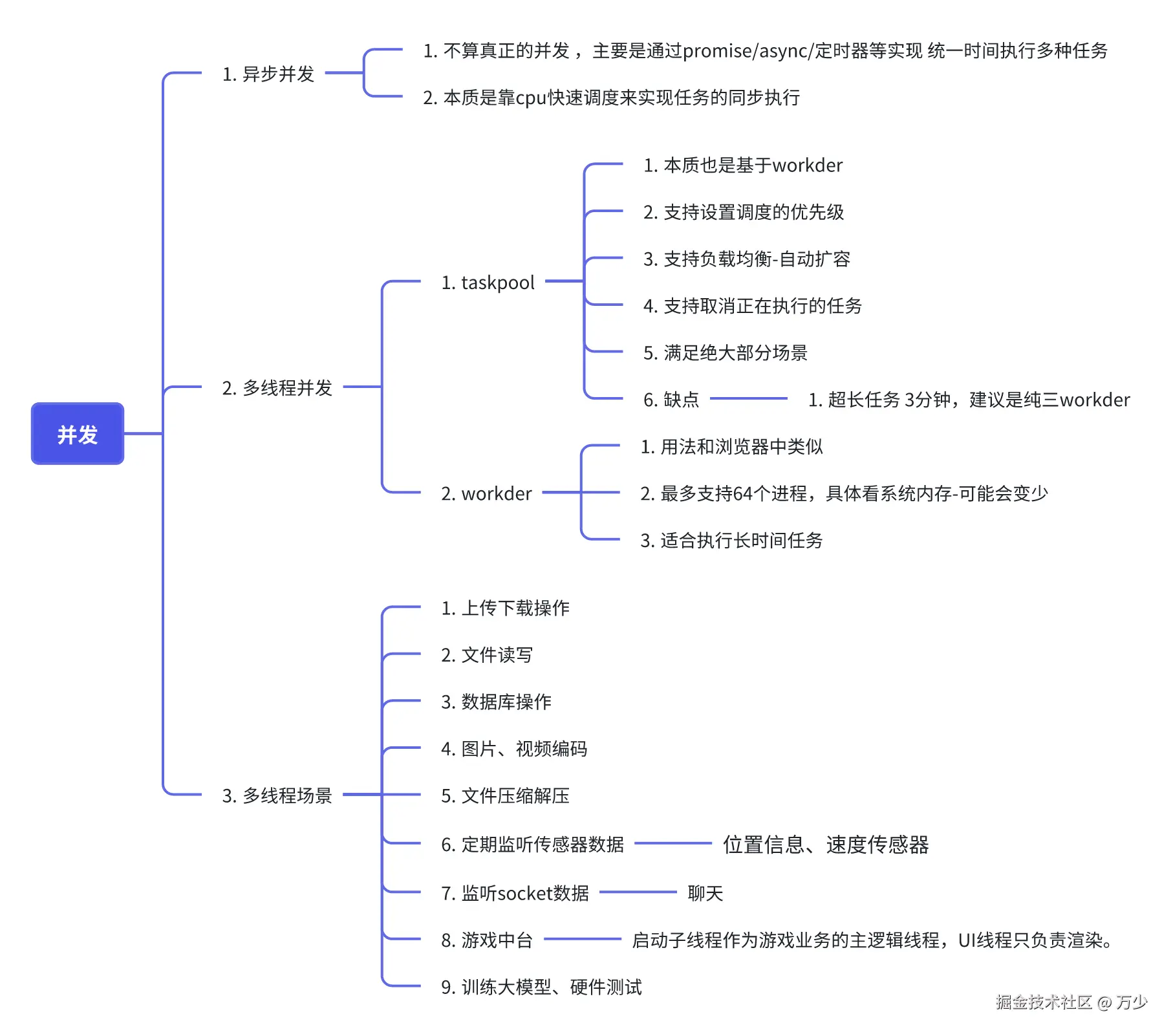
本文使用脚本实现hadoop-yarn-flink的快速部署(单机部署)。
环境:①操作系统:CentOS 7.6;②CPU:x86;③用户:root。
1.前置条件
把下面的的脚本保存到“pre-install.sh”文件,“sh pre-install.sh”执行。
脚本如下:
#!/bin/bash
# 检查JAVA_HOME环境变量是否设置
if [ -z "$JAVA_HOME" ]; then
echo "JAVA_HOME环境变量未设置,脚本将退出。"
exit 1
fi
# 文件路径
FILE="/etc/sysctl.conf"
# 要添加的内容
LINE="vm.max_map_count=2000000"
# 使用 grep 检查 vm.max_map_count 是否已存在,修改/etc/sysctl.conf vm.max_map_count=2000000
if ! grep -q "^vm\.max_map_count=" "$FILE"; then
# 如果不存在,则添加到文件末尾
echo "$LINE" >> "$FILE"
sudo sysctl -p
fi
# 修改handlers数
if ! grep -q "* soft nofile 65536" /etc/security/limits.conf; then
echo "* soft nofile 65536" >> /etc/security/limits.conf
fi
if ! grep -q "* hard nofile 65536" /etc/security/limits.conf; then
echo "* hard nofile 65536" >> /etc/security/limits.conf
fi
##关闭交换分区
swapoff -a
# 定义要检查的变量和值
HADOOP_HOME="/home/hadoop-3.3.3"
FLINK_HOME="/home/flink-1.13.1"
# 检查HADOOP_HOME是否已经设置
if ! grep -q "export HADOOP_HOME=" /etc/profile; then
echo "export HADOOP_HOME=$HADOOP_HOME" >> /etc/profile
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> /etc/profile
echo "export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop" >> /etc/profile
fi
# 检查FLINK_HOME是否已经设置
if ! grep -q "export FLINK_HOME=" /etc/profile; then
echo "export FLINK_HOME=$FLINK_HOME" >> /etc/profile
echo "export PATH=\$FLINK_HOME/bin:\$PATH" >> /etc/profile
fi
# 检查HADOOP_HOME是否已经设置
if ! grep -q "export HADOOP_CLASSPATH=" /etc/profile; then
echo "export HADOOP_CLASSPATH=\`hadoop classpath\`" >> /etc/profile
fi
# /home/目录下创建project_config目录
mkdir -p /home/project_config
# 执行生效
source /etc/profile
温馨提示:由pre-install.sh修改的是系统文件,因此需要重新登录打开一个新linux窗口执行接下来的命令。
执行这步出现下图提示是正常的,可继续执行下一步,是因为hadoop还没部署。

2.上传安装包
把flink-1.13.1-bin-scala_2.11.tgz、hadoop-3.3.3.tar、上传到“/home”目录下。
3.安装
把下面的的脚本保存到“hadoop-yarn-flink-install.sh”文件,“sh hadoop-yarn-flink-install.sh”执行。
脚本如下:
#!/bin/bash
# 获取当前主机IP(只取第一个非本地回环的IPv4地址)
HOST_NET=$(ip -o -4 addr show | awk '/inet / && !/127.0.0.1/ {split($4,a,"/"); print a[1]; exit}')
# 定义一个函数来杀掉进程
kill_process() {
local process_name=$1
local wait_time=$2
local pids=$(pgrep -f "$process_name")
if [ -n "$pids" ]; then
echo "杀掉 $process_name 进程: $pids"
for pid in $pids; do
kill "$pid" || kill -9 "$pid" # 先尝试正常终止,如果不行则强制终止
done
# 等待进程完全退出
while pgrep -x "$process_name" >/dev/null; do
sleep 1
echo "等待 $process_name 进程退出..."
if (( wait_time-- <= 0 )); then
echo "警告: $process_name 进程在 $wait_time 秒后仍未退出!"
break
fi
done
fi
}
# 使用函数杀掉进程
echo "检查并杀掉已存在的 SecondaryNameNode 进程..."
kill_process "SecondaryNameNode" 2
echo "检查并杀掉已存在的 NameNode 进程..."
kill_process "NameNode" 3
echo "检查并杀掉已存在的 ResourceManager 进程..."
kill_process "ResourceManager" 3
echo "检查并杀掉已存在的 NodeManager 进程..."
kill_process "NodeManager" 3
echo "检查并杀掉已存在的 DataNode 进程..."
kill_process "DataNode" 3
# 输出开始信息
echo "开始安装,安装IP:$HOST_NET,安装地址:/home"
# 对原安装目录进行备份
BACKUP_DIR="/home/hadoop-3.3.3_$(date +%Y-%m-%d.%H:%M:%S)"
if [ -d "/home/hadoop-3.3.3" ]; then
mv "/home/hadoop-3.3.3" "$BACKUP_DIR"
echo "原hadoop安装目录已备份至:$BACKUP_DIR"
fi
# 解压hadoop压缩包
if ! tar -xvf hadoop-3.3.3.tar -C /home/; then
echo "错误:解压hadoop压缩包失败。"
exit 1
fi
# 解压flink压缩包
if ! tar -zxvf flink-1.13.1-bin-scala_2.11.tgz -C /home/; then
echo "错误:解压flink压缩包失败。"
exit 1
fi
# 确保JAVA_HOME已定义
if [ -z "$JAVA_HOME" ]; then
echo "错误:JAVA_HOME环境变量未定义。"
exit 1
fi
# 修改hadoop-env.sh
echo "export JAVA_HOME=$JAVA_HOME" >> "/home/hadoop-3.3.3/etc/hadoop/hadoop-env.sh"
# 修改flink-conf.yaml
echo "classloader.resolve-order: parent-first" >> "/home/flink-1.13.1/conf/flink-conf.yaml"
echo "classloader.check-leaked-classloader: false" >> "/home/flink-1.13.1/conf/flink-conf.yaml"
# 修改core-site.xml 修改ip
if ! sed -i "s/21.81.10.234/$HOST_NET/g" /home/hadoop-3.3.3/etc/hadoop/core-site.xml; then
echo "错误:修改core-site.xml失败。"
exit 1
fi
# 修改yarn-site.xml 修改ip
for pattern in "21.81.10.234:8099" "21.81.10.234:8035" "21.81.10.234:8046"; do
if ! sed -i "s/$pattern/$HOST_NET:$(echo $pattern | cut -d: -f2)/g" /home/hadoop-3.3.3/etc/hadoop/yarn-site.xml; then
echo "错误:修改yarn-site.xml中的$pattern失败。"
exit 1
fi
done
# 格式化namenode
yes y | /home/hadoop-3.3.3/bin/hdfs namenode -format
# 启动hadoop
if ! /home/hadoop-3.3.3/sbin/start-dfs.sh; then
echo "错误:启动hadoop失败。"
exit 1
fi
# 启动yarn
if ! /home/hadoop-3.3.3/sbin/start-yarn.sh; then
echo "错误:启动yarn失败。"
exit 1
fi
echo "Hadoop与yarn启动成功,可通过访问:【$HOST_NET:9870/dfshealth.html】与【$HOST_NET:8099/cluster】验证或通过jps命令验证"
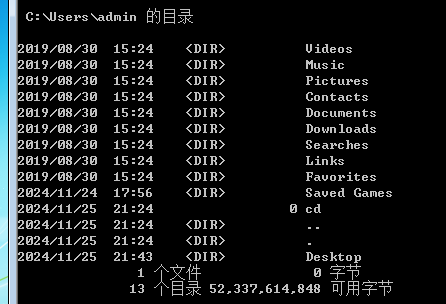
jps查看如下,说明部署成功:

至此hadoop-yarn-flink安装完成。
访问【$HOST_NET:9870/dfshealth.html】查看hadoop,如下图所示:

访问【$HOST_NET:8099/cluster】查看yarn,如下图所示:

4.常见问题
4.1 本机ssh免密登录异常
通过脚本部署hadoop时如出现异常信息如下:

解决:配置本机免密登录便可。
ssh-keygen -t rsa
ssh-copy-id ip地址
4.2 修改了ssh默认端口
需要修改/home/hadoop-3.3.3/etc/hadoop/hadoop-env.sh,如默认端口修改成2222。
在hadoop/hadoop-env.sh文件中最后加上export HADOOP_SSH_OPTS=“-p 2222” ,然后再重启hadoop则可。
4.3 flink jar包冲突解决
异常信息:

解决:
/home/flink-1.13.1/conf/flink-conf.yaml
classloader.resolve-order: parent-first
4.4 Yarn Application 8099端口访问不了
/home/hadoop-3.3.3/etc/hadoop/yarn-site.xml

用curl在linux窗口查看是否可正常访问,如可以则是映射出来的地址不可访问,可修改成可以访问的映射地址再通过web访问便可。