文章目录
- Prometheus 优势
- Prometheus 的组件、架构
- Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化
- 概念
- 数据模型
- 时间序列
- 指标名称
- 标签
- 样本
- 时间序列的表示方式
- 指标类型
- Counter(计数器)
- Gauge(仪表盘)
- Histogram(直方图)
- Summary(摘要)
- Jobs 和 Instance
- Prometheus 的部署(二进制)
- 创建 prometheus 根目录
- 官网下载 prometheus
- 上传 prometheus 到服务器并解压
- 为文件夹递归赋予可执行权限
- 创建软链接(或者直接改名文件夹)
- 前台启动 prometheus
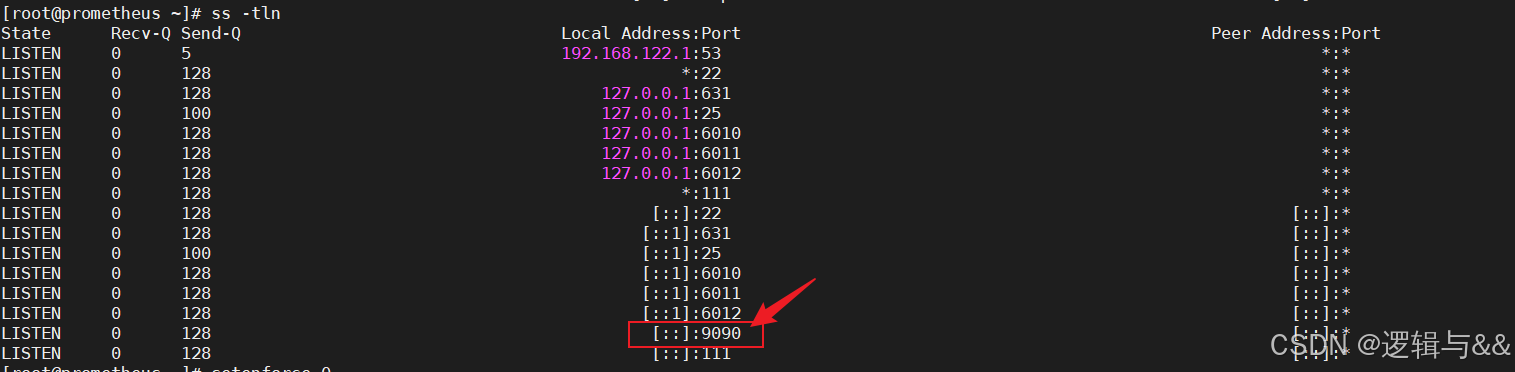
- 另启一个终端,判断端口状态
- 关闭前台进程,准备更方便的后台进程
- 使用 promtool 检查语法正确性
- 创建自启动脚本(将 prometheus 自定义为服务)
- 重载系统配置及启动 prometheus
- 访问不了,我们看看端口状态
- 再看看服务状态
- 查看安装的文档结构
- 重新加载配置
- 查看 Prometheus 后台
- Exporter 组件
- 作用
- Exporter 类型
- 直接采集型
- 间接采集型
- 文本数据格式
- 配置 Linux 主机监控(Node Exporter)
- 安装 Exporter
- Prometheus server 关联 node_exporter(静态配置功能)
- 主配置文件介绍
- 添加 node_exporter 任务(注意对齐)
- 检查代码语法
- 查看当前 targets
- 重启 Prometheus server,看看对 node1 的监控
- metrics 数据采集
- 查看 node1 文件系统的总大小
- 查看 cpu 指标(图形呈现)
- 配置 Mysql 主机监控
- 部署 mariadb
- 添加用户 exporter
- node1 上安装配置 Exporter
- 官网下载 mysqld_exporter 二进制包解压缩
- 为 mysqld_exporter 赋予执行权限,并创建软链接
- 配置 mysqld_exporter 配置文件,存放用户名和密码
- 后台运行 mysqld_exporter
- 查看暴露的端口
- 关联 Prometheus server
- 添加 mysqld_exporter 任务
- 检查语法,重启 prometheus 监控
- 查看 Prometheus 后台
- 数据采集
- 查询 MySQL 最大连接数
- 查询吞吐量
- 查询当前连接数
- 服务发现
- 基于文件的服务发现
- 注释 proemtheus.yml 中的 exporters 配置
- 重启 prometheus 服务
- 准备 target 配置文件
- 修改 Prometheus 配置文件
- 重启服务
- 其他方法进行服务发现
- PromQL
- 时序数据库 TSDB
- 特点
- 时序数据库的基本要求
- 常见的时序数据库
- PromQL 操作符
- 数学运算
- 布尔运算
- 集合运算符
- 操作符优先级
- PromQL 聚合操作
- 例子
- sum()
- count_values()
- topk()
- quantile()
- 内置函数
- 计算 Counter (计数器)指标增长率
- increase() 函数
- rate() 函数
- irate() 函数
- 预测Gauge(仪表盘)指标变化趋势
- predict_linear函数()
- 统计Histogram(直方图)指标的分位数
- Grafana数据展示
- 部署Grafana
- 下载软件包并安装
- 安装grafana
- 启动服务,加入开机自启
- 看3000端口是否监听
- 访问Grafana
- 添加数据源
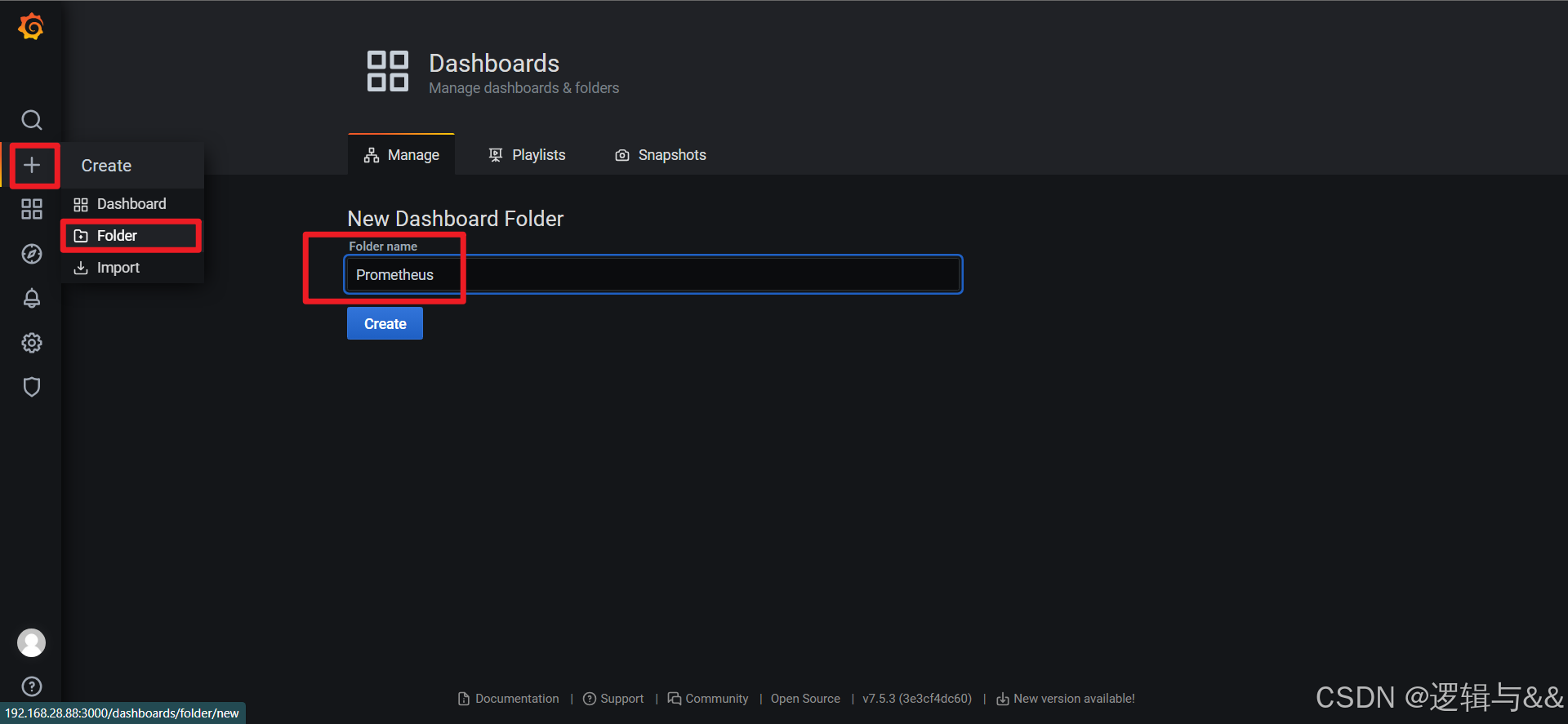
- 新建一个叫Prometheus的文件夹
- 创建仪表盘
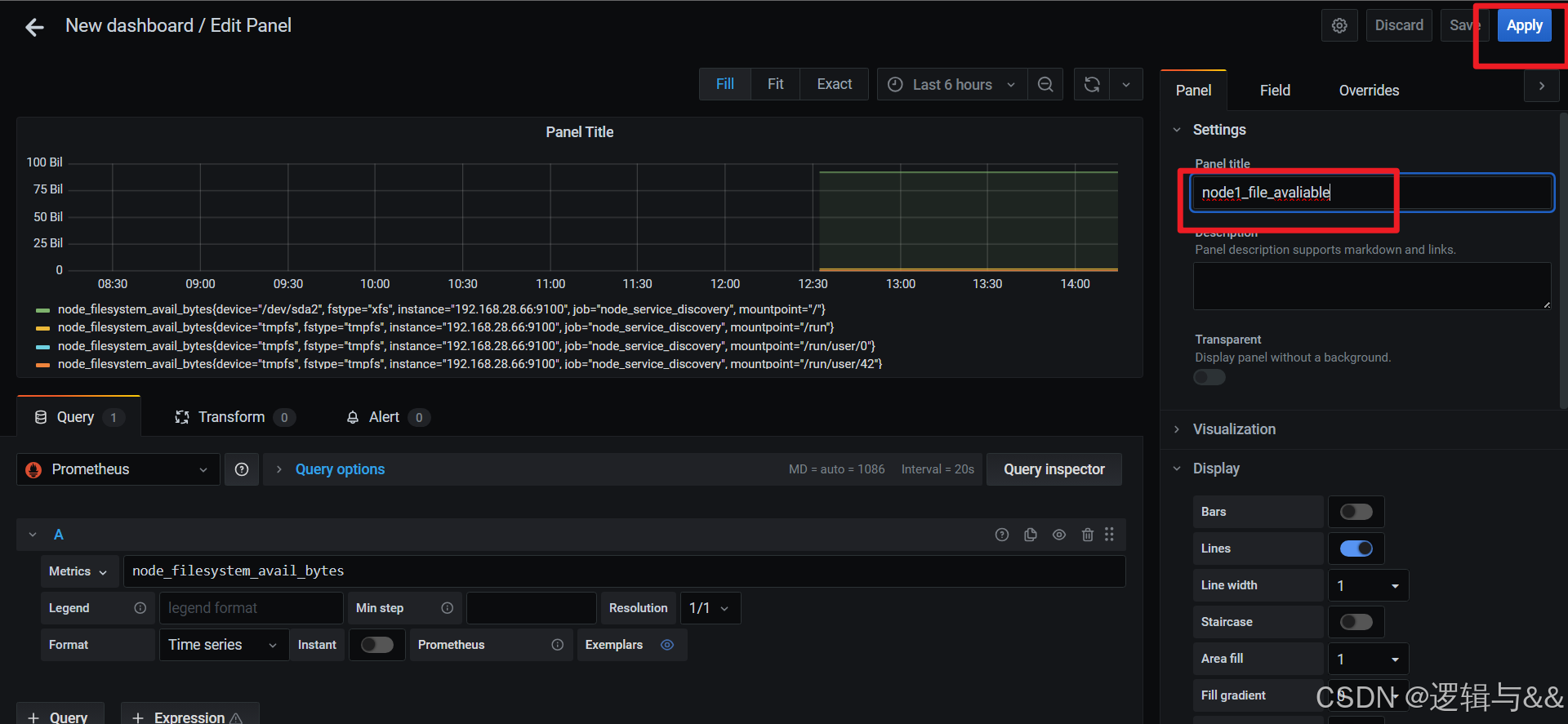
- 添加node1磁盘可用空间的监测
- 添加更多监控项
- 仪表盘
- 保存仪表盘
- 使用第三方模板
- 根据需求选择合适的模板
- 回到仪表盘进行导入
- 展现当前Linux主机的全部状态
- Altermanager告警
- 概述
- 告警逻辑
- Altermanger机制
- 分组机制
- 抑制机制
- 静默机制
- Altermanager的部署
- 下载解压安装包
- 编辑Alertmanger配置文件
- 查看配置文件
- Alertmanager使用邮箱报警
- QQ邮箱准备
- 修改配置文件
- 后台启动Alertmanager
- 关联Prometheus
- 添加告警规则
- 在Prometheus配置文件中导入
- 用promtool检查语法
- 重启prometheus
- 在web中查看Rules
- 关闭node1测试
- 等一分钟看邮箱是否有告警
Prometheus 优势
- 强大的查询语言 PromQL
- 不依赖分布式存储
- 不依赖分布式存储;单个服务节点拥有自治能力
- 通过静态配置文件或服务发现来获取监控目标(zabbix 要进行手动配置)
- 支持多种类型的图表和仪表盘
Prometheus 的组件、架构
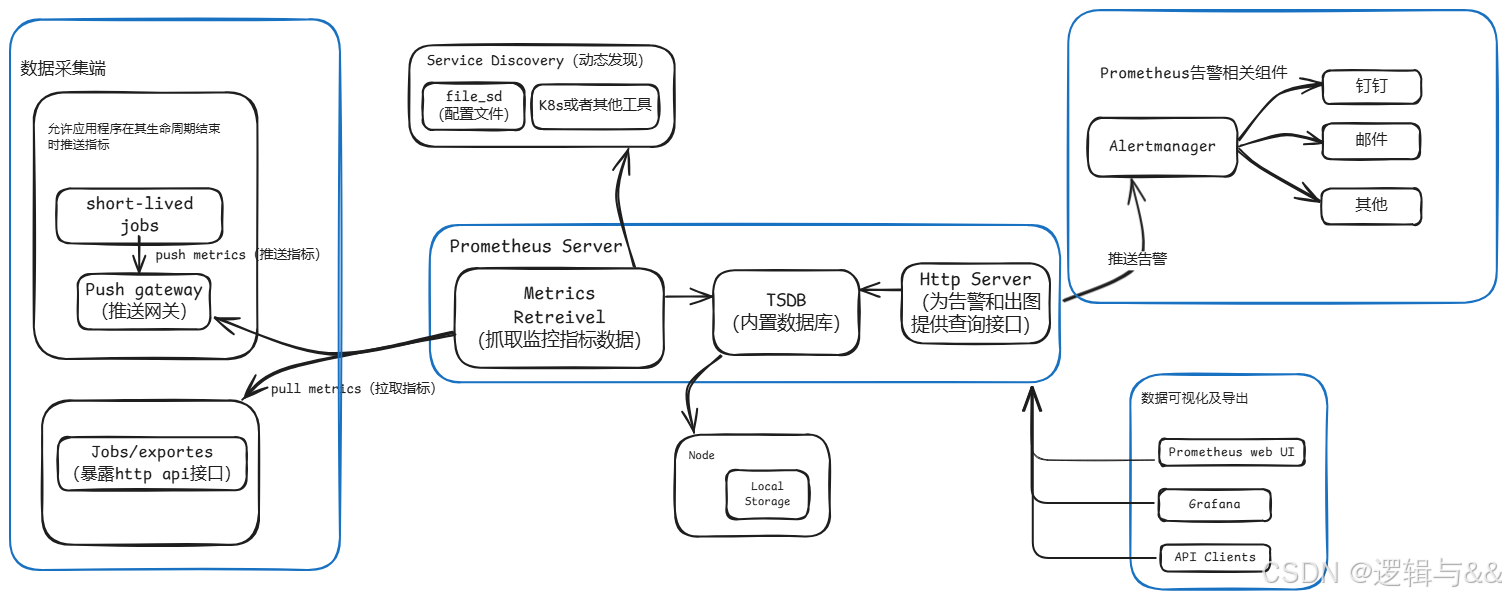
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化
| 组件 | 功能 |
|---|---|
| Prometheus server | 收集每个目标数据,并存储为时间序列数据,对外可提供数据查询支持和告警规则配置管理 |
| Exporter | 用于输出被监控组件信息的 HTTP 接口 |
| Pushgateway | 用于支持短期临时或批量计划任务工作的汇聚节点 |
| Alertmanager | 用于处理 Prometheus 服务器端发送的 alerts 信息,对其去除重数据、分组并路由到正确的接收方式,发出告警;支持丰富的告警方式 |
| Service Discovery | 动态发现待监控的 target,从而完成监控配置的重要组件 |
概念
数据模型
时间序列
- Prometheus 数据的基本单位
- Prometheus 采集的所有的监控数据均以 指标(metrics) 的形式保存在内置的时间序列数据库 TSDB 中
- 时间序列中的每一个点称为样本,每个样本由 度量名称(Metric Name)、标签(labels)、样本值(sample value)组成
- 指标名称及标签(键值对)是 时间序列的 唯一标识
指标名称
- 反映被监控样本的含义
- 如
httprequest_total可以看出来表示当前系统接收到的 http 请求总量 - 指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式
[a-zA-Z*:][a-zA-Z0-9_:]
标签
- 使用标签,Prometheus 开启了强大的多维数据模型
- 对于相同的指标名称,通过不同标签列表的集合,会形成特定的度量维度实例
- 例如,所有包含度量名称为
/api/tracks的 http 请求,打上method=POST的标签,就会形成具体的 http 请求 - 查询语言在这些指标和标签列表的基础上进行过滤和聚合,改变任何度量指标上的任何标签值(包括添加或删除指标),都会创建新的时间序列
- 标签的名称只能由 ASCII 字符、数字、以及下划线组成并满足正则表达式
[a-zA-Z_][a-zA-Z0-9_]* - 标签的值则可以包含任何
Unicode编码的字符
样本
在时间序列中的每一个点称为样本,样本由以下三部分组成
- 指标(metric):指标名称和描述当前样本特征的 labelset
- 时间戳:一个精确到时间毫秒的时间戳
- 样本值:一个浮点型数据表示当前样本的值
时间序列的表示方式
<metric name>{<label name>=<label value>, ...}
例:指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为如下
api_http_requests_total{method="POST", handler="/messages"}
指标类型
四种核心指标类型(数据)
Counter(计数器)
-
计数器类型的度量 只能增加 或重置为零
-
常用于记录事件的累计次数,如请求数、错误数等。
-
例:利用 PromQL 内置操作函数对 http 请求量进行分析
# 通过rate()函数获取5min内http请求的增长率 rate(http_requests_total[5m]) # 通过topk()函数得出访问量前十的HTTP地址 topk(10,http_requests_total)
Gauge(仪表盘)
-
仪表盘类型的度量 可以任意增减
-
常用于表示瞬时值,如温度、内存使用量、当前并发请求数等
-
示例:利用 PromQL 内置操作函数获取样本在一段时间内的变化
# 利用delta()函数计算node1主机cpu温度在两小时内的变化 delta(cpu_temp_celsius{host="node1"}[2h]) # 利用predict_linear()函数基于两小时的样本数据,预测node2四个小时之后的磁盘空间剩余是否小于0 predict_linear(node_filesystem_free{job="node2"}[2h],4*3600)<0
Histogram(直方图)
-
直方图类型的度量用于记录 量化指标的分布情况(如 cpu 平均使用率、页面平均响应时间)
-
为了解决取全部平均值长尾问题:如大多数 api 请求响应时间在 100ms 以内、个别请求响应时间需要五秒,导致平均响应时间拉长
-
Histogram 在一段时间范围内(通常是请求持续时间或响应大小)对数据进行采样,并将其计入可配置的存储桶(bucket)中,之后可以通过指定区间筛选样本,也可以统计样本总数,最后的结果为直方图展示
-
例
-
统计样本的值分布在 bucket 中的数量:
<basename>_bucket{le="<上边界>"}(即最大值小于等于上边界的数量)# 在总共2次请求当中。http 请求响应时间 <=0.005 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.005",} 0.0 # 在总共2次请求当中。http 请求响应时间 <=0.01 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.01",} 0.0 # 在总共2次请求当中。http 请求响应时间 <=0.025 秒 的请求次数为0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.025",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.05",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.075",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.1",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.25",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.5",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="0.75",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="1.0",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="2.5",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="5.0",} 0.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="7.5",} 2.0 # 在总共2次请求当中。http 请求响应时间 <=10 秒 的请求次数为 2 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="10.0",} 2.0 io_namespace_http_requests_latency_seconds_histogram_bucket{path="/",method="GET",code="200",le="+Inf",} 2.0 -
所有样本值的大小总和,命名为
<basename>_sum# 发生的2次 http 请求总的响应时间为 13.107670803000001 秒 io_namespace_http_requests_latency_seconds_histogram_sum{path="/",method="GET",code="200",} 13.107670803000001 -
样本总数,命名为
<basename>_count。值和<basename>_bucket{le="+Inf"}相同。# 当前一共发生了 2 次 http 请求 io_namespace_http_requests_latency_seconds_histogram_count{path="/",method="GET",code="200",} 2.0
-
Summary(摘要)
- summary 与 histogram 功能相似,提供在某个区间抽样检查
- 但需要提前指定好动态百分位数(Quantiles)
Jobs 和 Instance
在 Prometheus 中,任何被采集的目标(每一个暴露监控样本数据的 HTTP 服务)都称为 一个 实例 Instance,通常对应单个进程
具有相同采集目的的实例集合叫做 作业 Job
Prometheus 的部署(二进制)
创建 prometheus 根目录
mkdir /prometheus
官网下载 prometheus
https://prometheus.io/download/
上传 prometheus 到服务器并解压
tar -zxvf prometheus-2.47.0.linux-amd64.tar.gz -C /prometheus/
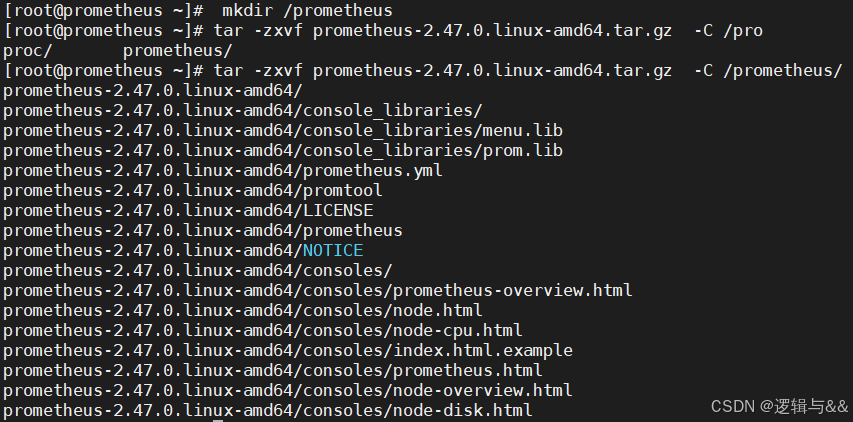
为文件夹递归赋予可执行权限
chown -R root:root prometheus-2.47.0.linux-amd64/
创建软链接(或者直接改名文件夹)
ln -sv prometheus-2.47.0.linux-amd64/ prometheus
# 或者 mv prometheus-2.47.0.linux-amd64/ prometheus

或

前台启动 prometheus
./prometheus
# [ctrl]+c 终止
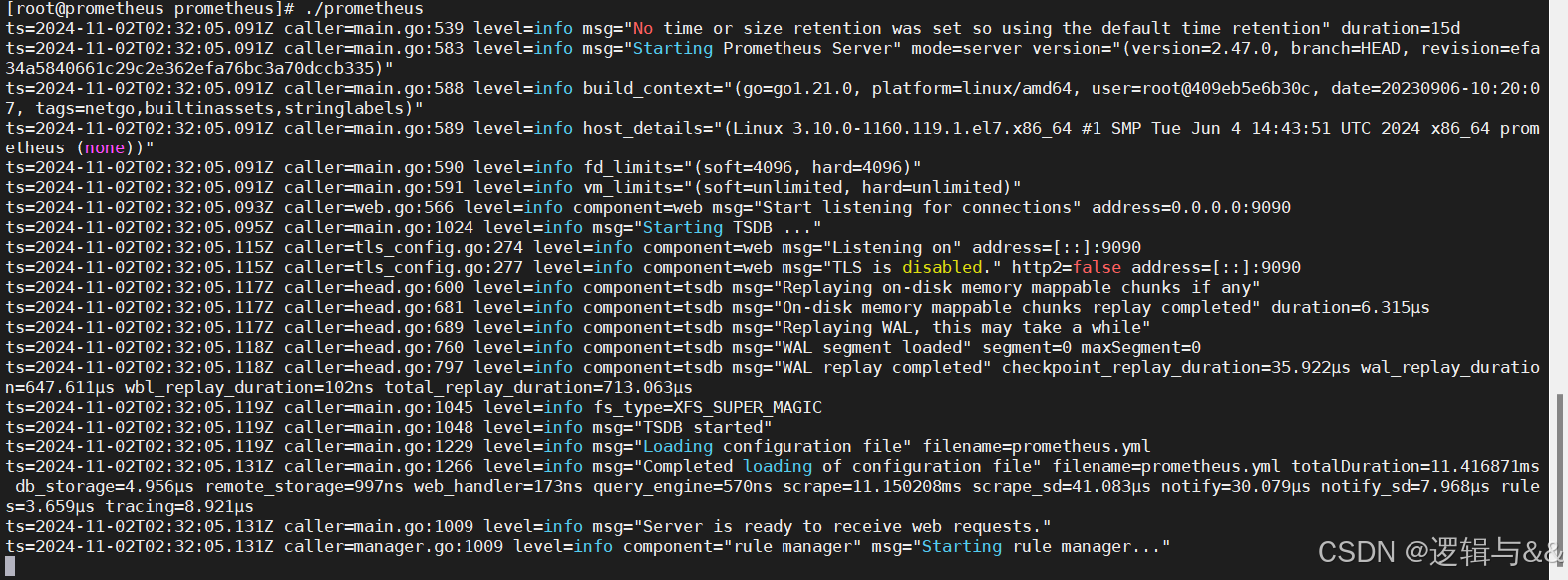
另启一个终端,判断端口状态
ss -ntl
这时理论上来说应该可以进行了,但是检查一番后发现没关防火墙,导致浏览器访问不到 Prometheus 后台
systemctl stop firewalld
setenforce 0
关闭前台进程,准备更方便的后台进程
使用 promtool 检查语法正确性
./promtool check config prometheus.yml

创建自启动脚本(将 prometheus 自定义为服务)
vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
Restart=on-failure
ExecStart=/data/prometheus/prometheus \
--config.file=/data/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus/data \
--web.listen-address=:9090 \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
重载系统配置及启动 prometheus
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
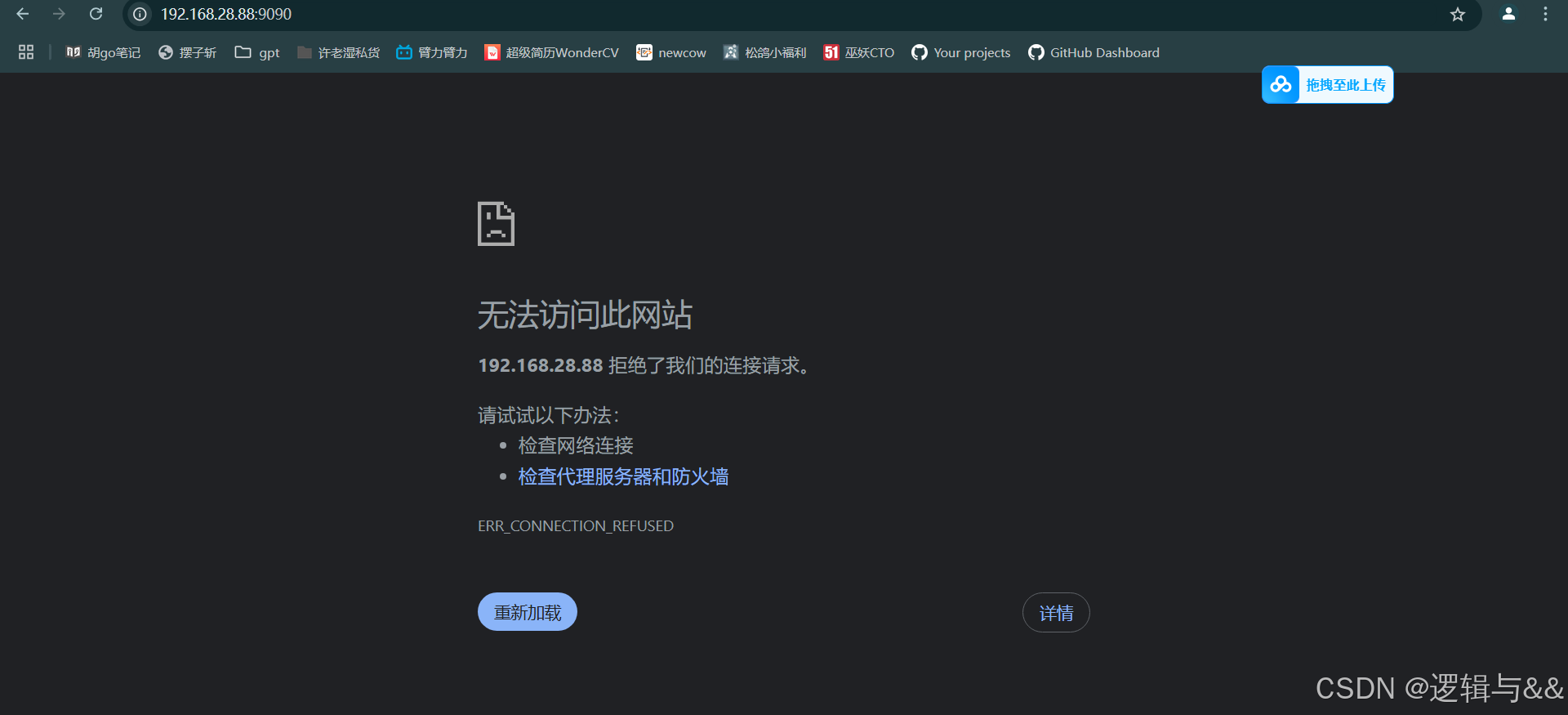
访问不了,我们看看端口状态
ss -ntl
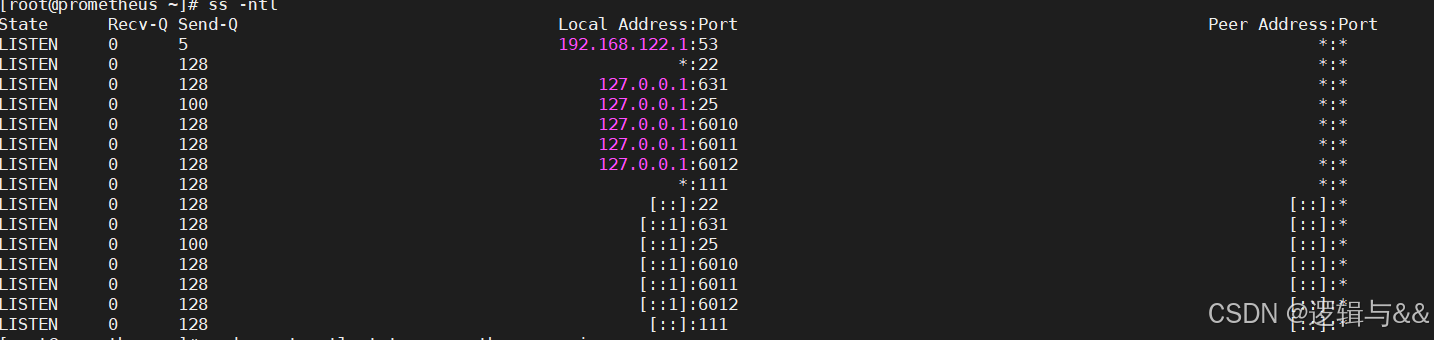
发现没有暴露 prometheus 对应的 9090 端口
再看看服务状态
systemctl status prometheus
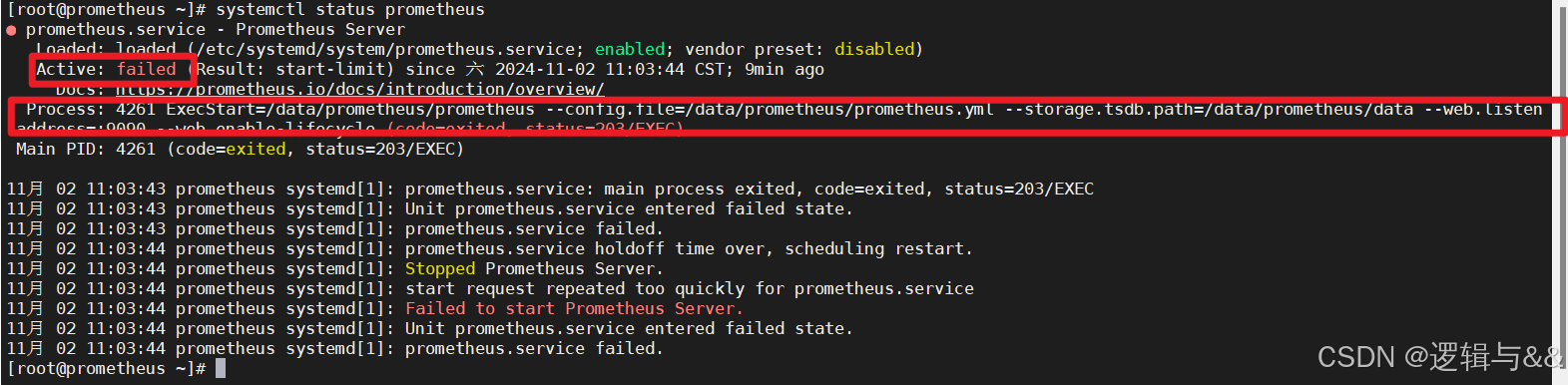
哦,发现一个很严重的问题
ExecStart=/data/prometheus/prometheus --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --web.listen-address=:9090 --web.enable-lifecycle (code=exited, status=203/EXEC)
服务配置文件里指定的文件路径错了
我们对应改成正确的
查看安装的文档结构
tree
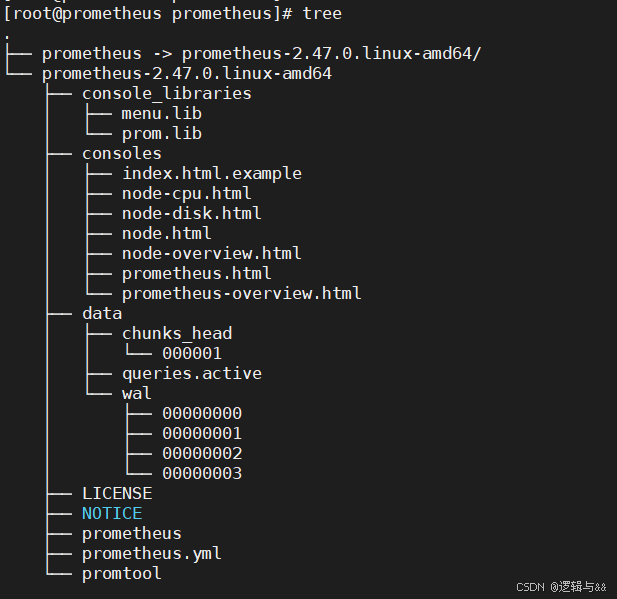
# vim /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
Restart=on-failure
ExecStart=/prometheus/prometheus/prometheus \
--config.file=/prometheus/prometheus/prometheus.yml \
--storage.tsdb.path=/prometheus/prometheus/data \
--web.listen-address=:9090 \
--web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target
重新加载配置
systemctl daemon-reload
systemctl enable prometheus.service
systemctl start prometheus.service
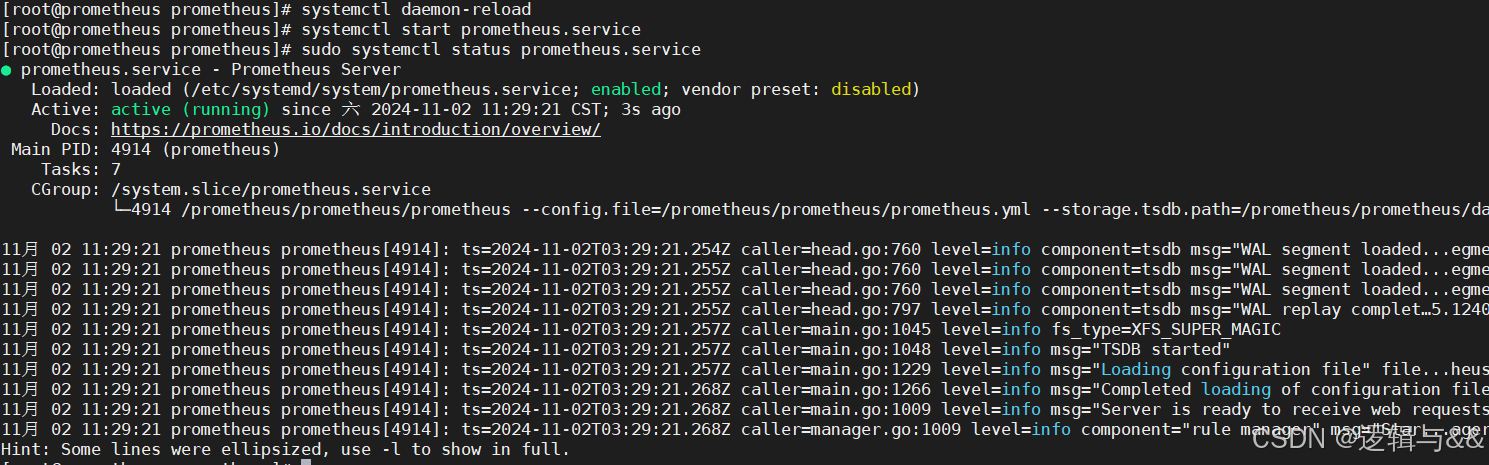
查看 Prometheus 后台
Exporter 组件
作用
连接被监控系统和服务与 Prometheus 服务器之间的桥梁
主要作用包括:数据收集、数据转换、暴露监控接口等
Exporter 类型
直接采集型
- Exporters 内置响应程序,可以直接向 Prometheus 提供 target 数据支持
- 可以更好的监控各自系统内部的运行状态
- 适合自定义监控指标的项目实施
- 如 k8s 直接提供了给 Prometheus 的接口
间接采集型
- 原始监控项并不支持 Prometheus,需要使用 Prometheus 客户端编写监控目标的监控采集数据
- 如 Linux 操作系统本身不能直接支持 Prometheus,需要使用单独的
Node Exporter
文本数据格式
特点:良好的跨平台性和可读性
全部文本数据可以通过 curl [服务器ip]/metrics 获取到,Prometheus 后台搜索项是对这些 metrics 的过滤呈现
curl 192.168.28.88:9090/metrics
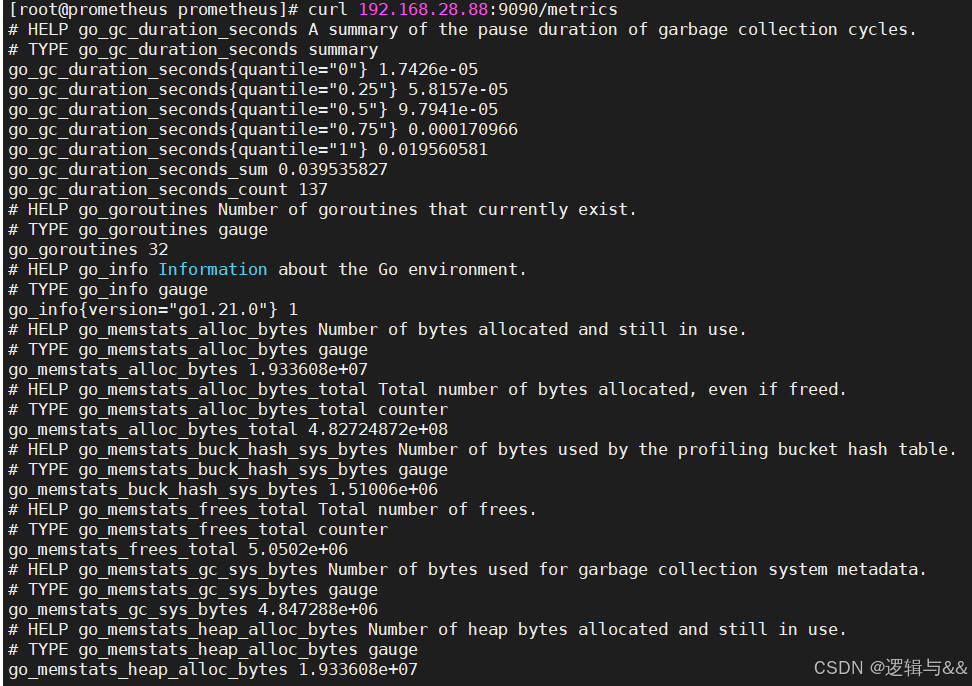
配置 Linux 主机监控(Node Exporter)
安装 Exporter
-
官网下载 node exporter 的二进制包并解压
mkdir /exporter tar -zxvf node_exporter-1.8.2.linux-amd64.tar.gz -C /exporter
-
为解压文件赋予执行权限
chown -R root:root /exporter/node_exporter-1.8.2.linux-amd64/ -
创建软链接
ln -sv /exporter/node_exporter-1.8.2.linux-amd64 /exporter/node_exporter
-
运行启动脚本后台启动 Node_exporter
cd /exporter/node_exporter ./node_exporter& # 加上`&`表示后台启动
-
jobs命令查看后台进程jobs # fg %1 恢复前台运行
-
查看暴露的端口号
ss -ntl
Prometheus server 关联 node_exporter(静态配置功能)
通过修改 Prometheus server 的主配置文件 prometheus.yml 中的 static_config 参数来采集 node_exporter 提供的数据
主配置文件介绍
cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
global:
scrape_interval:每次数据采集的时间间隔,默认为1分钟
scrape_timeout:采集请求超时时间,默认为10秒
evaluation_interval:执行rules的频率,默认为1分钟
scrape_configs:主要用于配置被采集数据节点操作,每一个采集配置主要由以下几个参数
job_name:全局唯一名称
scrape_interval:默认等于global内设置的参数,设置后可以覆盖global中的值
scrape_timeout:默认等于global内设置的参数
metrics_path:从targets获取meitric的HTTP资源路径,默认是/metrics
honor_labels:Prometheus如何处理标签之间的冲突。若设置为True,则通过保留变迁来解决冲突;若设置为false,则通过重命名;
scheme:用于请求的协议方式,默认是http
params:数据采集访问时HTTP URL设定的参数
relabel_configs:采集数据重置标签配置
metric_relabel_configs:重置标签配置
sample_limit:对每个被已知样本数量的每次采集进行限制,如果超过限制,该数据将被视为失败。默认值为0,表示无限制
添加 node_exporter 任务(注意对齐)
- job_name: "node_exporter"
static_configs:
- targets: ["192.168.28.66:9100"]
检查代码语法
./promtool check config prometheus.yml

查看当前 targets
重启 Prometheus server,看看对 node1 的监控
systemctl restart prometheus
可以看到监测的 node1
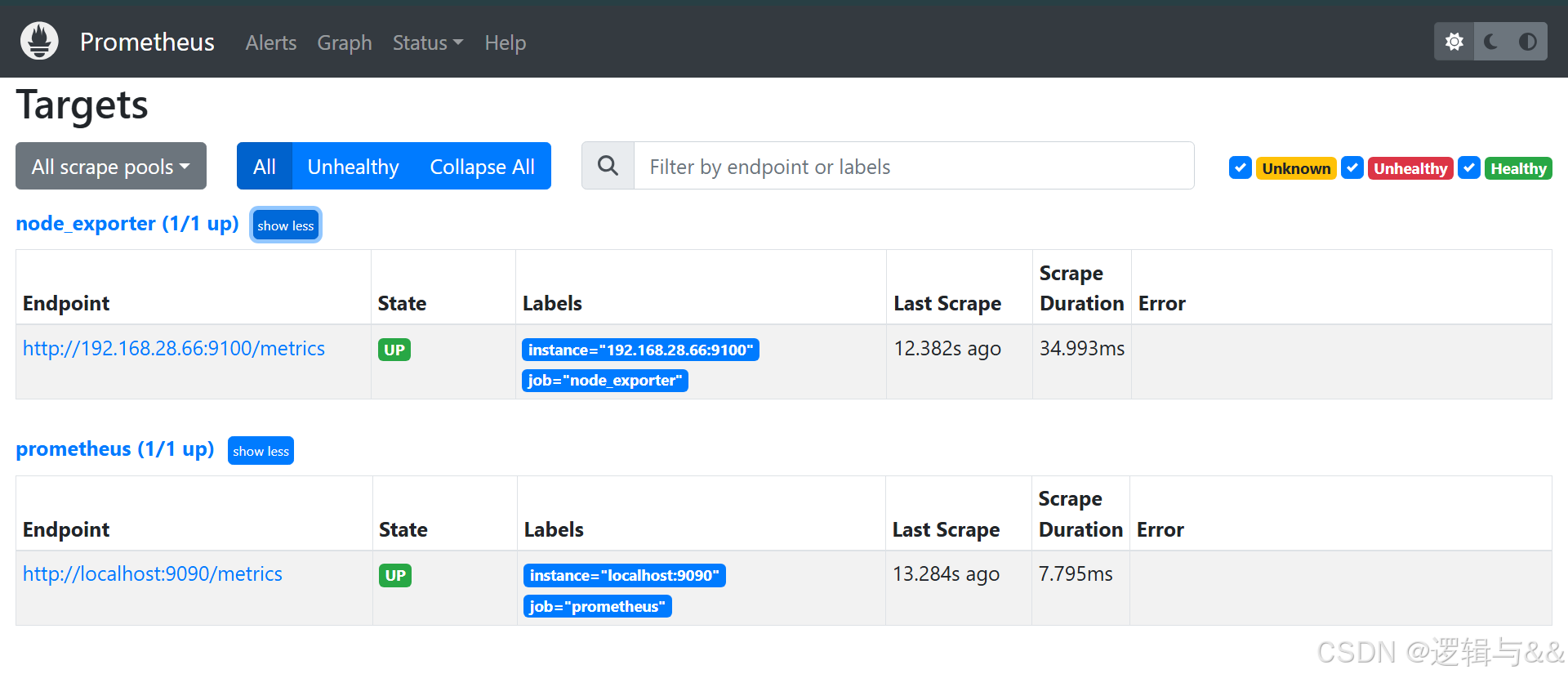
metrics 数据采集
查看 node1 文件系统的总大小
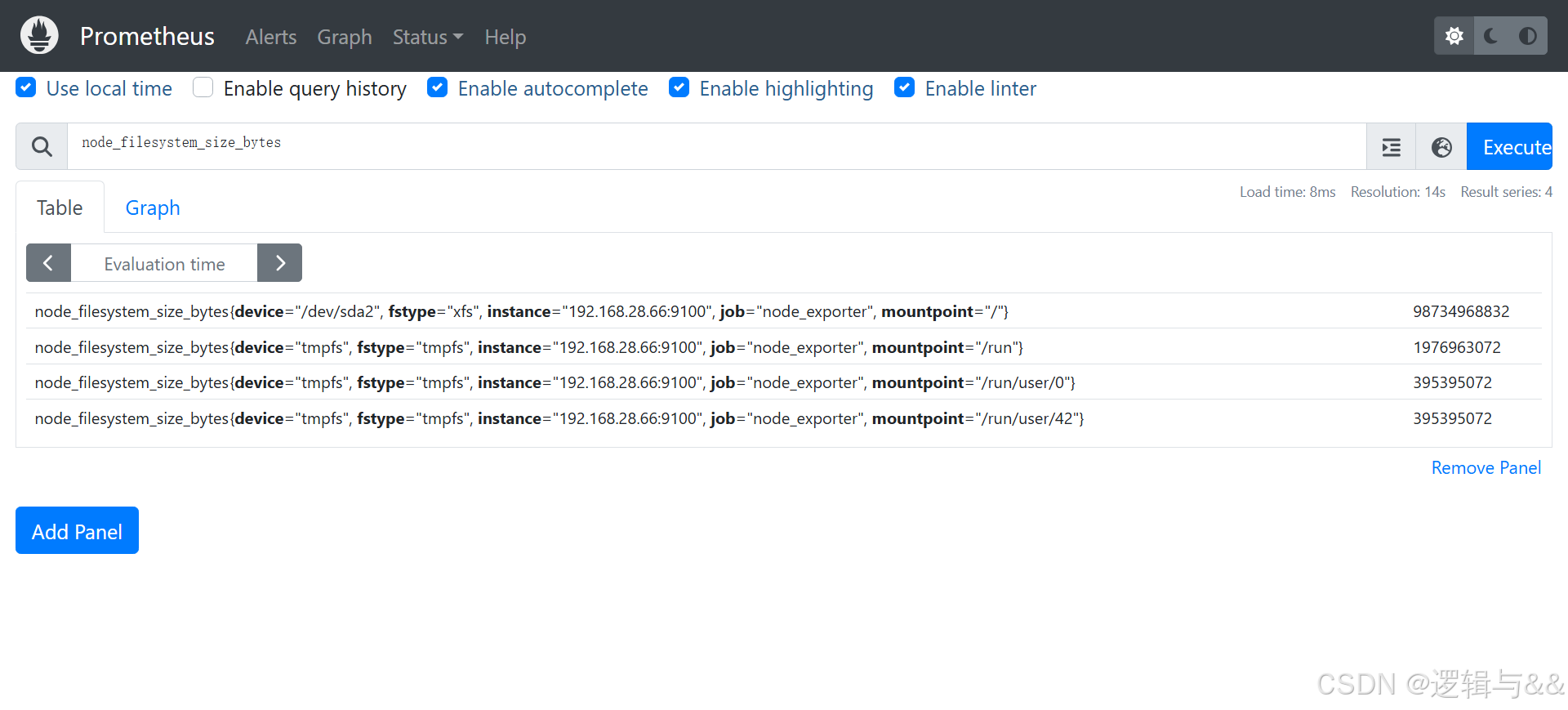
对查询结果进行数学运算(node1 总空间约为 100G)
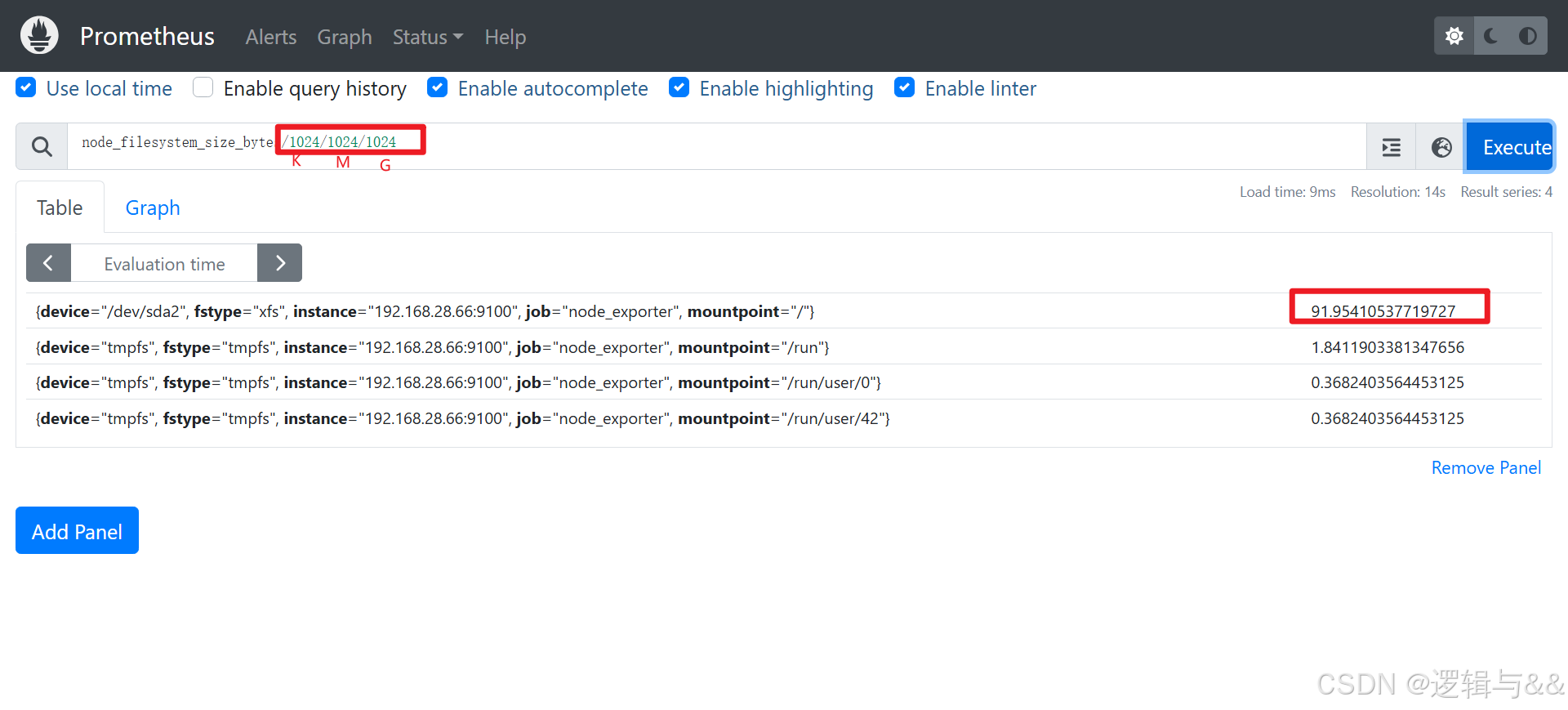
查看 cpu 指标(图形呈现)
node1 只分配了 2 核,且没有运行额外的进程,所以 cpu 曲线很平稳
配置 Mysql 主机监控
部署 mariadb
yum -y install mariadb-server # 安装mariadb服务端
systemctl enable --now mariadb
mysqladmin -uroot password '123456' # 初始化数据库并设置密码
mysql -uroot -p123456 -e "show databases;" # 测试数据库连接是否正常

添加用户 exporter
MariaDB [(none)]> grant all privileges on *.* to mysqld_exporter@'localhost' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> exit
node1 上安装配置 Exporter
官网下载 mysqld_exporter 二进制包解压缩
tar -zxvf mysqld_exporter-0.15.1.linux-amd64.tar.gz -C /exporter/
# exporter文件夹用的是是上个实验创建好的

为 mysqld_exporter 赋予执行权限,并创建软链接
chown -R root:root mysqld_exporter-0.15.1.linux-amd64/
ln -sv mysqld_exporter-0.15.1.linux-amd64 mysqld_exporter
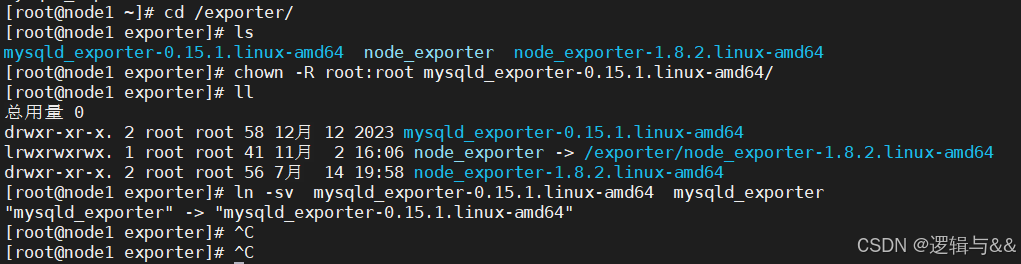
配置 mysqld_exporter 配置文件,存放用户名和密码
# cd mysqld_exporter
# vim mysqld_exporter.cnf
[client]
user=mysqld_exporter
password=123456
后台运行 mysqld_exporter
./mysqld_exporter --config.my-cnf='mysqld_exporter.cnf' &
查看暴露的端口
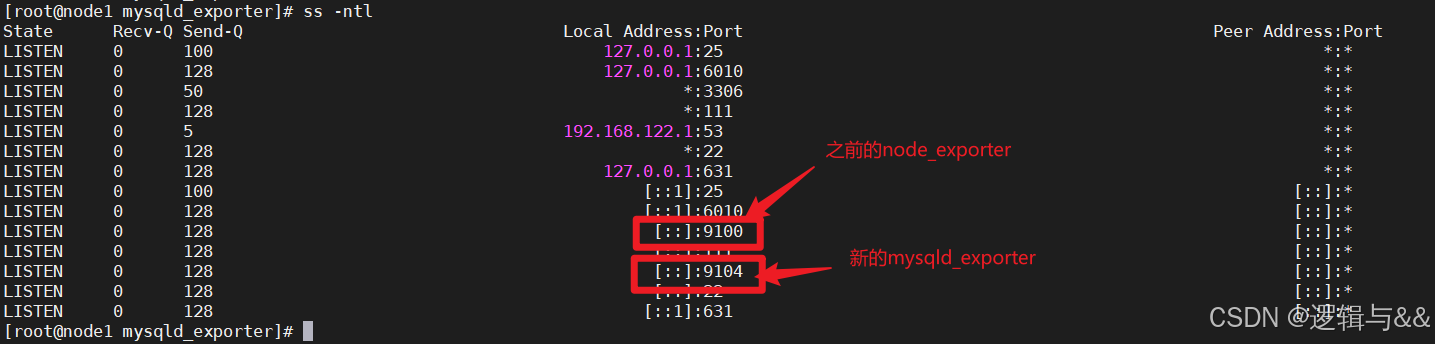
关联 Prometheus server
添加 mysqld_exporter 任务
# vim prometheus.yml
- job_name: 'mysqld_exporter'
# scrape_interval: 10s # 设置抓取间隔为 10 秒
static_configs:
- targets: ["192.168.28.66:9104"]
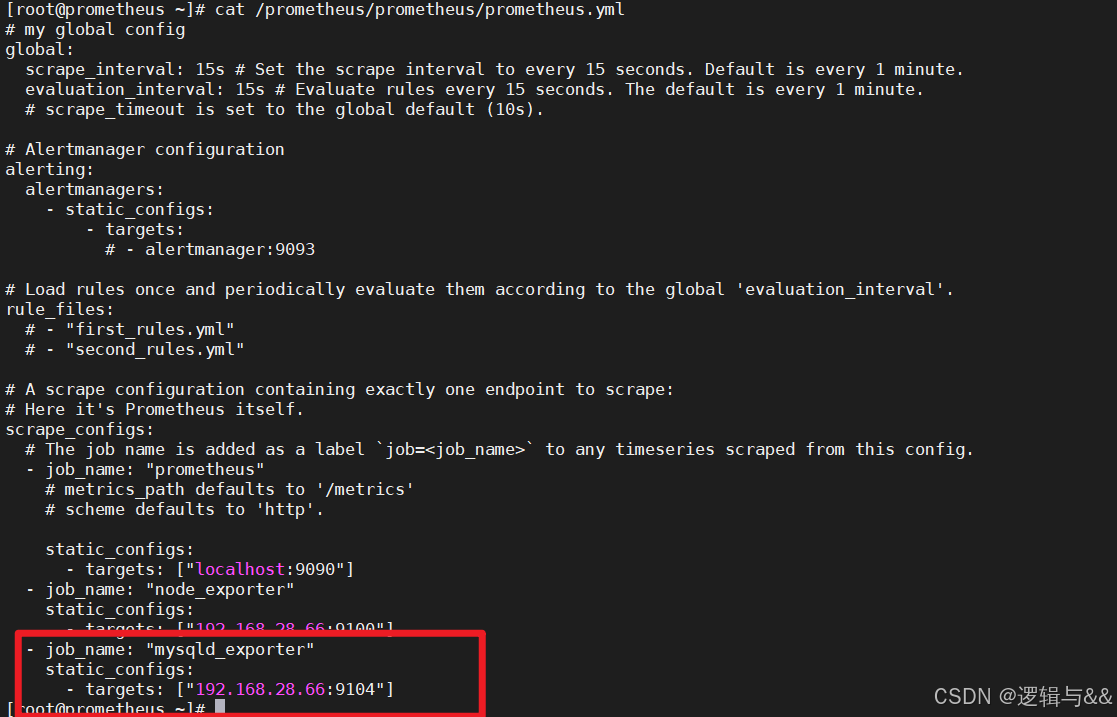
检查语法,重启 prometheus 监控
./promtool check config prometheus.yml
systemctl restart prometheus
查看 Prometheus 后台
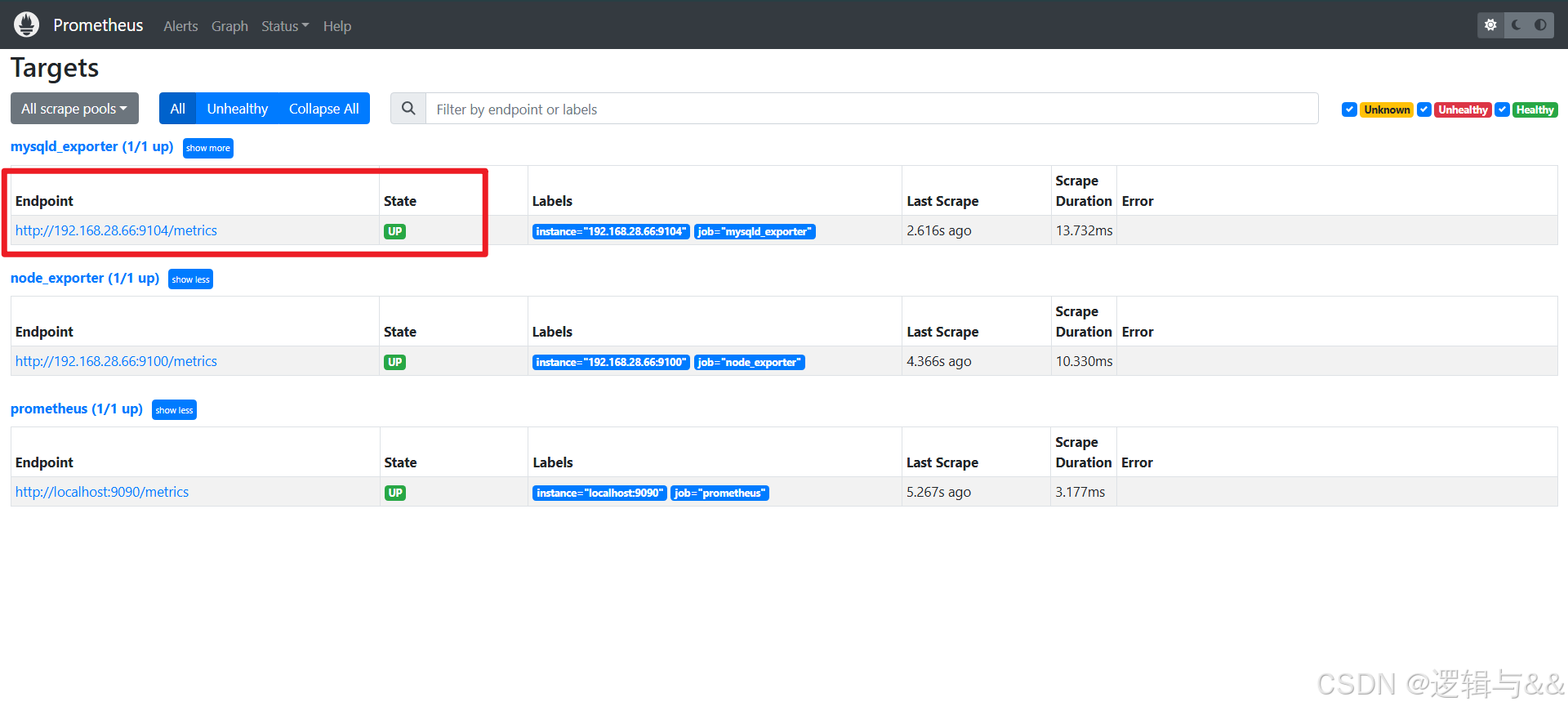
数据采集
查询 MySQL 最大连接数
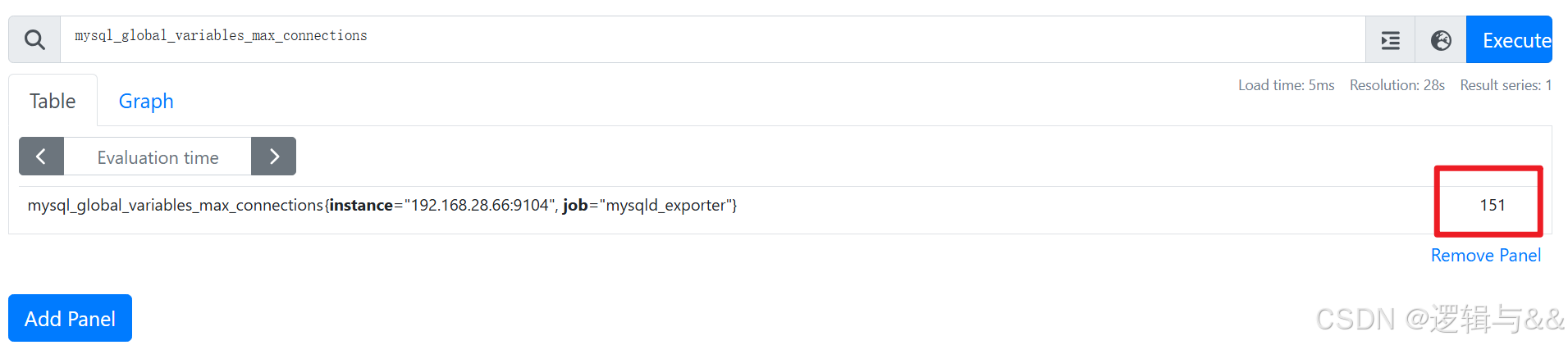
查询吞吐量

查询当前连接数
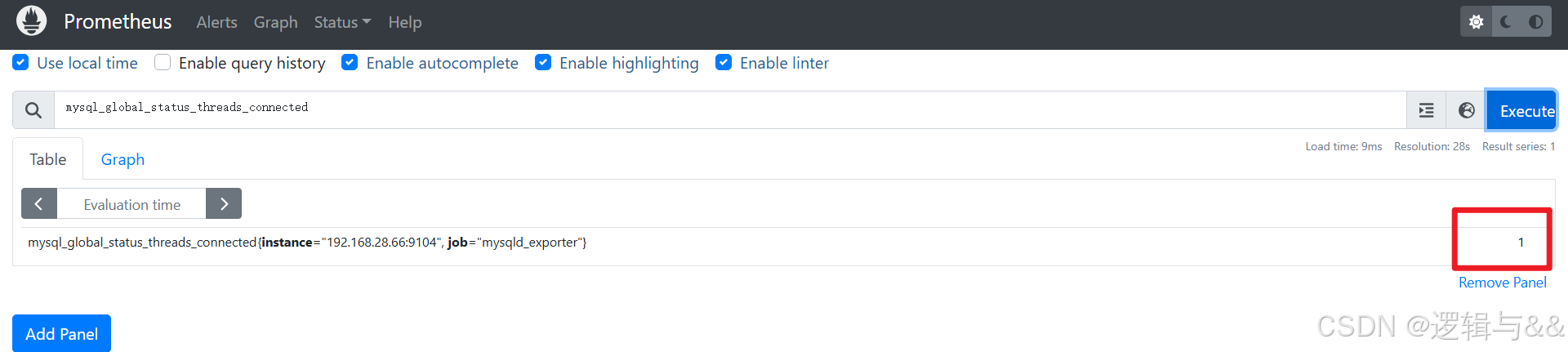
我们再到客户端连接一下
mysql —uroot -p123456

服务发现
Prometheus 服务发现可以自动发现并监控目标或变更目标,动态进行数据采集和处理
基于文件的服务发现
注释 proemtheus.yml 中的 exporters 配置
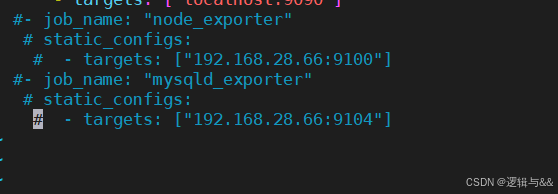
重启 prometheus 服务
systemctl restart prometheus

准备 target 配置文件
cd /prometheus
mkdir targets
# vim dev_node.yaml
- targets:
- "192.168.28.66:9100"
- "192.168.88.66:9104"
修改 Prometheus 配置文件
# vim prometheus.yml
# 加上以下内容
- job_name: "node_service_discovery"
file_sd_configs:
- files:
- targets/*.yml
- refresh_interval: 60s
重启服务
systemctl restart prometheus
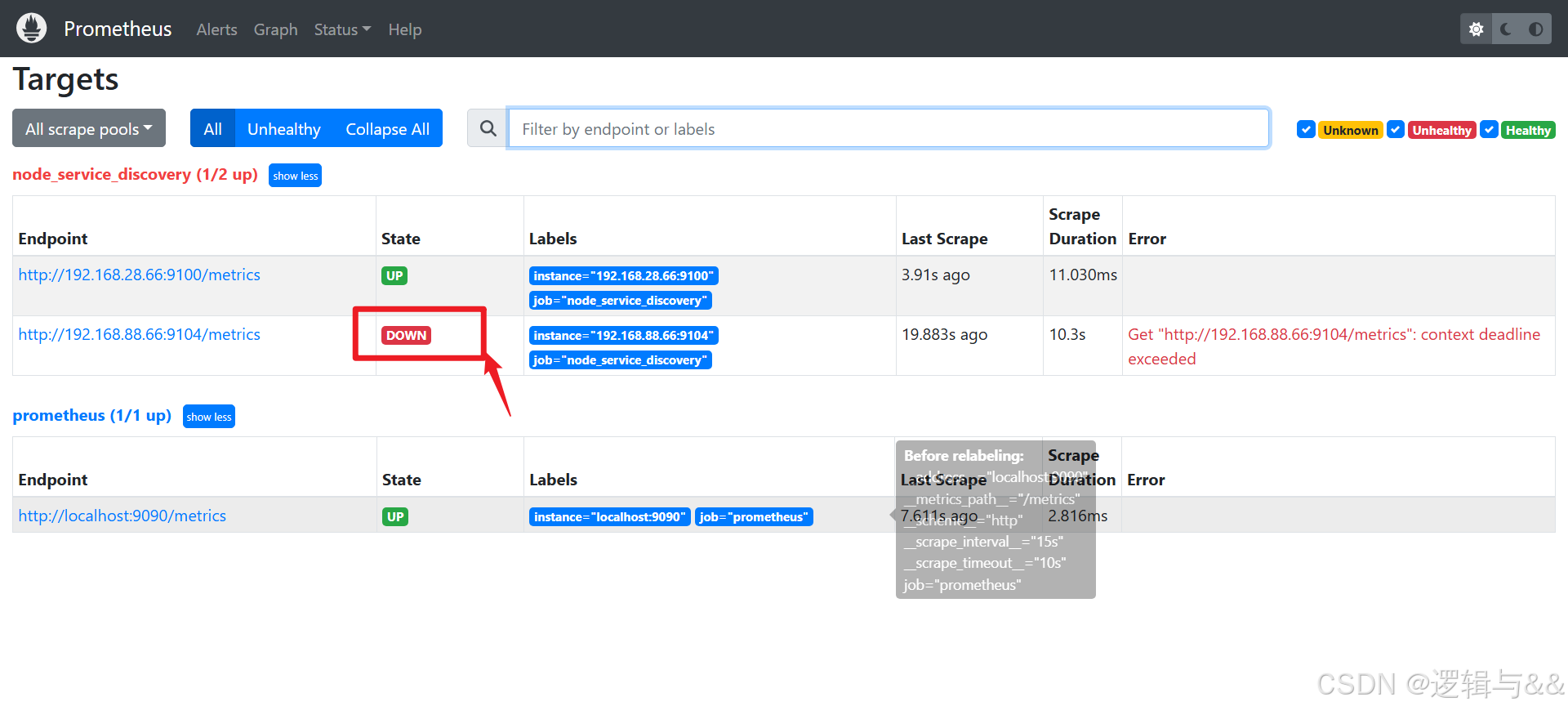
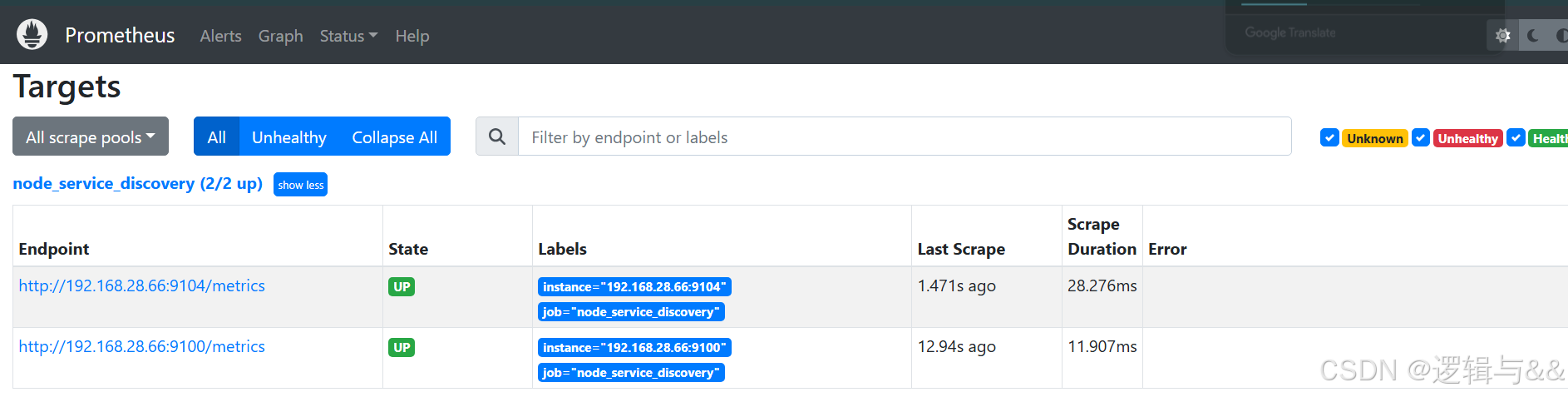
用于监控 Linux 的 metrics 正确 UP 了,检测 MySQL 的 metrics 却一直是 DOWN 状态
排查一下,如果说是 prometheus.yml 写错了,那压根就不会显示后台;说明是 dev_node.yml 写错了什么
cat prometheus/targets/dev_node.yml

确实是 targets 写错了
我们把他改对了,再看看
20241102202135740.png&pos_id=img-Shte1ISH-1730621534027)
由此说明,服务发现可以先把没有配置服务的 IP(端口)加上,只不过暂时会显示 DOWN 的状态
其他方法进行服务发现
除了基于文件的服务发现,Prometheus 还可以通过基于 k8s 的服务发现、基于 DNS 的服务发现
PromQL
- PromQL(Prometheus Query Language)
- Prometheus 自己开发,类似于 SQL 中的 DQL
- 使用这个查询语言能够进行各种聚合、分析和计算,使管理员能够根据指标更好地了解系统性能
时序数据库 TSDB
特点
- 数据写入——写多读少
- 数据查询——对最近生成的数据读取概率高;按一定的时间范围读取一段时间的数据
- 数据存储特点——数据存储量大;数据具有时效性(数据有一个保存周期)
时序数据库的基本要求
- 支持高并发、高吞吐的写入
- 快速查询的性能:提供索引支持或聚合查询
- 高可用性:在节点故障时能够自动恢复,保证系统的持续可用性;支持数据备份和恢复操作,防止数据丢失
- 可扩展性:支持通过添加新的节点来扩展存储和计算能力;
常见的时序数据库
- TimescaleDB: 基于 PostgreSQL 的时序数据库,支持 SQL 查询和事务处理
- OpenTSDB: 基于 HBase 的时序数据库,适用于大规模数据存储和查询
- InfluxDB: 开源时序数据库,支持高写入性能和灵活的查询语言
- VictoriaMetrics: 高性能、低成本的时序数据库,支持多租户和分布式部署
PromQL 操作符
数学运算
+(加法)-(减法)*(乘法)/(除法)%(求余)^(幂运算)
布尔运算
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
集合运算符
and(并且,交集)or(或者,并集)unless(差集)
操作符优先级
在 PromQL 操作符中优先级由高到低依次为:
^*, /, %+, -==, !=, <=, <, >=, >and, unlessor
PromQL 聚合操作
使用聚合操作的语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准差异)count(计数)count_values(对 value 进行计数)bottomk(后 n 条时序)topk(前 n 条时序)quantile(分布统计)
其中只有 count_values, quantile, topk, bottomk 支持参数(parameter)
without 用于从计算结果中 移除列举的标签,而保留其它标签。
by 则正好相反,结果向量中 只保留列出的标签,其余标签则移除。
例子
sum()
计算所有实例的活跃内存(node_memory_Active_bytes)总量,而不考虑具体的实例(instance)
sum(node_memory_Active_bytes) without (instance)
显示每个 HTTP 状态码(code)、请求处理程序(handler)、被监控的服务或目标(job)和 HTTP 请求方法(method)的请求次数
sum(http_requests_total) by (code,handler,job,method)
计算整个应用的 HTTP 请求总量
sum(http_requests_total)
count_values()
count_values 会为每一个唯一的样本值输出一个时间序列,并且每一个时间序列包含一个额外的标签
count_values("count", http_requests_total)
topk()
topk()用于对样本值进行排序,返回当前样本值前 n 位,或者后 n 位的时间序列
获取 HTTP 请求数前 5 位的时序样本数据
topk(5, http_requests_total)
quantile()
quantile 用于计算当前样本数据值的分布情况
quantile(φ, express) # 其中0 ≤ φ ≤ 1
当 φ 为 0.5 时,即表示找到当前样本数据中的中位数:
quantile(0.5, http_requests_total)
内置函数
计算 Counter (计数器)指标增长率
increase() 函数
increase(v range-vector)
# 参数v是一个区间向量,increase函数获取区间向量中的第一个后最后一个样本并返回其增长量
例:统计主机节点最近两分钟内的平均 CPU 使用率
increase(node_cpu_seconds_total[2m] )/120
node_cpu [2m] 获取时间序列最近两分钟的所有样本,increase 计算出最近两分钟的增长量,最后除以时间 120 秒得到 node_cpu 样本在最近两分钟的平均增长率
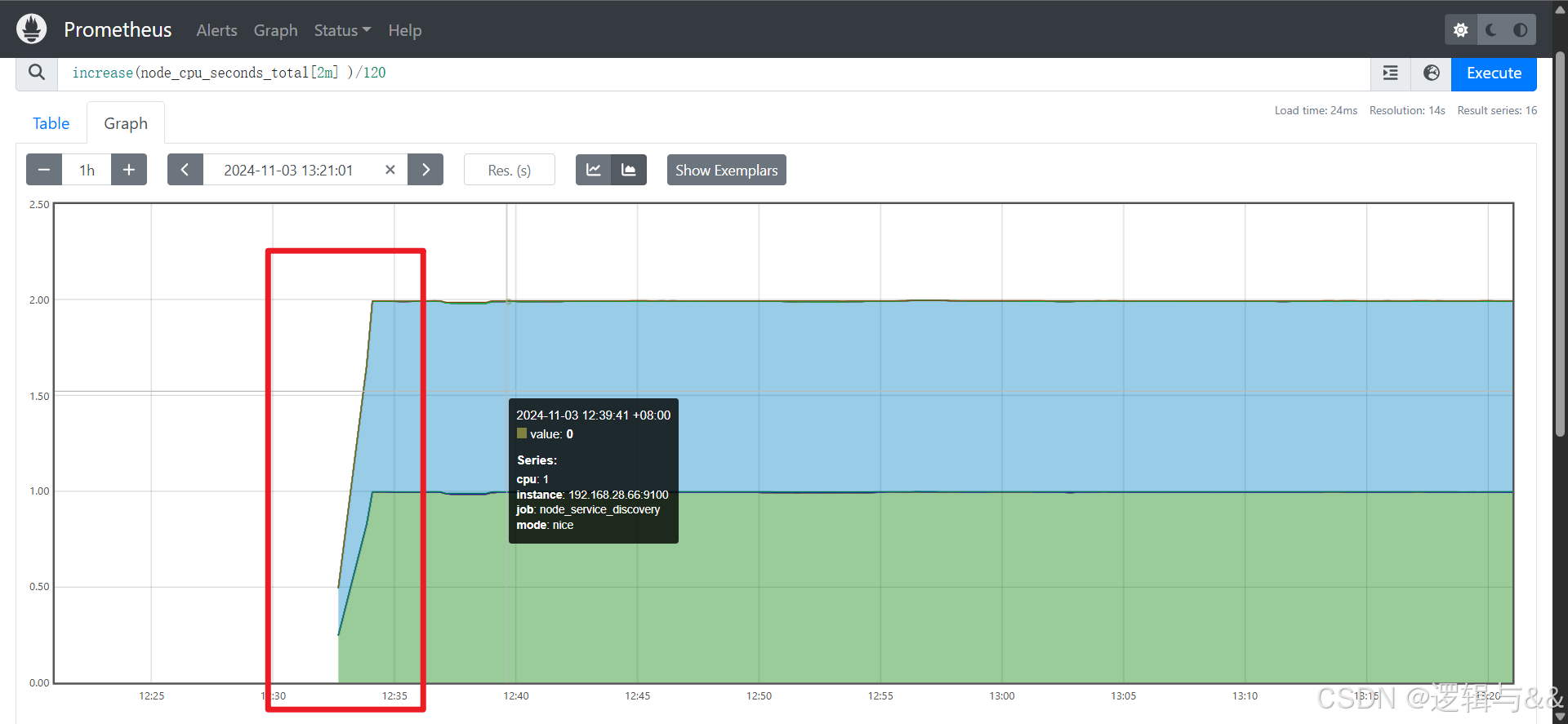
12:33 左右,CPU 使用突然上升到接近满载的状态,然后保持稳定。这表明在这个时间段内,系统开机经历了一次显著的负载增加
rate() 函数
rate(v range-vector)
# 直接计算区间向量v在时间窗口内平均增长速率
例:统计主机节点最近两分钟内的平均 CPU 使用率
rate(node_cpu_seconds_total[2m])
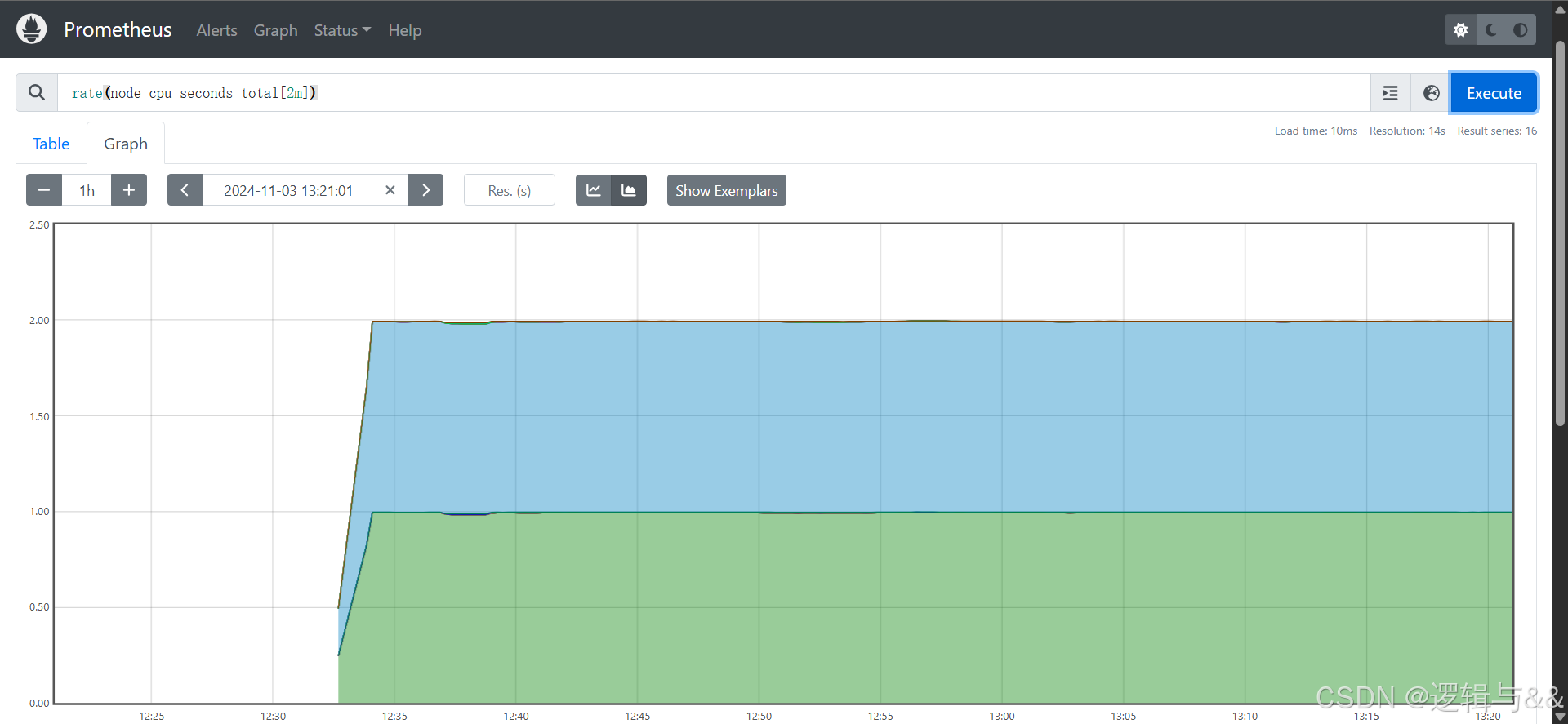
跟之前的incraese()函数处理的结果一模一样
irate() 函数
统计瞬时增长率,避免长尾问题
irate(v range-vector)
# 通过区间向量中最后两个样本数据来计算区间向量的增长速率
例:统计主机节点最近两分钟内的平均 CPU 使用率
irate(node_cpu_seconds_total[2m])
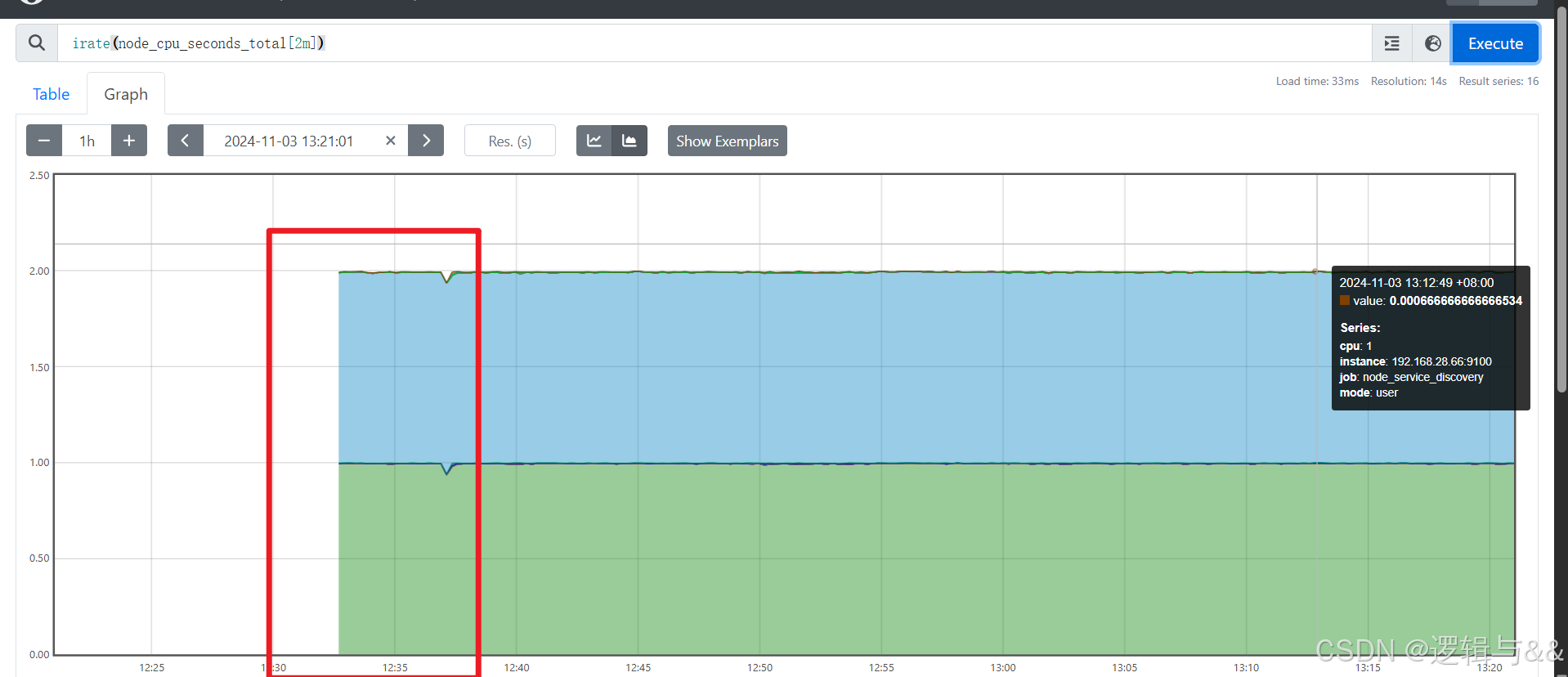
irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数
预测Gauge(仪表盘)指标变化趋势
predict_linear函数()
predict_linear(v range-vector, t scalar)
预测时间序列v在t秒后的值。它基于简单线性回归的方式,对时间窗口内的样本数据进行统计,从而可以对时间序列的变化趋势做出预测
例子:基于2小时的样本数据,来预测主机可用磁盘空间的是否在4个小时候被占满
predict_linear(node_filesystem_free_bytes{job="node_service_discovery"}[2h], 4 * 3600) < 0
统计Histogram(直方图)指标的分位数
Histogram的分位数计算需要通过histogram_quantile(φ float, b instant-vector)函数进行计算,φ(0<φ<1)表示需要计算的分位数
以指标http_request_duration_seconds_bucket为例
http_request_duration_seconds_bucket{le="0.5"} 0
http_request_duration_seconds_bucket{le="1"} 1
http_request_duration_seconds_bucket{le="2"} 2
http_request_duration_seconds_bucket{le="3"} 3
http_request_duration_seconds_bucket{le="5"} 3
http_request_duration_seconds_bucket{le="+Inf"} 3
http_request_duration_seconds_sum 6
http_request_duration_seconds_count 3
计算9分位数时,使用如下表达式
histogram_quantile(0.5, http_request_duration_seconds_bucket)
Grafana数据展示
Grafana支持图表模板导入,支持除Prometheus之外多种数据源(包括MySQL、zabbix、elasticsearch等)
部署Grafana
下载软件包并安装
官网地址:https://grafana.com/grafana/download
安装grafana
rpm -ivh grafana-7.5.3-1.x86_64.rpm
# 或者用yum装
yum install -y grafana-7.5.3-1.x86_64.rpm
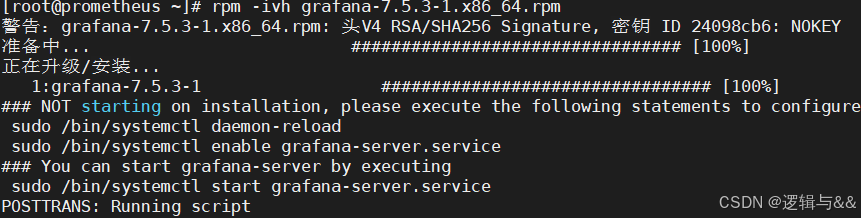
启动服务,加入开机自启
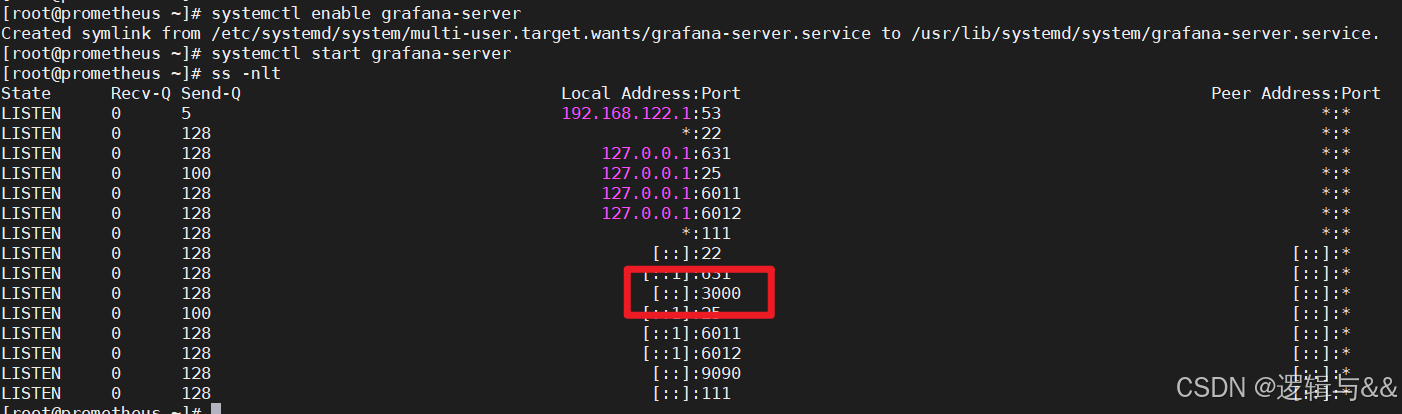
systemctl enable grafana-server
systemctl start grafana-server
看3000端口是否监听
访问Grafana
初始账号密码均为admin,登录以后提示修改密码
添加数据源
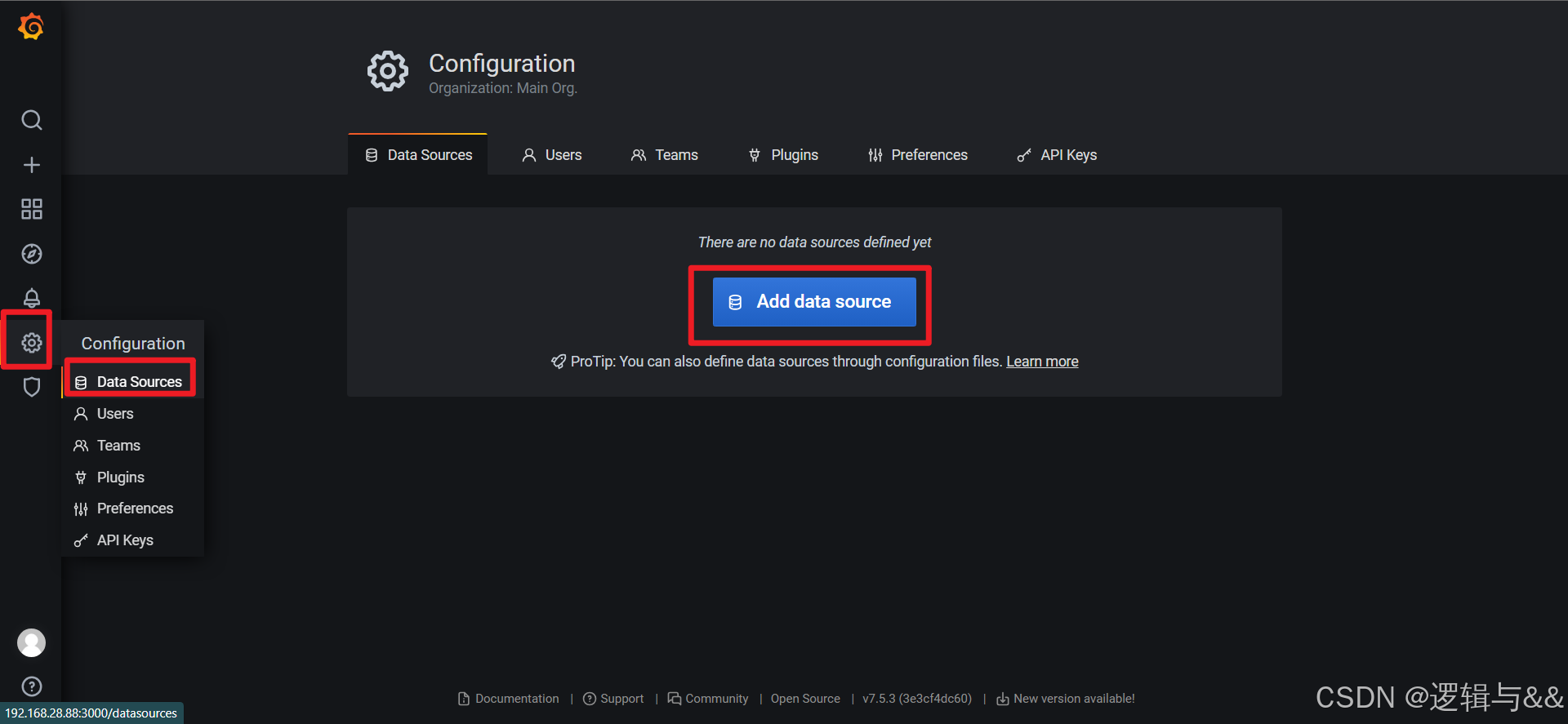
然后选择Prometheus数据源
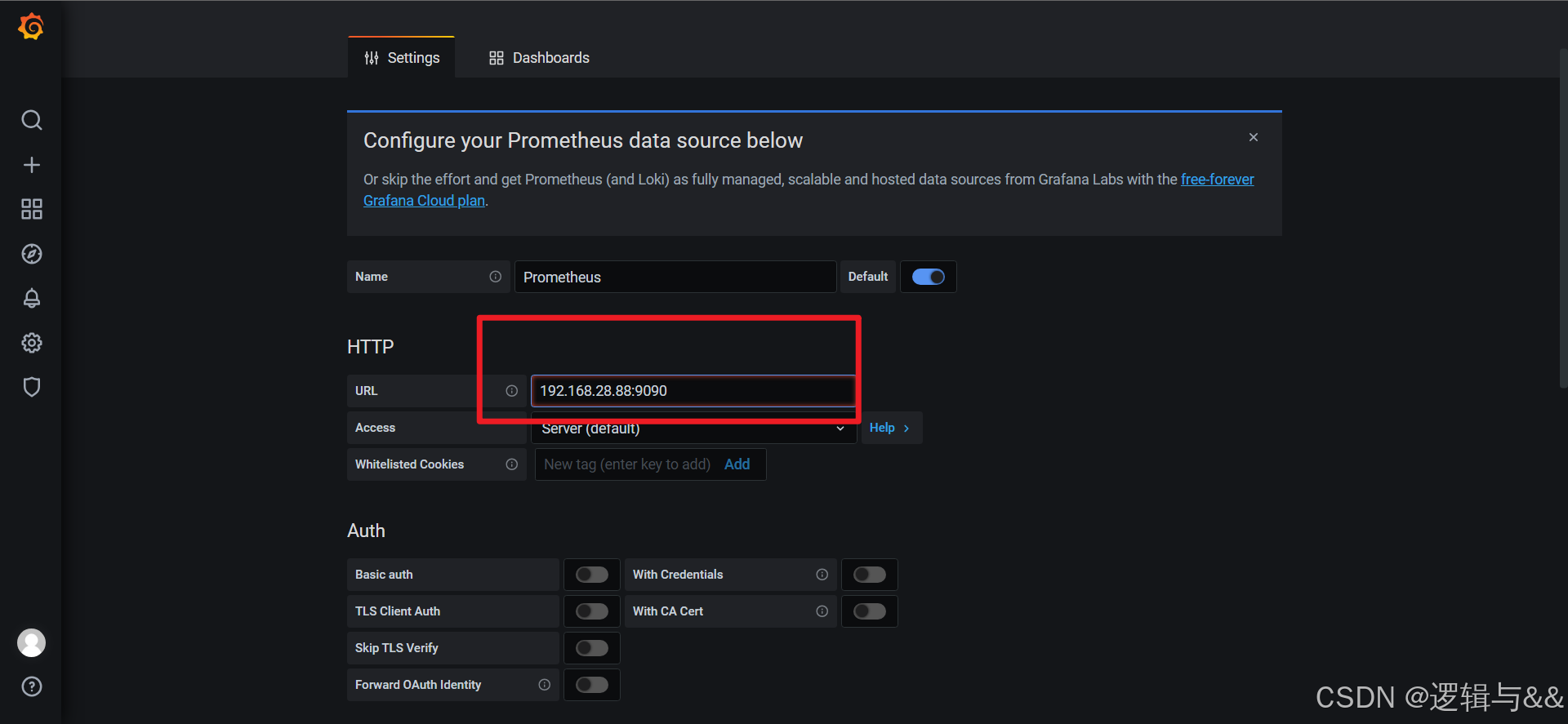
!记得保存设置,不然默认监测localhost:9090端口
新建一个叫Prometheus的文件夹
创建仪表盘
可以选择各种监控项
添加node1磁盘可用空间的监测
添加更多监控项
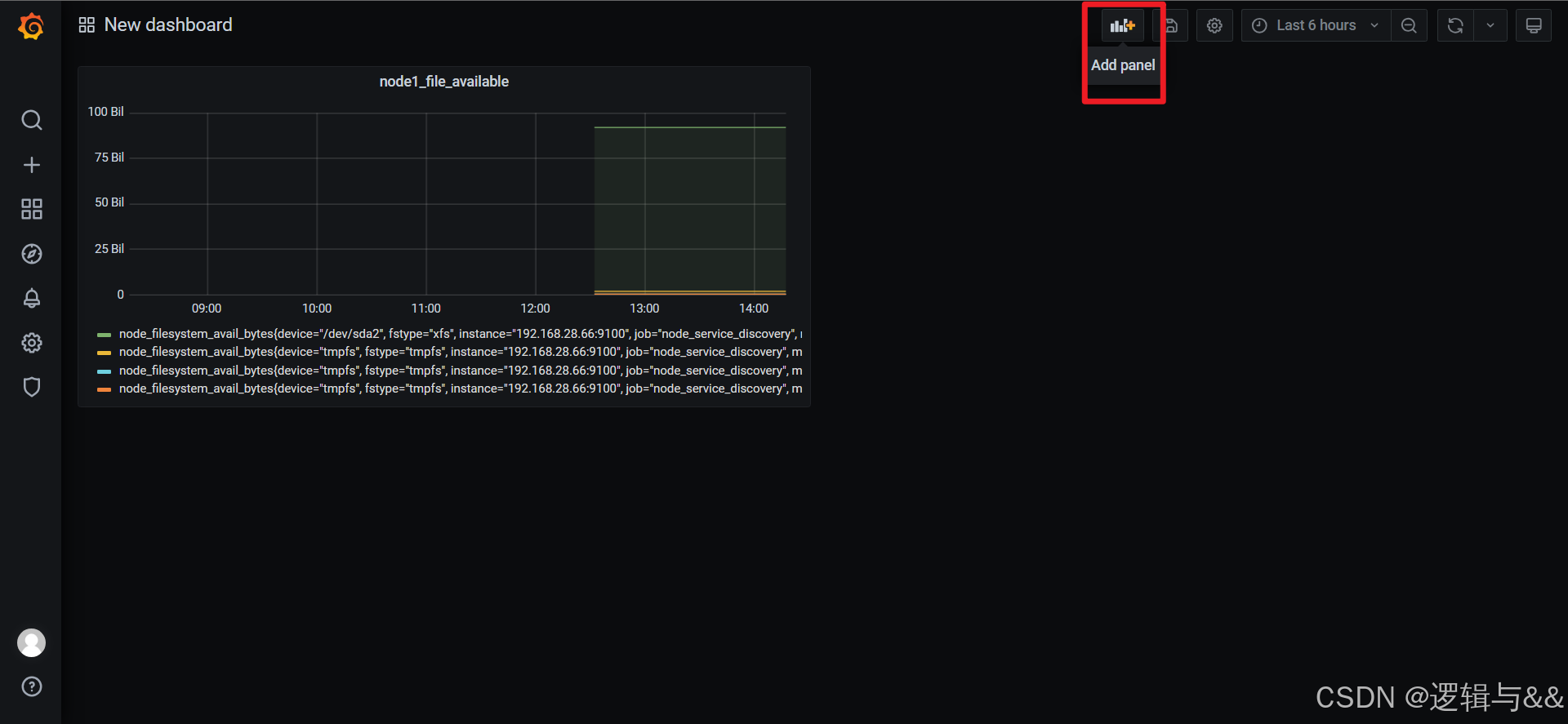
仪表盘
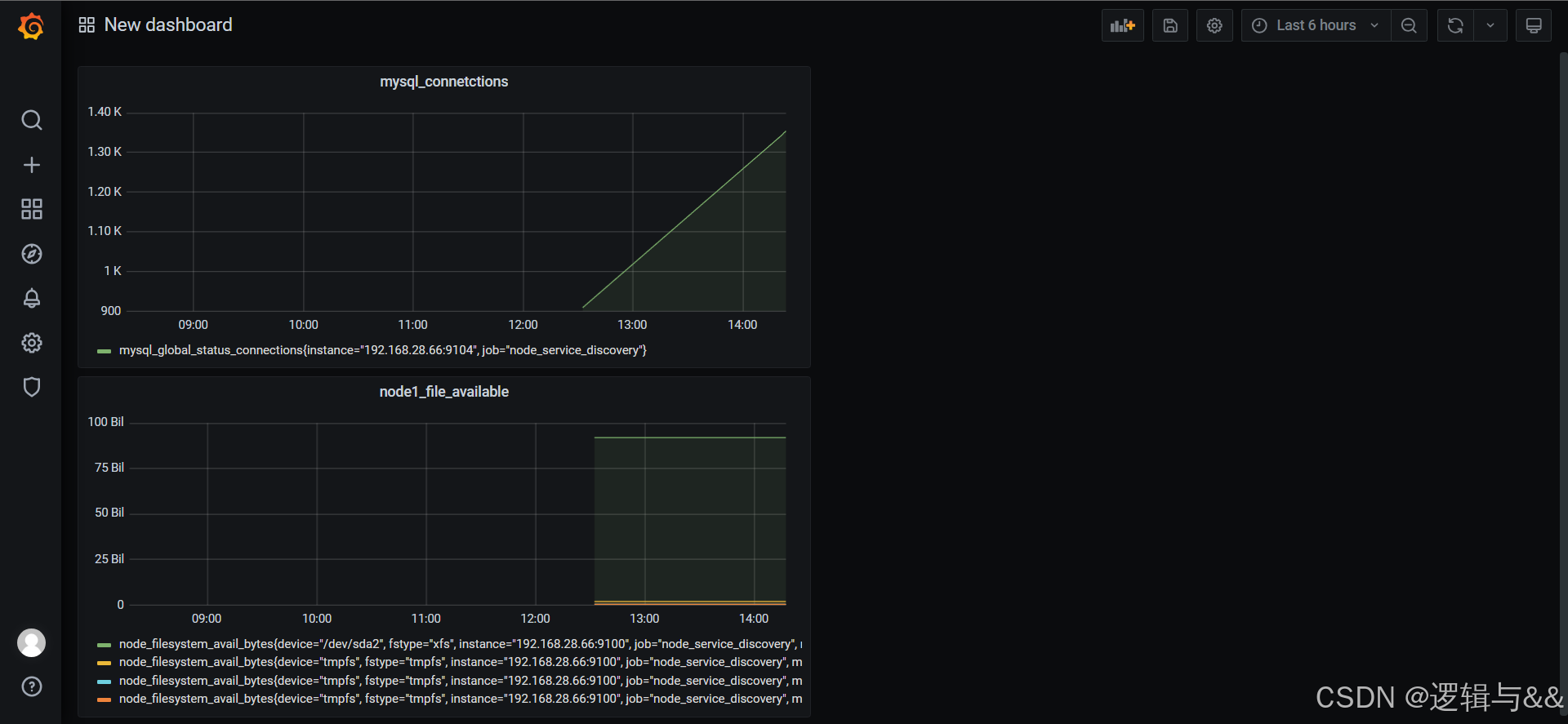
保存仪表盘
点击右上角的save dashboard
使用第三方模板
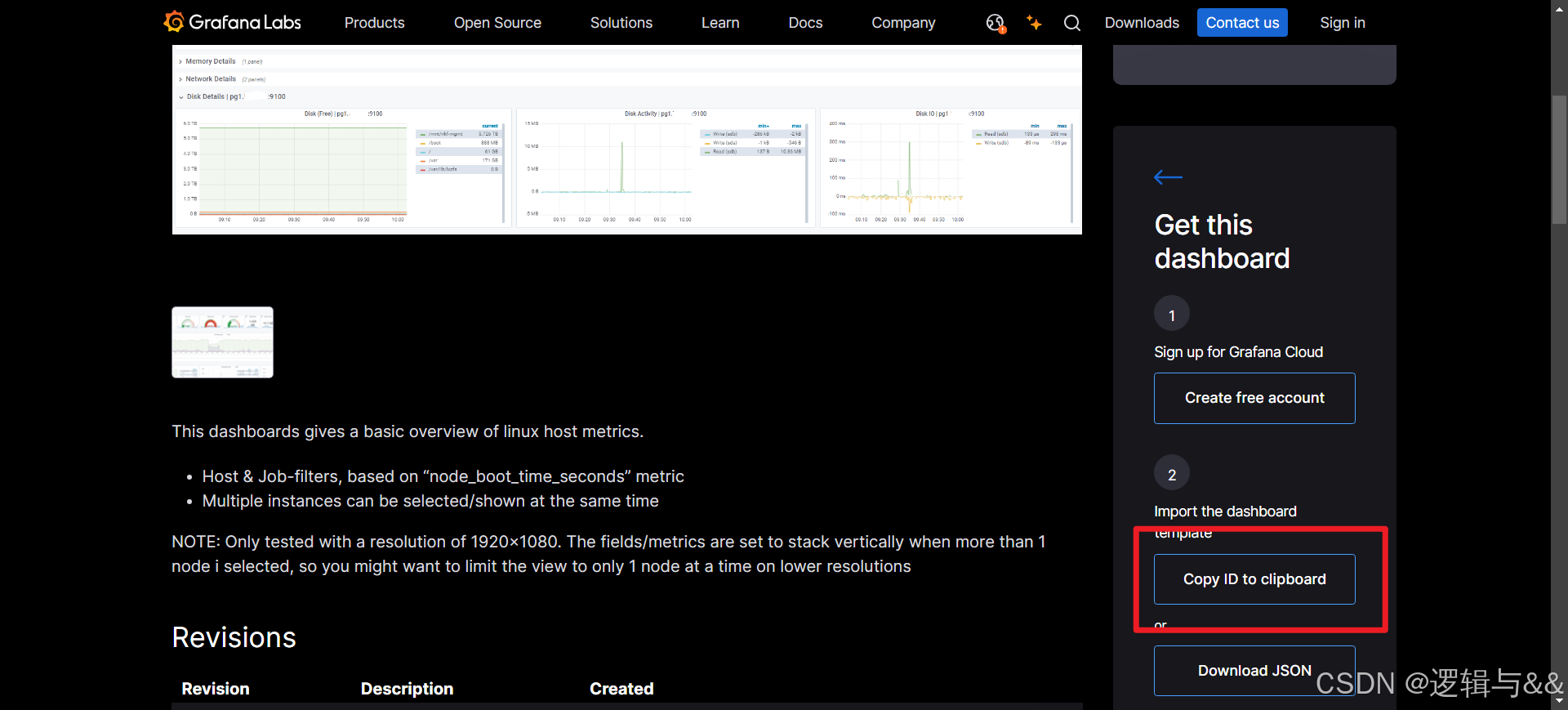
官方模板网站:https://grafana.com/grafana/dashboards/
根据需求选择合适的模板
复制模板ID
回到仪表盘进行导入
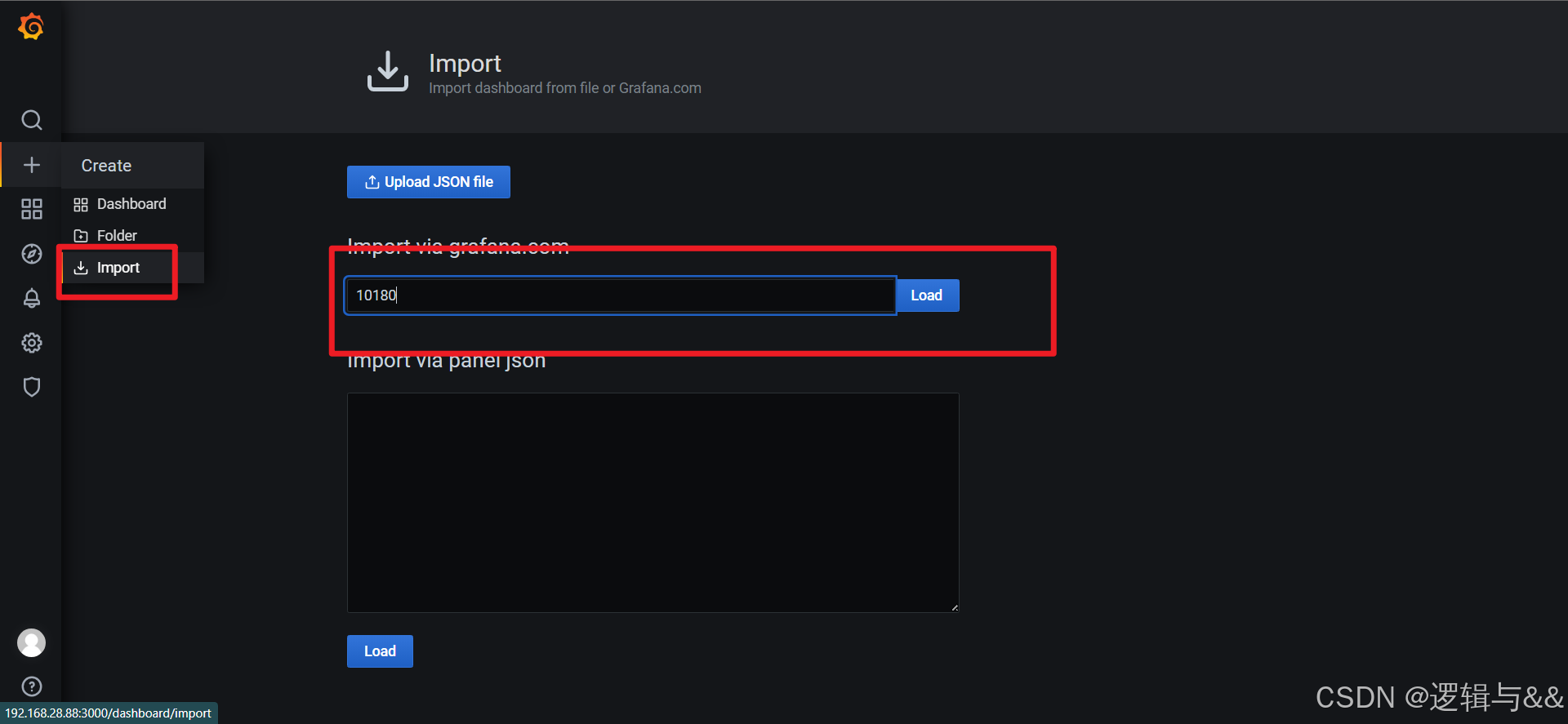
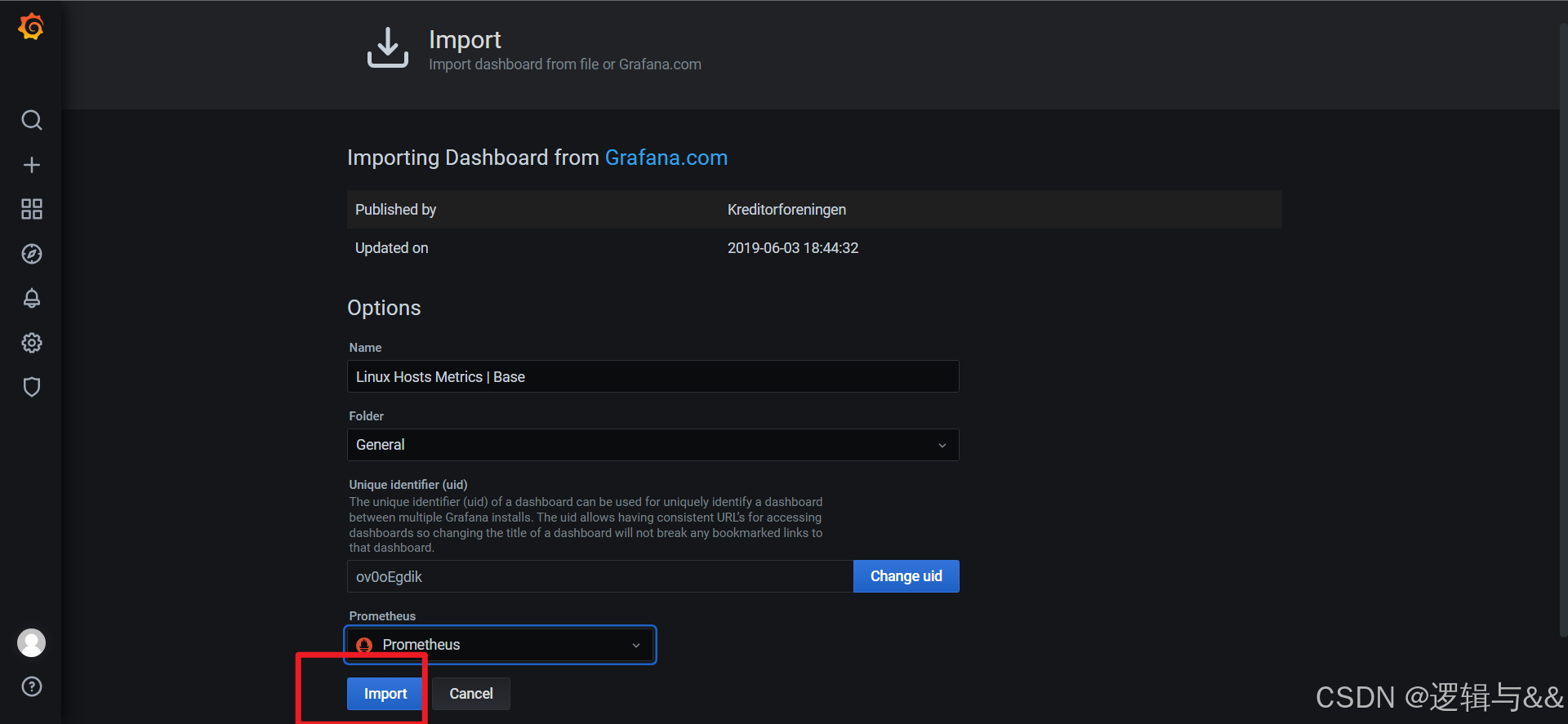
展现当前Linux主机的全部状态
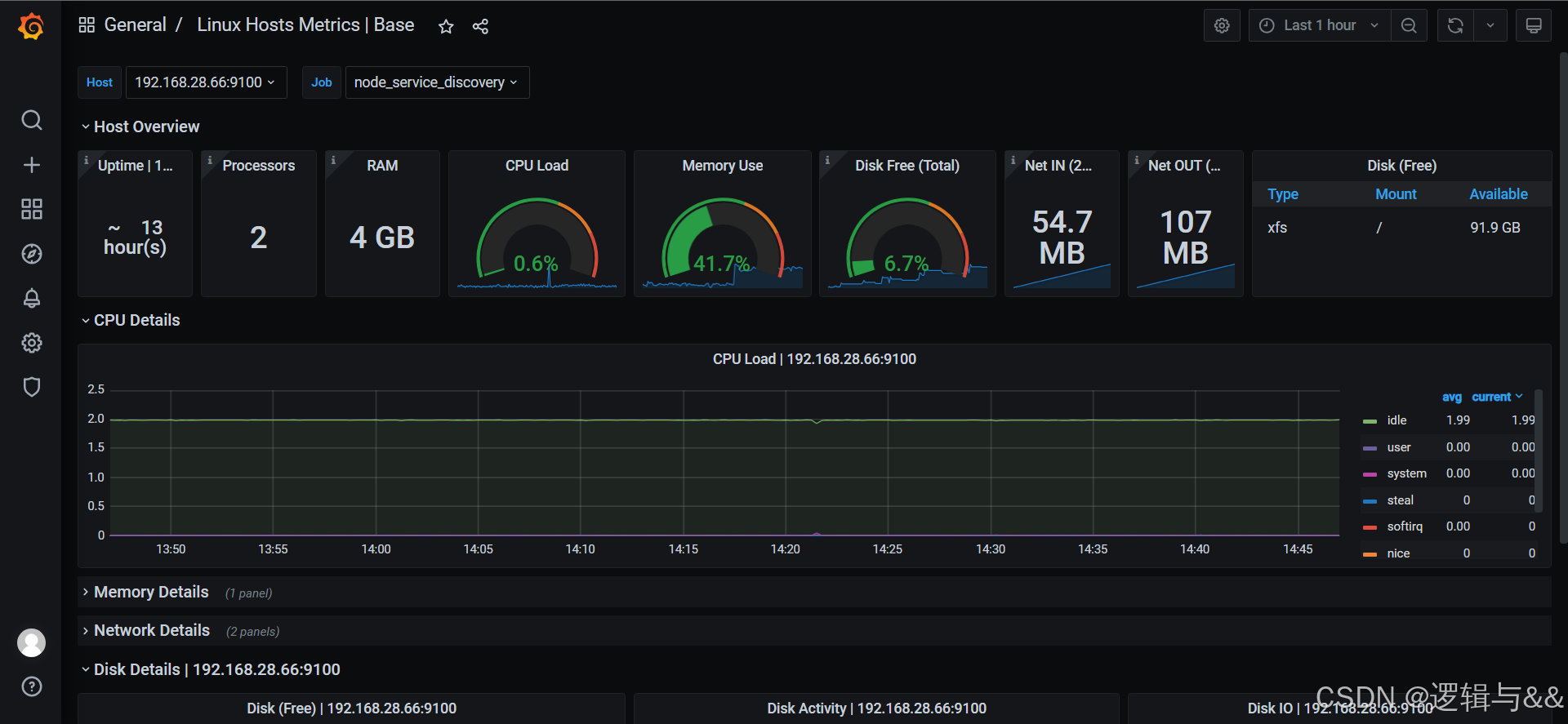
Altermanager告警
概述
- Prometheus对指标的收集、存储同告警能力分属于Prometheus Server和AlertManager两个独立的组件组成
- 前者仅仅负责基于告警规则生成告警通知,具体的告警操作则由后者完成
- AlertManager负责处理由客户端发来的告警通知
- 客户端通常是Prometheus Server,但也支持来自其他工具的告警
- AlertManageer对告警通知进行分组、去重后根据路由规则将其路由到不同的receiver,如email、企业微信、钉钉等
告警逻辑
- 在AlertManager上定义receiver,他们能够基于某个媒介接收告警信息的特定用户;
- 在Alertmanager上定义路由规则(route),以便将收到的告警通知按需分别进行处理
- 在Prometheus上定义告警规则生成告警通知,发送给Alertmanager
Altermanger机制
除了基本的告警,Atermanager还支持对告警进行去重分组、抑制、静默和路由等功能
分组机制
- 将相似告警合并为单个告警通知的机制
- 在系统因大面积故障而触发告警时,分组机制能避免用户被大量的告警噪声淹没,进而导致关键信息的隐没
抑制机制
- 系统中某个组件或服务故障而触发告警通知后,那些依赖于该组件或服务的其他组件或服务也会因此而触发告警
- 作用是避免类似的级联告警的一种特性,从而让用户的精力集中于真正的故障所在
静默机制
- 在一个特定的时间窗口内,便接收到告警通知,Alertmanager也不会真正向用户发送告警行为
- 通常,在系统例行维护期间,需要激活告警系统的静默特性
Altermanager的部署
下载解压安装包
mkdir /altermanager
tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz -C /altermanager/
cd /altermanager
和之前的组件类似,我们可以为这个文件夹赋予可执行权限并创建软链接
chown -R root:root alertmanager-0.21.0.linux-amd64/
ln -sv alertmanager-0.21.0.linux-amd64/ alertmanager

编辑Alertmanger配置文件
查看配置文件
# cat alertmanager.yml
global: # 全局配置模块
resolve_timeout: 5m # 用于设置处理超时时间,默认是5分钟
route: # 路由配置模块
group_by: ['alertname'] # 告警分组
group_wait: 10s # 10s内收到的同组告警在同一条告警通知中发送出去
group_interval: 10s # 同组之间发送告警通知的时间间隔
repeat_interval: 1h # 相同告警信息发送重复告警的周期
receiver: 'web.hook' # 使用的接收器名称
receivers: # 接收器
- name: 'web.hook' # 接收器名称
webhook_configs: # 设置webhook地址
- url: 'http://127.0.0.1:5001/'
inhibit_rules: # 告警抑制功能模块
- source_match:
severity: 'critical' # 当存在源标签告警触发时抑制含有目标标签的告警
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance'] # 保证该配置下标签内容相同才会被抑制
Alertmanager使用邮箱报警
QQ邮箱准备
生成授权码
修改配置文件
global:
resolve_timeout: 5m
smtp_from: '1640512870@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1640512870@qq.com'
smtp_auth_password: 'cdumhntvjsngejhf'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '1640512870@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
后台启动Alertmanager
./alertmanager &
关联Prometheus
# vim /prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.28.88:9093
.....
- job_name: "Alertmanager"
static_configs:
- targets: ["192.168.28.88:9093"]
添加告警规则
mkdir -p /prometheus/prometheus/rules/
cd /prometheus/prometheus/rules
vim rule.yml
groups:
- name: up
rules:
- alert: node
expr: up{job="node_service_discovery"} == 0
for: 1m
labels:
severity: critical
annotations:
description: "Node has been dwon for more than 1 minutes"
summary: "Node down"
在Prometheus配置文件中导入
cd /prometheus/prometheus
vim prometheus.yml
rule_files:
- "/prometheus/prometheus/rules/*.yml"

用promtool检查语法
./promtool check rules rules/rule.yml

重启prometheus
systemctl restart prometheus
在web中查看Rules
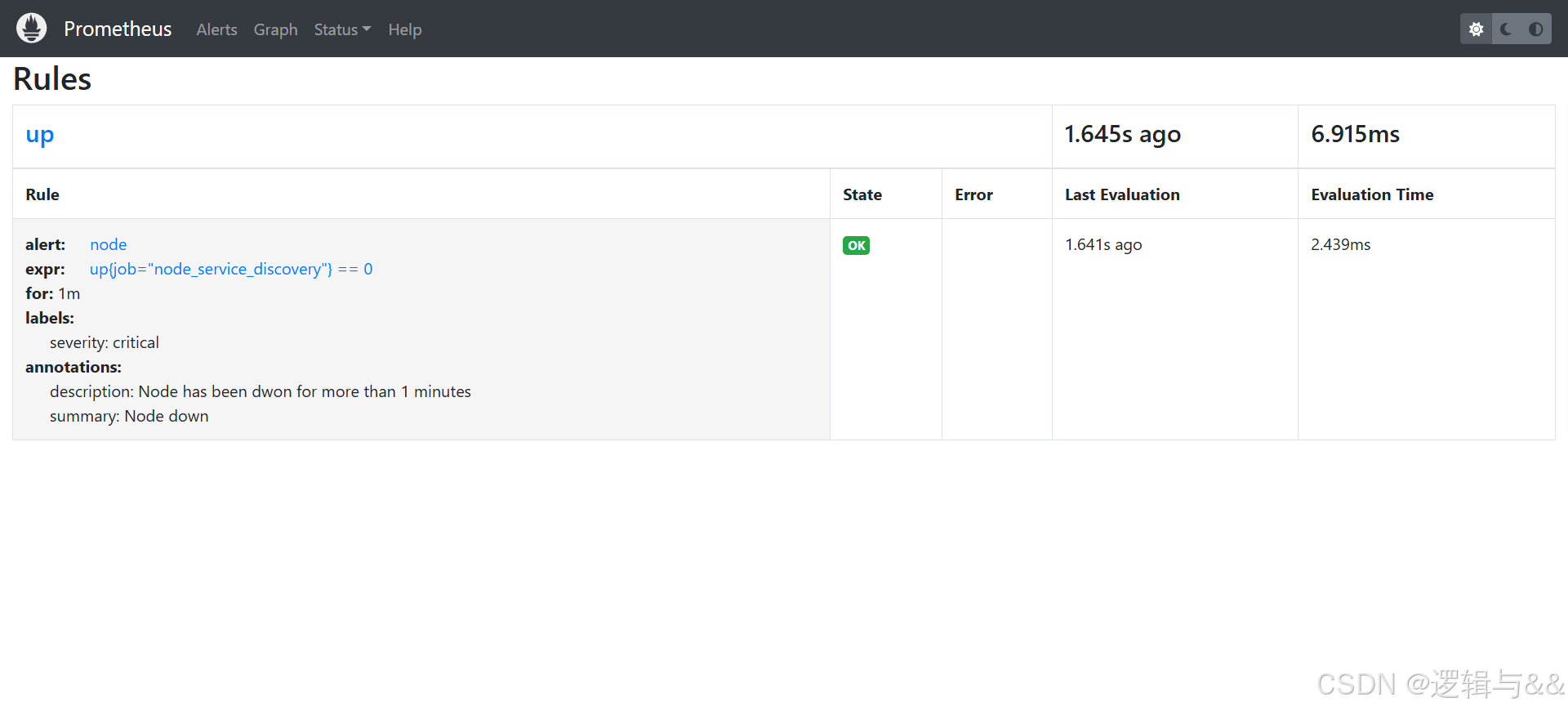
关闭node1测试
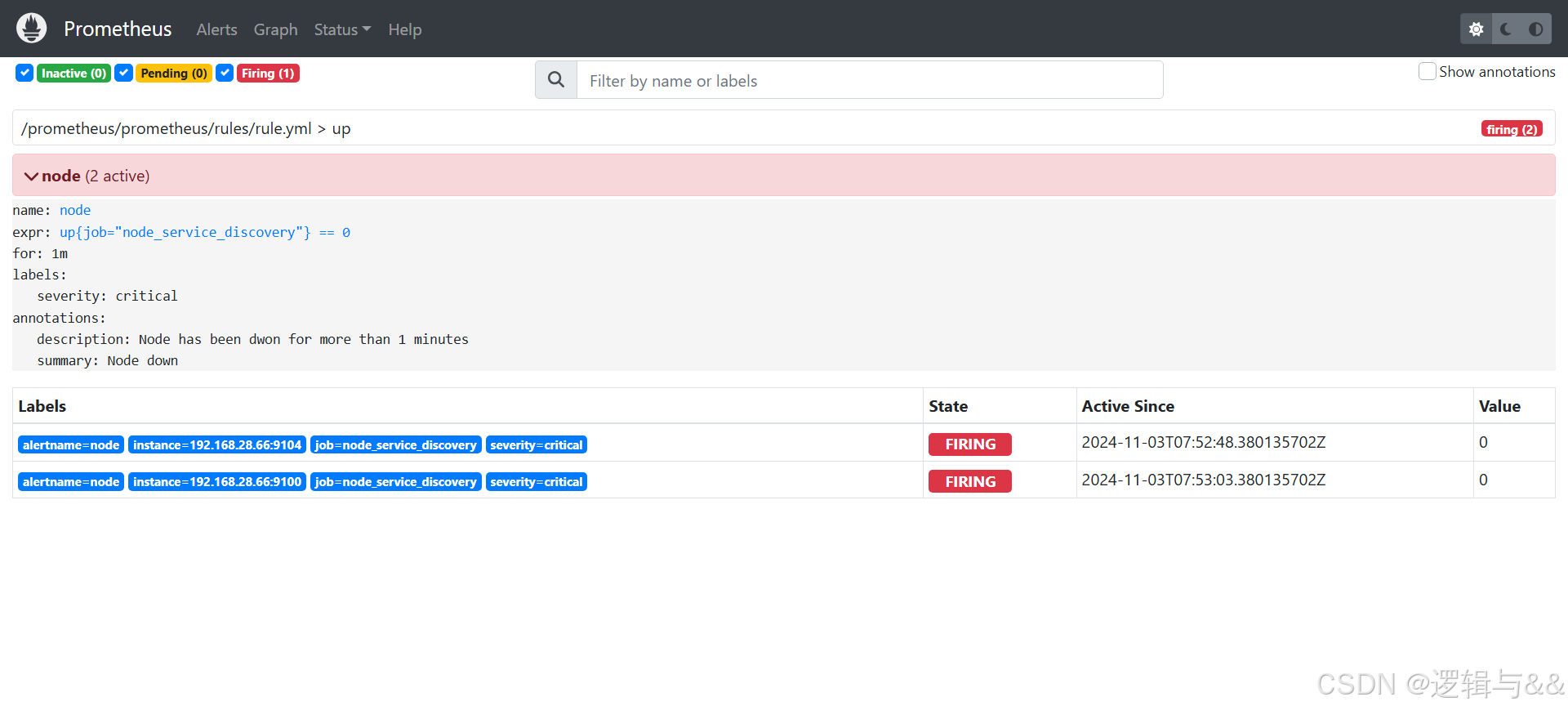
三种状态
- Interval没有满足触发条件,告警未激活状态
- pending,已满足触发条件,但未满足告警持续时间的状态,即未满足告警中for子句指定的持续时间
- firing,已满足触发条件且已经超过for子句中指定的持续时间时的状态
等一分钟看邮箱是否有告警