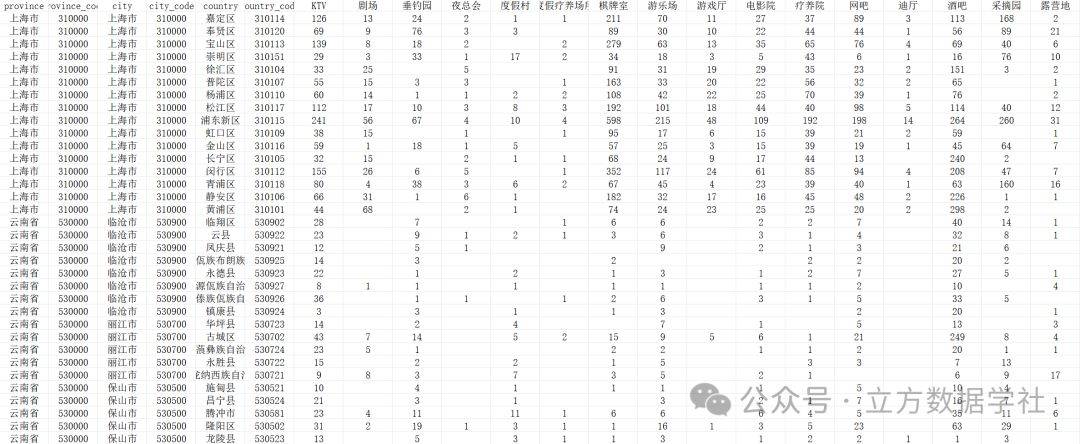
冒泡排序
基本原理:对存放原始数据的数组,按从前往后的方向进行多次扫描,每次扫描称为一趟。当发现相邻的两个数据次序和排序要求的大小次序不符合的时候,即将这两个数据进行互换。如果从小到大排序,这时,较小的数据就会逐个向前移动,好像气泡向上漂浮一样。
https://www.runoob.com/wp-content/uploads/2019/03/bubbleSort.gif
冒泡排序的特点:升序排序中每一轮比较会把最大的数下沉到最底,所以相互比较的次数每一轮都会比前一轮少
时间复杂度:O(n2)
代码演示:
#include <stdio.h>
int main() {
int a[10] = {2, 5, 1, 7, 6, 8}; // 前6个元素初始化,后面的元素为0
int n = 6; // 只对前6个元素进行排序
// 冒泡排序
for (int i = 0; i < n - 1; i++) { // 外层循环到 n-1
//为什么对于第一次循环需要进行n-1次循环
//每一轮都是将最大的数排到最后 当倒数第二大的数排好之后 最小的数也就已经排好了
for (int j = 0; j < n - 1 - i; j++) { // 内层循环到 n-1-i
//为什么需要循环n - 1 - j
//当最大的数排好后就已经不要再进行一次排序了 -1是为了防止数组越界
if (a[j] > a[j + 1]) {
//交换
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
}
}
}
// 输出排序后的数组
for (int i = 0; i < n; i++) {
printf("%d ", a[i]);
}
return 0;
}
快速排序

#include <stdio.h>
void QuickSort(int *arr,int low,int high){
if(low<high){//不加这个条件会死循环
int i=low;
int j=high;
int key=arr[low];
while(i<j){
while(i<j&&arr[j]>=key)
j--;
if(i<j)
arr[i++]=arr[j];//先赋值在自增
while(i<j&&arr[i]<key)
i++;
if(i<j)
arr[j--]=arr[i];//先赋值在自增
}
arr[i]=key;
QuickSort(arr,low,i-1);//给左边排序
QuickSort(arr,i+1,high);//给右边排序
}
}
int main(){
int a[11]={25,1,12,25,10,10,34,900,23,12,80};
QuickSort(a,0,10);
int i;
for(i=0;i<11;i++){
printf("%d ",a[i]);
}
return 0;
}
这是曾经思考过的问题, 它为什么叫快速排序呢?思考无果,然后忘记了,然后昨天被问起,自然想不出很好的答案。直到,看到了《暗时间》上有这个问题的答案。
在《暗时间》里,作者刘未然并没有直接给出答案,而是先说了两个游戏,猜数字和称球。这两个问题都很好理解,并且不难解答。然而,令我豁然开朗的是,他们指向了同一个思想,分而治之!把问题不断切割一半又一半,直到答案水落石出。
回到正题,我们的目标是排序,无论哪个排序方法都是基于两两比较的,问题在于如何才能减少比较的次数呢?举个例子,有这么一组数:1,2,3,4,5,15,78,89,90,100,200;一共11个。并且给出的初始顺序是从小到大的, 现在要排成从大到小。快速排序的思想,就是从中抽取一个数(称为基准吧),然后大于基准的在一边,小于或等于在另一边。比如,现在随机的抽取了78,那么1,2,3,4,5,15会在一边,89,90,100,200会在另一边。这时候,注意到,从这一刻开始,小于78的那些数就再也没有机会与大于78的数进行两两比较了。快速排序用了分而治之的思想,虽然,由于随机抽取,我们最好第一次抽到的是15,这样就平分了。但是没关系。忽略掉这个随机性因素,快排还是把大问题分成了两个小问题,哪怕这两个字问题不一定对等。只要递归下去,结果水到渠成。
相比大家应该都玩过猜数的游戏。就是给你一个100以内的数,然后让你猜这个数是多少。
先说第一个解决方案,就是从0到100一个一个数。
第二个解决方案就是先猜50,如果比50大就猜50左边的数,如果比50小就猜50左边的数,假设这个数是75,小于50的数就再也不用比较,就大大减少了比较次数。
这个例子就可以看成一个分而治之。把大问题拆成小问题。
而用到这个分而治之的想法时,在c语言就可以使用递归。
时间复杂度:O(N*logN)
空间复杂度:O(logN)
稳定性:不稳定