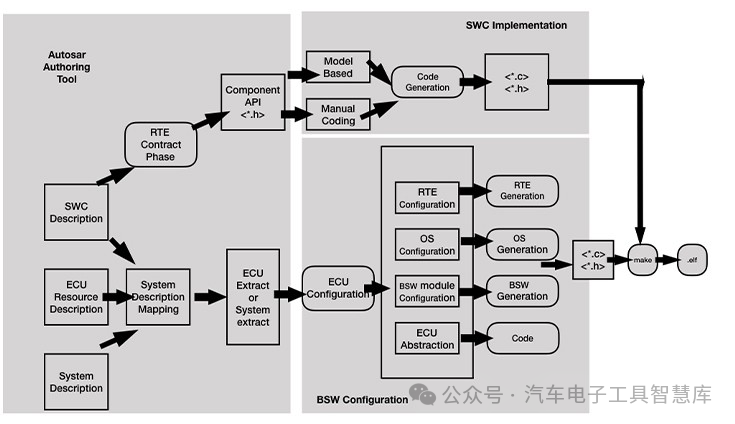
SE结构指的是Squeeze-and-Excitation(SE)模块,是一种广泛应用于卷积神经网络中的结构,旨在提升网络对特征通道的重要性建模能力。SE模块通过学习到特征通道之间的关系,并自适应地为每个通道分配权重,从而提升网络在特征表达上的能力。
1. SE结构的核心思想
SE模块的核心思想是**“通道注意力机制”**,即通过关注和重新加权每个通道的重要性,使网络能够更好地捕获哪些通道特征对任务更为重要。它包含以下几个步骤:
-
Squeeze(压缩)操作:通过全局平均池化操作,将每个通道的空间维度信息压缩为一个标量。这一步的作用是聚合每个通道的全局信息。假设输入特征图的维度为 H × W × C H \times W \times C H×W×C,其中 H H H为高度, W W W为宽度, C C C为通道数,那么通过全局平均池化后,得到一个 C C C维的向量,公式为:
z c = 1 H × W ∑ i = 1 H ∑ j = 1 W X c ( i , j ) z_c = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_c(i, j) zc=H×W1i=1∑Hj=1∑WXc(i,j)
其中, X c ( i , j ) X_c(i, j) Xc(i,j)表示第 c c c个通道在位置 ( i , j ) (i, j) (i,j)的值。 -
Excitation(激励)操作:通过一个全连接层(通常是两个全连接层)来对上述得到的向量进行非线性变换,从而生成每个通道的权重。具体过程如下:
- 第一个全连接层降低通道维度(通常是 r r r倍的压缩比, r r r为超参数)。
- 使用ReLU激活函数:
s = ReLU ( W 1 z ) s = \text{ReLU}(W_1z) s=ReLU(W1z) - 第二个全连接层恢复维度:
s = σ ( W 2 s ) s = \sigma(W_2s) s=σ(W2s)
其中, W 1 W_1 W1和 W 2 W_2 W2分别是全连接层的权重矩阵, σ \sigma σ是Sigmoid激活函数,用于将输出映射到(0, 1)之间的权重值。
-
Reweighting(重新加权)操作:将每个通道的权重重新分配给原始特征图。即将每个通道的特征乘以对应的权重值,实现特征的重新加权,公式为:
X ~ c = s c ⋅ X c \tilde{X}_c = s_c \cdot X_c X~c=sc⋅Xc
其中, s c s_c sc表示通道的权重, X c X_c Xc是原始输入特征图的第 c c c个通道。
2. SE结构的优点
- 轻量高效:SE模块的参数量和计算量相对较小,但对网络的表达能力有显著提升。
- 灵活性强:SE模块可以方便地嵌入到不同的卷积神经网络架构中,例如ResNet、Inception等。
- 提升网络性能:通过通道注意力机制,可以增强网络对重要特征的敏感性,通常能提升图像分类、目标检测等任务的精度。
3. SE结构的应用示例
假设在ResNet网络中嵌入SE模块,这通常称为SE-ResNet,其实现过程为:
- 在每个残差块的输出后插入SE模块,对输出特征进行通道加权。
- 这样不仅保留了ResNet的残差结构优点,还能进一步提升网络对特征的建模能力。
4. 公式总结
- 全局平均池化(Squeeze操作):
z c = 1 H × W ∑ i = 1 H ∑ j = 1 W X c ( i , j ) z_c = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_c(i, j) zc=H×W1i=1∑Hj=1∑WXc(i,j) - Excitation操作:
s = σ ( W 2 ⋅ ReLU ( W 1 ⋅ z ) ) s = \sigma(W_2 \cdot \text{ReLU}(W_1 \cdot z)) s=σ(W2⋅ReLU(W1⋅z)) - 重新加权操作:
X ~ c = s c ⋅ X c \tilde{X}_c = s_c \cdot X_c X~c=sc⋅Xc
总结:SE模块通过通道注意力机制来动态调整特征通道的重要性,提高了网络的表达能力和性能,同时其简单高效的设计使其易于集成到各种网络中。

![【YOLOv11[基础]】实例分割Seg | 导出ONNX模型 | ONN模型推理以及检测结果可视化 | python](https://i-blog.csdnimg.cn/direct/3dcf1673aaa94ce4b36e27278551f752.png)