决策 :在每个样本点 x \mathbf{x} x,选择后验概率最大的类别。
- 最优的条件:概率密度 p ( x ∣ w i ) p(\mathbf{x}|w_i) p(x∣wi)和先验概率 P ( w i ) P(w_i) P(wi)、风险能准确估计
- 具体的参数法(如正态分布假设)、非参数法(如 Parzen 窗、核密度估计)是贝叶斯分类器的近似,实际中难以达到最优。
- 判别模型(如逻辑回归、支持向量机 SVM):回避了概率密度估计,以较小复杂度估计后验概率 P ( w i ∣ x ) P(w_i|\mathbf{x}) P(wi∣x)或判别函数 g ( x ) g(\mathbf{x}) g(x)。
- 什么方法能胜过贝叶斯分类器:在不同的特征空间才有可能。
Q1: 贝叶斯分类器(基于贝叶斯决策的分类器)是最优的吗?
- 理论上:是的,贝叶斯分类器在理论上是最优的分类器,因为它最小化了分类风险。
- 实际中:不一定,因为贝叶斯分类器依赖于概率密度函数的精确估计,而实际中往往难以精确估计这些密度函数,特别是当数据分布复杂或高维时。
Q2: 什么方法能胜过贝叶斯分类器?
- 判别模型,如逻辑回归、SVM、神经网络等,特别是在以下情况下可能胜过贝叶斯分类器:
- 数据的真实分布复杂,难以准确建模。
- 特征空间高维,生成模型对概率估计的难度更大。
- 数据量有限时,生成模型容易过拟合。
{x}$分类的问题
- 单模式分类:连续特征、离散特征
- 复合模式分类
- 多分类器融合
贝叶斯分类器(基于贝叶斯决策的分类器)是最优的吗?
- 贝叶斯分类器是基于贝叶斯决策理论的分类器,其目标是最小化分类的总体风险(即误分类风险)。
- 最小风险:通过最小化条件风险(如 0-1 损失),选择最优分类。
- 最大后验概率决策 :在每个样本点 x \mathbf{x} x,选择后验概率最大的类别。
- 最优的条件:概率密度 p ( x ∣ w i ) p(\mathbf{x}|w_i) p(x∣wi)和先验概率 P ( w i ) P(w_i) P(wi)、风险能准确估计
- 具体的参数法(如正态分布假设)、非参数法(如 Parzen 窗、核密度估计)是贝叶斯分类器的近似,实际中难以达到最优。
- 判别模型(如逻辑回归、支持向量机 SVM):回避了概率密度估计,以较小复杂度估计后验概率 P ( w i ∣ x ) P(w_i|\mathbf{x}) P(wi∣x)或判别函数 g ( x ) g(\mathbf{x}) g(x)。
- 什么方法能胜过贝叶斯分类器:在不同的特征空间才有可能。
Q1: 贝叶斯分类器(基于贝叶斯决策的分类器)是最优的吗?
- 理论上:是的,贝叶斯分类器在理论上是最优的分类器,因为它最小化了分类风险。
- 实际中:不一定,因为贝叶斯分类器依赖于概率密度函数的精确估计,而实际中往往难以精确估计这些密度函数,特别是当数据分布复杂或高维时。
Q2: 什么方法能胜过贝叶斯分类器?
- 判别模型,如逻辑回归、SVM、神经网络等,特别是在以下情况下可能胜过贝叶斯分类器:
- 数据的真实分布复杂,难以准确建模。
- 特征空间高维,生成模型对概率估计的难度更大。
- 数据量有限时,生成模型容易过拟合。