目录
背景
传统的Mybaits开发方式,是通过mybatis-config.xml对框架进行全局配置,比如:一级缓存、主键生成器等。
而在SpringBoot发布后,通过引入 mybatis-spring-boot-starter依赖包,可以大大减少工作量,实现快速落地,可以参考此前的文章案例:SpringBoot集成Mybatis;下面我们结合SpringBoot分析Mybatis的初始化流程和执行流程。
预备知识
首先是预备知识,因为SpringBoot自动装配才使得Mybatis许多配置变得简洁,我们必须引入springboot的bean自动导入流程。
预备1:@SpringBootApplication注解加载
springboot启动的时候会读取META-INF\spring.factories文件,
把key=org.springframework.boot.autoconfigure.EnableAutoConfiguration的字符串作为类名去加载
(启动会配合META-INF\spring-autoconfigure-metadata.properties中的内容过滤掉不符合当前场景的)预备2:Bean的实例化和初始化顺序
可以参考文章:《Spring源码:bean加载流程》
我们明确一下的几个原则:
-
Bean的实例化和初始化是分开的步骤
-
Bean实例化之后,不等初始化完成,就提前暴露了一个BeanFactory到内存,方便解决循环依赖问题
-
当前Bean实例化后,会先完成所有依赖注入,再进行初始化(包括afterProperties()接口/postProcessAfterInstantiation()接口实现等)
预备3:ObjectFactory、FactoryBean、BeanFactory

源码分析
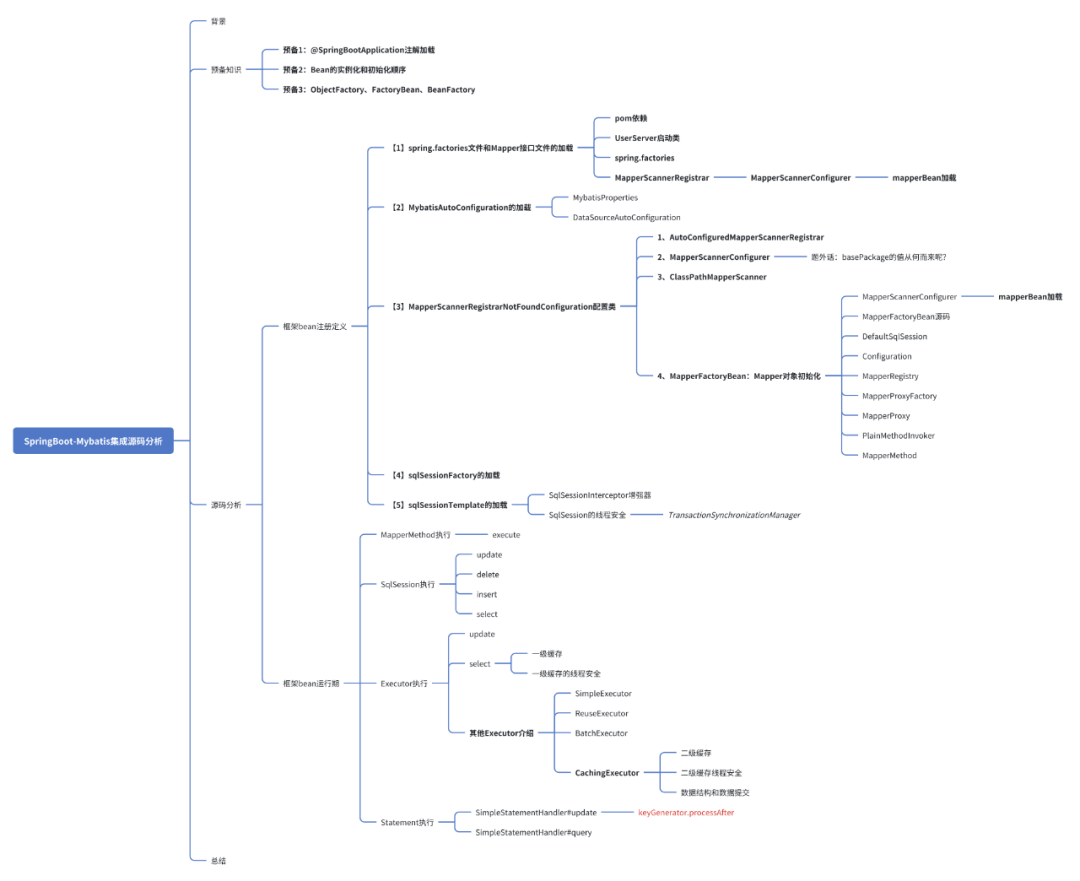
按照惯例,我们的源码分析,还是按照两条路线:框架Bean注册定义、框架Bean运行期。
一、框架Bean注册定义
1、spring.factories文件和Mapper接口文件的加载
1.1 pom依赖
<!-- 整合mybatis相关依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.2</version>
</dependency>我们首先加入了mybatis-spring-boot-starter依赖,我们点进去可以看到,mybatis-spring-boot-starter还依赖了其他的第三方jar包:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</dependency>
</dependencies>留意还有:mybatis-spring-boot-autoconfigure这个依赖
1.2 UserServer启动类
// ...其他注解
@SpringBootApplication
@MapperScan("com.bryant.mapper") // mapper扫描的包路径
public class UserServer {
public static void main(String[] args) {
SpringApplication.run(UserServer.class, args);
}
}我们看到@SpringBootApplication,也就代表了会触发以下的自动装配流程
-
@SpringBootApplication注解 修饰了 启动类
-
@EnableAutoConfiguration注解 修饰了 @SpringBootApplication注解
-
@Import(AutoConfigurationImportSelector.class) 修饰了 @EnableAutoConfiguration注解
-
AutoConfigurationImportSelector会在@SpringBootApplication启动类启动时,触发自动加载jar包的META-INF/spring.factories里面的所有配置候选类
我们回到这个mybatis-spring-boot-autoconfigure依赖包,发现确有spring.factories文件
/mybatis-spring-boot-autoconfigure/2.1.2/mybatis-spring-boot-autoconfigure-2.1.2.jar!/META-INF/spring.factories
1.3 spring.factories
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.mybatis.spring.boot.autoconfigure.MybatisLanguageDriverAutoConfiguration,\
org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration-
MybatisAutoConfiguration这个是主要的Mybatis自动配置类
1.4 MapperScannerRegistrar的mapper接口加载
我们在启动类加了这么一个注解@MapperScan
@MapperScan("com.bryant.mapper") // mapper扫描的包路径由于使用了@MapperScan,会触发其他资源引入
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Import(MapperScannerRegistrar.class)
@Repeatable(MapperScans.class)
public @interface MapperScan {
}@Import会触发自动引入MapperScannerRegistrar类
public class MapperScannerRegistrar implements ImportBeanDefinitionRegistrar, ResourceLoaderAware {
void registerBeanDefinitions(AnnotationMetadata annoMeta, AnnotationAttributes annoAttrs,
BeanDefinitionRegistry registry, String beanName) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(MapperScannerConfigurer.class);
// 设置了MapperFactoryBean
Class<? extends MapperFactoryBean> mapperFactoryBeanClass = annoAttrs.getClass("factoryBean");
if (!MapperFactoryBean.class.equals(mapperFactoryBeanClass)) {
builder.addPropertyValue("mapperFactoryBeanClass", mapperFactoryBeanClass);
}
// ...省略很多细节
builder.addPropertyValue("basePackage", StringUtils.collectionToCommaDelimitedString(basePackages));
registry.registerBeanDefinition(beanName, builder.getBeanDefinition());
}
}-
设置了一个beanClass = MapperScannerConfigurer的BeanDefinitionBuilder
-
给
MapperScannerRegistrar的bean定义,设置了属性mapperFactoryBeanClass:即MapperFactoryBean工厂 -
给MapperScannerRegistrar的bean定义,设置了属性basePackage:这里直接就是用的用户定义的路径值com.bryant.mapper
-
MapperScannerRegistrar实现了 ImportBeanDefinitionRegistrar接口,因此会触发方法,从而调用registerBeanDefinitions方法,完成BeanDefinitionRegistry对当前的MapperScannerRegistrar的bean定义注册(就是往BeanFactory加了一个BeanDefinition)
-
最终触发了MapperScannerConfigurer的postProcessBeanDefinitionRegistry(等后续的【3.2】MapperScannerConfigurer)
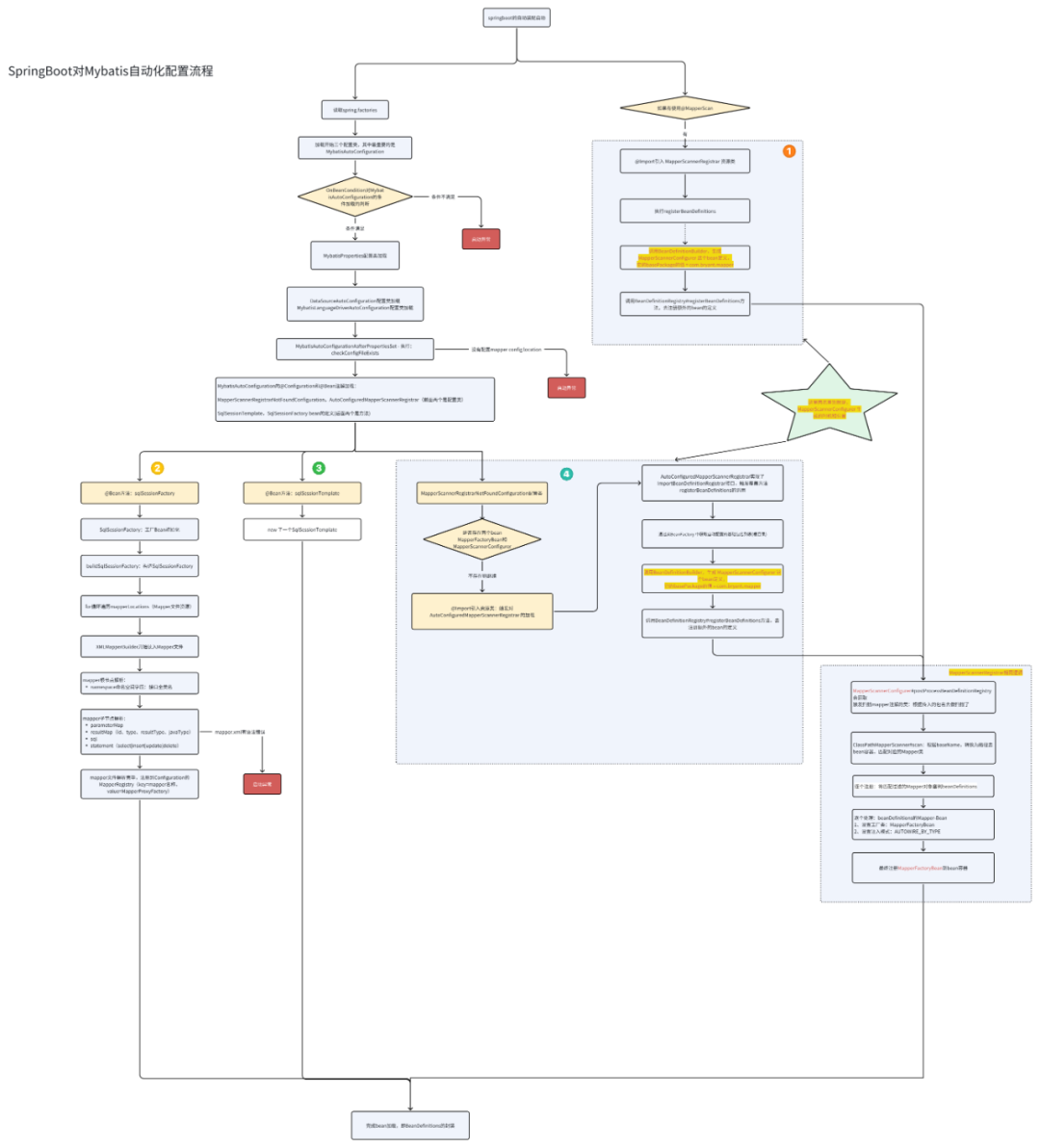
2、MybatisAutoConfiguration的加载
@org.springframework.context.annotation.Configuration
@ConditionalOnClass({ SqlSessionFactory.class, SqlSessionFactoryBean.class })
@ConditionalOnSingleCandidate(DataSource.class)
@EnableConfigurationProperties(MybatisProperties.class)
@AutoConfigureAfter({ DataSourceAutoConfiguration.class, MybatisLanguageDriverAutoConfiguration.class })
public class MybatisAutoConfiguration implements InitializingBean {
}代码分析:
-
@Configuration:声明这是配置类的注解
-
@ConditionalOnClass:条件注解,MybatisAutoConfiguration需要同时存在这两个类 - SqlSessionFactory、SqlSessionFactoryBean
-
@ConditionalOnSingleCandidate:条件注解,判断spring容器是否只有一个类型DataSource.class的bean的定义,或者有多个,但有一个主要的
-
@EnableConfigurationProperties:MybatisAutoConfiguration启用并加载配置MybatisProperties属性类
-
@AutoConfigureAfter:
-
数据库自动加载:DataSourcePoolMetadataProvidersConfiguration
-
处理动态SQL:MybatisLanguageDriverAutoConfiguration用于在 Spring Boot 应用程序中自动配置 MyBatis 的 LanguageDriver。LanguageDriver 是 MyBatis 中的一个组件,用于处理 SQL 映射文件中的动态 SQL 语句。
-
先完成2个配置类加载 - DataSourceAutoConfiguration、MybatisLanguageDriverAutoConfiguration
-
Mybatis的自动化配置步骤非常多,Bean也很多,实际上可以用一个类加载流程图搞定:
2.1、MybatisProperties
读取解析mybatis开头的配置,比如:
#指定mapper的配置文件的路径是mapper文件夹下的所有 xml文件。
mybatis.mapper-locations=classpath:mapper/*.xml2.2、DataSourceAutoConfiguration
引入了DataSourceProperties,读取解析spring.data开头的配置,比如:
#数据源配置
spring.datasource.url = jdbc:mysql://localhost:3306/xxx?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true&allowPublicKeyRetrieval=true
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=12345678
spring.datasource.name=xxx3、MapperScannerRegistrarNotFoundConfiguration配置类
这里跟1.5 的MapperScannerRegistrar的mapper接口加载是互斥关系,所以并不会同时发生。
正如其名,如果MapperScan相关的bean没有定义,那么就执行该配置类
@org.springframework.context.annotation.Configuration
@Import(AutoConfiguredMapperScannerRegistrar.class)
@ConditionalOnMissingBean({ MapperFactoryBean.class, MapperScannerConfigurer.class })
public static class MapperScannerRegistrarNotFoundConfiguration implements InitializingBean {
@Override
public void afterPropertiesSet() {
logger.debug(
"Not found configuration for registering mapper bean using @MapperScan, MapperFactoryBean and MapperScannerConfigurer.");
}
}
}-
@ConditionalOnMissingBean:如果找不到 MapperFactoryBean 和 MapperScannerConfigurer,就执行该配置类初始化
-
其实并没有别的成员属性要初始化的,有的只是引入AutoConfiguredMapperScannerRegistrar重新扫描注册bean
-
3.1、AutoConfiguredMapperScannerRegistrar
实现了2个接口:BeanFactoryAware、ImportBeanDefinitionRegistrar
public static class AutoConfiguredMapperScannerRegistrar implements BeanFactoryAware, ImportBeanDefinitionRegistrar {
private BeanFactory beanFactory;
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
if (!AutoConfigurationPackages.has(this.beanFactory)) {
logger.debug("Could not determine auto-configuration package, automatic mapper scanning disabled.");
return;
}
List<String> packages = AutoConfigurationPackages.get(this.beanFactory);
if (logger.isDebugEnabled()) {
packages.forEach(pkg -> logger.debug("Using auto-configuration base package '{}'", pkg));
}
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(MapperScannerConfigurer.class);
builder.addPropertyValue("processPropertyPlaceHolders", true);
builder.addPropertyValue("annotationClass", Mapper.class);
builder.addPropertyValue("basePackage", StringUtils.collectionToCommaDelimitedString(packages));
BeanWrapper beanWrapper = new BeanWrapperImpl(MapperScannerConfigurer.class);
Stream.of(beanWrapper.getPropertyDescriptors())
// Need to mybatis-spring 2.0.2+
.filter(x -> x.getName().equals("lazyInitialization")).findAny()
.ifPresent(x -> builder.addPropertyValue("lazyInitialization", "${mybatis.lazy-initialization:false}"));
registry.registerBeanDefinition(MapperScannerConfigurer.class.getName(), builder.getBeanDefinition());
}
@Override
public void setBeanFactory(BeanFactory beanFactory) {
this.beanFactory = beanFactory;
}
}-
BeanFactoryAware接口:其实Spring框架会对setBeanFactory方法进行回调,填入BeanFactory属性,让当前bean获得对 BeanFactory 的访问权限
-
ImportBeanDefinitionRegistrar接口:会注册相关的BeanDefinition,允许我们注册额外的Bean定义,使得应用SpringContenxt启动时能够动态地加载和管理Bean;这里是用BeanDefinitionRegistry对 MapperScannerConfigurer 进行注册
3.2、MapperScannerConfigurer
由于MapperScannerConfigurer这个类实现了BeanDefinitionRegistryPostProcessor接口,所以它就会被生成bean之前加载,调用它的postProcessBeanDefinitionRegistry方法。
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
if (this.processPropertyPlaceHolders) {
// (1)设置属性值
processPropertyPlaceHolders();
}
ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry);
scanner.setAddToConfig(this.addToConfig);
scanner.setAnnotationClass(this.annotationClass);
scanner.setMarkerInterface(this.markerInterface);
scanner.setSqlSessionFactory(this.sqlSessionFactory);
scanner.setSqlSessionTemplate(this.sqlSessionTemplate);
scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName);
scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName);
scanner.setResourceLoader(this.applicationContext);
scanner.setBeanNameGenerator(this.nameGenerator);
// (2)这里设置了mapperFactoryBeanClass是MapperFactoryBean
scanner.setMapperFactoryBeanClass(this.mapperFactoryBeanClass);
if (StringUtils.hasText(lazyInitialization)) {
scanner.setLazyInitialization(Boolean.valueOf(lazyInitialization));
}
scanner.registerFilters();
// (3)依据属性值进行mapper接口扫描
scanner.scan(StringUtils.tokenizeToStringArray(this.basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS));
}
// (1)设置属性值
private void processPropertyPlaceHolders() {
Map<String, PropertyResourceConfigurer> prcs = applicationContext.getBeansOfType(PropertyResourceConfigurer.class);
if (!prcs.isEmpty() && applicationContext instanceof ConfigurableApplicationContext) {
// 通过BeanFactory获取Bean定义
BeanDefinition mapperScannerBean =
((ConfigurableApplicationContext) applicationContext).getBeanFactory()
.getBeanDefinition(beanName);
// 取出"basePackage"属性值,并赋值
PropertyValues values = mapperScannerBean.getPropertyValues();
this.basePackage = updatePropertyValue("basePackage", values);
}
this.basePackage = Optional.ofNullable(this.basePackage).map(getEnvironment()::resolvePlaceholders).orElse(null);
}-
(1)processPropertyPlaceHolders:完成"basePackage"属性值赋值
-
(2)setMapperFactoryBeanClass:完成“mapperFactoryBeanClass”属性值复制,声明是用
MapperFactoryBean工厂去初始化Mapper对象 -
(3)这里就是要根据传入的包名去做扫描了,这里的this.basePackage就是上面说的 mapper文件基础路径
题外话:basePackage的值从何而来呢?
参考【1】的mapper接口配置注入,MapperScannerRegistrar最终往BeanFactory加入了一个名为MapperScannerRegistrar的BeanDefinition,它的basePackage的值 = com.bryant.mapper。
那么在【3】的MapperScannerConfigurer会通过beanName=MapperScannerRegistrar,从BeanFactory取出一个名为MapperScannerRegistrar的BeanDefinition,然后再提取basePackage的值 = com.bryant.mapper。
好了,现在我们聊到如何去扫描对应的包路径文件。
3.3、ClassPathMapperScanner
继承了ClassPathBeanDefinitionScanner父类,doScan内部会回调父类方法,然后进行bean定义处理。
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#scan
@Override
public Set<BeanDefinitionHolder> doScan(String... basePackages) {
// (1)调用父类ClassPathBeanDefinitionScanner#doScan方法
Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages);
if (beanDefinitions.isEmpty()) {
LOGGER.warn(() -> "No MyBatis mapper was found in '" + Arrays.toString(basePackages)
+ "' package. Please check your configuration.");
} else {
// (2)处理bean定义集合
processBeanDefinitions(beanDefinitions);
}
return beanDefinitions;
}
//(1)org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
//这里就是扫描类路径下的mapper注解类了。
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
//获取bean的名字
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
//这个是判断beanFactory是否包含beanName的bean的定义,不包含就会进入分支,这个分支也没啥特殊的,就是把bean的定义添加到beanFactory中
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) {
GenericBeanDefinition definition;
for (BeanDefinitionHolder holder : beanDefinitions) {
// the mapper interface is the original class of the bean
// but, the actual class of the bean is MapperFactoryBean
definition.getConstructorArgumentValues().addGenericArgumentValue(beanClassName);
definition = (GenericBeanDefinition) holder.getBeanDefinition();
String beanClassName = definition.getBeanClassName();
definition.setBeanClass(this.mapperFactoryBeanClass);
if (!explicitFactoryUsed) {
LOGGER.debug(() -> "Enabling autowire by type for MapperFactoryBean with name '" + holder.getBeanName() + "'.");
definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE);
}
}
}-
(1)findCandidateComponents:这里就是扫描类路径下的mapper注解类了
-
candidates:传入的包名是com.bryant.mapper,就会被转换成classpath*:com/bryant/mapper/**/*.class这个路径进行解析查找,将找到的类作为BeanDefinition的定义返回
-
-
(2)postProcessBeanDefinition
-
因为mapper是接口,是无法new一个对象的,所以这里要赋予BeanDefinition一个构造器参数
-
该bean的属性注入模式为AUTOWIRE_BY_TYPE
-
经过上面步骤,我们写好的Mapper接口,会被框架扫描到,并做好了Bean定义的准备,那么这个MapperBean究竟是生成啥样的对象呢?
3.4、MapperFactoryBean:Mapper对象初始化
我们回顾一下上面【3】的第3点 MapperScannerConfigurer;
它创建的 ClassPathMapperScanner 扫描器过程里,其中一个步骤是setMapperFactoryBeanClass,会去赋值工厂类为MapperFactoryBean,就是说后面的Mapper动态代理对象,都是基于MapperFactoryBean#GetObject生产出来的。
我们进入MapperFactoryBean源码
MapperFactoryBean是继承了SqlSessionDaoSupport,SqlSessionDaoSupport封装了一个SqlSessionTemplate。
public class MapperFactoryBean<T> extends SqlSessionDaoSupport implements FactoryBean<T> {
Override
public T getObject() throws Exception {
return getSqlSession().getMapper(this.mapperInterface);
}
}-
当 Spring 容器需要实例化一个 Mapper 接口的 Bean 时,它会调用 MapperFactoryBean 的 getObject 方法。
-
MapperFactoryBean 内部会使用 MyBatis 的 SqlSession 来创建 Mapper 接口的动态代理对象。
-
MapperFactoryBean#getObject():本质是SqlSessionTemplate#getMapper
我们进入DefaultSqlSession
public class DefaultSqlSession implements SqlSession {
private final Configuration configuration;
private final Executor executor;
@Override
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}
}-
果然里面是封装了Configuration连接和Executor执行器
-
SqlSessionTemplate#getMapper:本质是Configuration#getMapper
我们进入Configuration
public class Configuration {
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
}-
果然里面是封装了MapperRegistry注册表
-
Configuration#getMapper:本质是MapperRegistry#getMapper
我们进入MapperRegistry
public class MapperRegistry {
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
}-
真相呼之欲出,最后暴露了一个代理工厂类MapperProxyFactory
-
通过MapperProxyFactory,来创建Mapper代理对象
-
mapperProxyFactory.newInstance(sqlSession):本质是调用MapperProxyFactory
我们进入MapperProxyFactory
public class MapperProxyFactory<T> {
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}-
最终新建了一个MapperProxy
-
并通过Proxy.newProxyInstance,设置了一个代理对象MapperImpl,代理对象MapperImpl实现了全部的Mapper接口,并且通过MapperProxy来实现逻辑增强
我们进入MapperProxy
public class MapperProxy<T> implements InvocationHandler, Serializable {
private final SqlSession sqlSession;
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}代码分析:
-
在invoke方法中,首先判断当前代理对象是否是Object类,如果是,则直接调用当前对象的方法,否则,则使用缓存的Invoker对象来调用目标对象的方法。
-
增强方法invoke的主要步骤是cachedInvoker方法,是用来获取缓存的Invoker对象,如果缓存中不存在该对象,则创建一个新的Invoker对象,并将其缓存起来。
cachedInvoker
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
return methodCache.computeIfAbsent(method, m -> {
if (m.isDefault()) {
// ...这里是对接口的非公开方法(default方法、static方法等的处理)
} else {
// 默认走的是PlainMethodInvoker
return new PlainMethodInvoker(
new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}-
正常情况的接口都是public的,会触发PlainMethodInvoker的创建
-
PlainMethodInvoker最核心的,是对MapperMethod的封装,MapperMethod也是最核心的Mapper方法了
我们进入PlainMethodInvoker
private static class PlainMethodInvoker implements MapperMethodInvoker {
private final MapperMethod mapperMethod;
public PlainMethodInvoker(MapperMethod mapperMethod) {
super();
this.mapperMethod = mapperMethod;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
return mapperMethod.execute(sqlSession, args);
}
}-
PlainMethodInvoker封装了一个MapperMethod,其invoke实际上也是对MapperMethod的调用
我们进入MapperMethod
构造器
public class MapperMethod {
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
}-
MapperMethod内部会构建一个SqlCommand,以及MethodSignature
以上就是Mybatis对SqlSession的代码封装了,的确非常复杂,对象的调用链非常长,但我们用一张图来总结下也不是不行:
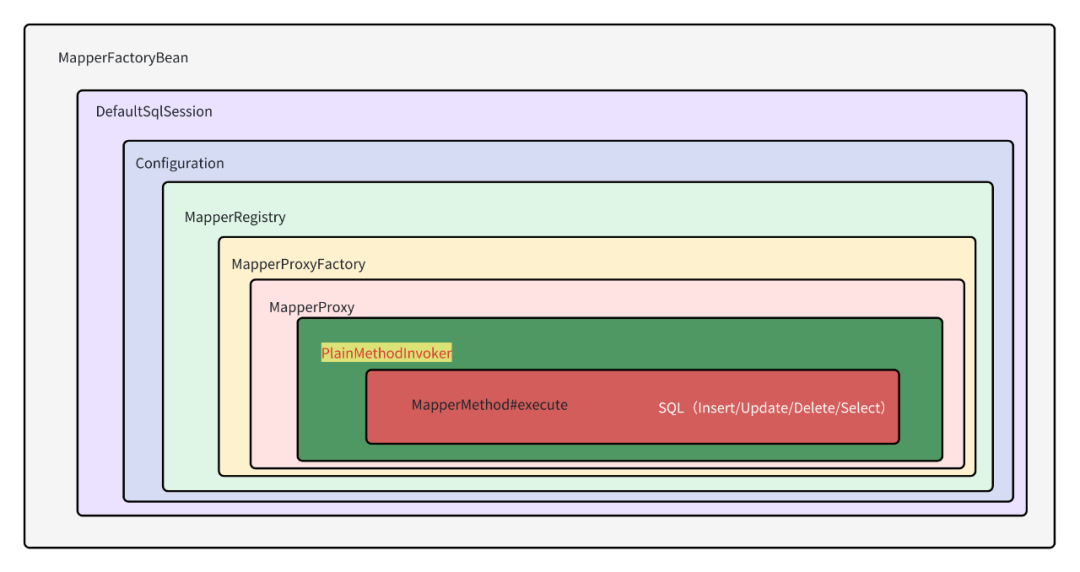
4、sqlSessionFactory的加载
@Bean
@ConditionalOnMissingBean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factory = new SqlSessionFactoryBean();
//...省略属性设置
return factory.getObject();
}如果缺少SqlSessionFactory,则默认调用这个方法
5、sqlSessionTemplate的加载
@Bean
@ConditionalOnMissingBean
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
ExecutorType executorType = this.properties.getExecutorType();
if (executorType != null) {
return new SqlSessionTemplate(sqlSessionFactory, executorType);
} else {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
public SqlSessionTemplate(SqlSessionFactory sqlSessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
this.sqlSessionFactory = sqlSessionFactory;
this.executorType = executorType;
this.exceptionTranslator = exceptionTranslator;
this.sqlSessionProxy = (SqlSession) newProxyInstance(
SqlSessionFactory.class.getClassLoader(),
new Class[] { SqlSession.class }, new SqlSessionInterceptor());
}-
如果缺少SqlSessionTemplate,则默认调用这个方法
-
SqlSessionTemplate的构造器,最终是调用了Proxy类的动态代理,生成对
SqlSession的代理对象。-
在 JDK 动态代理中,生成的代理类 $Proxy 是继承 Proxy 并且实现
SqlSession接口,当调用代理类的方法时,会进入到拦截器SqlSessionInterceptor的 invoke 方法中
-
5.1、SqlSessionInterceptor增强器
SqlSessionInterceptor
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
SqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,
SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);
try {
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
// force commit even on non-dirty sessions because some databases require
// a commit/rollback before calling close()
sqlSession.commit(true);
}
return result;
} catch (Throwable t) {
Throwable unwrapped = unwrapThrowable(t);
if (SqlSessionTemplate.this.exceptionTranslator != null && unwrapped instanceof PersistenceException) {
// release the connection to avoid a deadlock if the translator is no loaded. See issue #22
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
sqlSession = null;
Throwable translated = SqlSessionTemplate.this.exceptionTranslator
.translateExceptionIfPossible((PersistenceException) unwrapped);
if (translated != null) {
unwrapped = translated;
}
}
throw unwrapped;
} finally {
if (sqlSession != null) {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}SqlSessionInterceptor代理的逻辑比较复杂,下面我们用一张图来表示其过程:
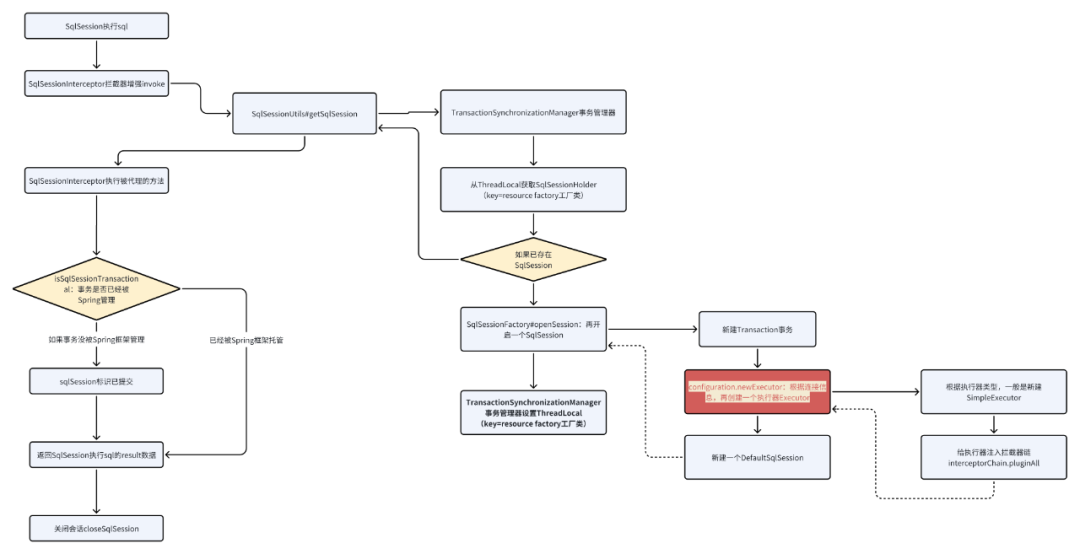
5.2、SqlSession的线程安全
刚刚我们从源码得知,获取会话的操作getSqlSession源码,SqlSession的线程安全是通过TransactionSynchronizationManager事务同步管理器来实现的。
public abstract class TransactionSynchronizationManager {
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
/**
* Gets an SqlSession from Spring Transaction Manager or creates a new one if needed. Tries to get a SqlSession out of
* current transaction. If there is not any, it creates a new one. Then, it synchronizes the SqlSession with the
* transaction if Spring TX is active and <code>SpringManagedTransactionFactory</code> is configured as a transaction
* manager.
*/
public static SqlSession getSqlSession(SqlSessionFactory sessionFactory, ExecutorType executorType,
PersistenceExceptionTranslator exceptionTranslator) {
SqlSessionHolder holder = (SqlSessionHolder)
TransactionSynchronizationManager.getResource(sessionFactory);
SqlSession session = sessionHolder(executorType, holder);
if (session != null) {
return session;
}
LOGGER.debug(() -> "Creating a new SqlSession");
session = sessionFactory.openSession(executorType);
registerSessionHolder(sessionFactory, executorType, exceptionTranslator, session);
return session;
}
@Nullable
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
Object value = doGetResource(actualKey);
return value;
}
@Nullable
private static Object doGetResource(Object actualKey) {
Map<Object, Object> map = resources.get();
if (map == null) {
return null;
}
Object value = map.get(actualKey);
// Transparently remove ResourceHolder that was marked as void...
if (value instanceof ResourceHolder && ((ResourceHolder) value).isVoid()) {
map.remove(actualKey);
// Remove entire ThreadLocal if empty...
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
}代码分析:
-
TransactionSynchronizationManager事务同步管理器的底层,维护了一个ThreadLocal
-
通过线程封闭的方式,实现了SqlSession线程安全
-
更多关于ThreadLocal的文章,可以参考:
-
线程安全反思录(上):ThreadLocal到底安全不?
-
JDK源码ThreadLocal类
-
5.3、小结
经过上面的流程,sqlSessionTemplate已经构建完成了,那么后面就是sqlSessionTemplate发挥作用的时刻了!
但是,Mybatis作为简洁高效的ORM框架,肯定不会直接暴露sqlSessionTemplate给用户去调用的,而是做了层层封装,使得更加切合业务开发习惯。
二、框架Bean运行期
当我们要查询一个SQL时,我们是怎么做到的?是不是按照以下的步骤:
-
@Autowired注入UserMapper
-
使用UserMapper的insert/update/delete/select接口
-
动态映射到Mapper.xml的sql执行
-
拿到组装结果并返回
我们上面已经知道了,@Autowired注入的Mapper,被调用时,最终会触发动态代理类的执行;上面经过分析,每个Mapper对象的方法,最终都会转化成一个MapperMethod,而这里面是一层非常复杂的对象封装链,如下图:
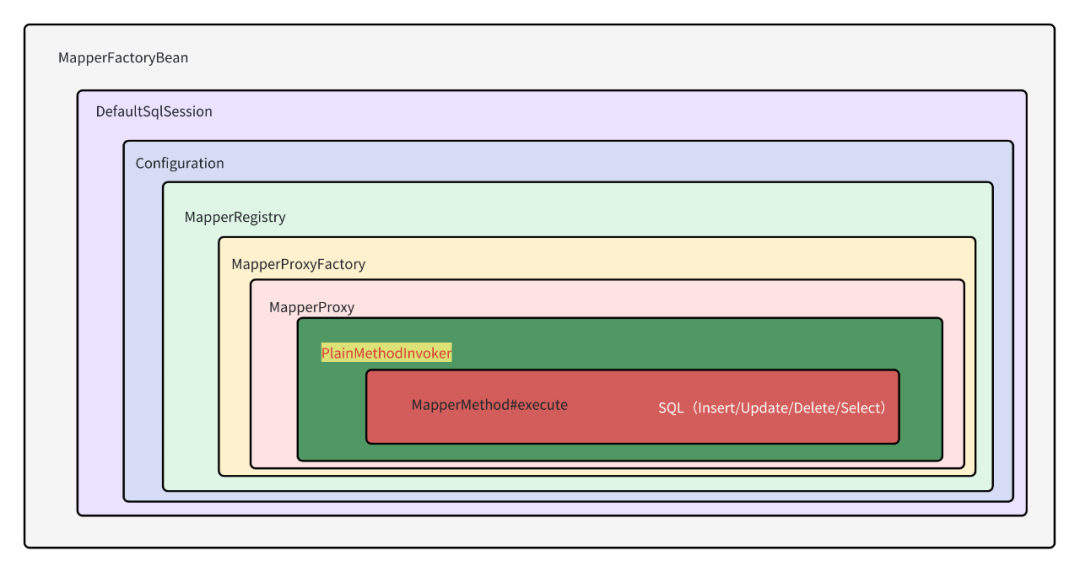
1、MapperMethod执行
上面说到的MapperMethod,就是最后SQL被执行的地方了,最核心的方法是execute方法:
org.apache.ibatis.binding.MapperMethod#execute
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}代码分析:
-
INSERT
-
convertArgsToSqlCommandParam:使用ParamNameResolver处理实参列表
-
调用了sqlSession的insert
-
rowCountResult:返回值类型进行转换(非常人性化,给框架点赞)
-
-
UPDATE
-
处理流程同INSERT类似
-
调用了sqlSession的update
-
-
DELETE
-
处理流程同INSERT类似
-
调用了sqlSession的delete
-
-
SELECT
-
executeWithResultHandler:处理返回值为Void且包含ResultHandler
-
executeForMany:处理返回值为集合或数组
-
executeForMap:处理返回值为Map
-
executeForCursor:处理返回值为Cursor
-
剩下的就返回单一对象的情况
-
你以为分析到此就结束?不,还有sqlSession的执行!
2、SqlSession执行
DefaultSqlSession实现了SqlSession接口定义的方法,并且为每种数据库操作提供了重载,见下图:

2.1、insert
额,底层原来是调用的update。。
@Override
public int insert(String statement, Object parameter) {
return update(statement, parameter);
}2.2、update
@Override
public int update(String statement, Object parameter) {
try {
dirty = true;
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.update(ms, wrapCollection(parameter));
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}-
获取MappedStatement
-
通过Executor进行update操作
2.3、delete
额,底层原来也是调用的update。。
@Override
public int delete(String statement) {
return update(statement, null);
}2.4、select
@Override
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}-
获取MappedStatement
-
通过Executor进行query操作
你以为分析到此就结束?不,还有Executor的执行!
3、Executor执行
BaseExecutor是模板类,包含了基础的数据库操作。
3.1、update
org.apache.ibatis.executor.BaseExecutor#update
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}SimpleExecutor则是默认的执行器,我们主要围绕它进行展开,继续关注doUpdate方法,继续往下debug到SimpleExecutor的内容。
org.apache.ibatis.executor.SimpleExecutor#doUpdate
/**
* 执行更新操作的实现方法
*
* @param ms 映射语句对象,包含执行的SQL信息
* @param parameter 传递给SQL的参数
* @return 更新操作影响的行数
* @throws SQLException 如果执行过程中发生SQL异常
*/
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
// 获取配置对象,用于创建StatementHandler
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler,负责执行SQL语句
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null);
// 准备SQL语句并返回Statement对象
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行更新操作并返回影响的行数
return handler.update(stmt);
} finally {
// 关闭Statement资源
closeStatement(stmt);
}
}代码分析:
-
获取Configuration信息
-
新建一个StatementHandler
-
prepareStatement:预处理
-
handler.update(stmt):执行更新操作并返回影响的行数
我们发现,最终的执行,是交给了StatementHandler的实现类来操作的
3.2、select
BaseExecutor#query:提供了缓存管理和事务管理的基本功能
org.apache.ibatis.executor.BaseExecutor#query
/**
* 查询数据并返回结果列表
*
* @param ms 映射语句对象,包含SQL模板和其他配置信息
* @param parameter 传递给SQL语句的参数
* @param rowBounds 用于分页查询的行范围
* @param resultHandler 结果处理器,用于处理查询结果
* @return 返回一个包含查询结果的列表
* @throws SQLException 如果查询过程中发生SQL异常
*
* 此方法是执行查询的核心方法之一它负责根据提供的参数和配置信息执行SQL查询,
* 并将结果传递给结果处理器进行处理或者封装成列表返回
*/
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 准备SQL语句并生成缓存键CacheKey
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
// 执行查询并返回结果
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
/**
* 查询数据库并返回结果列表
* 此方法是执行查询的核心部分,负责处理缓存、数据库查询以及结果处理
*
* @param ms 映射语句对象,包含查询的SQL和配置信息
* @param parameter 查询参数,可以是任何类型
* @param rowBounds 行范围对象,用于分页查询
* @param resultHandler 结果处理器,用于处理查询结果
* @param key 缓存键,用于标识查询缓存
* @param boundSql 准备好的SQL语句对象
* @return 查询结果列表,元素类型为E
* @throws SQLException 如果查询过程中发生数据库访问错误
*/
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 在查询堆栈为空且映射语句要求刷新缓存时,清除本地缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// 增加查询堆栈深度,防止递归查询导致的问题
queryStack++;
// 尝试从本地缓存中获取结果,如果resultHandler为null且缓存中存在结果,则使用缓存结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// 如果从缓存中获取到结果,处理本地缓存的输出参数
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 如果缓存中没有结果,从数据库查询数据
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
// 减少查询堆栈深度,确保资源正确释放
queryStack--;
}
// 当查询堆栈为空时,处理延迟加载和本地缓存
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
// 开启了statement级别的缓存,那么要清理会话级别的缓存数据
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
/**
* 从数据库中查询数据,并将结果存储在缓存中
* 如果声明类型为CALLABLE,则还将输出参数存储在缓存中
*
* @param ms 映射语句对象,包含SQL信息和配置
* @param parameter 查询参数
* @param rowBounds 行范围,用于分页
* @param resultHandler 结果处理器,用于处理查询结果
* @param key 缓存键,用于存储和检索缓存中的数据
* @param boundSql 编译后的SQL语句和参数映射
* @return 查询结果列表
* @throws SQLException 如果查询过程中发生SQL异常
*/
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 先在本地缓存中放入执行占位符,表示查询正在进行
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 执行查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 查询结束后,从本地缓存中移除执行占位符
localCache.removeObject(key);
}
// 将查询结果放入本地缓存
localCache.putObject(key, list);
// 如果声明类型为CALLABLE,则将输出参数放入本地缓存
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
/**
* 执行查询方法
*
* @param ms 映射语句对象,包含了一条SQL语句的配置信息
* @param parameter 传递给SQL语句的参数
* @param rowBounds 用于分页查询的参数,定义了起始记录和结束记录
* @param resultHandler 结果处理器,用于处理查询结果
* @param boundSql 编译后的SQL语句对象,包含了最终执行的SQL和参数映射
* @return 返回查询结果列表,列表中的元素类型由泛型E指定
* @throws SQLException 如果查询过程中发生SQL异常
*
* 此方法负责执行映射语句中的SQL查询,并通过StatementHandler处理查询结果
* 它封装了查询过程,包括创建StatementHandler、准备SQL语句、执行查询和关闭资源
*/
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
// 获取配置对象,Configuration包含了全局配置信息
Configuration configuration = ms.getConfiguration();
// 创建StatementHandler,用于处理SQL语句执行和结果集处理
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 准备SQL语句,包括创建Statement和设置参数等
stmt = prepareStatement(handler, ms.getStatementLog());
// 执行查询并返回结果
return handler.query(stmt, resultHandler);
} finally {
// 关闭Statement,释放资源
closeStatement(stmt);
}
}上面的代码很长,但是我们最终发现,到底也是交给statement处理最后的sql。
我们可以用一个流程图来解析
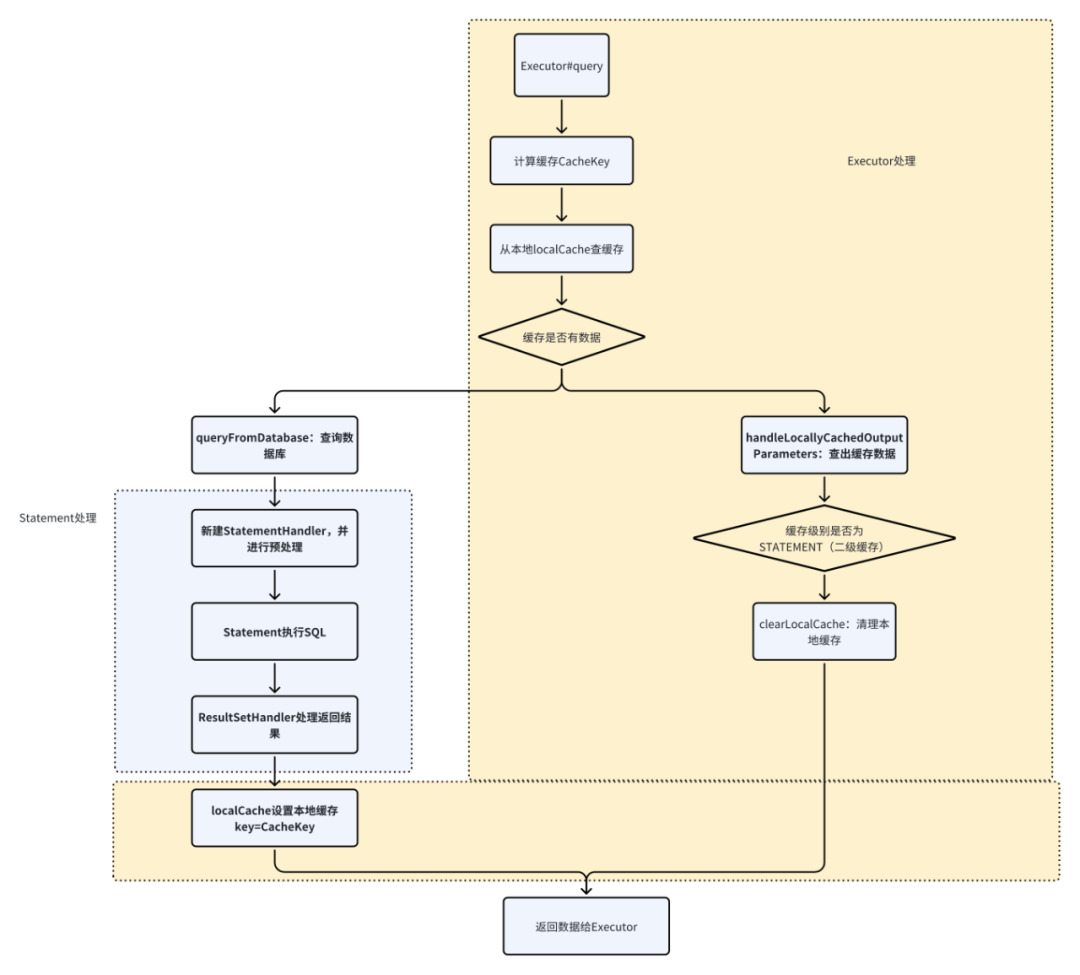
一级缓存 - CacheKey
上面代码的CacheKey,实际上就是SqlSession对象开启时,默认使用的一级缓存,它的生命周期跟SqlSession一样。
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}CacheKey对象由以下几个部分构成:id、offset和limit、sql、用户提交参数、Environment的id五部分构成。
一级缓存的线程安全
mybatis中的一级缓存是存放在hashMap中的,之所以没有用线程安全的集合,主要是因为SqlSession都是线程不安全的,所以没有必须要。
而SqlSession线程安全则是交给了每次触发行为的clearCache()方法,当每次执行sql完毕后,都会清理掉缓存的内容,这样就可以避免缓存所引起的线程安全问题!
其他Executor介绍
| 类型 | 特点 | 缓存 |
| SimpleExecutor | 专注实现4个基本方法实现 | 一级缓存 |
| ReuseExecutor | 减少SQL预编译开销、创建和销毁Statement对象开销,提高性能 | 一级缓存 |
| BatchExecutor | 批量处理优化方式,将多条SQL发送给数据库执行,减少网络方面开销,提高性能 | 一级缓存 |
| CachingExecutor | 增加二级缓存-statement级别的开销,减少数据库执行次数,提高性能 | 一级缓存 二级缓存 |
下面我们着重讲解一下CachingExecutor。
CachingExecutor
CachingExecutor封装了一个用于执行数据库操作的Executor对象,还有管理二级缓存的TransactionalCacheManager对象。
二级缓存
二级缓存:应用级别的缓存,由 TransactionalCacheManager&TransactionalCache两个组件来实现:
-
TransactionalCache:继承了Cache接口,保存某个SqlSession某个事务需要加的二级缓存数据
-
TransactionalCacheManager:用于管理CachingExecutor使用的二级缓存对象,即key。
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//【1】查询所在Namespace对应的二级缓存
Cache cache = ms.getCache();
if (cache != null) {
//【2】
flushCacheIfRequired(ms);
//【3】
if (ms.isUseCache() && resultHandler == null) {
//【4】
ensureNoOutParams(ms, boundSql);
//【5】
List<E> list = (List<E>) tcm.getObject(cache, key);
//【6】
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//【7】
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
}代码分析:
-
【1】ms.getCache()
-
获取缓存对象:查询所在Namespace对应的二级缓存(是否开启)
-
-
【2】flushCacheIfRequired(ms) -二级缓存什么时候需要清理呢?这里就是答案了!
-
缓存cache有数据 且 MappedStatement 的配置了需要清空缓存。
-
-
【3】ms.isUseCache()
-
检查是否使用缓存:如果 MappedStatement 配置了使用缓存且没有 ResultHandler,则继续执行以下步骤
-
-
【4】ensureNoOutParams:确保没有输出参数:调用 ensureNoOutParams 方法,确保查询语句没有输出参数。
-
【5】tcm.getObject:取出二级缓存
-
【6】尝试从二级缓存中获取查询结果。如果缓存中存在结果,则直接返回。
-
如果缓存中没有结果,则委托给 delegate 执行查询,并将结果存入缓存。
-
-
【7】没有启动二级缓存,则直接调用底层的Executor,最终返回查询结果。
二级缓存关系图如下
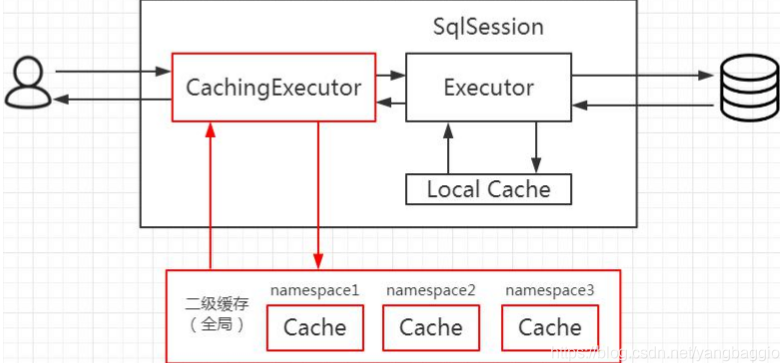
二级缓存的数据结构
MyBatis的二级缓存构建是通过装饰器模式实现的
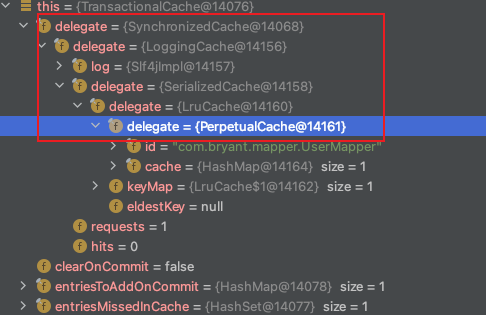
装饰链:SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache
SynchronizedCache:同步Cache,实现比较简单,直接使用synchronized修饰方法。
LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。
SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的Copy,用于保存线程安全。
LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value。
PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap二级缓存的线程安全
每当执行 insert、update、delete,flushCache=true 时,二级缓存都会被清空。
二级缓存的数据提交
二级缓存必须要在会话事务提交之后,才能生效!在查询到结果后,会调用 SqlSession 的 commit 方法进行提交。
public class TransactionalCache implements Cache {
private final Cache delegate;
private boolean clearOnCommit;
private final Map<Object, Object> entriesToAddOnCommit;
private final Set<Object> entriesMissedInCache;
public void commit() {
// 【1】提交事务前,清空已有的二级缓存脏数据
if (clearOnCommit) {
delegate.clear();
}
//【2】将entriesToAddOnCommit集合,保存到二级缓存
flushPendingEntries();
// 【3】clearOnCommit重置为false
reset();
}
private void flushPendingEntries() {
// 【3】遍历entriesToAddOnCommit集合,将其中记录的缓存添加到二级缓存里面
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
// 【4】遍历entriesMissedInCache集合,将entriesToAddOnCommit集合没有的缓存项目,追加到二级缓存里
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
}-
【1】提交事务前,清空已有的二级缓存脏数据
-
【2】将entriesToAddOnCommit集合,保存到二级缓存
-
【3】遍历entriesToAddOnCommit集合,将其中记录的缓存添加到二级缓存里面
-
【4】遍历entriesMissedInCache集合,将entriesToAddOnCommit集合没有的缓存项目,追加到二级缓存里
一级缓存和二级缓存对比
为了增加查询的性能,MyBatis 提供了二级缓存架构,分为一级缓存和二级缓存。
这两级缓存最大的区别就是:
-
一级缓存是会话级别的,只要出了这个 SqlSession,缓存就没用了
-
二级缓存可以跨会话,多个会话可以使用相同的缓存
-
一级缓存使用简单,默认就开启。二级缓存需要手动开启,相对复杂,而且要注意的事项也多,否则可能有隐患
-
二级缓存的 key 和一级缓存的 key 是一样的
4、Statement执行
SimpleStatementHandler#update
SimpleStatementHandler#update
/**
* 执行更新操作
*
* @param statement SQL语句的执行对象
* @return 受更新操作影响的行数
* @throws SQLException 如果执行更新操作时发生错误
*/
@Override
public int update(Statement statement) throws SQLException {
// 获取SQL语句
String sql = boundSql.getSql();
// 获取传递给SQL语句的参数
Object parameterObject = boundSql.getParameterObject();
// 获取键生成器
KeyGenerator keyGenerator = mappedStatement.getKeyGenerator();
// 用于记录受影响的行数
int rows;
// 如果键生成器是Jdbc3KeyGenerator类型
if (keyGenerator instanceof Jdbc3KeyGenerator) {
// 执行SQL并返回生成的键
statement.execute(sql, Statement.RETURN_GENERATED_KEYS);
// 获取受影响的行数
rows = statement.getUpdateCount();
// 在执行完SQL后处理生成的键
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else if (keyGenerator instanceof SelectKeyGenerator) {
// 如果键生成器是SelectKeyGenerator类型
// 执行SQL但不返回生成的键
statement.execute(sql);
// 获取受影响的行数
rows = statement.getUpdateCount();
// 在执行完SQL后处理生成的键
keyGenerator.processAfter(executor, mappedStatement, statement, parameterObject);
} else {
// 如果键生成器不是上述两种类型
// 简单执行SQL
statement.execute(sql);
// 获取受影响的行数
rows = statement.getUpdateCount();
}
// 返回受影响的行数
return rows;
}keyGenerator.processAfter
Jdbc3KeyGenerator为例子
@Override
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
processBatch(ms, stmt, parameter);
}
public void processBatch(MappedStatement ms, Statement stmt, Object parameter) {
// 【1】
final String[] keyProperties = ms.getKeyProperties();
if (keyProperties == null || keyProperties.length == 0) {
return;
}
// 【2】
try (ResultSet rs = stmt.getGeneratedKeys()) {
final ResultSetMetaData rsmd = rs.getMetaData();
final Configuration configuration = ms.getConfiguration();
if (rsmd.getColumnCount() < keyProperties.length) {
// Error?
} else {
// 【3】
assignKeys(configuration, rs, rsmd, keyProperties, parameter);
}
} catch (Exception e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e, e);
}
}我们可以用一个流程图来解析
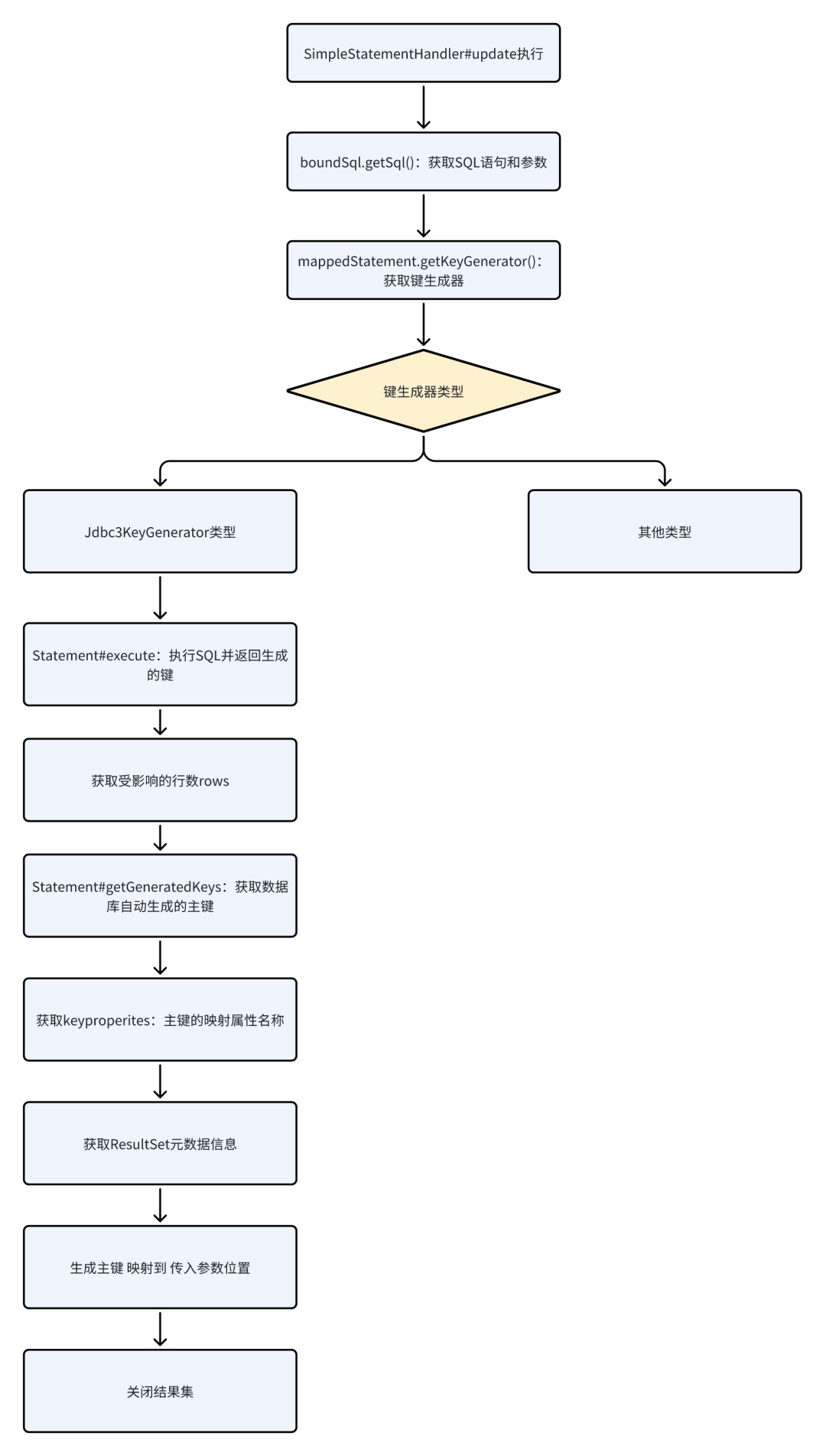
SimpleStatementHandler#query
/**
* 执行查询并处理结果集
*
* @param statement SQL语句的封装对象,用于执行SQL语句
* @param resultHandler 结果集处理对象,用于处理查询结果
* @return 返回一个包含查询结果的列表
* @throws SQLException 如果执行SQL语句时发生错误
*
*/
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 从BoundSql对象中获取SQL语句
String sql = boundSql.getSql();
// 执行SQL语句
statement.execute(sql);
// 处理并返回结果集
return resultSetHandler.handleResultSets(statement);
}总结
以上是SpringBoot集成了Mybatis的框架代码源码分析,我们从2个方面入手:
-
初始化时的Mybatis对MapperMethod的层层封装
-
运行期的MapperMethod执行
总结了以下知识点:
-
SpringBoot自动装载原理
-
一级缓存和二级缓存的区别和线程安全
-
主键生成器
-
SqlSessionInterceptor的代理模式
其他文章
多线程反思(中):对ThreadPoolExecutors的思考
线程安全反思录(上):ThreadLocal到底安全不?
Spring事务管理:应用实战案例和规则
Spring源码分析:bean加载流程
SpringCloud源码:客户端分析(一)- SpringBootApplication注解类加载流程
SpringCloud源码:客户端分析(二)- 客户端源码分析
Kafka消息堆积问题排查
基于SpringMVC的API灰度方案
理解到位:灾备和只读数据库
SQL治理经验谈:索引覆盖
Mybatis链路分析:JDK动态代理和责任链模式的应用
大模型安装部署、测试、接入SpringCloud应用体系
Mybatis插件-租户ID的注入&拦截应用
![[IAA系列] Image Aesthetic Assessment](https://i-blog.csdnimg.cn/direct/c57c9a90a3274471a4988630c0062375.png)