1、Array的使用
create table tableName(
......
colName array<基本类型>
......
)说明:下标从0开始,越界不报错,以null代替
arr1.txt
zhangsan 78,89,92,96
lisi 67,75,83,94
王五 23,12新建表:
create table arr1(
name string,
scores array<int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';加载数据:
load data local inpath '/home/hivedata/arr1.txt' into table arr1;
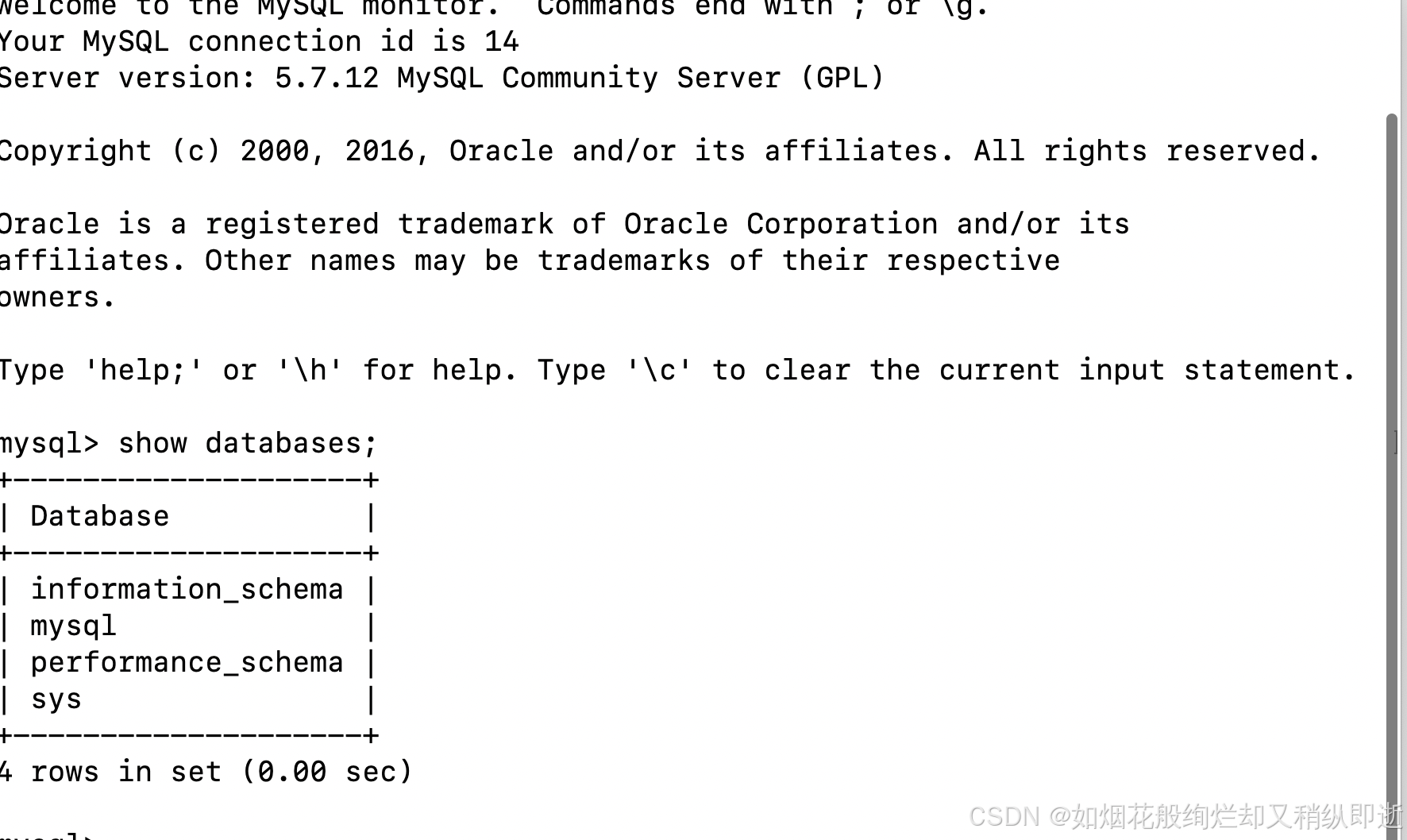
hive (yhdb)> select * from arr1;
OK
arr1.name arr1.scores
zhangsan [78,89,92,96]
lisi [67,75,83,94]
王五 [23,12]
Time taken: 0.32 seconds, Fetched: 3 row(s)需求:
1、查询每一个学生的第一个成绩
select name,scores[0] from arr1;
name _c1
zhangsan 78
lisi 67
王五 23
2、查询拥有三科成绩的学生的第二科成绩
select name,scores[1] from arr1 where size(scores) >=3;
3、查询所有学生的总成绩
select name,scores[0]+scores[1]+nvl(scores[2],0)+nvl(scores[3],0) from arr1;
以上写法有局限性,因为你不知道有多少科成绩,假如知道了,这样写也太Low2、展开函数的使用 explode
为什么学这个,因为我们想把数据,变为如下格式
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
lisi 67
lisi 75
lisi 83
lisi 94
王五 23
王五 12explode 专门用于炸集合。
select explode(scores) from arr1;
col
78
89
92
96
67
75
83
94
23
12想当然的以为加上name 就OK ,错误!
hive (yhdb)> select name,explode(scores) from arr1;
FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions-- lateral view:虚拟表。
会将UDTF函数生成的结果放到一个虚拟表中,然后这个虚拟表会和输入行进行join来达到数据聚合的目的。
具体使用:
select name,cj from arr1 lateral view explode(scores) mytable as cj;
解释一下:
lateral view explode(scores) 形成一张虚拟的表,表名需要自己起
里面的列有几列,就起几个别名,其他的就跟正常的虚拟表一样了。
name cj
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
lisi 67
lisi 75
lisi 83
lisi 94
王五 23
王五 12
select name,sum(cj) from arr1 lateral view explode(scores) mytable as cj group by name;
等同于如下写法:
select name,sum(score) from
(select name,score from arr1 lateral view explode(scores) myscore as score ) t group by name;
需求4:查询每个人的最后一科的成绩
select name,scores[size(scores)-1] from arr1;

3、Map的使用
语法格式:
create table tableName(
.......
colName map<T,T>
......
)上案例:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25建表:
create table map1(
name string,
scores map<string,int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';加载数据:
load data local inpath '/home/hivedata/map1.txt' into table map1;
需求:
需求一:
#查询数学大于35分的学生的英语和自然成绩
select name,scores['english'],scores['nature'] from map1
where scores['math'] > 35;
需求二:-- 查看每个人的前两科的成绩总和
select name,scores['chinese']+scores['math'] from map1;
OK
name _c1
zhangsan 177
lisi 90
wangwu 114
Time taken: 0.272 seconds, Fetched: 3 row(s)
需求三:将数据展示为:
-- 展开效果
zhangsan chinese 90
zhangsan math 87
zhangsan english 63
zhangsan nature 76
select name,subject,cj from map1 lateral view explode(scores) mytable as subject,cj ;
name subject cj
zhangsan chinese 90
zhangsan math 87
zhangsan english 63
zhangsan nature 76
lisi chinese 60
lisi math 30
lisi english 78
lisi nature 0
wangwu chinese 89
wangwu math 25
需求四:统计每个人的总成绩
select name,sum(cj) from map1 lateral view explode(scores) mytable as subject,cj group by name;
假如根据总成绩降序排序,不能在order by 中使用虚拟表的别名
select name,sum(score) sumScore from map1 lateral view explode(scores) myscore as subject,score group by name order by sumScore desc;
行转列
需求5:
-- 将下面的数据格式
zhangsan chinese 90
zhangsan math 87
zhangsan english 63
zhangsan nature 76
lisi chinese 60
lisi math 30
lisi english 78
lisi nature 0
wangwu chinese 89
wangwu math 25
wangwu english 81
wangwu nature 9
-- 转成:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25,english:81,nature:9造一些数据(新建表):
create table map_temp as
select name,subject,cj from map1 lateral view explode(scores) mytable as subject,cj ;第一步,先将学科和成绩形成一个kv对,其实就是字符串拼接
学习一下 concat的用法:
hive (yhdb)> select concat('hello','world');
OK
_c0
helloworld
Time taken: 0.333 seconds, Fetched: 1 row(s)
hive (yhdb)> select concat('hello','->','world');
OK
_c0
hello->world
Time taken: 0.347 seconds, Fetched: 1 row(s)
实战一下:
select name,concat(subject,":",cj) from map_temp;
结果:
name _c1
zhangsan chinese:90
zhangsan math:87
zhangsan english:63
zhangsan nature:76
lisi chinese:60
lisi math:30
lisi english:78
lisi nature:0
wangwu chinese:89
wangwu math:25
以上这个结果再合并:
select name,collect_set(concat(subject,":",cj)) from map_temp
group by name;
lisi ["nature:0","english:78","math:30","chinese:60"]
wangwu ["math:25","chinese:89"]
zhangsan ["nature:76","english:63","math:87","chinese:90"]
将集合中的元素通过逗号进行拼接:
select name,concat_ws(",",collect_set(concat(subject,":",cj))) from map_temp group by name;
结果:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25,english:81,nature:9
学习到了三个函数:
concat 进行字符串拼接
collect_set() 将分组的数据变成一个set集合。里面的元素是不可重复的。
collect_list(): 里面是可以重复的。
concat_ws(分隔符,集合) : 将集合中的所有元素通过分隔符变为字符串。想将数据变为:
lisi {"chinese":"60","math":"30","english":"78","nature":"0"}
wangwu {"chinese":"89","math":"25"}
zhangsan {"chinese":"90","math":"87","english":"63","nature":"76"}4、Struct结构体
create table tableName(
........
colName struct<subName1:Type,subName2:Type,........>
........
)
有点类似于java类
调用的时候直接.
colName.subName数据准备:
zhangsan 90,87,63,76
lisi 60,30,78,0
wangwu 89,25,81,9创建表:
create table if not exists struct1(
name string,
score struct<chinese:int,math:int,english:int,natrue:int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';加载数据:
load data local inpath '/home/hivedata/struct1.txt' into table struct1;查看数据,有点像map:
hive (yhdb)> select * from struct1;
OK
struct1.name struct1.score
zhangsan {"chinese":90,"math":87,"english":63,"natrue":76}
lisi {"chinese":60,"math":30,"english":78,"natrue":0}
wangwu {"chinese":89,"math":25,"english":81,"natrue":9}
Time taken: 0.272 seconds, Fetched: 3 row(s)
查询数学大于35分的学生的英语和语文成绩
select name, score.english,score.chinese from struct1
where score.math > 35;
这个看着和map很像,所以我认为map里 也可以使用 xxx.xxx
或者说我这里也可以使用[]
经过尝试:不可以。