并发下载器开发实战教程
一、系统设计概述
1.1 功能需求表
| 功能模块 | 描述 | 技术要点 |
|---|---|---|
| 分片下载 | 将大文件分成多个小块并发下载 | goroutine池、分片算法 |
| 断点续传 | 支持下载中断后继续下载 | 文件指针定位、临时文件管理 |
| 进度显示 | 实时显示下载进度和速度 | 进度计算、速度统计 |
| 错误处理 | 处理下载过程中的各种错误 | 错误类型定义、重试机制 |
| 文件合并 | 将下载的分片合并成完整文件 | 文件操作、数据校验 |
1.2 核心结构设计
// 下载任务结构
type DownloadTask struct {
URL string
TargetPath string
TotalSize int64
ChunkSize int64
Chunks []*Chunk
Progress *Progress
ErrorHandler *ErrorHandler
Concurrency int
RetryTimes int
RetryInterval time.Duration
}
// 分片信息
type Chunk struct {
ID int
Start int64
End int64
Downloaded int64
Status ChunkStatus
TempFilePath string
}
// 进度信息
type Progress struct {
TotalSize int64
Downloaded int64
Speed float64
Percentage float64
LastUpdate time.Time
StatusChannel chan StatusUpdate
}
// 错误处理器
type ErrorHandler struct {
RetryTimes int
RetryInterval time.Duration
Errors chan error
ErrorLog *log.Logger
}
二、核心代码实现
2.1 主程序入口
package main
import (
"fmt"
"log"
"os"
"time"
)
func main() {
// 创建下载任务
task := &DownloadTask{
URL: "https://example.com/largefile.zip",
TargetPath: "largefile.zip",
Concurrency: 5,
RetryTimes: 3,
RetryInterval: time.Second * 5,
}
// 初始化下载器
downloader := NewDownloader(task)
// 开始下载
err := downloader.Start()
if err != nil {
log.Fatal(err)
}
}
// NewDownloader 创建新的下载器实例
func NewDownloader(task *DownloadTask) *Downloader {
return &Downloader{
task: task,
progress: NewProgress(),
errorHandler: NewErrorHandler(task.RetryTimes, task.RetryInterval),
}
}
2.2 分片下载实现
// 分片管理
func (d *Downloader) splitTask() error {
// 获取文件大小
totalSize, err := d.getFileSize()
if err != nil {
return err
}
d.task.TotalSize = totalSize
// 计算分片大小
chunkSize := d.calculateChunkSize(totalSize)
d.task.ChunkSize = chunkSize
// 创建分片
var chunks []*Chunk
for i := 0; i < d.calculateChunkCount(); i++ {
start := int64(i) * chunkSize
end := start + chunkSize - 1
if i == d.calculateChunkCount()-1 {
end = totalSize - 1
}
chunk := &Chunk{
ID: i,
Start: start,
End: end,
Status: ChunkStatusPending,
TempFilePath: fmt.Sprintf("%s.part%d", d.task.TargetPath, i),
}
chunks = append(chunks, chunk)
}
d.task.Chunks = chunks
return nil
}
// 下载单个分片
func (d *Downloader) downloadChunk(chunk *Chunk) error {
client := &http.Client{}
req, err := http.NewRequest("GET", d.task.URL, nil)
if err != nil {
return err
}
// 设置Range头部
req.Header.Set("Range", fmt.Sprintf("bytes=%d-%d", chunk.Start, chunk.End))
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
// 创建临时文件
tmpFile, err := os.Create(chunk.TempFilePath)
if err != nil {
return err
}
defer tmpFile.Close()
// 写入数据并更新进度
buffer := make([]byte, 32*1024)
for {
n, err := resp.Body.Read(buffer)
if n > 0 {
tmpFile.Write(buffer[:n])
chunk.Downloaded += int64(n)
d.updateProgress(int64(n))
}
if err != nil {
if err == io.EOF {
break
}
return err
}
}
chunk.Status = ChunkStatusCompleted
return nil
}
2.3 进度监控实现
// 进度管理器
type Progress struct {
mu sync.Mutex
downloaded int64
totalSize int64
startTime time.Time
lastUpdate time.Time
speedSamples []float64
statusChannel chan StatusUpdate
}
// 更新进度
func (p *Progress) Update(n int64) {
p.mu.Lock()
defer p.mu.Unlock()
p.downloaded += n
now := time.Now()
duration := now.Sub(p.lastUpdate).Seconds()
if duration >= 1.0 {
speed := float64(n) / duration
p.speedSamples = append(p.speedSamples, speed)
if len(p.speedSamples) > 10 {
p.speedSamples = p.speedSamples[1:]
}
p.lastUpdate = now
// 计算平均速度
var avgSpeed float64
for _, s := range p.speedSamples {
avgSpeed += s
}
avgSpeed /= float64(len(p.speedSamples))
// 发送状态更新
p.statusChannel <- StatusUpdate{
Downloaded: p.downloaded,
TotalSize: p.totalSize,
Speed: avgSpeed,
Percentage: float64(p.downloaded) / float64(p.totalSize) * 100,
}
}
}
// 显示进度
func (p *Progress) displayProgress() {
for status := range p.statusChannel {
fmt.Printf("\rProgress: %.2f%% Speed: %.2f MB/s",
status.Percentage,
status.Speed/1024/1024)
}
}
2.4 错误处理实现
// 错误处理器
type ErrorHandler struct {
retryTimes int
retryInterval time.Duration
errors chan error
errorLog *log.Logger
}
// 错误重试
func (eh *ErrorHandler) RetryDownload(chunk *Chunk, downloadFunc func(*Chunk) error) error {
var lastErr error
for i := 0; i < eh.retryTimes; i++ {
err := downloadFunc(chunk)
if err == nil {
return nil
}
lastErr = err
eh.logError(fmt.Sprintf("Chunk %d download failed: %v, retry %d/%d",
chunk.ID, err, i+1, eh.retryTimes))
time.Sleep(eh.retryInterval)
}
return fmt.Errorf("max retry times reached: %v", lastErr)
}
// 错误日志记录
func (eh *ErrorHandler) logError(msg string) {
eh.errorLog.Println(msg)
}
2.5 完整下载管理器
// Downloader 主程序流程
func (d *Downloader) Start() error {
// 1. 切分任务
if err := d.splitTask(); err != nil {
return err
}
// 2. 创建工作池
workPool := make(chan *Chunk, d.task.Concurrency)
var wg sync.WaitGroup
// 3. 启动工作协程
for i := 0; i < d.task.Concurrency; i++ {
wg.Add(1)
go func() {
defer wg.Done()
for chunk := range workPool {
err := d.errorHandler.RetryDownload(chunk, d.downloadChunk)
if err != nil {
d.errorHandler.errors <- err
}
}
}()
}
// 4. 分发任务
go func() {
for _, chunk := range d.task.Chunks {
workPool <- chunk
}
close(workPool)
}()
// 5. 启动进度显示
go d.progress.displayProgress()
// 6. 等待所有下载完成
wg.Wait()
// 7. 合并文件
return d.mergeChunks()
}
// 合并分片文件
func (d *Downloader) mergeChunks() error {
targetFile, err := os.Create(d.task.TargetPath)
if err != nil {
return err
}
defer targetFile.Close()
for _, chunk := range d.task.Chunks {
chunkFile, err := os.Open(chunk.TempFilePath)
if err != nil {
return err
}
_, err = io.Copy(targetFile, chunkFile)
chunkFile.Close()
os.Remove(chunk.TempFilePath)
if err != nil {
return err
}
}
return nil
}
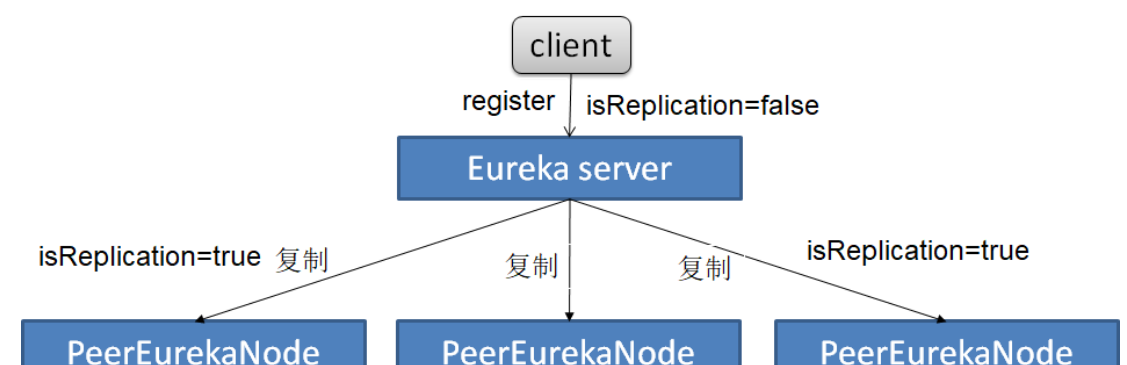
三、系统流程图
添加一个流程图来说明下载器的工作流程:

让我们再添加一个并发控制的状态图:

这个并发下载器的实现包含了以下核心特点:
-
分片下载设计
- 根据文件大小自动计算合适的分片大小
- 支持断点续传
- 临时文件管理
- 分片合并校验
-
goroutine协作
- 使用工作池控制并发数
- 协程间通信采用channel
- 优雅的协程退出机制
- 资源释放保证
-
进度监控
- 实时速度计算
- 平均速度统计
- 进度百分比显示
- 状态更新通知
好的,让我继续完成错误处理部分和补充其他重要内容:
- 错误处理
- 完整的重试机制
- 错误日志记录
- 错误类型分类
- 优雅降级策略
接下来补充一些重要的实现代码:
package main
import (
"context"
"fmt"
"io"
"log"
"net/http"
"os"
"sync"
"time"
)
// 错误类型定义
type DownloadError struct {
ChunkID int
Err error
Retried int
}
func (e *DownloadError) Error() string {
return fmt.Sprintf("chunk %d download failed: %v (retried: %d times)",
e.ChunkID, e.Err, e.Retried)
}
// 状态更新结构
type StatusUpdate struct {
ChunkID int
Downloaded int64
Speed float64
Error error
}
// 下载管理器
type Downloader struct {
ctx context.Context
cancel context.CancelFunc
task *DownloadTask
progress *Progress
errorHandler *ErrorHandler
wg sync.WaitGroup
}
// 创建新的下载管理器
func NewDownloader(task *DownloadTask) *Downloader {
ctx, cancel := context.WithCancel(context.Background())
return &Downloader{
ctx: ctx,
cancel: cancel,
task: task,
progress: NewProgress(task.TotalSize),
errorHandler: NewErrorHandler(task.RetryTimes, task.RetryInterval),
}
}
// 下载器核心实现
func (d *Downloader) Start() error {
// 1. 准备工作
if err := d.prepare(); err != nil {
return fmt.Errorf("preparation failed: %v", err)
}
// 2. 创建工作池
workChan := make(chan *Chunk, d.task.Concurrency)
statusChan := make(chan StatusUpdate, d.task.Concurrency)
// 3. 启动工作协程
for i := 0; i < d.task.Concurrency; i++ {
d.wg.Add(1)
go d.worker(workChan, statusChan)
}
// 4. 启动状态监控
go d.monitorStatus(statusChan)
// 5. 分发任务
for _, chunk := range d.task.Chunks {
select {
case workChan <- chunk:
case <-d.ctx.Done():
return fmt.Errorf("download cancelled")
}
}
// 6. 关闭工作通道
close(workChan)
// 7. 等待所有工作完成
d.wg.Wait()
// 8. 检查是否有错误发生
if err := d.errorHandler.GetFatalError(); err != nil {
return err
}
// 9. 合并文件
return d.mergeChunks()
}
// 工作协程
func (d *Downloader) worker(workChan <-chan *Chunk, statusChan chan<- StatusUpdate) {
defer d.wg.Done()
for chunk := range workChan {
err := d.downloadChunkWithRetry(chunk)
if err != nil {
statusChan <- StatusUpdate{
ChunkID: chunk.ID,
Error: err,
}
continue
}
statusChan <- StatusUpdate{
ChunkID: chunk.ID,
Downloaded: chunk.End - chunk.Start + 1,
}
}
}
// 带重试的分片下载
func (d *Downloader) downloadChunkWithRetry(chunk *Chunk) error {
retries := 0
for retries <= d.task.RetryTimes {
err := d.downloadChunk(chunk)
if err == nil {
return nil
}
retries++
if retries > d.task.RetryTimes {
return &DownloadError{
ChunkID: chunk.ID,
Err: err,
Retried: retries - 1,
}
}
// 记录重试日志
log.Printf("Chunk %d download failed: %v, retrying (%d/%d)...",
chunk.ID, err, retries, d.task.RetryTimes)
// 等待重试间隔
select {
case <-time.After(d.task.RetryInterval):
case <-d.ctx.Done():
return fmt.Errorf("download cancelled during retry")
}
}
return nil
}
// 优化的分片下载实现
func (d *Downloader) downloadChunk(chunk *Chunk) error {
// 创建HTTP请求
req, err := http.NewRequestWithContext(d.ctx, "GET", d.task.URL, nil)
if err != nil {
return err
}
// 设置Range头
req.Header.Set("Range", fmt.Sprintf("bytes=%d-%d", chunk.Start+chunk.Downloaded, chunk.End))
// 发送请求
resp, err := http.DefaultClient.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
// 检查响应状态
if resp.StatusCode != http.StatusPartialContent {
return fmt.Errorf("unexpected status code: %d", resp.StatusCode)
}
// 打开或创建临时文件
f, err := os.OpenFile(chunk.TempFilePath, os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
return err
}
defer f.Close()
// 设置写入位置
if _, err := f.Seek(chunk.Downloaded, io.SeekStart); err != nil {
return err
}
// 创建带缓冲的写入器
bufWriter := bufio.NewWriter(f)
defer bufWriter.Flush()
// 下载数据
buffer := make([]byte, 32*1024)
for {
select {
case <-d.ctx.Done():
return fmt.Errorf("download cancelled")
default:
n, err := resp.Body.Read(buffer)
if n > 0 {
// 写入数据
if _, err := bufWriter.Write(buffer[:n]); err != nil {
return err
}
// 更新进度
chunk.Downloaded += int64(n)
d.progress.Update(int64(n))
}
if err == io.EOF {
return nil
}
if err != nil {
return err
}
}
}
}
// 状态监控
func (d *Downloader) monitorStatus(statusChan <-chan StatusUpdate) {
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for {
select {
case status := <-statusChan:
if status.Error != nil {
d.errorHandler.HandleError(status.Error)
continue
}
d.progress.Update(status.Downloaded)
case <-ticker.C:
d.displayProgress()
case <-d.ctx.Done():
return
}
}
}
// 显示下载进度
func (d *Downloader) displayProgress() {
status := d.progress.GetStatus()
fmt.Printf("\rProgress: %.2f%% Speed: %.2f MB/s",
status.Percentage,
status.Speed/1024/1024)
}
// 优化的文件合并实现
func (d *Downloader) mergeChunks() error {
// 创建目标文件
targetFile, err := os.Create(d.task.TargetPath)
if err != nil {
return err
}
defer targetFile.Close()
// 使用bufio提升写入性能
bufWriter := bufio.NewWriter(targetFile)
defer bufWriter.Flush()
// 合并所有分片
for _, chunk := range d.task.Chunks {
// 打开分片文件
chunkFile, err := os.Open(chunk.TempFilePath)
if err != nil {
return err
}
// 使用bufio提升读取性能
bufReader := bufio.NewReader(chunkFile)
// 复制数据
_, err = io.Copy(bufWriter, bufReader)
chunkFile.Close()
// 删除临时文件
os.Remove(chunk.TempFilePath)
if err != nil {
return fmt.Errorf("failed to merge chunk %d: %v", chunk.ID, err)
}
}
return nil
}
func main() {
// 创建下载任务
task := &DownloadTask{
URL: "https://example.com/largefile.zip",
TargetPath: "largefile.zip",
Concurrency: 5,
RetryTimes: 3,
RetryInterval: time.Second * 5,
ChunkSize: 1024 * 1024 * 10, // 10MB per chunk
}
// 创建下载器
downloader := NewDownloader(task)
// 开始下载
if err := downloader.Start(); err != nil {
log.Fatal(err)
}
fmt.Println("\nDownload completed successfully!")
}
并发下载器的性能优化建议表:
| 优化方向 | 具体措施 | 预期效果 |
|---|---|---|
| 并发控制 | 根据系统资源调整并发数 | 避免资源竞争,提高整体性能 |
| 内存使用 | 使用固定大小的缓冲区 | 减少内存分配,避免GC压力 |
| IO操作 | 使用bufio进行缓冲IO | 减少系统调用,提高IO效率 |
| 错误处理 | 实现智能重试机制 | 提高下载成功率 |
| 进度计算 | 批量更新进度 | 减少锁竞争,提高并发效率 |
核心优化要点:
-
分片策略优化
- 动态调整分片大小
- 考虑网络状况
- 考虑文件大小
- 优化分片合并
-
内存管理优化
- 使用对象池
- 控制缓冲区大小
- 及时释放资源
- 避免内存泄漏
-
并发控制优化
- 动态调整goroutine数量
- 使用环形缓冲区
- 实现背压机制
- 优化锁策略
-
IO性能优化
- 使用bufio
- 适当的buffer大小
- 批量写入
- 减少系统调用
使用建议:
-
根据实际需求调整参数
- 并发数
- 分片大小
- 缓冲区大小
- 重试策略
-
监控关键指标
- CPU使用率
- 内存占用
- 磁盘IO
- 网络带宽
-
做好错误处理
- 完整的日志记录
- 合理的重试策略
- 优雅的降级处理
- 用户友好的错误提示
-
进行充分测试
- 单元测试
- 性能测试
- 压力测试
- 异常场景测试
这个并发下载器的实现考虑了实际应用中的各种场景,包括:
- 网络不稳定
- 断点续传需求
- 大文件处理
- 资源限制
- 错误恢复
- 性能优化
通过这些特性和优化,可以实现一个稳定高效的文件下载器。
怎么样今天的内容还满意吗?再次感谢观众老爷的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!








![通过IIC访问模块寄存器[ESP--1]](https://i-blog.csdnimg.cn/direct/2fa44fa6dbb847ab8cde68f6b1da1b96.png)