在深入研究 Amazon 的 PyTorch S3 连接器之前,有必要介绍一下它要解决的问题。许多 AI 模型需要使用无法放入内存的数据进行训练。此外,许多为计算机视觉和生成式 AI 构建的真正有趣的模型使用的数据甚至无法容纳在单个服务器附带的磁盘驱动器上。解决存储问题很容易。如果您的数据集无法在单个服务器上容纳,则需要与 S3 兼容的对象存储。在云中,这很可能是 Amazon 的 S3 对象存储。对于本地模型训练,您将需要 MinIO。S3 兼容性非常重要,因为 S3 已成为非结构化数据的实际接口,使用 S3 接口的解决方案将为工程师在选择数据访问库时提供更多选择。解决内存问题更具挑战性。您需要找出一种策略,以便在每次需要一批数据进行训练时读取数据,而不是在训练管道开始时加载一次数据集。一种常见的方法是在训练管道开始时加载对象路径列表,然后在批处理此路径列表时,检索每个对象以获取实际的对象数据。下面的两个可视化效果显示了前端加载与批量加载的详细信息。

Training Pipeline,用于在训练管道开始时检索整个数据集
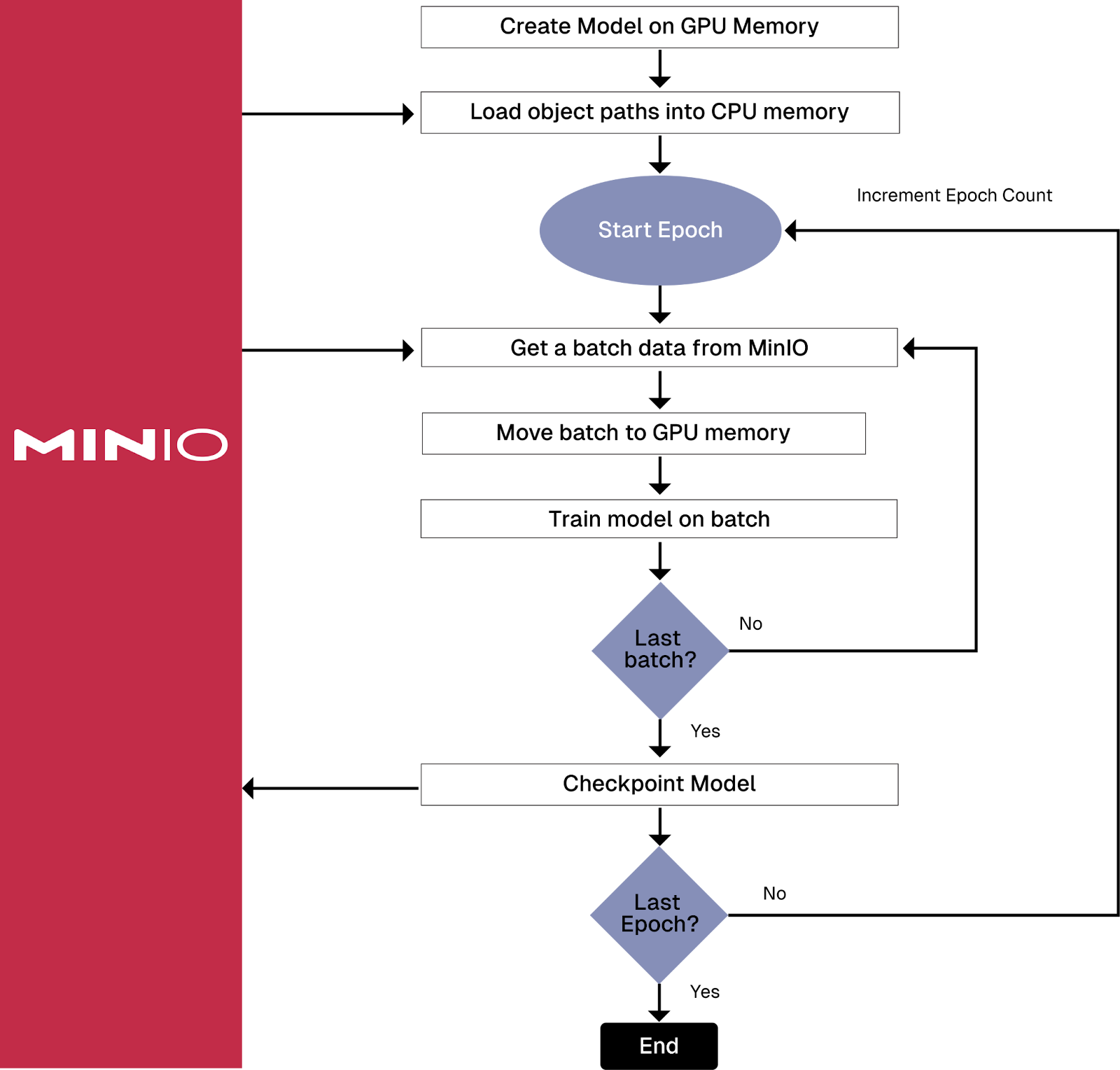
从存储中检索每个批次的数据的训练管道
如您所见,批量加载会给您的网络和存储解决方案带来更大的负担,这两者都需要快速。这是 Amazon 的 S3 Connector for PyTorch 解决“大型数据集问题”的方法之一,它提高了数据访问效率,减少了需要编写的代码量。事实证明,以前曾尝试解决大型数据集问题。让我们研究一下历史,并简要谈谈 Amazon 新连接器之前的库。其中许多库仍然可用,因此了解它们是什么非常重要,这样您就不会使用它们。
昔日的图书馆
Amazon 于 2021 年 9 月宣布推出适用于 PyTorch 的 Amazon S3 插件。这个插件从未作为真正的 Python 库进入 PyPI。相反,它可以通过 Amazon 的容器注册表获得,也可以从其 GitHub 存储库安装。如果您今天导航到这篇文章,您将看到一条通知,推荐适用于 PyTorch 的 S3 连接器。2023 年 7 月,PyTorch 宣布推出基于 CPP 的 S3 IO DataPipe。这个库看起来很有前途,因为它是作为 C++ 扩展实现的(将其解释为意味着它会非常快),并且具有用于列出和加载对象的类。列出 S3 存储桶中的对象有时可能会很慢,因此看起来 PyTorch 人员走在正确的道路上。原始公告仍然存在,没有警告,但如果您导航到 S3 IO Datapipe 文档的 GitHub 页面,您将看到弃用警告和使用 S3 Connector for PyTorch 的建议。用户文档也有类似的警告。现在我们知道了什么不应该使用,让我们看看适用于 PyTorch 的 S3 连接器。
适用于 PyTorch 的 S3 连接器简介
2023 年 11 月,Amazon 宣布推出适用于 PyTorch 的 S3 连接器。适用于 PyTorch 的 Amazon S3 连接器提供了专为 S3 对象存储构建的 PyTorch 数据集基元(数据集和数据加载器)的实现。它支持用于随机数据访问模式的地图样式数据集和用于流式处理顺序数据访问模式的可迭代样式数据集。在这篇文章中,我将重点介绍地图样式的数据集。在以后的文章中,我将介绍可迭代样式的数据集。此外,此连接器的文档仅显示了从 Amazon S3 加载数据的示例 - 我将向您展示如何对 MinIO 使用它。适用于 PyTorch 的 S3 连接器还包括一个检查点接口,用于将检查点直接保存和加载到 S3 存储桶中,而无需先保存到本地存储。如果您还没有准备好采用正式的 MLOps 工具,而只需要一种简单的方法来保存模型,那么这是一个非常好的选择。我还将在以后的文章中介绍此功能。为了好玩,让我们手动构建一个地图样式的数据集。如果您需要连接到不兼容 S3 的数据源,则需要采用这种技术。
手动构建地图样式数据集
地图样式数据集是通过实现一个类来创建的,该类覆盖了 PyTorch 的 Dataset 基类中的 getitem() 和 len() 方法。实例化后,各个样本将映射到索引或键。下面的代码显示了如何覆盖这些方法。它使用 MinIO SDK 手动检索存储的对象并对其应用转换。完整的代码下载可以在这里找到。
class ImageDatasetMap(Dataset):
def __init__(self, bucket_name: str, image_list: List[str], y, transform=None):
self.bucket_name = bucket_name
self.X = image_list
self.y = y
self.transform = transform
def __len__(self):
return len(self.y)
def __getitem__(self, index):
img = du.get_image_from_minio(self.bucket_name, self.X[index])
if self.transform is not None:
img = self.transform(img)
return img, self.y[index]
请注意这个类的两件事。首先,当它被实例化时,它会收到一个 S3 路径列表,而不是一个 S3 对象列表。本文的代码下载中使用以下函数来获取存储桶中的对象列表。
def get_mnist_lists(bucket_name: str, split: str='train',
smoke_test_size: int=0) -> Tuple[Any]:
# Get a list of objects and split them according to train and test.
object_list = get_object_list(bucket_name, split)
X = []
y = []
for path in object_list:
X.append(path)
label = int(path.split('/')[1]) #int(obj[6])
y.append(label)
if smoke_test_size > 0:
X = X[0:smoke_test_size]
y = y[0:smoke_test_size]
return X, y
其次,每次请求单个样本时,都会连接到数据源 MinIO 以检索样本。换句话说,将对数据集中的每个单独对象发出网络请求。下面的代码片段显示了如何实例化这个类并使用 dataset 对象创建一个 Dataloader。
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# The file loader type will download and load the training data directly into a
# dataset.
# Get a list of objects and split them according to train and test.
X_train, y_train = du.get_mnist_lists(bucket_name)
train_dataset = ImageDatasetMap(bucket_name, X_train, y_train, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True,
num_workers=num_workers)
最后,下面的代码段是一个简短的训练循环,显示了如何使用这个数据加载器。高亮显示的代码是批处理循环的开始。每当 for 循环产生并返回一批 ImageDatasetMap 对象时,就会发生 IO。此时,将调用所有 getitem() 方法。这会导致调用 MinIO 来检索对象数据。例如,如果您的批次大小设置为 200,则此循环的每次迭代将导致 200 次网络调用,以检索当前训练批次所需的 200 个样本。
# Epoch loop
for epoch in range(training_parameters['epochs']):
# Batch loop
for images, labels in loader:
# Move to the specified device.
images, labels = images.to(device), labels.to(device)
# Start of compute time for the batch.
compute_start = time.perf_counter()
# Flatten MNIST images into a 784 long vector.
images = images.view(images.shape[0], -1)
# Training pass
optimizer.zero_grad()
output = model(images)
loss = loss_func(output, labels)
loss.backward()
optimizer.step()
上面的代码使您的训练循环受 IO 限制。如果您的数据集太大,无法在训练管道开始时加载到内存中,并且每个样本都是一个单独的对象,那么这是在模型训练期间访问数据集的最佳选择。
将 S3 连接器连接到 MinIO
将 S3 连接器连接到 MinIO 就像设置环境变量一样简单。之后,一切都会顺利进行。诀窍是以正确的方式设置正确的环境变量。本文的代码下载使用 .env 文件来设置环境变量,如下所示。此文件还显示了我用于使用 MinIO Python SDK 直接连接到 MinIO 的环境变量。请注意,AWS_ENDPOINT_URL 需要 protocol,而 MinIO 变量不需要。此外,你可能会注意到 AWS_REGION 变量的一些奇怪行为。从技术上讲,访问 MinIO 时不需要它,但如果为此变量选择错误的值,则 S3 连接器中的内部检查可能会失败。如果您收到这些错误之一,请仔细阅读该消息并指定它请求的值。
AWS_ACCESS_KEY_ID=admin
AWS_ENDPOINT_URL=http://172.31.128.1:9000
AWS_REGION=us-east-1
AWS_SECRET_ACCESS_KEY=password
IMAGENET_BUCKET_NAME=imagenet
MINIO_URL=172.31.128.1:9000
MINIO_ACCESS_KEY=admin
MINIO_SECRET_KEY=password
MINIO_SECURE=false
MNIST_BUCKET_NAME=mnist
使用 S3 连接器创建地图样式数据集
要使用 S3 连接器创建地图样式数据集,您无需像上一节中那样编写代码和创建类。S3MapDataset.from_prefix() 函数将为您完成所有工作。此函数假定您已设置环境变量以连接到 S3 对象存储,如上一节所述。它还要求可以通过 S3 前缀找到您的对象。下面显示了一个演示如何使用此函数的代码段。
from s3torchconnector import S3MapDataset
uri = 's3://mnist/train'
aws_region = os.environ['AWS_REGION']
train_dataset = S3MapDataset.from_prefix(uri, region=aws_region,
transform=MNISTTransform(transform))
请注意,URI 是 S3 路径。在路径 mnist/train 下可以递归找到的每个对象都应该是属于训练集的对象。上述函数还需要一个 transform 来将对象转换为张量并确定标签。这是通过如下所示的可调用类的实例完成的。
from s3torchconnector import S3Reader
class MNISTTransform:
def __init__(self, transform):
self.transform = transform
def __call__(self, object: S3Reader) -> torch.Tensor:
content = object.read()
image_pil = Image.open(BytesIO(content))
image_tensor = self.transform(image_pil)
label = int(object.key.split('/')[1])
return (image_tensor, label)
这就是使用 S3 Connector for PyTorch 创建地图样式数据集所需要做的全部工作。
结论
适用于 PyTorch 的 S3 连接器易于使用,工程师在使用时编写的数据访问代码更少。在本文中,我展示了如何将其配置为使用环境变量连接到 MinIO。配置完成后,三行代码创建一个 dataset 对象,并使用简单的可调用类转换 dataset 对象。高速存储和高速数据访问与高速计算齐头并进。适用于 PyTorch 的 S3 连接器专为高效 S3 访问而构建,由为我们提供 S3 的公司编写。最后,如果您的网络是训练管道中最薄弱的环节,请考虑创建包含多个样本的对象,您甚至可以使用 tar 或 zip 来生成这些样本。Iterable 样式的数据集专为这些场景而设计。我关于 PyTorch 的 S3 连接器的下一篇文章将介绍这项技术。