docker环境下部署kafka
前置条件
Apache Kafka 自 2.8.0 版本开始引入了不依赖 Zookeeper 的“Kafka Raft Metadata Mode”,本文章依然使用Zookeeper 作为集群管理的插件。
#拉去zookeeper镜像
docker pull wurstmeister/zookeeper
#运行zookeeper容器
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
启动后防火墙开放端口2181
su
在这里插入代码片do firewall-cmd --zone=public --add-port=2181/tcp --permanent
重载配置
sudo firewall-cmd --reload
部署kafka容器
#拉去kafka镜像
docker pull wurstmeister/kafka
#运行kakfa进行
docker run -d \
--name kafka \ # 容器名称为 kafka
--restart=always \ # 自动重启策略,始终重启
-p 9092:9092 \ # 将容器的 9092 端口映射到主机的 9092 端口
--link zookeeper \ # 链接到名为 zookeeper 的容器
-e KAFKA_ZOOKEEPER_CONNECT=192.168.253.166:2181 \ # 指定 Zookeeper 的连接地址
-e KAFKA_ADVERTISED_HOST_NAME=192.168.253.166 \ # 广播给 Kafka 客户端的主机名
-e KAFKA_ADVERTISED_PORT=9092 \ # 广播给 Kafka 客户端的端口号
-v /etc/localtime:/etc/localtime \ # 将主机的时区信息挂载到容器中
wurstmeister/kafka # 使用 wurstmeister 提供的 Kafka 镜像
同理需要放开防火墙端口9092,注意需要将命令中的Zookeeper连接ip切换为自己的本机ip,另外在实际生产中为了安全性,还需要给kafka加上用户和密码,此处仅演示使用,不再赘述。
kafka原理解析
kafka 生产与消费的核心架构模型

核心概念
- producer:生产者就是产生消息的组件
- broker:一个broker可以认为就是一个服务节点,服务实例。
- consumer:消费者 消费信息的组件
- zookeeper:用于管理和协调Kafka的Broker
逻辑组件
-
topic:生产者创建消息是要发送给特定的主题的,而消费者拉取消息也是要指定主题的。消息就是通过主题来归类的,类似于RabbitMQ中的Exchange的概念
-
partition:是Kafka下数据存储的基本单元,这是个物理上的概念,同一个topic的数据,会被分散的存储到多个partition中,这些partition可以在同一台机器上,也可以是在多台机器上,kafka中的消息是以键值对的形式存储的,如果没有指定分区,消息是默认按照轮询的方式存储到各个分区上的。

-
offset:偏移量, Kafka 的消息是可以持久化并反复消费的,这是因为在每个分区中,当有消息写入就会像追加日志那样顺序写入(顺序IO的写入性能是十分好的),通过 offset 来记录对应消息所在的位置。因此,offset 是消息在 partition 中的唯一标识,并且能看出同一个 partition 内的消息的先后顺序,我们称之为 “Kafka 保证消息在分区内是有序的”。
场景应用
1. 实时数据流管道
日志收集与聚合:Kafka可以用于收集和聚合来自不同系统的日志数据,然后将这些数据传输到集中存储系统(如Hadoop、Elasticsearch)进行分析。
指标监控与报警:通过Kafka传输系统运行指标数据,并实时分析,帮助及时发现并处理系统异常。
2. 数据集成
数据库变更数据捕获(CDC):使用Kafka连接器捕获数据库中的变更(如插入、更新、删除),然后将变更数据流式传输到其他存储系统或服务。
跨数据中心复制:在地理上分散的数据中心之间传输数据,实现数据的实时同步。
3. 流处理与分析
实时分析与机器学习:结合流处理框架(如Apache Flink、Apache Spark Streaming),Kafka可以用于实时数据分析和机器学习模型的在线更新。
用户行为跟踪:收集用户在网站或应用上的行为数据,进行实时分析以优化用户体验或做出业务决策。
4. 消息队列
解耦服务与微服务通信:在微服务架构中使用Kafka作为消息队列,实现服务间松耦合和可靠通信。
事件溯源模式:记录应用程序的所有状态变化作为事件流,以实现事件溯源和回放。
5. 物联网(IoT)
传感器数据收集:通过Kafka收集大量传感器设备的数据,实现实时监控和管理。
边缘计算支持:在边缘设备上进行初步数据处理后,将结果发送到中心服务器进行进一步分析。
6. 金融服务
交易流水处理:金融机构可以使用Kafka处理大量交易流水,确保数据的实时性和一致性。
欺诈检测:实时分析交易行为,快速识别异常以防止欺诈活动。
7. 内容分发
新闻推送与个性化推荐:根据用户兴趣实时推送个性化内容,提高用户参与度。
视频直播流处理:用于视频直播的数据传输和实时处理,确保低延迟和高质量。
Kafka通过其高吞吐量、可扩展性、容错性以及灵活的订阅机制,使得它在这些场景中能够有效地支持复杂的实时数据流处理需求。
整合kafka
引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.9.13</version>
</dependency>
引入配置
# Kafka集群的地址,用于指定Kafka服务器的位置。
spring.kafka.bootstrap-servers=192.168.253.166:9092
# 消费者组ID,用于标识消费者所属的组,Kafka通过消费者组来管理消息的消费。
spring.kafka.consumer.group-id=my-group
# 自动偏移量重置策略,当没有初始偏移量或当前偏移量在服务器上不存在时,使用此配置。
# 'earliest'从最早的可用消息开始消费。latest:从最新的消息开始读取。none:没有找到以前的偏移量,抛出异常。
spring.kafka.consumer.auto-offset-reset=earliest
# 生产者键序列化器,定义消息键的序列化方式,这里使用字符串序列化。
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
# 生产者值序列化器,定义消息值的序列化方式,这里使用字符串序列化。
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者键反序列化器,定义如何将字节数组反序列化为消息键,这里使用字符串反序列化。
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费者值反序列化器,定义如何将字节数组反序列化为消息值,这里使用字符串反序列化。
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 是否启用幂等性,确保每条消息在Kafka中只会被写入一次,从而避免重复写入。
spring.kafka.producer.enable-idempotence=true
# 事务ID前缀,用于标识生产者事务。每个生产者实例必须有唯一的事务ID前缀,以支持事务性生产者功能。
# 这个设置是可选的,仅在需要事务性保证时使用。
#spring.kafka.producer.transaction-id-prefix=tx-
生产者
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Service
public class KafkaProducer {
private static final String TOPIC = "my_topic";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
kafkaTemplate.send(TOPIC, message);
System.out.println("Sent message: " + message);
}
// 带回调的发送消息方法
public void sendMessageCallback(String message) {
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(TOPIC, "A", message);
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
// 发送成功时的处理逻辑
System.out.println("成功回调=[" + message +
"] with offset=[" + result.getRecordMetadata().offset() + "]");
}
@Override
public void onFailure(Throwable ex) {
// 发送失败时的处理逻辑
System.err.println("失败回调=["
+ message + "] due to : " + ex.getMessage());
// 可选择在此处实现重试机制或记录日志
}
});
}
}
消费者
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumer {
@KafkaListener(topics = "my_topic", groupId = "my-group")
public void listen(String message) {
System.out.printf("普通A message: %s%n", message);
}
}
写个方法调用
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@GetMapping("/send")
public String send() {
kafkaProducer.sendMessageCallback("Hello, Kafka!");
return "Message sent!";
}
@GetMapping("/send2")
public String send2() {
kafkaProducer.sendMessage("Hello, Kafka启动");
return "Message sent!";
}
}
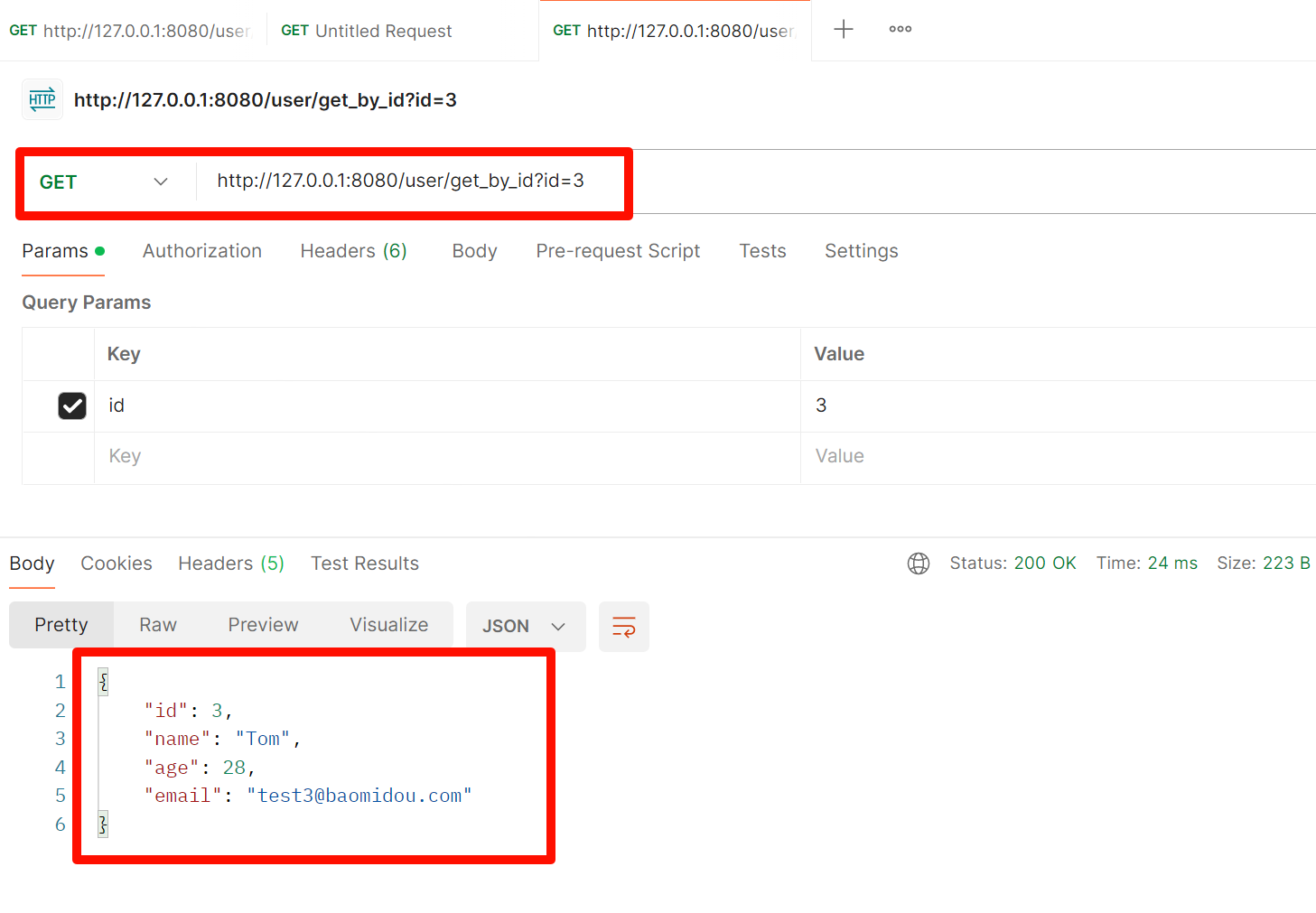
生产者测试结果

消费者测试结果

配置说明
1. 生产者配置(Producer Configuration)
- bootstrap.servers:Kafka 集群地址列表,格式为 hostname:port。
- key.serializer:消息键的序列化器类,用于将消息键转换为字节数组。
- value.serializer:消息值的序列化器类,用于将消息值转换为字节数组。
- acks:生产者确认消息的策略(0 = 不确认,1 = 主节点确认,all = 所有副本确认)。
- compression.type:压缩类型(none, gzip, snappy, lz4, zstd)。
- enable.idempotence:是否启用幂等性,防止重复发送相同消息。
- transactional.id:事务 ID 前缀,用于支持事务功能。
- batch.size:每个批次的最大字节数。
- linger.ms:发送延迟,允许生产者在发送前等待更多消息以填满批次。
- max.in.flight.requests.per.connection:在同一时间内可以发送到服务器的最大未确认请求数。
2. 消费者配置(Consumer Configuration)
- bootstrap.servers:Kafka 集群地址列表,格式为 hostname:port。
- group.id:消费者所属的消费组 ID,用于管理消费者的负载均衡和偏移量。
- key.deserializer:消息键的反序列化器类,用于将字节数组转换为消息键。
- value.deserializer:消息值的反序列化器类,用于将字节数组转换为消息值。
- auto.offset.reset:自动偏移量重置策略(earliest = 最早可用,latest = 最新,none = 抛出异常)。
- enable.auto.commit:是否启用自动提交偏移量;默认为 true。
- auto.commit.interval.ms:自动提交偏移量的时间间隔,仅在启用自动提交时有效。
- max.poll.records:每次调用 poll() 时返回的最大记录数。
- session.timeout.ms:消费者会话超时时间,超出此时间后会被认为失效。
- heartbeat.interval.ms:心跳间隔时间,用于与 Kafka 保持连接活跃状态。
3. 代理配置(Broker Configuration)
- broker.id:唯一标识每个代理的 ID,通常是整数值。
- listeners:定义代理监听客户端请求的地址和端口,例如:PLAINTEXT://localhost:9092。
- log.dirs:日志文件存储目录,可以设置多个目录以实现数据分散存储。
- num.partitions:新主题默认分区数,如果未指定,则使用此值创建新主题时默认分区数。
- replication.factor:默认副本因子,当主题创建时,如果未指定副本因子,则使用此值。
- min.insync.replicas:确保最小同步副本数量,以防止数据丢失。
- zookeeper.connect:Zookeeper 的连接字符串,用于管理集群元数据和协调操作。
- delete.topic.enable:是否允许删除主题;默认为 false。
- log.retention.hours:日志保留时间(小时),超过此时间的数据将被删除。
4. 全局和其他设置
- 连接设置
Connection timeout: 连接超时时间设置。
Retry count: 重试次数设置。 - 安全性设置
SSL configuration: SSL 配置,用于安全传输数据。
SASL configuration: SASL 配置,用于身份验证。
springboot整合kafka教程暂且到此结束。