一、服务调用流程
服务在订阅过程中,把notify 过来的urls 都转成了invoker,不知道大家是否还记得前面的rpc 过程,protocol也是在服务端和消费端各连接子一个invoker,如下图:
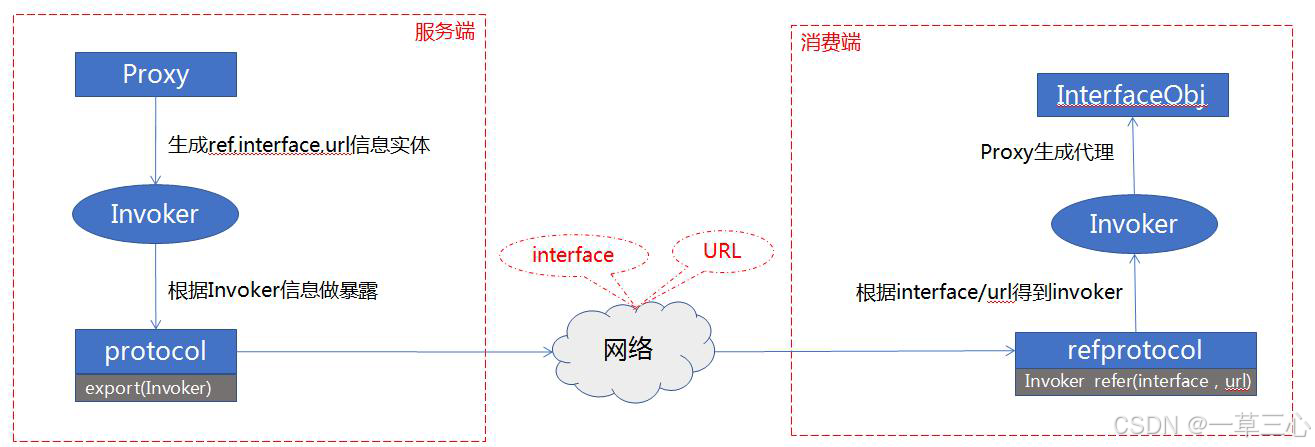
这张图主要展示rpc 主流程,消费端想要远程调用时,他是调用invoker#invoke方法;服务端收到网络请求时,也是直接触发invoker#invoke 方法。,Dubbo 设计invoker 实体的初衷,就是想要统一操作,无论你要做什么方法调用,都请使用invoker 来包装后,使用invoker#invoke来调用这个动作,简化来看,rpc 过程即是如此:
消费端invoker#invoke ------>网络---->服务端invoker#invoke--->ref 服务
上面的链路是个简化的路径,但在实际的dubbo 调用中,此链条可能会有局部的多层嵌套,如:
消费端invoker#invoke ------>容错策略--->网络---->服务端invoker#invoke--->ref服务
那么此时要重新定义链条吗?那不是个好主意。Dubbo 的做法是这样,将容错策略也包装成invoker 对象:
FailfastClusterInvoker#invoke--->protocolInvoker.invoke-->网络---->服务端invoker#invoke--->ref 服务
依次类推,dubbo 内部有非常多的invoker 包装类,它们层层嵌套,但rpc流程不关心细节,只傻瓜式地调用其invoke 方法,剩下的逻辑自会传递到最后一个invoker 进行网络调用。
服务引入时,最终又对生成invoker的做了一层代理,所以熟悉动态代理的知道,当执行服务调用时最先执行到的是InvokerInvocationHandler#invoke方法
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
try {
return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
} catch (Throwable fromJavassist) {
// try fall back to JDK proxy factory
try {
T proxy = jdkProxyFactory.getProxy(invoker, interfaces);
logger.error("Failed to generate proxy by Javassist failed. Fallback to use JDK proxy success. " +
"Interfaces: " + Arrays.toString(interfaces), fromJavassist);
return proxy;
} catch (Throwable fromJdk) {
logger.error("Failed to generate proxy by Javassist failed. Fallback to use JDK proxy is also failed. " +
"Interfaces: " + Arrays.toString(interfaces) + " Javassist Error.", fromJavassist);
logger.error("Failed to generate proxy by Javassist failed. Fallback to use JDK proxy is also failed. " +
"Interfaces: " + Arrays.toString(interfaces) + " JDK Error.", fromJdk);
throw fromJavassist;
}
}
}二、Dubbo过滤器链
Filter(过滤器)在很多框架中都有使用过这个概念,基本上的作用都是类似的,在请求处理前或者处理后做一些通用的逻辑,而且Filter 可以有多个,支持层层嵌套。
Dubbo 的Filter 实现入口是在ProtocolFilterWrapper,因为ProtocolFilterWrapper 是Protocol 的包装类,所以会在SPI 加载的Extension 的时候被自动包装进来。当然filter 要发挥作用,必定还是要
在嵌入到RPC 的调用线中(你马上应该反应过来,嵌入的办法就是包装成invoker)
ProtocolFilterWrapper 作为包装类,会成为其它protocol 的修饰加强外层。因此,protocol 的export 和refer 方法,首先是调用ProtocolFilterWrapper 类的。
暴露服务代码:
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
if (UrlUtils.isRegistry(invoker.getUrl())) {
return protocol.export(invoker);
}
FilterChainBuilder builder = getFilterChainBuilder(invoker.getUrl());
return protocol.export(builder.buildInvokerChain(invoker, SERVICE_FILTER_KEY, CommonConstants.PROVIDER));
}引入服务代码:
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
if (UrlUtils.isRegistry(url)) {
return protocol.refer(type, url);
}
FilterChainBuilder builder = getFilterChainBuilder(url);
return builder.buildInvokerChain(protocol.refer(type, url), REFERENCE_FILTER_KEY, CommonConstants.CONSUMER);
}可以看到,两者原来的invoker 对象,都由builder#buildInvokerChain 做了一层包装。
来看一下filterChain 的逻辑
public <T> Invoker<T> buildInvokerChain(final Invoker<T> originalInvoker, String key, String group) {
Invoker<T> last = originalInvoker;
URL url = originalInvoker.getUrl();
//......(省略部分代码)
if (!CollectionUtils.isEmpty(filters)) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new CopyOfFilterChainNode<>(originalInvoker, next, filter);
}
return new CallbackRegistrationInvoker<>(last, filters);
}
return last;
}逻辑较为简单:
1、所有filter 包装进invoker 对象中,invoke 方法直接调对应的filter#invoke。
2、filter 对象首尾相联,前一个filter#invoke 参数,传入后一个filter 的invoker对象
3、最后一个filter.invoke 参数中,直接传原始的invoker 对象
4、filter 的所有获取,按扩展点方式得到
ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
所以这里创建RpcInvocation,执行invoke方法,中间会经过一系列过滤器filter#invoke后,就会来到FailoverClusterInvoker#invoke方法中。
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
RpcInvocation rpcInvocation = new RpcInvocation(serviceModel, method, invoker.getInterface().getName(), protocolServiceKey, args);
String serviceKey = url.getServiceKey();
rpcInvocation.setTargetServiceUniqueName(serviceKey);
// invoker.getUrl() returns consumer url.
RpcServiceContext.setRpcContext(url);
if (serviceModel instanceof ConsumerModel) {
rpcInvocation.put(Constants.CONSUMER_MODEL, serviceModel);
rpcInvocation.put(Constants.METHOD_MODEL, ((ConsumerModel) serviceModel).getMethodModel(method));
}
if (ProfilerSwitch.isEnableSimpleProfiler()) {
ProfilerEntry parentProfiler = Profiler.getBizProfiler();
ProfilerEntry bizProfiler;
boolean containsBizProfiler = false;
if (parentProfiler != null) {
containsBizProfiler = true;
bizProfiler = Profiler.enter(parentProfiler, "Receive request. Client invoke begin.");
} else {
bizProfiler = Profiler.start("Receive request. Client invoke begin.");
}
rpcInvocation.put(Profiler.PROFILER_KEY, bizProfiler);
try {
return invoker.invoke(rpcInvocation).recreate();
} finally {
Profiler.release(bizProfiler);
if (!containsBizProfiler) {
int timeout;
Object timeoutKey = rpcInvocation.getObjectAttachmentWithoutConvert(TIMEOUT_KEY);
if (timeoutKey instanceof Integer) {
timeout = (Integer) timeoutKey;
} else {
timeout = url.getMethodPositiveParameter(methodName, TIMEOUT_KEY, DEFAULT_TIMEOUT);
}
long usage = bizProfiler.getEndTime() - bizProfiler.getStartTime();
if ((usage / (1000_000L * ProfilerSwitch.getWarnPercent())) > timeout) {
StringBuilder attachment = new StringBuilder();
for (Map.Entry<String, Object> entry : rpcInvocation.getObjectAttachments().entrySet()) {
attachment.append(entry.getKey()).append("=").append(entry.getValue()).append(";\n");
}
logger.warn(String.format("[Dubbo-Consumer] execute service %s#%s cost %d.%06d ms, this invocation almost (maybe already) timeout\n" +
"invocation context:\n%s" +
"thread info: \n%s",
protocolServiceKey, methodName, usage / 1000_000, usage % 1000_000,
attachment, Profiler.buildDetail(bizProfiler)));
}
}
}
}
return invoker.invoke(rpcInvocation).recreate();
}下面代码主要做了三件事情:
1、List<Invoker<T>> invokers = list(invocation);获取当前服务可执行的所有invokers数量。
2、LoadBalance loadbalance = initLoadBalance(invokers, invocation);利用SPI机制获取当前负载均衡策略LoadBalance。
3、doInvoke(invocation, invokers, loadbalance)。负载均衡策略会选择出一个invoker然后执行。
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Router route.");
List<Invoker<T>> invokers = list(invocation);
InvocationProfilerUtils.releaseDetailProfiler(invocation);
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
InvocationProfilerUtils.enterDetailProfiler(invocation, () -> "Cluster " + this.getClass().getName() + " invoke.");
try {
return doInvoke(invocation, invokers, loadbalance);
} finally {
InvocationProfilerUtils.releaseDetailProfiler(invocation);
}
}我们知道一个服务的invokers都存在了registryDirectory中
protected List<Invoker<T>> list(Invocation invocation) throws RpcException {
return getDirectory().list(invocation);
}
public List<Invoker<T>> list(Invocation invocation) throws RpcException {
if (destroyed) {
throw new RpcException("Directory already destroyed .url: " + getUrl());
}
BitList<Invoker<T>> availableInvokers;
// use clone to avoid being modified at doList().
if (invokersInitialized) {
availableInvokers = validInvokers.clone();
} else {
availableInvokers = invokers.clone();
}
List<Invoker<T>> routedResult = doList(availableInvokers, invocation);
return Collections.unmodifiableList(routedResult);
}然后回利用路由规则调用routerChain.route方法,路由出正确的invokers,具体路由功能后面再讲解。
public List<Invoker<T>> doList(BitList<Invoker<T>> invokers, Invocation invocation) {
if (forbidden && shouldFailFast) {
// 1. No service provider 2. Service providers are disabled
throw new RpcException(RpcException.FORBIDDEN_EXCEPTION, "No provider available from registry " +
getUrl().getAddress() + " for service " + getConsumerUrl().getServiceKey() + " on consumer " +
NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() +
", please check status of providers(disabled, not registered or in blacklist).");
}
if (multiGroup) {
return this.getInvokers();
}
try {
// Get invokers from cache, only runtime routers will be executed.
List<Invoker<T>> result = routerChain.route(getConsumerUrl(), invokers, invocation);
return result == null ? BitList.emptyList() : result;
} catch (Throwable t) {
logger.error("Failed to execute router: " + getUrl() + ", cause: " + t.getMessage(), t);
return BitList.emptyList();
}
}三、负载均衡
下面这行代码会获取到当前配置的负载均衡策略
LoadBalance loadbalance = initLoadBalance(invokers, invocation)
最终也是利用SPI机制加载,ExtensionLoader#getExtension(DEFAULT_LOADBALANCE) ,而默认的负载均衡策略可以看到是随机。
protected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) {
ApplicationModel applicationModel = ScopeModelUtil.getApplicationModel(invocation.getModuleModel());
if (CollectionUtils.isNotEmpty(invokers)) {
return applicationModel.getExtensionLoader(LoadBalance.class).getExtension(
invokers.get(0).getUrl().getMethodParameter(
RpcUtils.getMethodName(invocation), LOADBALANCE_KEY, DEFAULT_LOADBALANCE
)
);
} else {
return applicationModel.getExtensionLoader(LoadBalance.class).getExtension(DEFAULT_LOADBALANCE);
}
}
然后继续执行来到FailoverClusterInvoker#doInvoke方法,首先获取执行次数for循环进行调用,只要不是正常返回,就再试一次,默认的len为3次,这也是dubbo基础常识,在这里可以体现出来。
然后调用下面的select方法获取到一个invoker,最终会执行到loadBalance#doSelect方法,当然不同的负载均衡策略获取invoker的算法也不同,这里应用了模板模式。
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
int len = calculateInvokeTimes(methodName);
// retry loop.
RpcException le = null; // last exception.
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
for (int i = 0; i < len; i++) {
//Reselect before retry to avoid a change of candidate `invokers`.
//NOTE: if `invokers` changed, then `invoked` also lose accuracy.
if (i > 0) {
checkWhetherDestroyed();
copyInvokers = list(invocation);
// check again
checkInvokers(copyInvokers, invocation);
}
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
RpcContext.getServiceContext().setInvokers((List) invoked);
boolean success = false;
try {
Result result = invokeWithContext(invoker, invocation);
if (le != null && logger.isWarnEnabled()) {
logger.warn("Although retry the method " + methodName
+ " in the service " + getInterface().getName()
+ " was successful by the provider " + invoker.getUrl().getAddress()
+ ", but there have been failed providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost()
+ " using the dubbo version " + Version.getVersion() + ". Last error is: "
+ le.getMessage(), le);
}
success = true;
return result;
} catch (RpcException e) {
if (e.isBiz()) { // biz exception.
throw e;
}
le = e;
} catch (Throwable e) {
le = new RpcException(e.getMessage(), e);
} finally {
if (!success) {
providers.add(invoker.getUrl().getAddress());
}
}
}
throw new RpcException(le.getCode(), "Failed to invoke the method "
+ methodName + " in the service " + getInterface().getName()
+ ". Tried " + len + " times of the providers " + providers
+ " (" + providers.size() + "/" + copyInvokers.size()
+ ") from the registry " + directory.getUrl().getAddress()
+ " on the consumer " + NetUtils.getLocalHost() + " using the dubbo version "
+ Version.getVersion() + ". Last error is: "
+ le.getMessage(), le.getCause() != null ? le.getCause() : le);
}RandomLoadBalance#doSelect方法,具体代码逻辑不做详细解释,主要是根据服务设置的权重进行随机选取,权重大的被选中的概率就会大一点,有兴趣的可以断点研究下,这里只是让大家了解负载均衡就是这么简单的东西,我们也可以创建一个自己的负载均衡策略,只需要继承AbstractLoadBalance并实现自己的doSelect方法,然后还需要配置指定用我们所写的负载均衡策略,从代码流程上可以看出来,dubbo的负载均衡策略其实是客户端负载均衡。
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
if (!needWeightLoadBalance(invokers,invocation)){
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
// Every invoker has the same weight?
boolean sameWeight = true;
// the maxWeight of every invokers, the minWeight = 0 or the maxWeight of the last invoker
int[] weights = new int[length];
// The sum of weights
int totalWeight = 0;
for (int i = 0; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
// Sum
totalWeight += weight;
// save for later use
weights[i] = totalWeight;
if (sameWeight && totalWeight != weight * (i + 1)) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
if (offset < weights[i]) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}那么dubbo中已经支持的负载均衡策略也有很多,依次是ConsistentHashLoadBalance(一次性哈希),LeastActiveLoadBalance(最少活跃数),RandomLoadBalance(按照权重随机),RoundRobinLoadBalance(轮训),ShortestResponseLoadBalance(最短响应策略);不过生产环境中权重策略跟轮训策略是使用的最多的两种负载均衡方式。
四、集群容错
集群容错的实现方式其实在生成invoker的时候已经看到了,dubbo会将生成的invoker最外层在包装一层ClusterInvoker,这里又利用到了一种设计模式叫做装饰者模式。因为远程服务调用过程总肯定会先执行到ClusterInvoker#doInvoke方法,那么每个容错ClusterInvoker实现类会按照自己的方式去执行,当然我们也能继承AbstractClusterInvoker方法,然后实现doInvoke方法,然后配置自己的集群容错策略,所以这个功能跟负载均衡一样简单。
Dubbo为应对不同的业务场景和需求,提供了以下几种集群容错策略,具体源码有兴趣的可以单独研究:
1. FailoverClusterInvoker(默认)
失败一次自动切换,自动重试其他invoker,默认三次。适用于读操作多、对实时性要求不高的场景。
2. Failfast
快速失败,立即报错,只发起一次调用。适用于非幂等性操作或实时性要求极高的场景。
3. Failsafe
失败安全,出现异常时直接忽略。适用于对结果不敏感的操作,如日志记录。
4. Failback
失败自动恢复,记录失败请求,定时重发。适用于可以异步处理且对实时性要求不高的操作。
5. Forking
并行调用多个服务器,只要一个成功即返回。注意提高响应速度的同时,需注意资源消耗和并行度控制。
6. Broadcast
广播调用所有服务提供者,任一报错即报错。适用于需要全局一致性的场景,如全局缓存更新。
选择合适的集群容错策略,对于优化Dubbo应用的性能和可靠性至关重要。
到此Dubbo的服务调用过程讲解完毕。