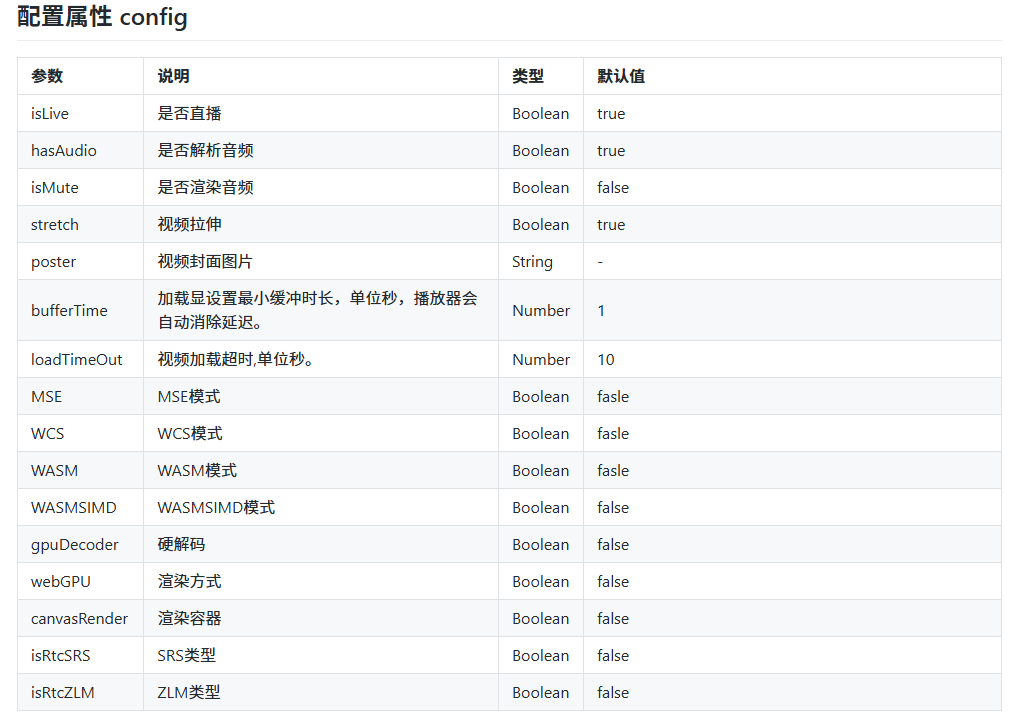
1--官方仓库
https://github.com/ocrmypdf/OCRmyPDF
2--基本步骤
# 安装ocrmypdf库
sudo apt install ocrmypdf
# 安装简体中文库
sudo apt-get install tesseract-ocr-chi-sim
# 转换
# -l 表示使用的语言
# --force-ocr 防止出现以下错误:ERROR - PriorOcrFoundError: page already has text! - aborting (use --force-ocr to force OCR)
# input.pdf 表示待转换的pdf
# output.pdf 表示转换后保存的pdf
ocrmypdf -l chi_sim input.pdf output.pdf --force-ocr3--常见错误
Error1:
ERROR - PriorOcrFoundError: page already has text! - aborting (use --force-ocr to force OCR)

Solution:
添加--force-ocr
ocrmypdf -l chi_sim input.pdf output3.pdf --force-ocr