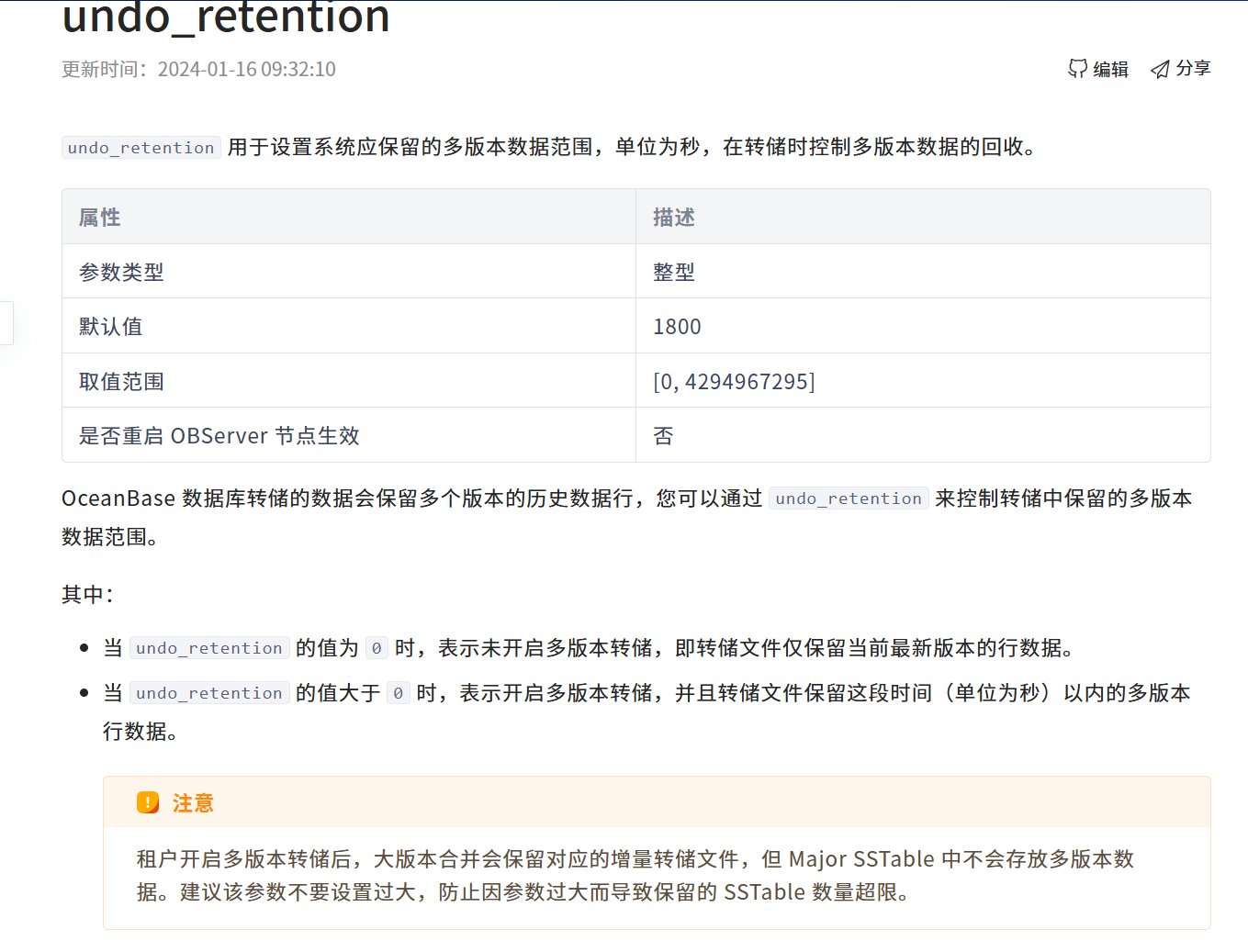
虽说 MapReduce 简化了大数据编程的难度,但是如果每来一个需求都要写一个 MapReduce 代码,那岂不是太麻烦了。尤其是在全民“CRM”的2000年代,对于像数据分析师已经习惯使用SQL进行分析和统计的工程师,让他们去 MapReduce 编程还是有一定的难度。
所以,又先后出现了 Pig、Hive 基于 MapReduce 的上层应用,前者通过将 Pig Latin 编程语言编写的脚本转换为 MapReduce 计算任务,后者通过将 HiveQL 转换为 MapReduce 程序。总之,都是为了再次简化大数据计算的难度。
而有着近似 SQL 语言的 Hive 就比较非常受欢迎(本文主要介绍 Hive),因为非 Java 编程者可以通过 SQL 语句对 HDFS 的数据实现 MapReduce 操作,从而完成大数据计算的工作。
通过实操更直观的感受一下 Hive 到底是啥。
既然涉及到SQL,那一定会存在表名、列名,Hive 自然而然承担了表名、列名、数据类型等元数据和 HDFS 文件数据映射关系的管理。
以下面的 HiveQL 为例,创建的表最终会根据hive.metastore.warehouse.dir配置,在 HDFS 生成一个名为test的目录。
CREATE TABLE test(id int,name string,age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';


再以下面的 HiveQL 为例,添加的数据最终会在test目录下体现。
insert into test values (1,'zs',18),(2,'ls',19),(3,'ww',20);

通过下图可以发现,在执行 insert 语句时会转化为 MapReduce 任务并执行,所以会发现这个过程比传统数据库慢很多,当然,Hive并不是为这么点数据量诞生的,也不仅仅只支持这样简单的场景。

通过上面的示例,是不是感觉 Hive 和数据库差不多?
Hive 本身的技术架构确实没有什么创新,就是成熟的数据库技术和HDFS、MapReduce的结合体。有 HDFS 这样的存储底座可以存储大量的数据,又可以通过 SQL 语句实现数据的统计和分析,Hive 又被称为数据仓库。
如果对数据仓库没有概念的可以看下oracle对数仓的定义。
思考:select avg(age) from test 这样的 SQL 会转换成什么样的 MapReduce 程序,欢迎评论区交流。