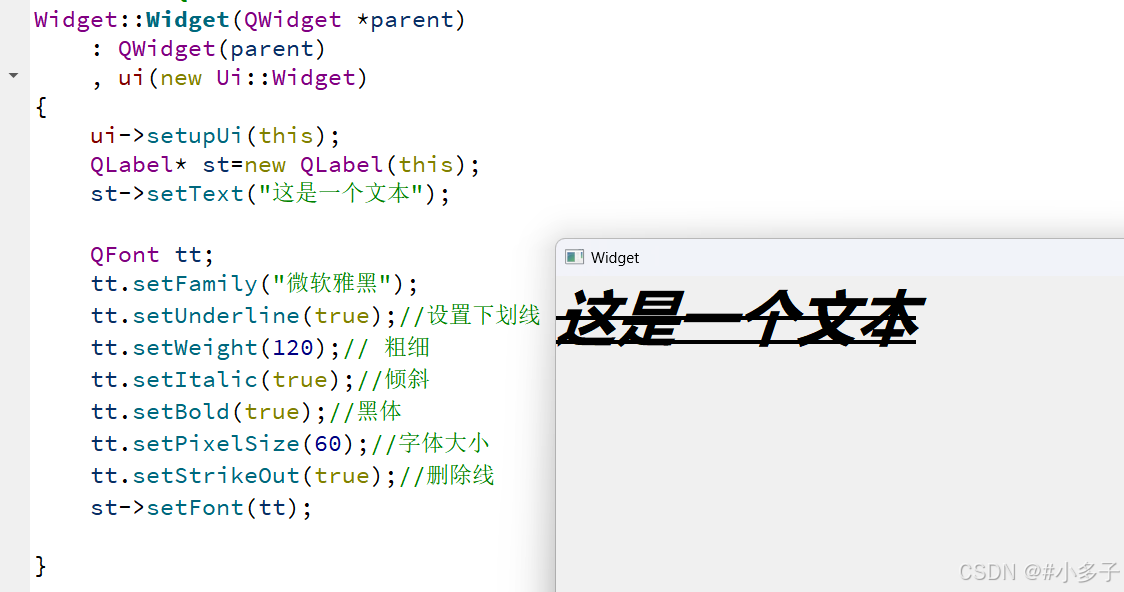
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门!
逻辑回归是一种经典的统计学习方法,用于分类问题尤其是二分类问题。它通过学习数据的特征和目标标签之间的关系,输出样本属于某个类别的概率。本文将从零开始用Python实现逻辑回归模型,深入探讨其数学原理,并逐步讲解如何编写代码实现。我们会涵盖从数据预处理、特征归一化、梯度下降算法到模型训练的每一个细节。通过丰富的代码示例和详细的中文注释,本文将帮助读者从头掌握逻辑回归模型的构建与优化。
正文
目录
- 逻辑回归简介
- 逻辑回归的数学原理
- 2.1 逻辑回归的假设函数
- 2.2 损失函数的推导
- 2.3 梯度下降优化
- 从零开始实现逻辑回归模型
- 3.1 数据预处理
- 3.2 逻辑回归模型类的定义
- 3.3 编写模型训练方法
- 3.4 编写模型预测方法
- 逻辑回归模型的性能评估
- 4.1 准确率与混淆矩阵
- 4.2 交叉验证
- 完整代码实现
- 实验与结果分析
- 总结
1. 逻辑回归简介
逻辑回归是一种广泛应用的分类模型,通常用于二分类问题。不同于线性回归直接输出一个数值,逻辑回归使用一个Sigmoid函数将预测值映射到[0, 1]区间,以此表示样本属于某个类别的概率。逻辑回归的目标是找到最佳的参数,使得模型能够正确地将输入映射到相应的类别。
2. 逻辑回归的数学原理
逻辑回归的数学基础是线性模型,通过线性组合的输入特征生成一个预测值,然后利用Sigmoid函数将其转换为概率。
2.1 逻辑回归的假设函数
逻辑回归的假设函数为:
h θ ( x ) = σ ( θ T x ) = 1 1 + e − θ T x h_{\theta}(x) = \sigma(\theta^T x) = \frac{1}{1 + e^{-\theta^T x}} hθ(x)=σ(θTx)=1+e−θTx1
其中:
-
h
θ
(
x
)
h_{\theta}(x)
hθ(x) 是预测的概率值;
- θ \theta θ 是模型的参数向量;
- x x x 是特征向量;
- σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1是Sigmoid激活函数。
Sigmoid函数的输出在(0, 1)之间,表示样本属于正类(标签为1)的概率。
2.2 损失函数的推导
逻辑回归的目标是最小化损失函数(Cost Function),通常选择对数似然函数作为损失函数。对于单个样本,损失函数为:
L ( h θ ( x ) , y ) = − y log ( h θ ( x ) ) − ( 1 − y ) log ( 1 − h θ ( x ) ) L(h_{\theta}(x), y) = -y \log(h_{\theta}(x)) - (1 - y) \log(1 - h_{\theta}(x)) L(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
其中 y 为样本的真实标签。当 y=1 时,我们最小化 − log ( h θ ( x ) ) -\log(h_{\theta}(x)) −log(hθ(x));当 y=0 时,我们最小化 − log ( 1 − h θ ( x ) ) -\log(1 - h_{\theta}(x)) −log(1−hθ(x))。
总体的损失函数,即所有样本的平均损失为:
J ( θ ) = 1 m ∑ i = 1 m ( − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ) J(\theta) = \frac{1}{m} \sum_{i=1}^m \left(-y^{(i)} \log(h_{\theta}(x^{(i)})) - (1 - y^{(i)}) \log(1 - h_{\theta}(x^{(i)}))\right) J(θ)=m1i=1∑m(−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i))))
2.3 梯度下降优化
为了优化损失函数,我们可以使用梯度下降法更新参数 ( \theta )。梯度下降的更新公式为:
θ = θ − α ∇ J ( θ ) \theta = \theta - \alpha \nabla J(\theta) θ=θ−α∇J(θ)
其中:
α
\alpha
α 是学习率;
-
∇
J
(
θ
)
\nabla J(\theta)
∇J(θ) 是损失函数
J
(
θ
)
J(\theta)
J(θ)关于参数的梯度。
梯度的计算公式为:
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m} \sum_{i=1}^m \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_j^{(i)} ∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)
3. 从零开始实现逻辑回归模型
接下来,我们将逐步实现逻辑回归模型,包括数据预处理、模型定义、训练和预测。
3.1 数据预处理
首先,我们使用一个简单的二分类数据集。数据集需要进行标准化处理,以提高模型的训练效果。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 生成简单的二分类数据集
np.random.seed(0)
X = np.random.randn(100, 2) # 100个样本,每个样本2个特征
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 简单的线性可分数据
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
3.2 逻辑回归模型类的定义
接下来,我们定义逻辑回归模型类,包括初始化、Sigmoid函数和损失函数的实现。
class LogisticRegression:
def __init__(self, learning_rate=0.01, n_iterations=1000):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.weights = None
self.bias = None
def sigmoid(self, z):
# 定义Sigmoid激活函数
return 1 / (1 + np.exp(-z))
def compute_cost(self, y, y_pred):
# 计算损失函数
m = len(y)
cost = (-1 / m) * np.sum(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))
return cost
3.3 编写模型训练方法
使用梯度下降算法优化模型参数。梯度计算基于损失函数的偏导数。
def fit(self, X, y):
# 初始化参数
m, n = X.shape
self.weights = np.zeros(n)
self.bias = 0
for i in range(self.n_iterations):
# 计算线性模型的预测值
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
# 计算梯度
dw = (1 / m) * np.dot(X.T, (y_pred - y))
db = (1 / m) * np.sum(y_pred - y)
# 更新权重和偏差
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
# 每100次迭代打印一次损失
if i % 100 == 0:
cost = self.compute_cost(y, y_pred)
print(f"Iteration {i}: Cost {cost}")
3.4 编写模型预测方法
逻辑回归的预测输出是一个概率值,可以通过设置一个阈值(如0.5)来决定样本属于哪个类别。
def predict(self, X):
# 预测函数
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
return [1 if i > 0.5 else 0 for i in y_pred]
4. 逻辑回归模型的性能评估
为了评估逻辑回归模型的性能,我们使用准确率和混淆矩阵。
4.1 准确率与混淆矩阵
准确率表示正确预测的比例,混淆矩阵能更清晰地展示模型的分类表现。
from sklearn.metrics import accuracy_score, confusion_matrix
# 模型训练与预测
model = LogisticRegression(learning_rate=0.1, n_iterations=1000)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# 计算准确率和混淆矩阵
accuracy = accuracy_score(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)
print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
4.2
交叉验证
交叉验证通过多次数据划分和训练,得到模型更加稳定和可靠的性能评价。
5. 完整代码实现
以下是逻辑回归模型的完整代码实现:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix
class LogisticRegression:
def __init__(self, learning_rate=0.01, n_iterations=1000):
self.learning_rate = learning_rate
self.n_iterations = n_iterations
self.weights = None
self.bias = None
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def compute_cost(self, y, y_pred):
m = len(y)
cost = (-1 / m) * np.sum(y * np.log(y_pred) + (1 - y) * np.log(1 - y_pred))
return cost
def fit(self, X, y):
m, n = X.shape
self.weights = np.zeros(n)
self.bias = 0
for i in range(self.n_iterations):
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
dw = (1 / m) * np.dot(X.T, (y_pred - y))
db = (1 / m) * np.sum(y_pred - y)
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
if i % 100 == 0:
cost = self.compute_cost(y, y_pred)
print(f"Iteration {i}: Cost {cost}")
def predict(self, X):
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
return [1 if i > 0.5 else 0 for i in y_pred]
# 数据准备
np.random.seed(0)
X = np.random.randn(100, 2)
y = (X[:, 0] + X[:, 1] > 0).astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练与评估
model = LogisticRegression(learning_rate=0.1, n_iterations=1000)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
conf_matrix = confusion_matrix(y_test, predictions)
print(f"Accuracy: {accuracy}")
print(f"Confusion Matrix:\n{conf_matrix}")
6. 实验与结果分析
在不同的学习率、迭代次数、数据分布下,我们可以调整模型参数并观察损失函数的变化。
7. 总结
本文从零开始用Python实现了逻辑回归模型,包括数学原理、代码实现和性能评估。通过这些步骤,读者可以深入理解逻辑回归的工作原理,并掌握如何从头构建和优化分类模型。











![简单实现QT对象的[json]序列化与反序列化](https://i-blog.csdnimg.cn/direct/a471c3bca6934b36b2edb7b662d6f128.gif)