Netty 强大的 ByteBuf
Netty ByteBuf功能可以类比NIO 中 ByteBuffer,那为什么不直接使用NIO 中ByteBuffer?
主要是易用性和扩展性一些方面,有点可以肯定,Netty 基于NIO实现的,底层肯定用了ByteBuffer 。
-
jdk Buffer API 复杂性,读写时需要重要设置position、limit等,很容易出错
-
NIO Buffer 扩展性差,功能有限

ByteBuf 工作原理
回顾之前的文章NIO ByteBuffer读写时需要修改position
独立的读写指针
维护了两个指针 readerIndex ,writerIndex ,读写操作互不影响,读时不会影响写指针,写时也不会影响读指针,操作比NIO更简单
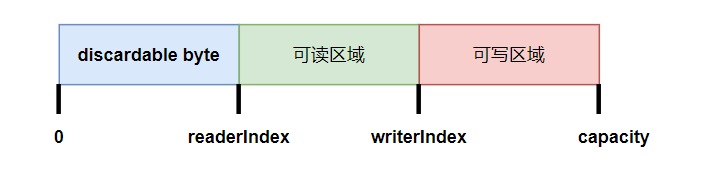
0 <= readerIndex <= writerIndex <= capacity
ByteBuf 类型
ByteBuf实际上是一个抽象类,它有多种实现
-
Heap ByteBuf:这种类型的 ByteBuf 将数据存储在 JVM 堆内存中,受JVM垃圾回收管理。
-
Direct ByteBuf:这种类型的 ByteBuf 使用了直接内存,不受JVM垃圾回收管理,通常可以提供更快的 IO 操作性能,由于不受JVM垃圾回收管理,一般需要手动释放内存。
-
Composite ByteBuf:允许将多个 ByteBuf 组合为一个逻辑上的 ByteBuf,这样可以简化复杂的协议编码解码过程,比如在网络协议编码解码过程中协议数据分为请求头和请求体。
顺序访问索引
- readInt() / readLong() / readDouble() / …
从readerIndex开始读取,并且会修改readerIndex
- writeInt(int value)/ writeLong(Long value)/ 等
从writerIndex 开始写入,也会修改从writerIndex
随机访问索引
getInt(int index)
getLong(int index)
getXXX(int index)
随机读不会修改 readerIndex,也不会涉及内存复制操作,当然ByteBuf会检验索引的合法性,设置无效的索引会导致 IndexOutOfBoundsException。
虽然随机读不会修改指针,但我们也可以手动调整指针 readerIndex(int readerIndex)/writerIndex(int writerIndex)
discardable bytes
discardable bytes 指的0 到 readerIndex之间的字节,这些内容已经读过,按道理可以丢弃以节省内存。
discardReadBytes()方法:这个方法会将 readerIndex 到 writerIndex 之间的数据移动到缓冲区的开始位置,并更新 readerIndex 和 writerIndex 的值。 适当使用可以优化内存,可以优化内存,但不建议频繁使用,因为涉及内存复制,对性能有影响。
查找操作
ByteBuf 提供了多种方法来查找缓冲区中的特定字节或序列。
这些查找操作对于协议解析、数据验证以及其他需要在数据流中定位特定模式的场景非常有用
indexOf(int fromIndex, int toIndex, byte value)
bytesBefore(byte value)
indexOf(int fromIndex, int toIndex, byte[] bytes)
bytesBefore(byte[] bytes)
indexOf(int fromIndex, int toIndex, ByteBuf bytes)
bytesBefore(ByteBuf bytes)
//还支持指定处理器操作
forEachByte(ByteProcessor processor)
forEachByte(int index, int length, ByteProcessor processor)
forEachByteDesc(ByteProcessor processor)
forEachByteDesc(int index, int length, ByteProcessor processor)
查找操作的性能考虑
查找操作的性能会受到ByteBuf大小影响,一些极端情况可能需要多次比较和字节读取操作,这也会增加 CPU 的开销
派生缓冲区
派生缓冲区可以共享底层的字节数据,但具有独立的读写指针,
派生缓冲区很方便地在不复制大量数据的情况下,从不同的角度或范围对原始数据进行操作。
数据共享
派生缓冲区与原始缓存区是数据共享(底层是同一内容的指针引用),数据修改会互相影响。
当然派生缓冲区也可以用于多线程,由于数据共享的,所以不存在数据同步问题,当然可能并发修改,可能需要加锁保证线程安全。
派生缓冲区对于不同的角度查看数据场景非常有用。如协议解析中的数据分段处理(请求体,请求头等)。
派生缓冲区相关API
- duplicate()
- slice()
- slice(int index,int length)
复制操作
复制后的ByteBuf 内容和索引都是互相独立的,复制操作会进行内存复制。
copy()
copy(int index,int length)
总结
ByteBuf 确实比 NIO 中 ByteBuffer 功能强大,相信读者也感受到了,灵活掌握ByteBuf使用,可以轻松应对很多场景。