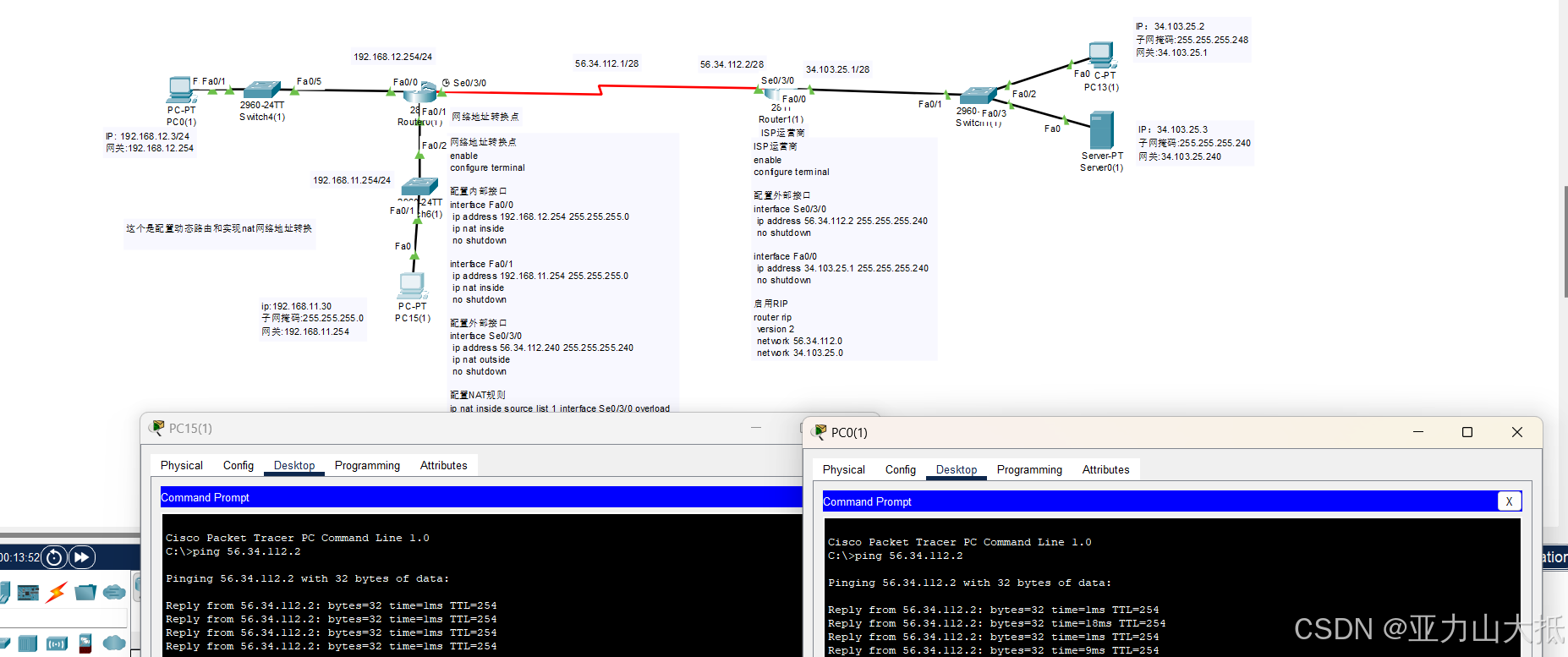
(一)高精度算法概述
高精度算法是指能够处理超出常规数据类型表示范围的数值的算法。在 C++ 中,标准数据类型通常有固定的位数和精度限制,而高精度算法可以解决大数运算、金融计算和科学计算等领域的问题。
(二)高精度算法的实现方法
- 使用第三方库,如 GMP、Boost.Multiprecision 等,提供扩展的数据类型和函数,能够处理任意大小的整数和高精度浮点数。
-
- 这些第三方库为 C++ 程序员提供了强大的工具,使得处理大数运算变得更加容易。例如,在金融领域中,可能需要对非常大的数值进行精确计算,以确保交易的准确性和安全性。使用这些库,可以轻松地处理超出常规数据类型范围的数值,提高程序的可靠性和稳定性。
-
- 同时,这些库通常具有良好的性能和优化,可以在处理大规模数据时保持高效的计算速度。程序员可以根据具体的需求选择合适的库,并利用其提供的功能来实现高精度算法。
- 自定义高精度数据结构,如链表表示的大整数,可以更深入地理解高精度算法的内部机制。
-
- 自定义高精度数据结构是另一种实现高精度算法的方法。通过使用链表等数据结构,可以灵活地表示大整数,并实现各种数学运算。例如,可以使用链表的节点来存储大整数的每一位数字,通过对链表的操作来进行加法、减法、乘法和除法等运算。
-
- 这种方法虽然实现复杂,但可以更深入地理解高精度算法的内部机制,对于学习和研究算法的原理非常有帮助。同时,自定义数据结构也可以根据具体的需求进行优化和调整,以提高算法的性能和效率。
(三)高精度算法的应用场景
- 加密货币:在比特币等加密货币的交易和挖矿过程中,高精度算法用于处理大数运算。
-
- 加密货币的交易和挖矿涉及到大量的数值计算,其中很多数值超出了常规数据类型的表示范围。高精度算法可以准确地处理这些大数运算,确保交易的安全性和准确性。例如,在比特币的挖矿过程中,需要进行复杂的哈希计算,这些计算通常涉及到非常大的数值。高精度算法可以有效地处理这些计算,提高挖矿的效率和成功率。
- 科学模拟:在物理和化学模拟中,高精度算法可以提供更精确的计算结果。
-
- 在科学模拟中,精度要求通常非常高,因为微小的误差可能会导致结果的巨大偏差。高精度算法可以提供更精确的计算结果,帮助科学家更好地理解和预测物理和化学现象。例如,在量子力学模拟中,需要对非常小的数值进行精确计算,高精度算法可以满足这种需求。
- 金融工程:在金融衍生品定价和风险管理中,高精度算法用于处理复杂的数学模型。
-
- 金融工程领域涉及到复杂的数学模型和大量的数值计算,高精度算法在其中发挥着重要作用。例如,在金融衍生品定价中,需要对各种风险因素进行精确评估,这通常涉及到非常复杂的数学模型和大量的数值计算。高精度算法可以提供更准确的计算结果,帮助金融机构更好地管理风险和制定投资策略。
二、高效排序算法

(一)希尔排序
希尔排序通过将原数组分为几个子数组,先分别将这几个子数组排序,再把排序好的子数组进行排序,可以大大提高效率,排序方法可使用任意简单排序,这里使用插入排序。
希尔排序,也称为 Shell 排序,是一种就地比较排序算法。它通过比较和交换相距较远的元素来对数组进行排序,从而推广了插入排序或冒泡排序等交换排序。此排序算法以其发明者 Donald Shell 命名,他在 1959 年首次发表了该算法。
希尔排序通过比较和交换相距较远的元素来减少无序度。最初,比较和交换距离较远的元素,然后逐渐减少比较和交换的间距,直到间距为 1,此时算法变为简单的插入排序。间距序列的选择对算法的性能有显著影响。
希尔排序算法可以分为以下几个步骤:
- 选择一个间距序列。
- 对每个间距进行间隔插入排序。
- 减少间距,重复步骤 2,直到间距为 1。
间距序列的选择是算法性能的关键。常用的间距序列包括:
- Shell 的原始序列:n/2, n/4, …, 1
- Hibbard 序列:1, 3, 7, 15, …, 2^k - 1
- Sedgewick 序列:1, 5, 19, 41, 109, …
下面是希尔排序在 C++ 中的两个实现。第一个实现使用固定的间距序列,第二个实现使用动态计算的间距。
实现方式一:固定间距序列
#include<iostream>
void print(int a[],int n){
for(int i =0; i < n; i++){
std::cout << a[i]<<" ";
}
std::cout << std::endl;
}
void shellSort(int a[],int n){
int gap =3;
int i, j;
while(gap--){
for(i = gap; i < n; i++){
int key = a[i];
for(j = i - gap; j >=0&& a[j]> key; j -= gap){
a[j + gap]= a[j];
}
a[j + gap]= key;
}
}
}
int main(){
int a[]={1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31};
int n = sizeof(a)/sizeof(a[0]);
print(a,n);
shellSort(a,n);
print(a,n);
return 0;
}
实现方式二:动态间距序列
#include<iostream>
#include<vector>
using namespace std;
// 希尔排序函数
void shellSort(vector<int> &v) {
int n = v.size();
int h = 1;
while (h < n / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < n; i++) {
for (int j = i; j >= h && v[j] < v[j - h]; j -= h) {
swap(v[j], v[j - h]);
}
}
h = h / 3;
}
}
int main() {
vector<int> arr = {9, 4, 2, 8, 5, 1, 7, 3, 6};
cout << "希尔排序前:";
for (int i = 0; i < arr.size(); i++) {
cout << arr[i] << " ";
}
cout << endl;
shellSort(arr);
cout << "希尔排序后:";
for (int i = 0; i < arr.size(); i++) {
cout << arr[i] << " ";
}
cout << endl;
return 0;
}
(二)堆排序
堆排序从堆开始,将最大的元素放在数组末尾,然后重建少了一个元素的堆。在新堆中,将最大的元素移到正确的位置上,然后为其他元素恢复堆属性。
堆排序是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
- 第一步,升序建大堆
- 第二步,将根结点与最后的叶子结点交换,然后再次建大堆 (每次最后确定的最大数不参与建大堆)
实现代码(升序建大堆):
#include<iostream>
#include<vector>
void AdjustDown(vector<int>& a,int n,int root){
int parent=root;
int child=parent*2+1;
while(child<n){
if(child+1<n&&a[child+1]>a[child]){
++child;
}
if(a[child]>a[parent]){
swap(a[child],a[parent]);
parent=child;
child=parent*2+1;
}else{
break;
}
}
}
void HeapSort(vector<int>& a,int n){
//排升序,建大堆
for(int i=(n-1-1)/2;i>=0;i--){
AdjustDown(a,n,i);
}
int end=n-1;
while(end>0){
swap(a[0],a[end]);
AdjustDown(a,end,0);
end--;
}
}
int main(){
int n;
cin >> n;
vector<int> a;
while(n--){
int k;
cin >> k;
a.push_back(k);
}
HeapSort(a, a.size());
for(auto e : a){
cout << e << " ";
}
return 0;
}
堆排序使用堆来选数,效率就高了很多。时间复杂度:O (N*logN),空间复杂度:O (1),稳定性:不稳定。
(三)快速排序
快速排序以一个边界值为基准划分为两个数组,第一个数字中所有的元素都小于边界值,第二个则都大于边界值。然后不断的迭代下去,直到划分为只包含一个元素的数组。
快速排序(Quick Sort)是一种高效的排序算法,由英国计算机科学家东尼・霍尔(Tony Hoare)于 1960 年发明。
快速排序算法的基本思想是分治法(Divide and Conquer),其核心步骤如下:
- 选择一个基准元素(pivot),通常选择序列中的第一个或最后一个元素。
- 将序列分为两部分,一部分是小于等于基准元素的元素,另一部分是大于基准元素的元素。
- 递归地对这两部分序列进行快速排序。
详细描述一下给任意 n 个数排序的快速排序算法:
- 假设我们要对数组 a [1..n] 排序。初始化区间 [1..n] 。
- 令 l 和 r 分别为当前区间的左右端点。下面假设我们对 l 到 r 子段内的数字进行划分。取 pivot = a [l] 为分界线,将 < pivot 的数字移到左边,>pivot 的数字移到右边,然后将 pivot 放在中间。假设 pivot 的位置是 k。
- 如果左边区间 [l..k - 1] 长度大于 1,则对于新的区间 [l..k - 1],重复调用上面的过程。
- 如果右边区间 [k + 1..r] 长度大于 1,则设置新的区间 [k + 1, r],重复调用上面的过程。当整个过程结束以后,整个序列排序完毕。
代码实现:
// 该代码参考 https://www.geeksforgeeks.org/quick-sort/
#include<bits/stdc++.h>
#define N 100010
using namespace std;
int n;
int a[N];
void quick_sort(int l,int r){
// 设置最右边的数为分界线
int pivot = a[r];
// 元素移动
int k = l -1;
for(int j = l; j < r;++j)
if(a[j]< pivot)
swap(a[j], a[++k]);
swap(a[r], a[++k]);
if(l < k -1)quick_sort(l, k -1);
// 如果序列的分界线左边的子段长度>1,排序
if(k +1< r)quick_sort(k +1, r);
// 如果序列的分界线右边的子段长度>1,排序
// 上面的过程结束后,到这里左子段和右子段已经分别排好序。又因为确定分界线以后的移动操作
// 保证了左子段中的元素都小于等于分界线,右子段中的元素都大于分界线。所以整个序列也是有序的。
}
int main(){
// 输入
scanf("%d",&n);
for(int i =1; i <= n;++i)
scanf("%d",&a[i]);
// 快速排序
quick_sort(1, n);
// 输出
for(int i =1; i <= n;++i)
printf("%d ", a[i]);
return 0;
}
快速排序的空间复杂度是 O (n),具体来说,在整个排序过程中,元素的移动都在原始数组中进行。所以快速排序是一种原地排序算法。时间复杂度分析:在「详细算法描述」中,我们的算法分为若干层。每一层中都是分治法的三个步骤:我们首先进行问题拆分,然后进入下一层,下一层的问题解决后,我们返回这一层进行子问题解的合并。
对于子段解的合并,其复杂度是 O (1),因为有分界线的存在,当我们把左边和右边都排好序后,它们和分界线元素一起天然形成了原序列的完整排序。而问题拆分的复杂度是 O (n),因为我们移动数组元素的时候,需要将每个子段扫一遍。那么把所有层的子段一起看,就相当于在每一层都把整个序列完整扫了一遍。
一共有多少层呢?因为每次我们都知道当前子段的中位数,所以可以保证每次划分,两个字段长度比较平衡,所以下一层子段的长度都比上一层减少了一半,直到长度为 1 算法停止。
三、复杂排序算法

(一)鸽巢排序
鸽巢排序是一种基于计数的排序算法,它利用了鸽巢原理的概念。具体步骤如下:
首先确定待排序序列中的最小值和最大值,以便确定需要准备多少个鸽巢,即桶或容器。例如,对于一个待排序的数组,先找到其中的最小元素和最大元素。
然后创建一个与鸽巢数量相同的鸽巢数组,并初始化为 0。这个鸽巢数组的大小为(最大值 - 最小值 + 1)。
接着遍历待排序数组的所有元素,将元素的值减去最小值得到鸽巢数组的下标,然后将鸽巢数组的对应位置加 1。比如,如果一个元素的值为 10,最小值为 5,那么它对应的鸽巢数组下标为 5,将鸽巢数组中下标为 5 的位置的值加 1。
最后遍历鸽巢数组,将非 0 的值依次放回原数组。按照鸽巢数组的顺序,将对应位置的值不为 0 的元素依次放回原数组,即可得到有序序列。
以下是使用 C++ 实现鸽巢排序算法的代码:
#include<iostream>
#include<vector>
void pigeonholeSort(std::vector<int>& arr){
int minVal = arr[0];
int maxVal = arr[0];
for (int i = 1; i < arr.size(); ++i) {
if (arr[i] < minVal) {
minVal = arr[i];
}
if (arr[i] > maxVal) {
maxVal = arr[i];
}
}
int range = maxVal - minVal + 1;
std::vector<int> holes(range,0);
for (int i = 0; i < arr.size(); ++i) {
holes[arr[i] - minVal]++;
}
int index = 0;
for (int i = 0; i < range; ++i) {
while (holes[i] > 0) {
arr[index++] = i + minVal;
holes[i]--;
}
}
}
鸽巢排序算法的优点是简单易懂,且对于某个范围内的整数排序效果较好。然而,该算法的缺点是需要额外的空间存储鸽巢数组,且无法处理非整数数据类型。对于较大的数据范围,鸽巢数组的大小也会变得很大,使得算法的空间复杂度增加。
(二)圈排序
圈排序是一种基于交换的不稳定排序算法。该算法通过将每个元素移动到它应该在的位置来完成排序。
具体过程是,对于待排序序列中的每个元素,我们将其放回正确的位置,并将原来位置上的元素继续移动,直到回到起始位置。
例如,对于一个待排序的数组,从第一个元素开始,将其与其他元素进行比较,找到它在排序后应该处于的位置。如果第一个元素不在正确的位置上,将其与当前位置上的元素交换,直到它处于正确的位置上。然后,对下一个元素进行同样的操作,直到所有元素都在正确的位置上。
以下是使用 C++ 实现圈排序算法的代码:
#include<iostream>
#include<vector>
void cycleSort(std::vector<int>& arr){
int n = arr.size();
for (int cycleStart = 0; cycleStart < n - 1; ++cycleStart) {
int item = arr[cycleStart];
int pos = cycleStart;
for (int i = cycleStart + 1; i < n; ++i) {
if (arr[i] < item) {
pos++;
}
}
if (pos == cycleStart) continue;
while (item == arr[pos]) pos++;
if (pos!= cycleStart) {
std::swap(item, arr[pos]);
}
while (pos!= cycleStart) {
pos = cycleStart;
for (int i = cycleStart + 1; i < n; ++i) {
if (arr[i] < item) {
pos++;
}
}
while (item == arr[pos]) pos++;
if (item!= arr[pos]) std::swap(item, arr[pos]);
}
}
}
圈排序算法具有以下优点:圈排序是一种原地排序算法,不需要额外的空间;圈排序是一种稳定的排序算法,相等元素的相对顺序不会被改变;圈排序对于包含大量重复元素的数组具有较好的性能,因为它只进行必要的交换操作。
(三)反序列排序
反序列排序算法是一种随机打乱待排序序列,然后检查是否已经有序,如果没有则重复这个过程的算法。
例如,对于一个待排序的数组,首先随机打乱数组的顺序。然后检查数组是否已经有序,如果不是,则再次随机打乱数组,直到数组有序为止。
以下是使用 C++ 实现反序列排序算法的代码:
#include<iostream>
#include<vector>
#include<algorithm>
bool isSorted(std::vector<int>& arr){
for (int i = 0; i < arr.size() - 1; ++i) {
if (arr[i] > arr[i + 1]) {
return false;
}
}
return true;
}
void bogoSort(std::vector<int>& arr){
while (!isSorted(arr)) {
std::random_shuffle(arr.begin(), arr.end());
}
}
尽管反序列排序算法结构简单,但它的平均时间复杂度为 O ((n+1)!),因此在实际应用中几乎不会使用。
(四)慢速排序
慢速排序是一种递归的排序算法,它使用了冒泡排序的变体。将待排序序列划分为两部分,然后递归地对这两部分进行排序,最后再通过交换相邻元素来确保序列有序。
具体来说,对于一个待排序的数组,首先将数组划分为两部分。然后递归地对这两部分进行排序。接着,如果数组中间位置的元素大于右边位置的元素,则交换这两个元素。最后,递归地对左边部分和右边部分分别进行排序,直到整个数组有序。
以下是使用 C++ 实现慢速排序算法的代码:
#include<iostream>
#include<vector>
void slowSort(std::vector<int>& arr, int left, int right){
if (left >= right) {
return;
}
int mid = (left + right) / 2;
slowSort(arr, left, mid);
slowSort(arr, mid + 1, right);
if (arr[mid] > arr[right]) {
std::swap(arr[mid], arr[right]);
}
slowSort(arr, left, right - 1);
}
四、高级算法应用场景

(一)堆排序、归并排序、二分查找在面试中的应用
在面试中,堆排序、归并排序、二分查找等高级算法常常是考察的重点内容。不仅要求能够准确地写出这些算法的代码,还需要深入理解其工作原理和性能特点,甚至能够对其进行变种的讨论或在特定场景下进行优化。
对于堆排序,面试官可能会要求解释其建堆和调整堆的过程,以及如何利用堆来实现排序。例如,可以通过分析堆的性质,即大根堆中每个节点的值都大于等于其子节点的值,小根堆中每个节点的值都小于等于其子节点的值,来阐述堆排序的原理。在性能方面,堆排序的时间复杂度为 ,空间复杂度为 ,稳定性为不稳定。面试官可能会进一步询问如何在实际应用中优化堆排序,或者在特定场景下如何选择使用堆排序还是其他排序算法。
归并排序也是面试中常见的算法之一。面试官可能会要求解释归并排序的分治思想,即先将数组分成两个子数组,分别进行排序,然后再将两个有序的子数组合并成一个有序的数组。在实现归并排序时,需要注意空间复杂度的问题,因为归并排序需要额外的空间来存储临时数组。此外,面试官可能会询问归并排序的稳定性,以及如何在实际编程中应用归并排序来处理大规模数据。
二分查找是一种高效的查找算法,前提是数据结构必须先排好序。面试官可能会要求解释二分查找的原理,即通过不断缩小查找范围,每次将查找区间分为两部分,根据中间元素与目标元素的大小关系来确定下一步的查找方向。在面试中,还可能会出现二分查找的变种问题,如查找第一个出现的等于给定目标值的元素、查找最后一次出现的等于给定目标值的元素、查找第一个大于等于给定值的元素、查找最后一个小于等于给定值的元素等。这些变种问题需要对二分查找的原理有深入的理解,并能够灵活地运用。
对于更高级的面试,可能会要求讨论这些算法的变种,或者在特定情景下如何优化它们。例如,在堆排序中,可以考虑使用不同的堆结构,如大根堆和小根堆的混合使用,或者在归并排序中,可以采用并行归并的方式来提高效率。在二分查找中,可以根据数据的分布特点来选择不同的查找策略,或者在特定的数据结构上进行二分查找的优化。
总之,在面试中,对堆排序、归并排序、二分查找等高级算法的掌握程度是考察应聘者编程能力和算法思维的重要指标之一。通过深入理解这些算法的原理和性能特点,并能够在实际问题中灵活运用和优化,能够提高在面试中的竞争力。
(二)高级排序算法在实际编程中的应用
高级排序算法在数据处理、游戏开发、系统编程等多种场景下都有广泛的应用。这些算法可以帮助快速排序、搜索和过滤数据,在 AI 决策、路径查找等方面发挥重要作用,同时还能优化性能和资源管理。
在数据处理领域,高级排序算法可以对大规模数据进行高效的排序和搜索。例如,归并排序可以将多个有序的子数组合并成一个有序的数组,适用于处理大规模数据的排序问题。堆排序可以快速地找到数据中的最大值或最小值,适用于优先队列等数据结构。二分查找可以在有序数据中快速地查找特定元素,提高数据检索的效率。
在游戏开发中,高级排序算法也有着重要的应用。例如,在游戏中的排行榜功能中,可以使用快速排序或归并排序对玩家的得分进行排序,以便展示给玩家。在游戏中的路径查找算法中,如 A * 算法,需要对开放列表和关闭列表进行排序,以提高算法的效率。此外,在游戏中的资源管理中,也可以使用排序算法对资源进行分类和排序,以便更好地管理和利用资源。
在系统编程中,高级排序算法可以优化性能和资源管理。例如,在操作系统的内存管理中,可以使用堆排序或快速排序对内存块进行排序,以便更好地分配和回收内存。在数据库管理系统中,排序算法可以用于对数据进行索引和查询优化。在网络编程中,排序算法可以用于对数据包进行排序和处理,以提高网络通信的效率。
总之,高级排序算法在实际编程中有着广泛的应用,可以帮助提高程序的性能和效率,优化资源管理,解决各种实际问题。在选择使用高级排序算法时,需要根据具体的应用场景和需求,综合考虑算法的时间复杂度、空间复杂度、稳定性等因素,选择最合适的算法。


![[pdf,epub]228页《分析模式》漫谈合集01-45提供下载](https://i-blog.csdnimg.cn/img_convert/bbc04da097a84dc5ab9df74beca34dfc.png)



![[STM32] ADC 模数转换器 (十)](https://i-blog.csdnimg.cn/direct/4509302f3add45dfbd3cf65c44f2d3eb.png)