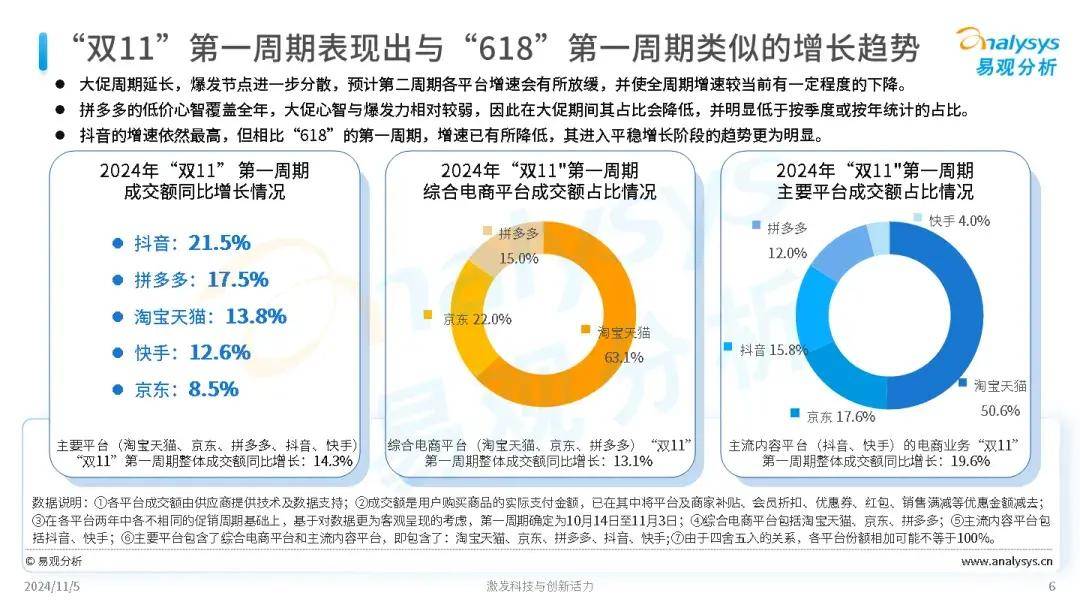
目录
TiDB整体架构
TiDB架构图
组件-TiDB Server
架构图
流程
关系型数据转成kv
编辑
组件-TiKV Server
架构图
主要功能:
列簇
组件-列存储TiFlash
组件-分布式协调层:PD
PD架构图
路由
Region Cache
back off
TSO分配
概念
解决性能瓶颈
高可用设计
调度
信息收集
生成调度
执行调度
Label与高可用
事务
单行数据修改的流程
多行数据修改流程(分布式)
锁
痛点(tidb 6.0以后版本优化)
内存悲观锁
原子性
MVCC和二段式提交
副本机制
region
raft日志
在线ddl
读取数据
架构图
DML读流程
SQL的Parse与Compile
rocksDB查找数据
热点小表缓存(cache table)
编辑
读取时保证读的是主节点机制
IndexRead
leaseRead
Follower Read
Coprocessor
写入数据
架构图
DML写流程
rocksDB写入
RocksDB
流程
内存写入磁盘的流程
raft日支复制过程:
propose阶段
append阶段
replicate阶段
commited阶段
apply阶段
集群选举
初始化的选举
运行过程中主节点发生异常的选举
多个从节点同时发起选举
基础概念
集群管理(TIME)
痛点(tidb 6.0以后版本优化):
解决方案
HTAP
什么是htap
OLTP(联机事务处理)和OLAP(联机分析处理)
传统解决方案
MPP架构
过滤
交换
连接
聚合步骤的数据交换
编辑
使用场景
TiFlash
异步复制
一致性读取
智能选择
placement rule
痛点(tidb 6.0以后版本优化):
使用placement rule之后
tikv打标签
设置放置策略
建表语句中关联放置策略
性能
top sql
痛点(tidb 6.0以后版本优化):
解决方案
TiDB整体架构
TiDB集群主要包括三个核心组件:TiDB Server,PD Server 和TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator组件
TiDB作为新一代的NewSQL数据库,在数据库领域已经逐渐站稳脚跟,结合了Etcd/MySQL/HDFS/HBase/Spark等技术的突出特点,随着TiDB的大面积推广,会逐渐弱化OLTP/OLAP的界限,并简化目前冗杂的ETL流程,引起新一轮的技术浪潮。一言以蔽之,TiDB,前景可待,未来可期。
TiDB架构图


组件-TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑并通过 PD Server找到存储计算所需数据的TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址

架构图

- protocol layer:协议层,处理客户端的连接
- parse和compile:解析和编译sql,parse输出ast语法书给compile,compile做优化,输出执行计划
- executor:compile的输出执行计划给executor,执行sql,根据不同类型,调用transaction,kv,DistSQL
- DistSQL:对复杂的sql进行封装,比如多表范围查询,join,子查询等,输出是单表的计算任务
- Transaction:处理事务
- kv:根据主键,或者唯一索引等的点查,走这里
- schema load和worker和start job:处理ddl执行
- cache table:缓存写少读多数据
- gc:垃圾回收,因为支持mvcc,在事务变更后,会将变更前的数据保存,为了防止这样的数据太多,定期清理
流程

关系型数据转成kv
聚簇表


组件-TiKV Server
TiKV Server 负责存储数据,用于存储 OLTP 数据,采用 行存储格式,支持 事务机制,TiKV 本身是一个 分布式的 Key-Value 存储引擎。
存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region
TiKV 的 API 在 KV 键值对层面提供对分布式事务支持,默认提供了 SI (Snapshot Isolation) 的隔离级别。
TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。
TiKV 支持高可用和自动故障转移,所有数据都会自动维护多副本(默认为三副本)。
架构图

主要功能:
- 数据持久化:TiKV 在内部选择了基于 LSM-Tree 结构的 RocksDB 引擎(是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎)作为数据存储引擎。可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
-
分布式事务支持:TiKV 的事务采用的是 Google 在 BigTable 中使用的两阶段提交事务模型:Percolator。在每个 TiKV 节点上会单独分配存储锁的空间,称为 CF Lock。
-
副本的强一致性和高可用性:采用 Multi-Raft 机制实现了多副本的强一致和高可用。TiKV 中存储的 Region 会自动分裂与合并,实现动态扩展,并借助 PD 节点可使 Region 在 TiKV 节点中灵活调度。
-
MVCC(多版本并发控制)。
-
Coprocessor(协同处理器)。
将 SQL 中的一部分计算利用协同处理器,下推到 TiKV 节点中完成(即算子下推)。充分利用 TiKV 节点的计算资源实现并行计算,从而减轻 TiDB Server 节点的计算压力。TiKV 节点将初步计算后的数据返回给 TiDB Server 节点,减少了网络带宽的占用

列簇
列簇(Column Family,简称CF)是一种数据存储结构,用于存储具有相同特征的数据列。

组件-列存储TiFlash
用于存储 OLAP 数据,和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以 列存储格式,主要的功能是为分析型的场景加速。
tikv通过日志传输,将日志传给tiflash,当tikv的主节点挂了,但是tiflash不参与投票
tidb server接到申请,会根据类型自动路由到tikv或者tiflash,也可以手工指定

组件-分布式协调层:PD
PD (Placement Driver) 是整个 TiDB 集群的 元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
PD 不仅存储集群元信息,同时还会根据 TiKV 节点实时上报的 数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是 整个集群的“大脑” 。
此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。

PD架构图

PD集群也是主从结构的,有一个leader,另外的节点是follower。集成了ETCD,其Raft协议保证了数据的一致性。
PD中存储了数据的元数据信息,同时提供Region的调度功能。
PD提供全局时钟TSO的功能。
Store:集群中的存储实例,对应TiKV。
Region:数据的存储单元,负责维护存储的数据。包含多个副本,每个副本叫一个Peer。读写操作在主节点(leader节点)进行,相关信息通过Raft协议同步到follower节点。leader和follower之间组成一个group,就是raft group。
PD的主要功能:
- 整个集群的TiKV的元数据存储
- 分配全局ID和事务ID
- 生成全局时间戳TSO
- 收集集群中TiKV的信息,进行调度
- 提供label,支持高可用
- 提供TiDB Dashboard
路由

TiDB Server接收用户的SQL请求,执行器Executor通过TiKV Client与TiKV进行交互,TiKV Client需要先从PD获取到Region的元数据信息。
Region Cache
TiKV Client从PD获取Region的元数据信息,需要与PD进行交互,这会涉及到网络开销、数据传输,为了提高效率,减少数据的网络传输,TiKV Client本地可以将Region的元数据信息缓存起来,供下次使用,这个缓存是Region Cache。
back off
back off:TiKV Client从PD拿到leader信息后到Region进行读取,如果此时原有leader失效,变成follower了,则Region会反馈信息给TiKV Client,让TiKV Client找PD,获取最新的leader,重新去新的leader节点读取数据,这个过程就是back off。back off越多,读取数据的延迟就越高,效率越低。
TSO分配
概念
TSO = physical time logical time
TSO是一个int64的整数;physical time是物理时钟,精确到毫秒;logical time是逻辑时钟,将1号码的物理时钟划分成262144个逻辑时钟。

- tso 请求者 发送请求到pd client,
- pd client同步立刻返回一个对象
- 异步请求pd leader ,此时不是单个请求,在一段时间内的批量申请统一请求,减少网络代价
- tso 请求者虽然没有获取tso,可以进行解析编译等后续动作
- tso做完后续动作,调用wait等待tso的值,等到以后继续动作
- 如果tso没处理完,pd leader已经返回了tso,pd client先把值存在那,等着tso 请求者调用wait函数获取tso值
解决性能瓶颈

PD节点可能会宕机,PD需要将当前已分配的TSO记录存储到磁盘,防止宕机的时候数据丢失。
写磁盘是有磁盘IO的,每次分配一个TSO、写一次磁盘,性能会比较低。PD采用每次分配3秒钟的TSO,在内存缓存中记录了3秒钟的TSO缓存供高并发的TiDB Server排队取用,存储在磁盘的是时间区间,3秒钟写一次磁盘,以提高效率。写磁盘的数据会通过Raft协议同步到其他PD节点。
高可用设计
PD每次缓存3秒的TSO,磁盘3秒钟写一次,磁盘数据通过Raft协议同步到其他节点。
当leader节点宕机,leader节点的缓存会丢失,但磁盘的数据已同步到其他PD节点。其他PD节点因无主而会重新选举leader节点,新leader节点产生后,仅会知道磁盘中存储的数据,原leader中的缓存数据无法恢复。为了保证TSO的单调递增特性,新leader不会再从磁盘中存储的时间窗口内分配TSO,而是新启动一个3秒钟的时间窗口分配TSO。这会导致TSO不严格连续,但能保证TSO单调递增。
调度

信息收集
PD通过心跳收集TiKV的信息。主要包括:Store的心跳和Region的心跳。
Store心跳:报告tikv节点的情况
Region的心跳:报告region情况

生成调度
生成调度(operator)的主要关注的信息包括:
负载均衡、热点Region、集群拓扑、缩容、故障恢复、Region合并等。
执行调度
PD生成好operator后,会将operator发送到相关节点进行执行。

Label与高可用

DC:数据中心
Rack:机柜
对于Region1,由于有两个Region在同一个机柜,所以存在一个机柜坏了后Region1不可用的情况。
对于Region2,由于有两个Region在同一个数据中心,所以存在一个数据中心出问题后Region2不可用的情况。
对于Region3,分布在不同的数据中心、不同的机柜,所以就算一个数据中心出问题,Region3仍然可用。
label,PD的标签功能,主要用于标记一个Region如何分布,PD根据label选择将Region分配到哪里。

TiKV实例会记录自己的信息:server.labels
PD实例上配置label的规则,包括:副本数、隔离级别等信息
PD与TiKV配合使用即可实现label的分配和高可用。
事务
单行数据修改的流程

多行数据修改流程(分布式)

采用二段式提交
1)begin时,通过pd获取时间戳
2)预写入到tikv中,通过cf方式,写入2个列,default和锁
- default(修改的数据),其中会根据id和时间戳生成,default中,对于update和delete,只写入修改后的值,因为修改后的值会覆盖以前的值,不用找以前的值,可以加快速度
- 锁,在多行事务中,一个事物只生成一个主锁,所有行数据共用一个锁,W代表写锁
- 在别的事务想要修改这一行,看锁信息看到已经有别的事务锁定了这一行
- 多行场景:第一行,到tikv节点1,插入一个default和lock列,lock是主锁(有pk标志)
- 多行场景:第二行,到tikv节点2,插入一个default和lock列,注意,lock不是主锁,主锁在节点1中(通过@1查案),只有第一行产生的锁才是主锁
3)提交
- 在tikv中写入write的列,将提交的时间戳写进去
- 在锁的列中,新增一行,D代表删除锁,提交成功
- 在多副本中(后续会讲到),只有超过半数的节点都将数据写入到socksDB后(apply操作完成),才会在此处提交
4)在读取的时候,
- 发现write中有数据,当前时间120,找到最近提交的时间戳110,看开始时间是100,可以根据时间戳找default数据
- 发现write中没数据,看到lock中有锁,此时的default不能读
注意,当写入行信息超过255字节,会直接被存放到write列(不放入default列),如果写入行信息超过255字节,会进入default列中
锁
原本的锁,见上述流程,总结如下

痛点(tidb 6.0以后版本优化)
在tidb server commit后,走到prewrite流程,在tikv的主节点进行上锁
- 在tikv的lock信息,还需要同步到从节点中,但其实没必要,在主节点就可以看到锁了,还增加了网络代价,在不考虑高可用性,从性能角度来讲,这不太好
- 如果只看主节点的锁信息,没必要持久化到磁盘,只在内存中放置就行了
内存悲观锁
注意,这是tidb 6.0以后版本支持的功能
将锁信息放到主节点缓存中,不持久化到磁盘,不复制到从节点
但会出现锁丢失,如果主节点宕机,缓存中的锁没有持久化,会出现事务回滚

可以通过配置,或者输入在线命令,开启内存悲观锁,总结如下

原子性
发生异常,在提交时,tikv node1commit成功,在tikv node2持久化write的时候宕机了
此时查看tikv node2的lock,知道主锁,然后查看主锁状态(已经删除,代表已经提交成功),将tikv node2的数据也变成提交成功
MVCC和二段式提交

按照上面视图举例:
- 两个事务,第一个事务处理时,从TOM改成JACK,对TOM生成一个副本,未提交,此时读取的是TOM的值,修改成JACK是在副本发生的
- 第一个事务提交后,第二个事务还未提交。有JACK的数据(110时间戳成功),还有TOM的数据(老的时间戳),两条数据
- 在120时间戳读取的时候,读取1的数据,是JACK(因为此时第二个事务没有提交,读取的是老的数据)
事务一提交后,事务二没有提交的图,注意,prewrite但未提交,只写入lock锁信息,没有写入default,因为在读的时候,要读取default数据,更新后的数据此时在副本中

副本机制

接到申请后,主节点将日志传输到从节点,主节点负责读写。
主节点定期给从节点发心跳信息,如果从节点超时没收到主节点的心跳,会发起选举
region
region是逻辑单元,存放key value的格式数据,插入数量超过阈值(例如96M),新生成一个region
在delete或者update后,原有region如果扩大,扩大到一定阈值(例如144M)会进行分裂,原有region如果缩小,缩小到一定阈值(例如1M),会进行region的合并,所以region的大小不是固定的
每个region,会构成一个raft日志组
每个region会定期向pd汇报心跳,如果region过多,会产生管理压力
raft日志
TiKV节点中存在两种类型的RocksDB,RocksDB kv是存储的K-V型数据,RocksDB raft存放的是数据从操作指令,即数据操作的增删改查指令,也就是Raft日志

在线ddl
在线ddl变更,不阻塞读写
- 用户发起ddl申请,start job接收申请
- 如果是加/减列,放入tikv的job queue中,如果是索引操作,放入index queue中
- 同一时间段内,只有一个tidb server作为owner,其中的workers工作,定期将job队列的job任务取出来执行,job队列中存放了来自多个tidb server的ddl申请,但此时只有这一个workers执行(不区分ddl申请是否来自于本tidb server),多个tidb server做ddl变更,同一时刻,只有一个tidb server执行ddl。过段时间由PD决定,谁做owner,别的tidb server中的workers作为owner,轮换进行
- schema load会加载执行后的结果,用于下一次执行ddl
- 执行成功后的Job,被放到history queue中

读取数据
架构图

DML读流程

TiDB Server中的Protocol Layer首先接收用户的SQL请求,TiDB Server会到PD获取TSO,以及元数据(包括所在的TiKV、Region、Leader等等信息),同时经过解析模块Parse对SQL进行词法分析和语法分析,再由Compile模块进行编译,最终进行Execute。
SQL的Parse与Compile


Protocol Layer接收到SQL请求后,会由PD Client与PD进行交互,获取TSO。
Parse模块会对SQL进行词法分析、语法分析,生成抽象语法树AST。
Compile分成几个阶段:
- 预处理preprocess,检测SQL的合法性、绑定信息等,判断SQL是否是点查SQL(仅查询一条数据,比如按Key查询),如果是点查语句则不需要执行optimize优化,直接执行即可。
- 优化optimize,逻辑优化,根据关系代数、等价交换等对SQL进行逻辑变换,比如外连接尝试转内连接等;物理优化,基于逻辑优化的结果和统计信息,选择最优的算子。
rocksDB查找数据

block cache:最近最常读取的数据,放到缓存中,在读取的时候,先去block cache中查找,如果没找到,进行下一步
根据顺序,查找:memTable=》immutable=》磁盘
磁盘找到最新的数据,不会读取老数据,因为是追加写,新数据一定在老数据之上的文件中
磁盘文件的每一层,都会根据key进行排序,存放最小和最大的key,如果查找的key不在范围内,找下一个,如果在范围内,用二分法查找
采用布隆过滤器加速:如果布隆过滤器认为可能在,那有可能不在(误判断),如果过滤器认为不在,那肯定不在
热点小表缓存(cache table)

注意,这是tidb 6.0以后版本支持的功能
有租约概念,比如5秒内是租约,租约时间内不许写,只能读,数据在内存中
过了租约时间(5秒),直接写进tikv中,并从tikv中直接读数据
重新续约后,数据加载到内存中,不许写,只能从内存读


读取时保证读的是主节点机制
TiDB Server拿到元数据后去TiKV节点找leader Region读取数据,此时不能完全保证在读取数据的时候原来的leader还是leader。因为这个时间间隔内,原leader可能失效,重新选举了leader,也就是TiDB Server从PD处拿到的leader信息在真正要读数据的这个时间间隔内失效了,变成follower了,就不能读数据了。
要解决这个问题,TiDB采用了读取时进行心跳检测机制,TiDB Server拿到leader信息后,到leader region真正读数据的时候,由该region发起一次心跳检测,检测当前region是否还是leader,如果是,就直接读取数据,如果不是,就不能读取数据,重新获取leader region,从新的leader读取数据。
IndexRead
第2个问题是,抛开MVCC机制,只考虑Raft协议,用户的读操作需要读取之前的请求已经提交的数据。在读取时,如果有写操作存在,则读取被阻塞。什么时候可读?TiDB引入了ReadIndex和ApplyIndex。当读取数据时,先获取到要读取的数据所在的位置(index)。然后寻找Raft日志复制阶段中commited阶段的index,确保commited的index大于要读取的数据的index后,记录commited的index作为ReadIndex值,寻找Raft日志复制阶段中的apply阶段的index作为ApplyIndex值。只有当ApplyIndex的值等于ReadIndex的值时,可以确定当前index的数据已经提交持久化,从而知道要读取的数据所在的index的值已确定持久化,此时读取的数据就是提交后的数据。
leaseRead
Lease Read也可以叫Local Read。因为读取之前,需要发心跳,确定读取的节点的数据是主节点(没有发生主从切换),但如果每次读取都发心跳,会增加网络代价,以下是优化方案


当10:00:00的时候,刚发生过心跳,10:00:00 + election timeout(时间间隔) 的时间点之前,就会确保当前节点一定是主节点,此时不重新发心跳,直接读取主节点数据
Follower Read

follower的数据与leader的数据是一致的,所以读实际上可以从follower读的,也就是读写分离是可以的,前提是:保证follower的数据与leader的数据是线性一致的。
要保证数据的线性一致,Follower Read是在follower节点上按照Index Read的方式读取数据的。
读取的时候,从节点询问主节点提交索引,获取到提交索引(commit index,比如1_97)之后,需要follower节点的apply index等于获取到的commit index后才能进行数据的读取。因为此时提交索引(1_97)之前的数据已经完成了apply,所以从节点的这部分数据也是可以读取的
Coprocessor
协同处理器,可以实现:执行物理算子,算子下推:聚合、全表扫描、索引扫描等。
比如,TiDB Server接收到用户的请求。TiKV的所有数据会发送到TiDB Server做运算,一方面增加网络带宽,一方面TiDB Server的负载会很高。

引入Coprocessor后,可以实现count算子下推。每个TiKV节点计算自己节点上的count,将值传到TiDB Server,TiDB Server只需要对各个节点的进行一次处理就好了。

写入数据
架构图
用户提交写请求,由TiDB Server接收,TiDB Server向PD申请TSO,并获得Region的元数据信息,TiDB Server的写请求会由TiKV中的raftstore pool线程池接收并进行处理,执行Raft日志复制过程(Propose、Append、Replicate、Commited、Apply)完成数据写入操作。

DML写流程

写流程的前半部分,跟读流程一样,可以先看下读流程
rocksDB写入
tidb是用tikv组件完成的持久化
RocksDB

流程
- 接到写申请,先做wal(先写入到日志中),防止断电,故障恢复后从wal日志加载数据。写入的时候不经过操作系统的缓存,直接写入磁盘中
- 写入内存中
- 内存写的数据超过一定数量,内容转存到immutable,并新开一块内存(接收新的申请),转存的步骤为了防止写io的时候发生阻塞,影响memtable的性能
- 异步将immutable内容写入磁盘
- 如果写入非常快,导致immutable超过限制,会触发写流控,进行保护
内存写入磁盘的流程
在内存中进行数据合并,批量写入磁盘,不修改历史数据,进行追加写,速度会很快


先写入level0的文件,内容与immutable内容是一样的
level0文件达到一定数量会到level1级别,进行文件切分和压缩,合并的时候进行排序,在查询的时候通过二分法查找速度会很快(存放的内容是key value形式)
raft日支复制过程:
propose阶段
leader将写请求写入Raft日志,Raft日志的唯一标识是:Region号+日志当前的序号。

append阶段
leader将Raft日志写入到本地的RocksDB。

replicate阶段
leader将本地的Raft日志逐条发送到follower,follower在本地完成append。

commited阶段
follower在完成append的时候,会将状态反馈给leader。

apply阶段
当大多数follower都反馈append成功,leader会认为数据持久化已经稳妥了,就会执行commit,否则leader会认为数据持久化失败,不会进行commit。
注意,只有apply成功后,两段式提交才会写入write的cf中,删除lock,才能读到本次操作后的数据

集群选举
初始化的选举

- 当集群刚启动的时候,所有TiKV节点都是follower,term=1
- 此时follower会一直等待leader的信息,直到超过election timeout(默认10秒钟)的时间都还没等到
- 则region会把自己变成candidate,term=2,并将这个信号发送给其他节点。
- 其他节点收到信号后,会用term值与自己保存的term值进行比较,如果收到的term比自己的term值大,则其他节点会同意这个信号请求,并将自己的term更新成信号中的term值表示一段新关系的开始。
- 当大多数节点都同意,则leader选举成功。
运行过程中主节点发生异常的选举

当集群中有leader的时候,leader会按一定的时间间隔heartbeat time interval(默认10秒)给folloer发送心跳,表示leader存在,follower禁止起义,follower收到心跳信息后,只能按兵不动。
当集群中突然失去leader节点的时候,follower无法收到心跳信号,当超过heartbeat time interval还没收到心跳信号,则有follower就会起义,将自己变成candidate,并发送选举请求给其他节点开始进行选举。
多个从节点同时发起选举

如果在选举leader的过程中,出现多个节点都选择自己做为candidate的,都选自己做leader,则有可能导致无法选举出新的leader。
解决办法就是不同的节点采用随机的、不同的无主选举时间election timeout,防止多个节点同时发起选举。
基础概念
- Election timeout,无主选举时间,超过这个时间还没收到leader的信息就会发起leader选举,对应参数raft-election-timeout-ticks,默认值raft-base-tick-interval
- Heartbeat time interval,心跳时间,leader发送心跳到follower的时间间隔,需要小于Election timeout,对应参数raft-heartbeat-ticks,默认值raft-base-tick-interval
集群管理(TIME)
痛点(tidb 6.0以后版本优化):
随着业务的增长,对集群的管理,原先只能通过命令行方式

解决方案
注意,这是tidb 6.0以后版本支持的功能

HTAP
什么是htap
OLTP(联机事务处理)和OLAP(联机分析处理)
定义:
- OLTP:联机事务处理(Online Transaction Processing),主要用于日常事务处理,如银行交易、销售记录等,强调高吞吐量和实时处理。
- OLAP:联机分析处理(Online Analytical Processing),主要用于数据分析、决策支持,强调复杂查询和多维数据分析。
数据处理方式:
- OLTP:主要处理当前的、详细的数据,强调增删改查(CRUD)操作,数据更新频繁,响应时间短。
- OLAP:处理历史的、汇总的数据,强调复杂查询和数据分析,通常使用数据立方或多维数组存储数据,支持批量数据处理。

传统解决方案

HTAP的要求

TIDB的HTAP解决方案

MPP架构


过滤
第一步,并行节点做过滤,每个节点分别过滤表数据,缩小数据范围

交换
将pid做hash,并将相等的数据做数据交换,让每个节点在查看order.pid=product.pid时,在本节点找数据就行,不用去别的节点找数据,减少网络代价
将order的pid等于1,2,3的数据,和product的pid等于1,2,3的数据,都在一个节点中存放

连接
每个节点并行做连接

聚合步骤的数据交换
将state字段做hash,并将state hash值一样的数据交换到一个节点中

聚合
在tiflush中计算,并将结果发送回tidb server

使用场景



TiFlash
tiflash存放列数据,提供OLAP功能
异步复制
从tikv的leader接收raft log,但不参与投票和选举

一致性读取
每次收到读取请求,TiFlash 中的 Region 副本会向 Leader 副本发起进度校对(一个非常轻的 RPC 请求),只有当进度确保至少所包含读取请求时间戳所覆盖的数据之后才响应读取。
在下面的场景中,生成绿id101数据和黄id22的数据,在2个tikv中,读取的时候也需要2个数据的修改是一致的,不可以读到101的数据但没读到22的数据
T0时刻:生成key是1和999的数据
T1时刻:客户端找tiflash查询,但此时tiflash同步的索引才到绿108,黄20,想要查询的数据是绿101,黄22
T2时刻:客户端将key=1的数据从100改成200
T3时刻:tiflash去tikv查询,获取当前tikv节点绿125,黄31,tiflash就等着这两个值被同步到tiflash
T4时刻:在tiflash同步到了绿125,黄31数据,认为要查询的数据已经同步到tiflash中了
T5时刻:知道查询的时刻是T1,所以T0和T1的数据都是有效数据,T2虽然对数据做了更改,不读取,返回key=1 value=100 ,key=999 value=7的数据






智能选择
自动选择查tikv或者tiflash
下面这个数据,
- product数据从大量数据中找少量数据,适合走索引,走tikv
- sales数据只找一列,从tiflash中查询
- 将数据返回tidb server,做表连接

placement rule
注意,这是tidb 6.0以后版本支持的功能
痛点(tidb 6.0以后版本优化):
跨地域部署的集群,无法本地访问:在多个中心部署时,有北京,纽约,东京,一部分数据在纽约,如果用户在北京,需要跨地域读取数据,因为本地没有副本数据
在北京想要访问T2和T3,但T3的主节点在纽约,每次访问的网路代价都很大,影响业务吞吐量
无法根据业务隔离资源:在纽约中,有3个用户,分别访问T4,T5,T6,都在TIKV5上,出现了瓶颈,TIKV4和TIKV6很清闲,应该让4,5,6都分担一些压力
难以按照业务等级配置资源和副本数:在东京,T7表很重要,希望T7表多几个副本
T8都是一些历史数据,希望T8放到一些冷机器上,将T7放到一些性能好的机器上,T8不要和T7抢资源

使用placement rule之后


tikv打标签

设置放置策略

建表语句中关联放置策略

性能
top sql
痛点(tidb 6.0以后版本优化):
如果发现个别tikv的cpu很高,想要看看哪个sql有问题,用于优化
原本只有集群维度的慢查询,还有sql statements

如果突然出现cpu占用率急速升高,想马上看下哪个sql导致的,无法查看

解决方案
注意,这是tidb 6.0以后版本支持的功能
在tikv的dashboard中新增top sql

参考文章:
TIDB简介及TIDB部署、原理和使用介绍-CSDN博客
百度安全验证
https://blog.csdn.net/wux_labs/article/details/128841334
数据库必知必会:TiDB(7)Placement Driver-CSDN博客