数据库的高可用能力是数据库的基本能力,可靠性的设计和机制能够保证数据库节点异常时能够正常切换、减少业务的影响范围和时间,保证业务的可用性和连续性。本文主要介绍GaussDB数据库的高可用能力测试验证情况,通过模拟故障场景来验证GaussDB集中式数据库在异常情况下的高可用能力。如果对测试过程不感兴趣的,可以直接跳到最后测试总结部分。
1、测试环境准备
1.1 环境部署架构
测试环境采用生产同城同一个数据库集群3AZ三节点部署方式,每个节点一个数据库服务器,这里的AZ可以认为是不同的机房模块。如下图所示:

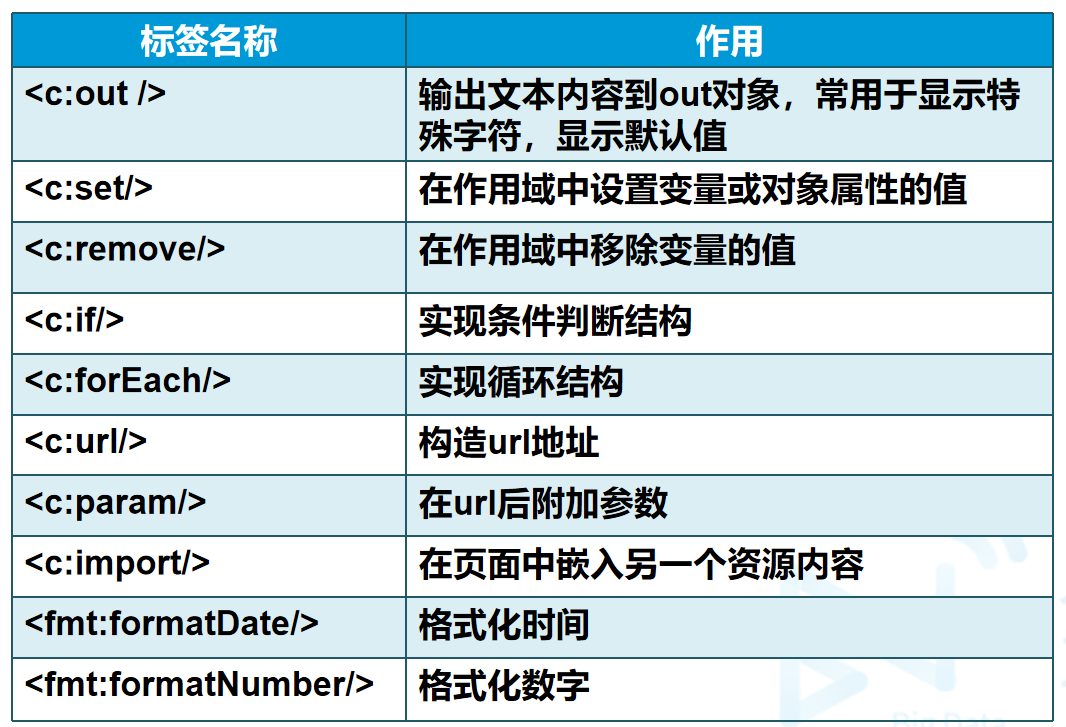
- CM由CM Agent、CM Server和OM monitor构成:
- CM Agent:管理服务组件,由OMM拉起(周期1秒),主要负责CMS、DN进程的保活及启停,仲裁指标采集、仲裁命令执行等。集群的每台主机上均有CM Agent进程。CMA故障可能会导致启停能力丢失、实例故障检测能力丢失。
- CM Server:管理服务组件,由CMA拉起(周期1秒),根据CM Agent上报的实例状态判定当前状态是否正常,是否需要修复,并下发指令给CM Agent执行。CM Server会将集群的拓扑信息保存在ETCD。
- OM Monitor:管理服务组件,由crontab定时任务控制拉起(周期1分钟),主要负责OMM、etcd、cm_agent进程的保活及启停
- DN节点:数据服务组件,由CMA拉起(周期1秒),负责存储业务数据、执行数据查询任务以及返回应用结果。DN主备节点之间采用Quorum复制或Paxos协议复制。
- ETCD节点:管理服务组件,由OMM自动拉起(周期1秒),主要协助CMS选主、持久化集群仲裁信息、保存集群的拓扑信息等。
其中DN主节点、ETCD主节点和CM Server主节点不一定在同一台主机上,实际会分布在不同的服务器上。
1.2 高可用测试脚本
1.2.1 Benchmark-TPCC测试
1)脚本配置
db=postgers
driver=com.huawei.gaussdb.jdbc.Driver
conn=jdbc:gaussdb://xx.xx.xx.xx:port, xx.xx.xx.xx:port/dbxx?currentSchema=xx&targetServerType=master&socketTimeout=60&connectionTimeout=2&LoginTimeout=6<RowFetchSize=1000
2)运行脚本
##准备数据
sh runDatabaseBuild.sh props.gs
##测试运行
sh runBenchmark.sh props.gs
##清理数据
sh runDatabaseDestroy.sh props.gs
1.2.2 Sysbench测试
1)下载并安装sysbench工具,配置时指定支持pgsql
yum install –y make automake libtool pkgconfig libaio-devel
yum install –y openssl-devel mysql-devel postgresql-devel
./autogen.sh
./configure -prefix=xx --with-pgsql
Make && make install
2)修改GaussDB参数并重启
##修改参数password_encryption_type
Gs_guc set -Z datanode -N all -c “password_encryption_type=1”
##修改gs_hba.conf配置文件,添加以下内容
Host all all 0.0.0.0/0 md5
##修改完成后生效
##重新配置用户密码,否则不生效
=> alter user xxxx identified by ‘xxxx’;
因为sysbench连接gaussdb使用md5加密算法,默认是不支持的
3)创建用户和库后,运行脚本测试
##prepare语句
#sysbench oltp_read_write.lua --db-driver=pgsql --pgsql-host=xx.xx.xx.xx --pgsql-port=xx --pgsql-user=xx --pgsql-password=xx --pgsql-db=xx --tables=10 --table-size=1000000 --threads=10 --time=300 --report-interval=1 prepare
##run语句
#sysbench oltp_read_write.lua --db-driver=pgsql --pgsql-host=xx.xx.xx.xx --pgsql-port=xx --pgsql-user=xx --pgsql-password=xx --pgsql-db=xx --tables=10 --table-size=1000000 --threads=10 --time=300 --report-interval=1 run
1.2.3 中断继续执行
由于TPCC和sysbench测试的时候出现错误会中断退出,为了验证中断能重连,准备监控脚本在中断时候能够重新拉起任务执行,以验证故障时候业务的恢复时间。
#!/bin/sh
#输入变量
log_output=$1
#定义要监控的进程名称
PROCESS_NAME="runBenchmark.sh"
#定义启动进程的命令
cd /tmp/benchmarksq5.0/run
START_COMMAND="/bin/sh /tmp/benchmarksq5.0/run/runBenchmark.sh props.gs >> $1"
#日志文件路径
LOG_FILE="/tmp/monitor_and_restart.log"
# 无限循环,持续监控进程
while true; do
# 检查进程是否存在
if ! pgrep -x "$PROCESS_NAME" > /dev/null; then
echo "$(date): $PROCESS_NAME is not running. Restarting..." | tee -a "$LOG_FILE"
# 尝试启动进程
eval $START_COMMAND
if [ $? -eq 0 ]; then
echo "$(date): $PROCESS_NAME restarted successfully." | tee -a "$LOG_FILE"
else
echo "$(date): Failed to restart $PROCESS_NAME." | tee -a "$LOG_FILE"
fi
else
echo "$(date): $PROCESS_NAME is running." | tee -a "$LOG_FILE"
fi
# 等待1秒钟
sleep 1
done
2、高可用测试场景
2.1 DN主节点故障有效性
2.1.1 测试目标
考察GaussDB数据库DN主节点异常的情况下,对业务处理的影响,DN节点能否正常切换、业务影响的时间是多少。
2.1.2 故障场景
1)DN主节点停进程
#查询节点信息
Cm_ctl query -Cv
#执行停止操作
Cm_ctl stop -n 1 -D /xx/dn_6001
TPS降为0,持续约16s,为DN节点主备切换时间。
2)DN主节点进程kill
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
TPS降为0,持续约10s,为DN节点主备切换时间
3)DN主节点进程挂起
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
TPS降为0,持续约102s,为检测DN主节点异常及主备切换时间。进程挂起状态下,触发DN节点僵死检测机制。
4)DN主节点服务器禁用网卡
##禁用网卡
ifdown eth0
##恢复网卡
ifup eth0
测试发现DN主节点很快发生切换,但是应用连接挂起无响应,旧的连接没有释放并且链路不通,应用侧需要有链路超时断开机制。新的连接请求会使用新的DN主节点建立链接。
5)DN主节点服务器重启
##重启服务器
reboot
TPS降为0,持续约14s,为DN节点主备切换时间。
2.1.3 DN僵死检测机制
当DN进程处于D、T、Z或者连接超时等僵死状态时,DN无法及时处理业务请求,导致业务中断,影响业务正常功能。CM支持根据配置值定时检测DN是否处于僵死状态,对连续处于僵死状态的DN,达到配置次数后做重启恢复操作。

如果开启了enable_e2e_rto开关,当检测到1次僵死后会立即将实例状态置为UNKNOWN,进而触发选主仲裁流程。默认是没开启这个参数,由控制参数agent_phony_dead_check_interval(默认值10s)、phony_dead_effective_time(默认值5次)控制检测的时长。
- 连接类僵死默认(10 * 5)秒后标记为僵死,触发重启。
- 由于实例正常运行也会出现D状态,执行gstack等定位动作会出现T状态,为避免这种场景导致的误判和core生成不完整,D/T状态僵死规格为持续3分钟状态未变化,则触发重启。
- coredump时也会有D/T状态,检测到数据库core标记后,此时不会做重启动作,但是会将实例置为UNKNOWN,进而触发选主仲裁流程。
2.2 DN节点副本故障有效性
2.2.1 测试目标
考察单个DN备节点和所有DN备节点异常时对业务的影响。
2.2.2 故障场景
1)单个DN节点停进程
#查询节点信息
Cm_ctl query -Cv
#执行停止操作
Cm_ctl stop -n 1 -D /xx/dn_6001
对业务无影响,进程需要手动start
2)单个DN节点进程kill
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
对业务无影响,进程1s后由CMA自动拉起
3)单个DN节点进程挂起
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
对业务无影响,进程触发僵死检测,100s后kill并由CMA自动拉起
4)单个DN节点服务器禁用网卡
##禁用网卡
ifdown eth0
##恢复网卡
ifup eth0
对业务无影响,网络正常后恢复。
5)单个DN节点服务器重启
##重启服务器
reboot
对业务无影响,DN进程在备机重启后自动拉起。
6)所有DN备节点进程kill
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
业务变成只读,持续约6s,为备节点DN进程恢复时间。
7)所有DN备节点进程挂起
ps –fu $USER|grep ‘bin/gaussdb’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
业务变成只读,持续约150s后恢复,为检测DN备节点异常并kill后重新拉起恢复。DN进程挂起时触发DN僵死检测机制。
8)所有DN备节点网络异常
##禁用网卡
ifdown eth0
##恢复网卡
ifup eth0
业务变成只读,影响时长为网络恢复时间。
9)所有DN节点服务器重启
##重启服务器
reboot
业务变成只读,持续约110s后恢复,为DN备节点服务器重启恢复时间。
2.3 ETCD节点故障有效性
2.3.1 测试目标
考察ETCD节点异常时对业务的影响。
2.3.2 故障场景
1)ETCD所有节点kill进程
ps –fu $USER|grep ‘bin/etcd’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
业务无影响,ETCD进程1s后由OMM组件自动拉起。ETCD主节点异常会发生切换。
2)ETCD所有节点进程挂起
ps –fu $USER|grep ‘bin/etcd’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
业务无影响,ETCD进程1s后由OMM组件kill并自动拉起。ETCD主节点异常会发生切换。
2.4 CM Server组件故障有效性
2.4.1 测试目标
考察CM Server组件异常时对业务的影响。
2.4.2 故障场景
1)CM Server所有节点kill进程
ps –fu $USER|grep ‘bin/cm_server’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
业务无影响,CM Server进程1s后由CMA组件自动拉起。CM Server主节点异常会发生切换。
2)CM Server所有节点进程挂起
ps –fu $USER|grep ‘bin/cm_server’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
业务无影响,CM Server进程1s后由CMA组件kill并自动拉起。CM Server主节点异常会发生切换。
2.5 CM Agent组件故障有效性
2.5.1 测试目标
考察CM Agent异常时对业务的影响。
2.5.2 故障场景
1)CM Agent所有节点kill进程
ps –fu $USER|grep ‘bin/cm_agent’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -9
业务无影响,CM Server进程1s后由OMM组件自动拉起。
2)CM Agent所有节点进程挂起
ps –fu $USER|grep ‘bin/cm_agent’|grep –v ‘grep’ | awk ‘{print $2}’|xargs kill -19
业务无影响,CM Server进程1s后由OMM组件kill并自动拉起。
2.6 备份影响验证
2.6.1 测试目标
考察GaussDB数据库在主节点和备节点备份时候对读写业务的影响。
2.6.2 测试场景
1)GaussDB数据库主节点发起备份对读写业务影响
经测试验证,主节点备份期间TPS下降40%左右,备份结束后恢复。
2)GaussDB数据库备节点发起备份对读写业务影响
经测试验证,备节点备份期间TPS和响应时间没有明显变化,对业务无影响。
3)GaussDB数据库备节点发起备份对备节点读业务影响
经测试验证,备节点备份期间备节点只读业务TPS和响应时间没有明显变化,对业务无影响。
2.7 AZ故障切换影响验证
2.7.1 测试目标
考察GaussDB数据库在AZ故障手动切换的时候对业务的影响。
2.7.2 测试场景
1)DN节点执行AZ切换
#switchover切换操作
cm_ctl switchover -z AZ2
切换期间TPS降为0,持续约9s,为DN节点主备AZ切换时间。
2)数据库管理平台(TPOPS)执行AZ切换
切换期间TPS降为0,持续约9s,为DN节点主备AZ切换时间。
2.8 DN主节点服务器性能degrade
2.8.1 测试目标
考察GaussDB数据库DN主节点服务器网络性能异常时对业务的影响。
2.8.2 测试场景
1)DN主节点网络延时高
#模拟网络延迟高操作
tc qdisc add dev eth0 root netem delay 2ms 0.3ms
#取消网络延迟高操作
tc qdisc del dev eth0 root netem delay 2ms 0.3ms
故障期间TPS下降约60%,网络恢复后TPS恢复正常。
2)DN主节点网络抖动高
#模拟网络抖动高操作
tc qdisc add dev eth0 root netem delay 0.1ms 2ms
#取消网络抖动高操作
tc qdisc del dev eth0 root netem delay 0.1ms 2ms
故障期间TPS下降约60%,网络恢复后TPS恢复正常。
3)DN主节点网络重传高
#模拟网络重传高操作
tc qdisc add dev eth0 root netem loss 10%
#取消网络重传高操作
tc qdisc del dev eth0 root netem loss 10%
故障期间TPS下降约95%,网络恢复后TPS恢复正常。
3、高可用测试总结
总体上来说,GaussDB数据库具备DN主节点进程和服务器异常时自动切换的能力、支持AZ机房级别的手动切换。这里测试验证了DN主节点故障、DN备节点异常等主要场景的高可用能力,测试结果如下表所示:
- DN主节点异常时,能够正常切换到备节点,切换期间业务TPS降为0,影响时长约10s。
- DN备节点异常时,CMA会自动拉起进程。在所有DN备节点异常时,保证高可靠性的前提下,数据库会变成只读状态,故障恢复时间为备节点恢复时间。
- 当DN节点进程挂起或服务端口假活状态时,DN会触发僵死状态的检测,此时DN异常处理的时长100s~200s。
- 当DN主节点网络异常时,DN主备虽然发生了切换,但是应用和DN原主节点之间的旧链接并没有立即释放,此时数据库端是无法主动断开这个连接(网络通信已经异常了,无法发送网络包),需要在应用侧或驱动侧配置链路超时断开机制,这样旧的连接会及时释放掉,业务请求会通过新主建立新的链接。不然业务请求会一直通过旧连接过来,交易会访问失败的。
- ETCD节点、CM Server节点和CM Agent节点异常时,对业务无影响,只会影响本身的监控和切换功能。ETCD主节点和CM Server主节点异常时都会发生主备切换。
- GaussDB数据库支持AZ级别的手动切换,切换期间业务TPS降为0,影响时长约10s。
- 备份期间的影响,如果是在DN主节点备份,TPS会下降40%,所以要求在备节点备份。备节点备份期间对主备节点的业务没有影响。

不过在测试过程中发现ETCD主节点和CM Server主节点不支持手动AZ切换、ETCD节点不支持手动启停,在功能细节上还有待完善。
以上是GaussDB集中式数据库的高可用测试相关验证总结,如果对测试结果有疑问的,欢迎一起讨论和指正。
参考资料:
- GaussDB数据库产品文档
- GaussDB数据库高可用部署方案简析