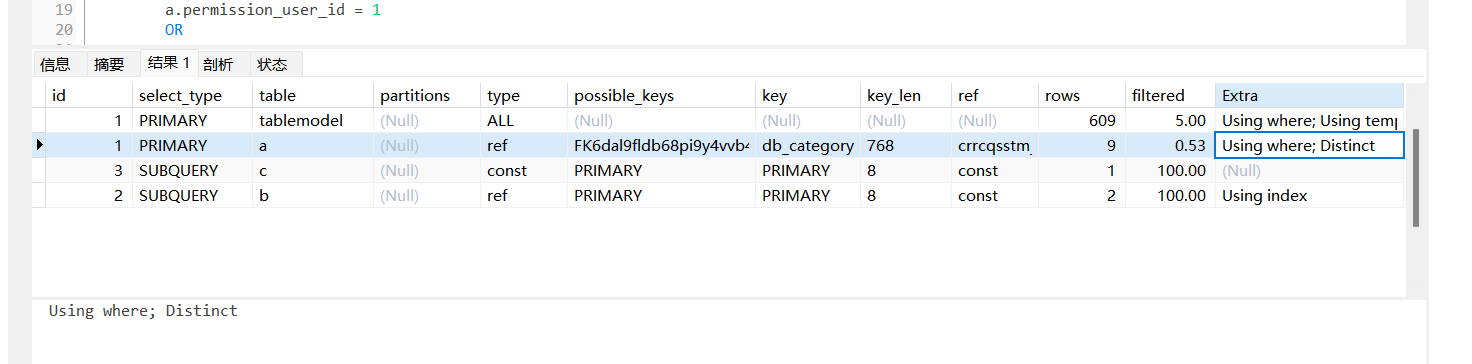
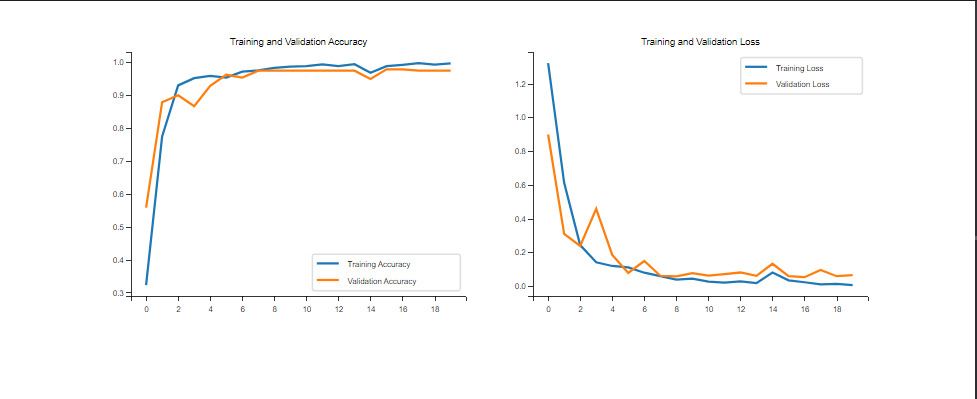
测试了下网上找的一篇代码,运行成功~
# import sys
# print(sys.path)
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.datasets import Planetoid
# 加载并预处理Cora数据集
dataset_path = './dataset/cora'
dataset = Planetoid(root=dataset_path, name='Cora')
data = dataset[0] # 取第一个图数据
# 打印数据集信息以确认加载成功
print(f'Dataset: {dataset}')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_node_features}')
print(f'Number of classes: {dataset.num_classes}')
print(data)
class GNN(torch.nn.Module):
def __init__(self, num_features, num_classes):
super(GNN, self).__init__()
self.conv1 = GCNConv(num_features, 16) # 第一个卷积层
self.conv2 = GCNConv(16, num_classes) # 第二个卷积层
def forward(self, data):
x, edge_index = data.x, data.edge_index # 获取节点特征和边索引
x = self.conv1(x, edge_index) # 第一个卷积
x = F.relu(x) # 激活函数
x = self.conv2(x, edge_index) # 第二个卷积
return F.log_softmax(x, dim=1) # 返回经过softmax的输出
model = GNN(num_features=dataset.num_node_features, num_classes=dataset.num_classes)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
print(model)
# 训练过程
model.train()
for epoch in range(200):
optimizer.zero_grad() # 清除之前的梯度
out = model(data) # 前向传播 data如何传递给forward函数的?
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
if epoch % 20 == 0:
print(f'Epoch {epoch}, Loss: {loss.item()}')
model.eval()
_, pred = model(data).max(dim=1) # 获取预测结果
correct = pred[data.test_mask] == data.y[data.test_mask] # 比较预测与真实标签
accuracy = int(correct.sum()) / int(data.test_mask.sum()) # 计算准确率
print(f'Test Accuracy: {accuracy:.4f}')
遇到的问题:
1.python是脚本语言,没有编译过程,因此对齐要非常小心,创建model这一行干脆不要空格,否则class的结束部分会报错。
一般语句不需要缩进,顶行书写且不留空白。
当表示分支、循环、函数、类等含义,在if,while,for,def,class等保留字所在的完整语句后通过英文冒号(:)结尾,并在之后进行缩进,表示前后代码之间的从属关系
2.Plaintoid数据本地读取的问题,从github下载后放到/dataset/cora/raw下面,运行成功~
参考: 1 .GNNpython代码实现_mob649e816347dd的技术博客_51CTO博客
2. https://zhuanlan.zhihu.com/p/452747749