大数据挖掘
数据挖掘
数据挖掘定义
技术层面:
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又==潜在有用的信息==的过程。
数据准备环节
数据选择 质量分析 数据预处理
数据仓库
从多个数据源搜集的信息存放在一致的模式之下
特征化
对目标数据的一般特性和特征汇总
聚类分析
最大化类内相似度 最小化类间相似性
数据准备
大数据定义
超出正常处理范围
由海量数据+复杂类型的数据 构成
数据对象
组成数据集的元素,每个数据对象均为一个实体
数据对象由属性描述
数据的正确性分析
缺失值
数据错误
度量标准错误
编码不一致
处理缺失数据
忽视
较小缺失率 有缺失值的样本或属性
人工补全缺失值
重新采样
领域知识
自动补全缺失值
固定值
均值
基于算法
插补法
均值插补
回归插补
极大似然估计
噪声过滤
回归法
均值平滑法
离群点分析
处理噪声数据
局部离群因子LOF计算
数据量
子集选择
数据量太大
减小时间复杂度
数据聚合
尺度变换
数据更稳定
调整类分布
不平衡数据
哈尔小波交换
通过调整分辨率
数据标准化
最小最大标准化
Z-score标准化
大数据挖掘与分析
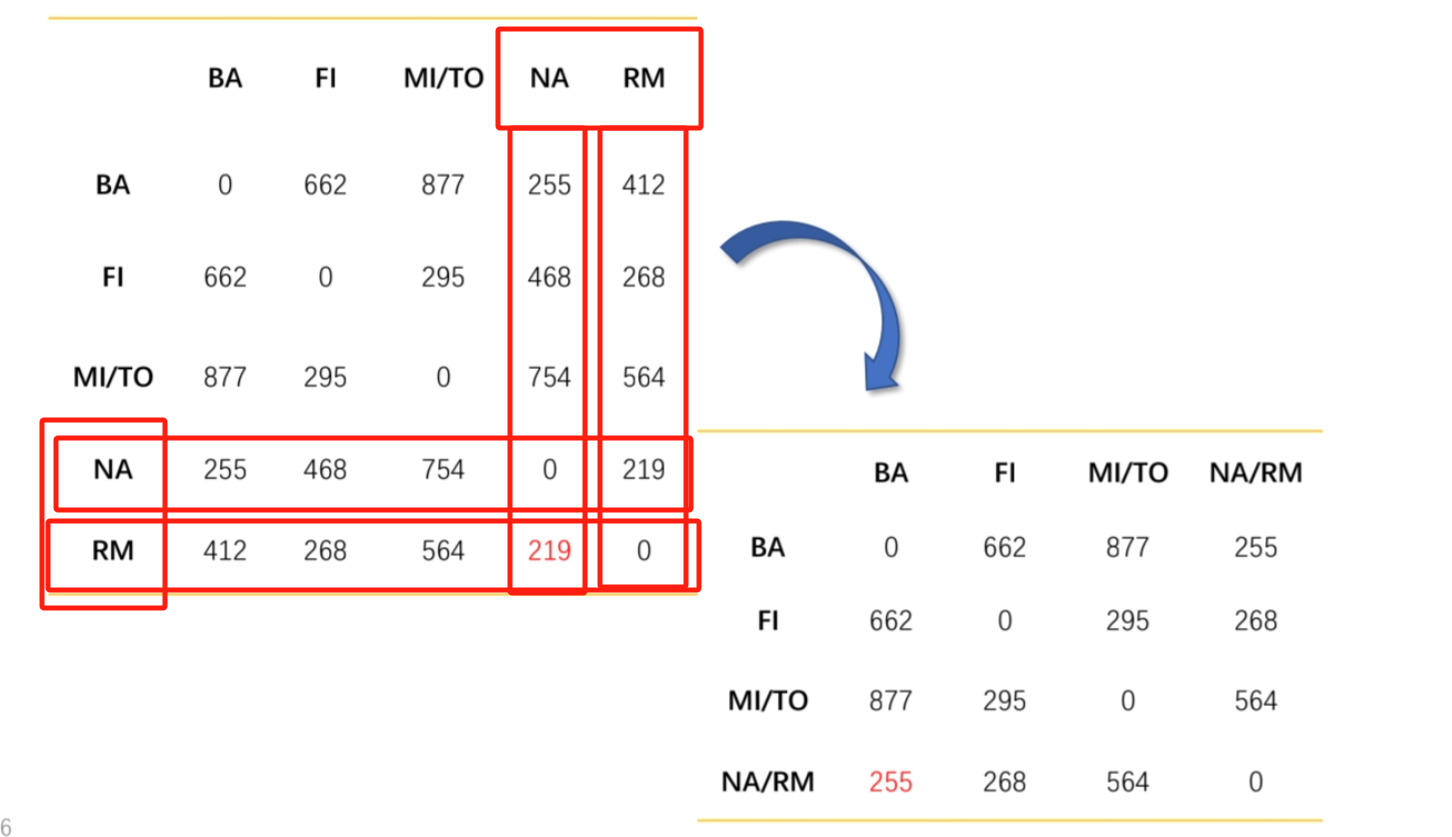
邻近性
相似性和相异性统称为邻近性
数据矩阵
存放数据对象
相异性矩阵
存放数据对象的相异性值
二元属性邻近性
数值数据距离
闵可夫斯基距离
h=1 2 正无穷
维度诅咒
基于距离的聚类在高纬度下无效
在高维情况下 P(0,1)更有效
逆文档频率
IDF 或 Goodall度量
基本思路:
将基本词汇看做全部属性的集合
每个词频是属性的值
余弦度量
余弦相似度
逆文档频率 阻尼系数
累计距离矩阵(大概率)
计算等图
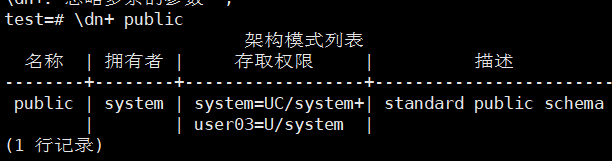
算法题目APRIORI
基本的Apriori算法
Apriori算法的基本思路是采用层次搜索的迭代方法,由候选(k-1)-项集来寻找候选k-项集,并逐一判断产生的候选k-项集是否是频繁的。
设C k 是长度为k的候选项集的集合,L k 是长度为k的频繁项集的集合。为了简单,设最小支持度阈值min_sup为最小元组数,即采用最小支持度计数。
输入:事务数据库D,最小支持度阈值min_sup。
输出:所有的频繁项集集合L。
方法:其过程描述如下:
通过扫描D得到1-频繁项集L1;
for (k=2;Lk-1!=Ф;k++)
{ Ck=由Lk-1通过连接运算产生的候选k-项集;
for (事务数据库D中的事务t)
{ 求Ck中包含在t中的所有候选k-项集的计数;
Lk={c | c∈Ck and c.sup_count≥min_sup};
//求Ck中满足min_sup的候选k-项集
}
}
return L=∪kLk;
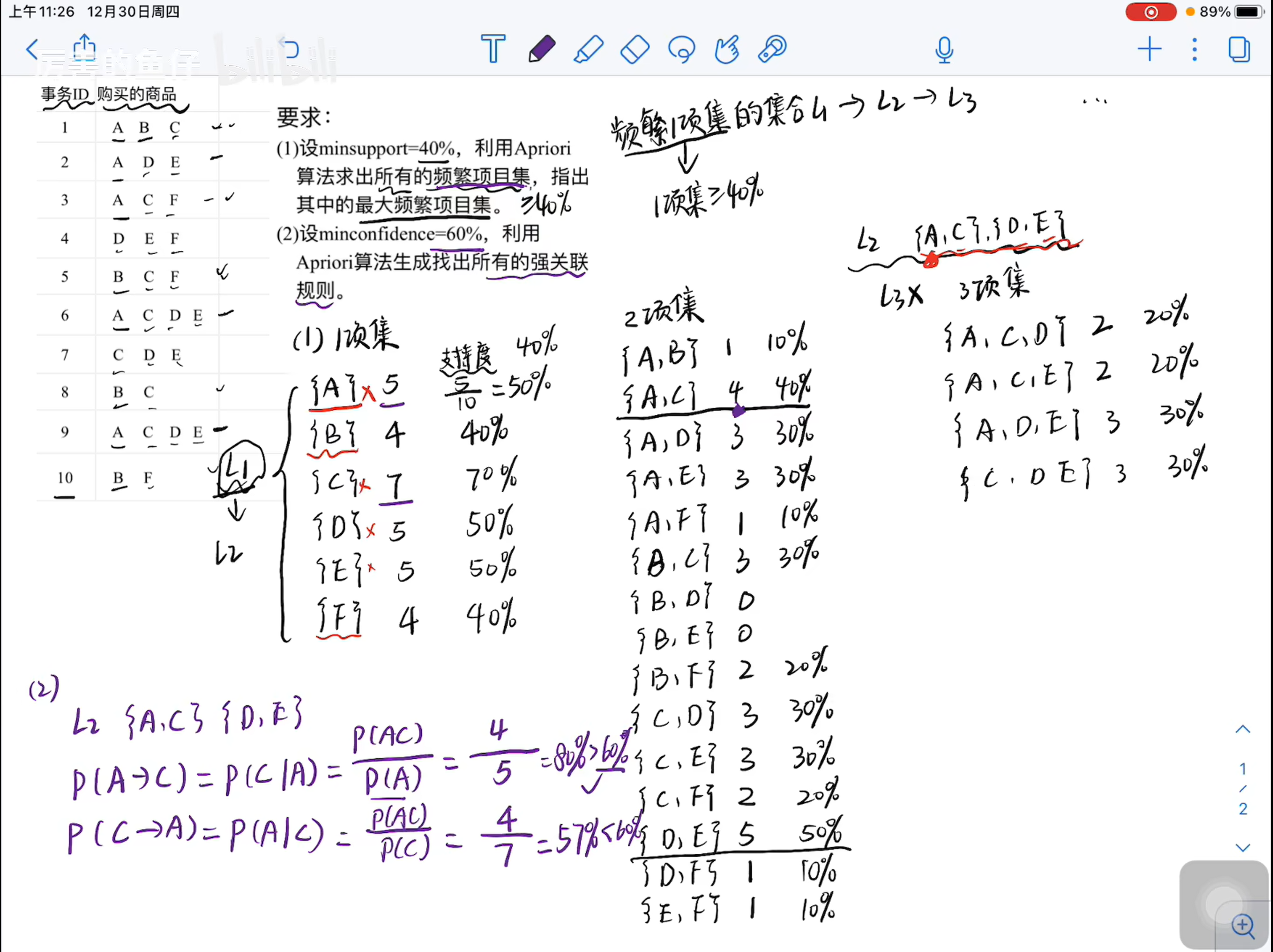
这是通过Apriori计算最大频繁项集 和 计算强关联规则的题目
要求为超过最小支持度 最小支持度的计算很简单
即为

Apriori优化
基于散列的Apriori
基于散列的Apriori技术基于Apriori算法, 为了解决此算法在数据集较大的情况下候选项集数量爆炸的问题 以及支持度计数效率低下的问题
基于散列的优化:
在生成候选项集时,通过哈希函数映射分桶 每个桶记录频数 如果桶中的频数小于最小支持度的阈值 则该桶中所有项集可以直接剪枝
因为通过哈希函数可以快速找到相应的桶,所以计算效率较高
h(x,y)=(hash(x)+hash(y))modn
哈希树分组
算法题目FPgrowth

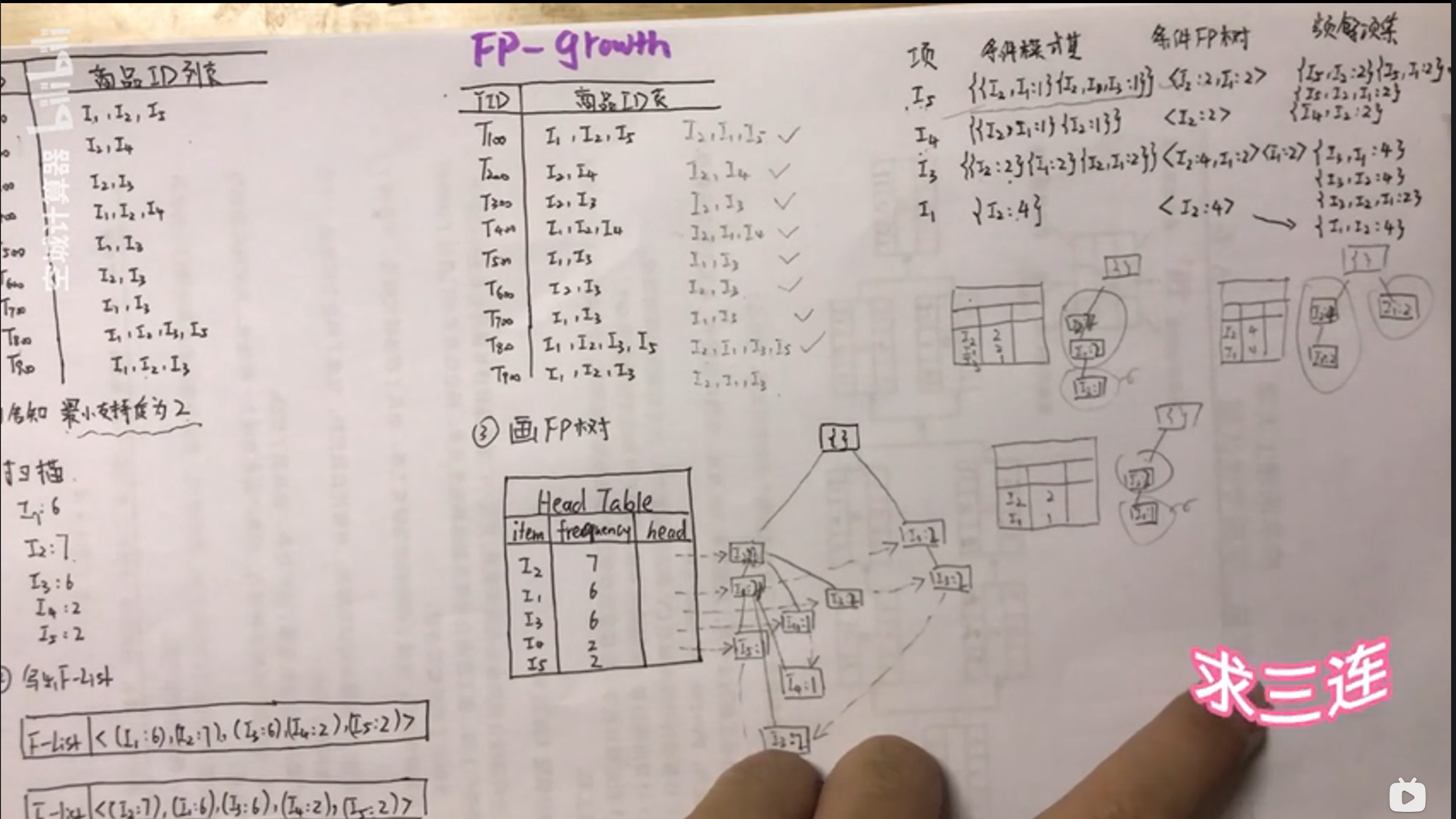
条件模式基的寻找
在FPtree的项目里倒着找,沿着虚线将出现的频次进行统计,,写出条件模式基
条件FP Tree
沿着条件模式基画FP Tree
记得剪去最小支持度不够的项
频繁项集
将条件FPtree与项进行组合 得到频繁项集
列式计数Apriori算法
使用垂直数据格式挖掘频繁项集
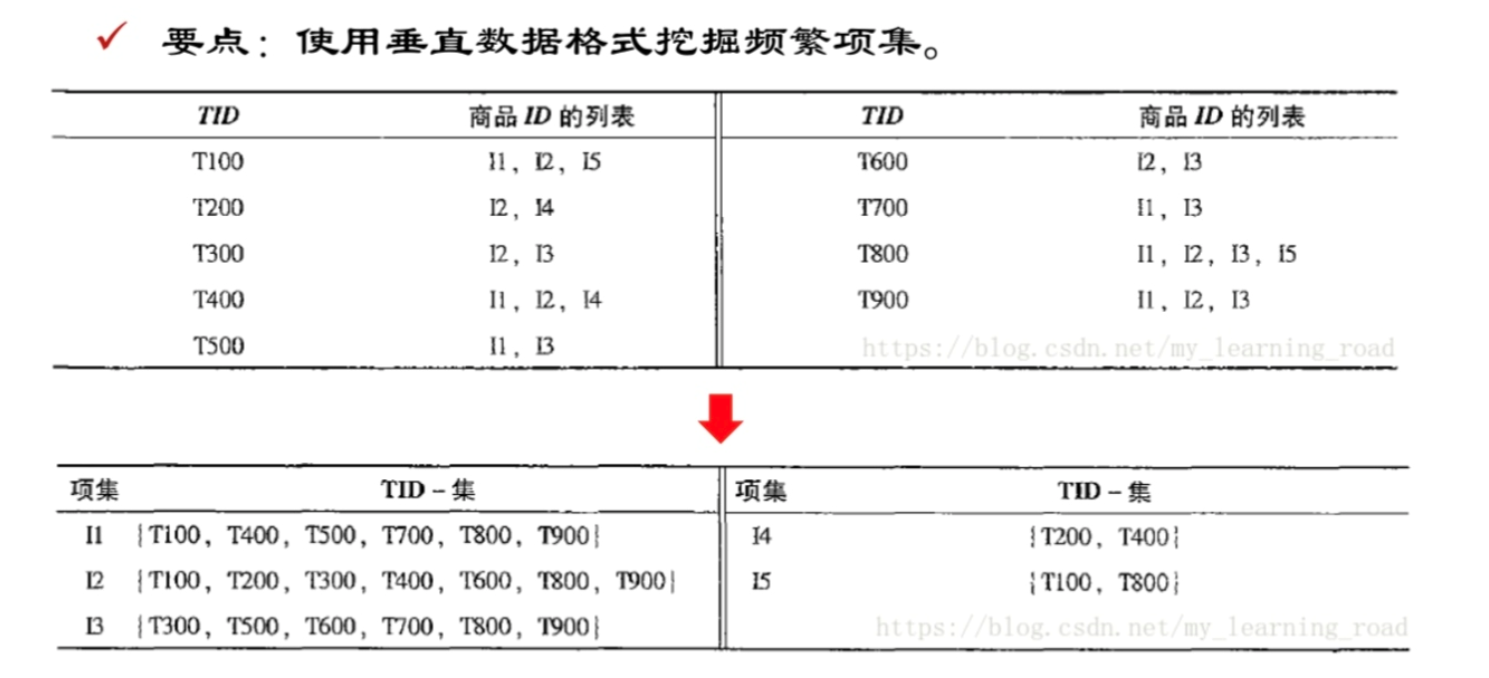
关联模式挖掘
超集
包含了另一个集合中所有元素的集合为超集
闭模式
一个频繁项集 没有任何它的超集具有与他相同的支持度
也就是不被冗余覆盖的核心模式
闭模式显著减少了需要存储的频繁模式数量
可以推导出所有频繁模式及其支持度
极大模式
没有频繁的超集
极大模式只保留频繁模式中“最大”的部分
无法还原所有频繁模式的支持度信息
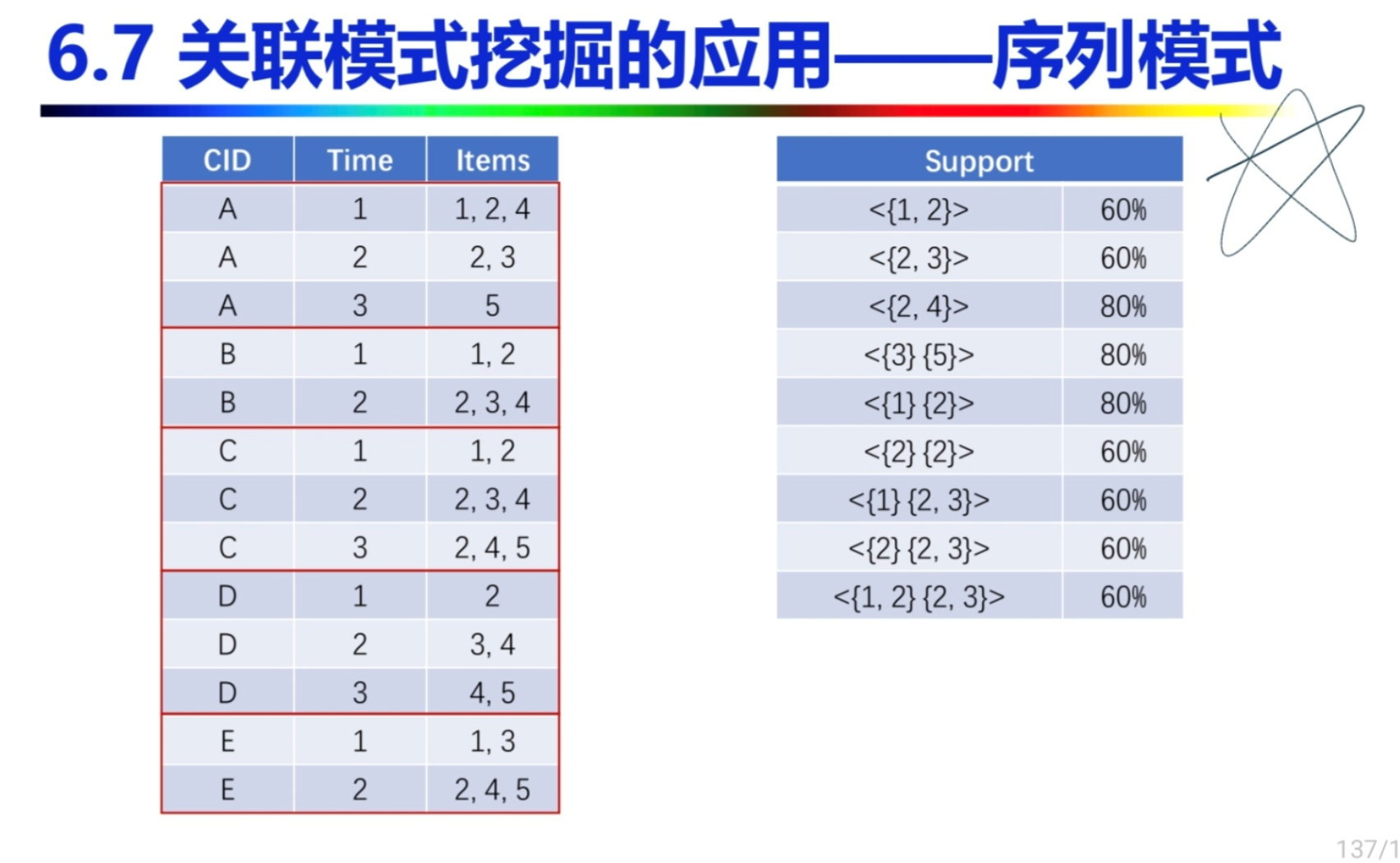
序列模式
序列模式是指诸如此类的模式,其项中包含多个项,在计数时,相同项仅计数一次
聚类
好的聚类方法产生高质量的聚类结果
要求
高类内相似性 高内聚
低类间相似性 低耦合
能够发掘隐藏模式 有价值
聚类的好坏在于:
相似度测量方法
不同尺度 不同类型的距离函数设计不同
主要聚类方法
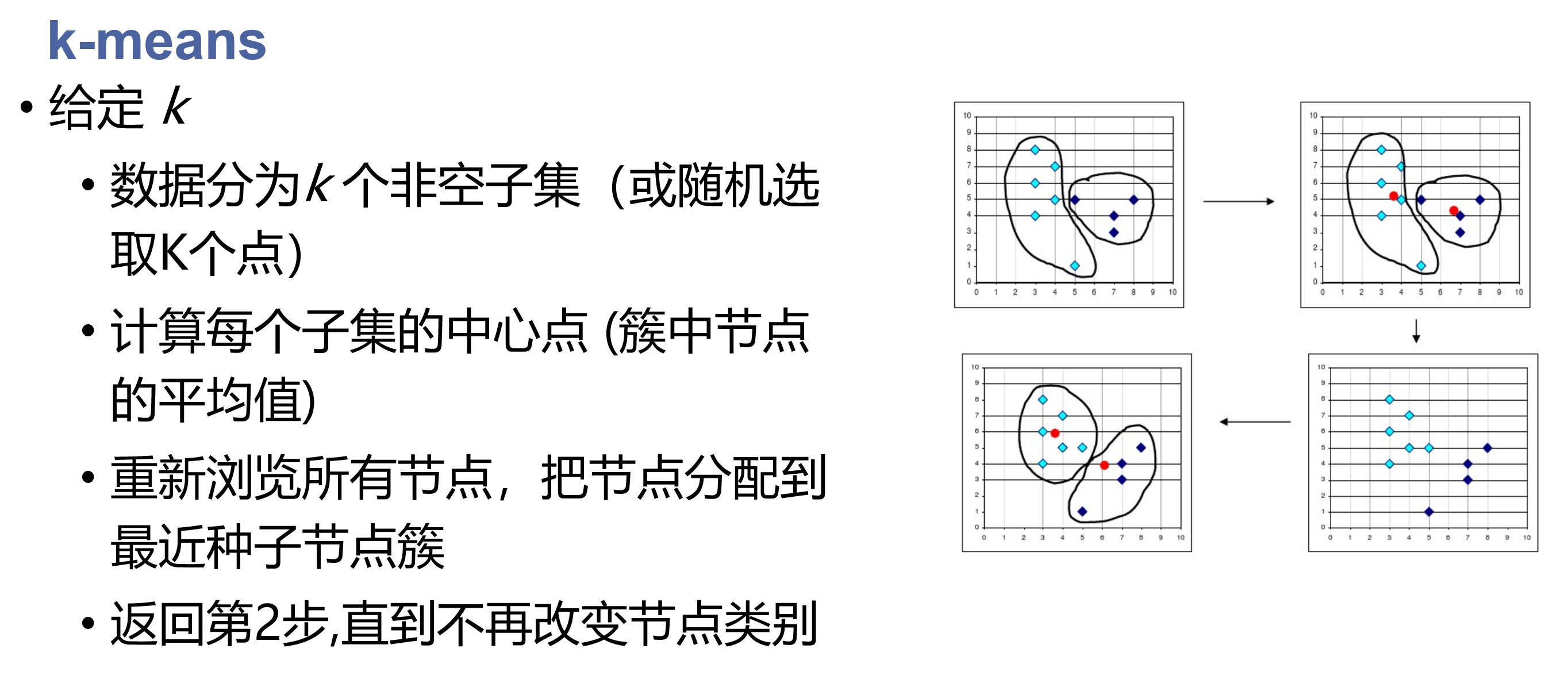
基于代表点的聚类
代表性方法:kmeans kmedians kmedoids CLARANS
层次方法
基于准则对数数据层次分解
代表性方法:Diana Agnes BIRCH CAMELEON
基于密度的方法
代表性方法:DBSCAN OPTICS DENClue
基于网格的方法
代表方法:STING WaveCluster CLIQUE
基于模型的方法
代表性方法:EM SOM COBWEB
聚类评估方法(概率低)
熵不考哈
熵 :可以反馈特征子集的聚类质量
经验法
肘方法
交叉验证
基于代表点聚类
K means

kmedians
选取代表点选取中值 对异常点不那么敏感
Kmedoids
从非代表点中随机选取点代替中心点集合中的某个点,重新划分 诸葛尝试 选择最优
PAM
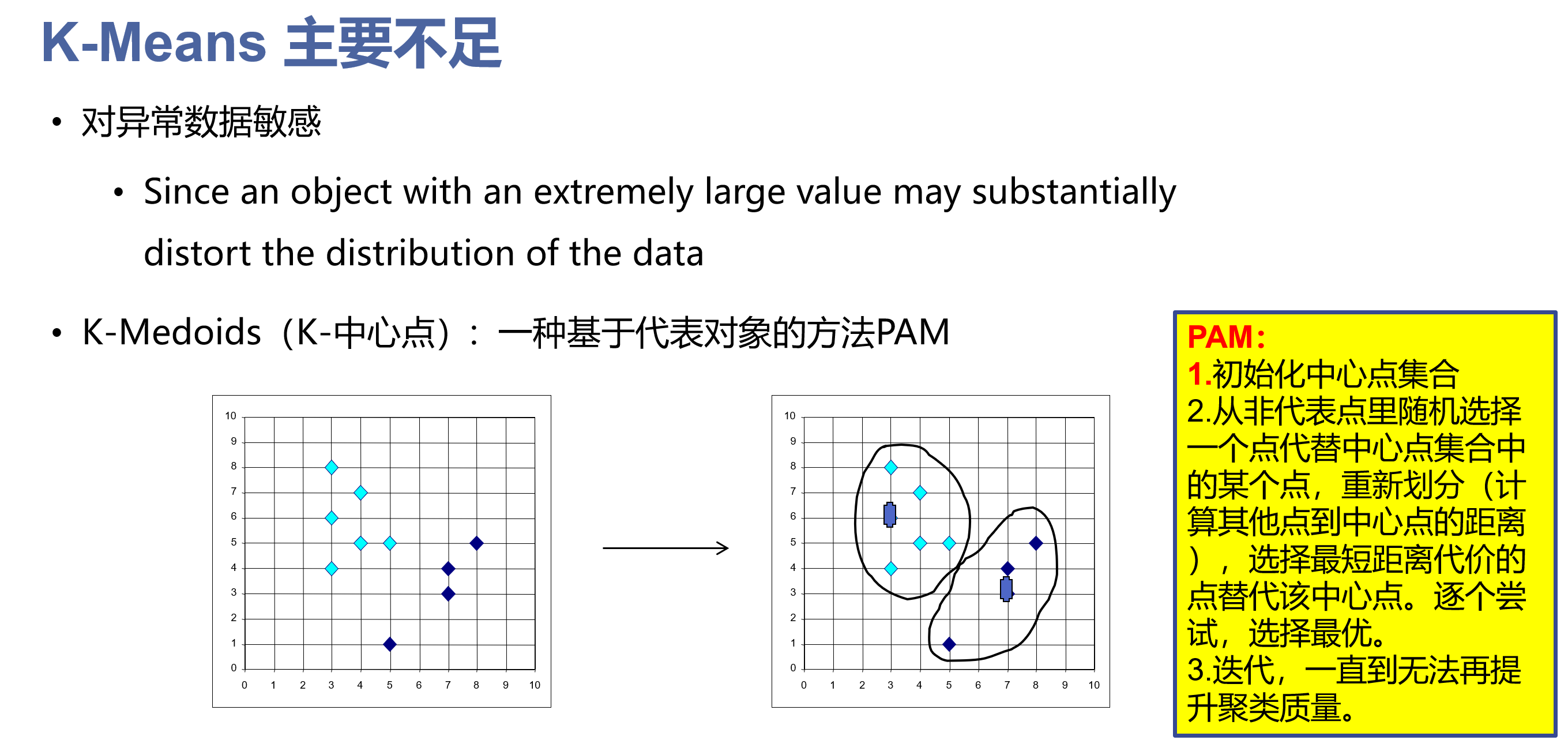
1不受离群点数据影响
2适于处理小数据集
CLARA(小概率)
基于抽样的方法 找到最优中心点集为目标
CLAEANS(小概率)
采样并随机选择
层次聚类
AGNES凝聚法

不断将簇进行合并 最后得到所有合并后的集合为止
DIANA法
分裂法

Birch
CHAMELEON
基于密度聚类
- 发现任意形状簇Discover clusters of arbitrary shape
- 能容忍噪音Handle noise
- 一边扫描One scan
- 需要以密度相关的参数作为终止条件
DBSCAN
原理:
对象的密度可以用靠近该对象的节点数量表示。
找出核心对象和其邻域,形成稠密区为簇
参数:
Eps : 邻域半径
MinPts : 邻域半径内的最小节点数 判断是否为核心节点的阈值
核心节点q 满足
|N_Eps (q) | ≥ MinPts
核心节点扩展区域 边缘节点定义边界

或者

OPTICS(可能不考)
定义了两种距离,核心距离与可达距离
对于不同对象可能有不同的可达距离
DENCLUE(大概率不考)
引入影响函数与密度函数的概念进行聚类
离群点检测
离群点Outlier:
以一种不同机制产生的不同于大多数据表现的不正常的数据。
如:虚假行为,电信诈骗,医药分析,网络攻击,等。
与噪音数据区别
噪音数据是错的数据
是一个测量变量中的随机错误或误差 包括错误的值 偏离期望的孤立点
噪音数据在数据处理前已经被移除。
分类
全局离群点
情境(条件)离群点
今天的最高温度是-15度
集体离群点
数据对象的子集形成集体离群点
例如:一些计算机之间频繁发送信息
离群点特征
有趣的 少量的
基于离群点方法检测出的离群点不能对应真正的异常行为
只能为用户提供可疑数据
基于密度的方法
直方图
通过直方图找到
核密度估计
确定数据中的稀疏区域以便报告异常点
基于概率的方法
极值:对应概率分布的统计尾部
识别模型低概率区域中的对象
一元离群点检测
根据概率密度函数进行
基于距离的方法
基本思路
数据集中显著偏离其他对象的点
根据每个点在局部区域上的密度和其邻近点的密度来判断异常程度
基于聚类的方法
检测方法
建立正常模型
离群点为不能正常符合这个模型的数据点
将异常数据度量为数值
分数越大越可能是离群点
形式
基于聚类产生簇
寻找远离簇的数据点
考虑对象和它最近簇之间的距离
半监督学习
结合聚类与分类检测离群点
先基于聚类识别正常簇,然后使用这个簇的一类模型识别离群点