本文以兰州市为研究区域使用计算机视觉技术从交通摄像头拍摄的交通图像中提取实时交通流量和街景特征,以预测PM2.5浓度,并解释道路环境变化对PM2.5水平的影响。
【论文题目】
Enhancing urban real-time PM2.5 monitoring in street canyons by machine learning and computer vision technology
【题目翻译】
利用机器学习和计算机视觉技术增强城市街道峡谷中的PM2.5实时监测
【期刊信息】
Sustainable Cities and Society,Volume 100, January 2024, 105009
【作者信息】
Zhiguang Fan, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Yuan Zhao, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000,zhaoyuan@lzu.edu.cn
Baicheng Hu, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Li Wang, 兰州大学西部生态安全协同创新中心,中国兰州730000
Yuxuan Guo, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Zhiyuan Tang, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Junwen Tang, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Jianmin Ma, 北京大学城市与环境学院地表过程实验室,中国北京100871
Hong Gao, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Tao Huang, 甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
Xiaoxuan Mao,甘肃省环境污染预测与控制重点实验室,兰州大学地球与环境科学学院,中国兰州 730000
【论文链接】
https://doi.org/10.1016/j.scs.2023.105009
【关键词】
PM2.5、城市道路、街景、交通图像、计算机视觉技术、极端梯度提升 (XGBoost)
【本文亮点】
-
提出了基于机器学习的方法,通过交通摄像头图像预测城市道路PM2.5。
-
从交通图像、天气数据和交叉口PM2.5中提取特征。
-
开发了5个极端梯度提升回归(XGBR)模型,并使用SHAP分析评估输入变量对预测的影响。
-
确定了天气、交通流量和街道峡谷作为影响PM2.5的主要因素。
-
在20个点上验证了XGBR模型,并与极端梯度提升分类(XGBC)模型进行了外推准确性比较。
【摘要】
在高峰时段,行人和司机都面临着较长时间的道路空气污染暴露,增加了呼吸系统疾病的风险。街道峡谷中的交通流量、建筑特征和天气条件的变化导致不同道路段和交叉口的暴露水平不同。尽管部署大量传感器可以实时获取每个道路段的PM2.5水平,但它们无法解释天气、交通和建筑对PM2.5水平的影响。因此,我们在兰州市尝试使用计算机视觉技术(CVT)从交通图像中提取实时交通流量和街景特征,以预测PM2.5浓度,并解释道路环境变化对PM2.5水平的影响。结果表明,通过使用极端梯度提升(XGB)回归模型,PM2.5预测的决定系数达到R²=0.956。气象条件、交通流量和建筑物是预测道路PM2.5浓度的关键变量。气象条件控制了道路PM2.5水平的持续波动,而交通流量则可能导致PM2.5水平的突然变化。研究表明,交通摄像头和CVT的结合可以获取道路PM2.5浓度,为快速了解道路污染状况、识别高污染道路以及进行道路暴露评估提供了重要帮助。
【引言】
城市化导致了中国城市人口的显著增加和人类健康风险的上升(Fan et al., 2022; Hu & Zhao, 2022; Singh et al., 2021; Zhu et al., 2021)。城市中的繁重交通被认为是细颗粒物(PM2.5)的主要来源(Askariyeh et al., 2020; Li & Managi, 2021; Luo & Liao, 2015; Sánchez-Ccoyllo et al., 2009)。因此,全面了解道路附近的空气污染特征可以为识别道路污染源和评估相关暴露风险提供基础。道路上颗粒物的增加可能由燃料燃烧、车辆组件磨损和尘土再悬浮造成。PM2.5是由无机和有机成分组成的复杂混合物,可能导致不良健康后果(Guidoni et al., 2020; Peng et al., 2021; Yang et al., 2020)。流行病学研究和近年来的冠状病毒气溶胶传播研究已将PM2.5暴露与呼吸系统疾病相关联(Tang et al., 2020; Wang et al., 2021)。高峰通勤时段的高车流量和行人流量可能增加通勤者的健康风险。然而,稀疏的固定点监测不足,进一步增加了了解城市道路PM2.5污染实时变化的难度(Buonanno et al., 2011; Steffens et al., 2012)。
大量研究评估了道路空气污染及其对通勤者的暴露风险。这些研究利用便携式移动监测设备进行移动追踪或固定点监测,以高时间和空间分辨率捕捉颗粒浓度的时空变化。它们考虑了城市道路微环境中的各种因素,如气象条件、通勤类型和交通流量(Kumar et al., 2018; Qiu et al., 2017; Targino et al., 2016)。此外,某些研究将重点扩展到城市环境因素,通过优化城市街道峡谷的多维空间形态和增加城市绿地覆盖,识别缓解城市空气污染的潜在途径(O’Regan et al., 2022; Wang et al., 2022)。这些研究通常综合了实地观察、计算流体动力学模型、物理模拟和经验模型,以全面了解不同情境和地点通勤者面临的道路空气污染和暴露风险(Fu et al., 2017; Zhang et al., 2015)。交通流量和车辆类型在确定主要PM2.5和前体排放物中至关重要(Li et al., 2022; Xu et al., 2022),但在城市尺度上实时监测这些因素仍然具有挑战性。尽管存在已建立的方法,正如Khan et al. (2018)所指出的那样,“使用传统的RADAR、LIDAR和LASAR技术解决这个问题既耗时又昂贵且繁琐。”总体而言,现有的道路空气污染研究方法各有局限。实地观察的覆盖受限于部署和维护成本。计算流体动力学(CFD)模型需要大量资源,可能产生不确定的结果。物理模拟受限于实验条件。经验模型受限于数据获取,当处理新情境时可能表现不佳。因此,考虑到高成本和计算复杂性,这些传统方法往往未在城市的大尺度和长时间尺度上实施。
为了获得城市地区空气污染物的空间分割特征,广泛使用了土地利用模型和移动监测(Apte et al., 2017; Patton et al., 2015; Zwack et al., 2011)。移动监测需要沿街道进行反复的空气污染物取样,并同时测量气象条件(Hankey et al., 2019)。通过将经验模型、移动监测和计算机视觉技术(CVT)相结合,开发了新方法,以实现更准确且空间分辨率更高的城市空气污染预测。这些方法通过CVT从Google街景中提取了详细的街道峡谷特征,如道路、建筑物、植被和车辆(O’Regan et al., 2022)。这些特征被用于对城市街道中的细颗粒物和超细颗粒物(如黑碳、PM1和PM2.5)进行定量评估(Liu et al., 2021; Lloyd et al., 2021; Lu et al., 2021; Qi & Hankey, 2021)。虽然这些方法为街道尺度的空气污染预测开辟了新途径,但Google街景或百度街景并未实时捕捉街道峡谷特征(Kerckhoffs et al., 2022; Meng et al., 2020; Yu et al., 2022)。虽然道路、建筑物和常绿植被很少发生变化,但车辆作为主要排放源在道路上的数量却有很大变化。在一些研究中,进行了街道移动监测,并将结果与街景图像进行比较,以建立实时交通与街景图像之间的关系,从而改善城市道路上空气污染的短期空间分布(Messier et al., 2018)。移动空气质量监测的优势在于其能够将测量空间分辨率提高到街道级别以下,但代价是每个特定位置的时间稀疏性。然而,移动监测无法实现固定位置的连续时间观测,因此尽管有效捕捉了空间变化,但在揭示细粒度的时间变化方面存在限制。此外,由于成本限制,固定监测站难以实现与移动监测相同的空间覆盖范围。因此,平衡捕捉道路污染的时间细节和扩展到其他感兴趣地点的覆盖范围是一个重大挑战。
为克服这些挑战,我们的目标是开发一个利用交通摄像头广泛部署的城市道路空气污染评估模型。该模型将利用实时交通图像获取实时道路PM2.5浓度,从而为更多的城市交叉口获取实时污染信息。中国已经建立了超过1500个空气质量监测站。全国每个主要城市都有多个到几十个监测站(Rohde & Muller, 2015)。然而,几乎不可能单独覆盖每个交叉口以提供实时的大气污染浓度。另一方面,交通摄像头已经覆盖了城市中几乎所有主要交叉口。如果能够直接从交通图像中检索PM2.5浓度,这将意味着可以避免在交叉口部署空气质量传感器和大气污染监测设备的相关成本。同时,这种方法也将解决监测站空间覆盖密度不足的问题。在这个思路的指导下,我们进行了实地调查,从道路图像中提取固定的道路环境和时变交通特征,并结合语义分割和目标检测技术。提取的数据与通过便携式监测仪器和气象仪器采集的PM2.5浓度相结合,用于训练和建立道路PM2.5预测模型,基于成熟的图像识别技术。我们的目标是获得比以前报告的经验模型更好的PM2.5预测结果。我们选择了三个PM2.5取样点用于模型训练和分析,并增加了二十个地点以评估模型的外推能力。本研究的目标是探索通过使用交通摄像头图像进行实时PM2.5评估的方法,并促进在不同实际街道空气污染情境下的数据获取。
【材料和方法】
2.1. 采样点
兰州市位于中国西北部,具有山谷地形,人口约为438万。交通拥堵指数(CDI)可以反映城市的交通拥堵情况,其中CDI ≥1.5 表示拥堵。在中国77个城市中,兰州市的最高CDI达到了2.75,平均CDI排名第14位,特定时段的CDI显示拥堵主要发生在通勤高峰期(Wei et al., 2022)。我们选择了兰州市的城关区作为模型开发的目标区域,因为该区占全市人口的34%,是最为拥挤且交通拥堵最严重的区域。考虑到工作日和周末交通拥堵的变化,我们确保了采样覆盖了一周的时间。我们在三个站点上收集了为期一周的道路数据,旨在用最少的样本量建立和测试方法的预测能力。这种方法将为采样策略和相关成本提供重要见解。需要注意的是,样本量丰富通常能提升方法性能,涵盖更多的天气条件、季节、道路情况和城市特征。同时,周内的道路污染变化也不容忽视。我们目前的重点是以低成本测试方法的可行性。因此,我们选择了相同季节的一周作为采样期间,以实现成本效益。
如图1所示,我们选择了三个道路交叉口进行街景图像、气象数据和PM2.5浓度的采集。这三个站点具有不同的道路环境和交通流量特征,位于不同类型的土地使用区域(图S1)。在这些站点上收集的数据用于训练这些站点的模型,PM2.5和气象变量在交通高峰期的早晨(8:00–9:00)和晚上(17:00–18:00)每天连续采样为期一周。由于在2022年3月31日至4月6日,站点1进行了交通管控(COVID-19防控措施),为了比较高峰期和正常时间的交通差异,在此期间对站点1进行了额外的7天采样。虽然这三个训练站点可以用于模型开发和评估站点的PM2.5浓度预测能力,但尚无法确定模型是否能预测城市中其他站点的情况。换句话说,验证模型的外推能力需要额外的交叉口样本进行验证。额外的二十个站点(T1至T20)按照相同的方法进行采样,仅用于评估模型的外推能力。因此,我们检验了基于有限道路交叉口图像的模型在没有采样数据的情况下预测其他道路和交叉口PM2.5浓度的能力。实地采样由作者进行。表S1和图S2展示了每个站点的详细采样时间和简要的道路条件描述。
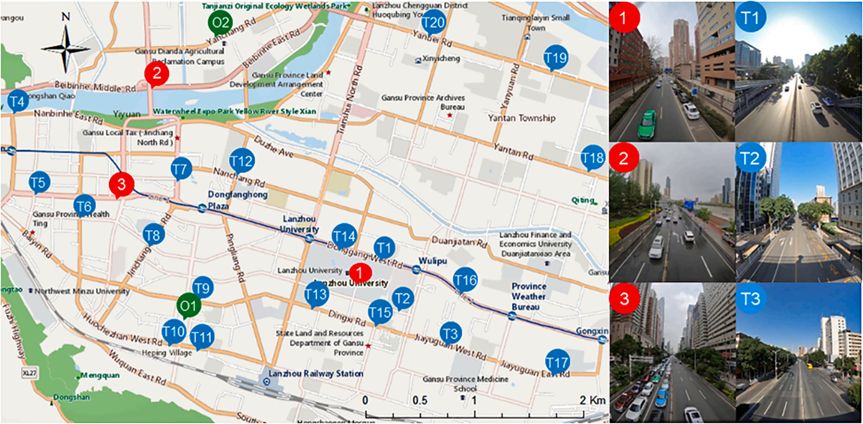
图1. 三个训练站点(红色)1至3的位置,二十个评估站点(蓝色)T1至T20的位置,以及两个官方空气质量监测站(绿色)O1和O2的位置。
根据兰州市的道路特点,我们选择了三种主要的道路类型,具有不同的基本特征:站点1:紧邻大学校园,尤其在晚餐时间有大量的行人。站点2:位于黄河大桥上,具有多车道、交通拥堵和植被覆盖的特点。站点3:位于兰州市中心的主干道上,特征为交通密集和行人众多。
2.2. 街景采集过程
2.2.1. 街景采集
我们在一个交通立交桥上设置了一台相机,以便获取整个交叉口的交通图像。使用了全景相机(Max,GoPro,美国)来记录交通和道路场景的视频数据。视频数据以2秒间隔提取,以匹配气象数据和PM2.5采样的频率。提取的视频数据中的每一帧都用于通过目标检测技术进行车辆计数和车牌识别(图2a)。
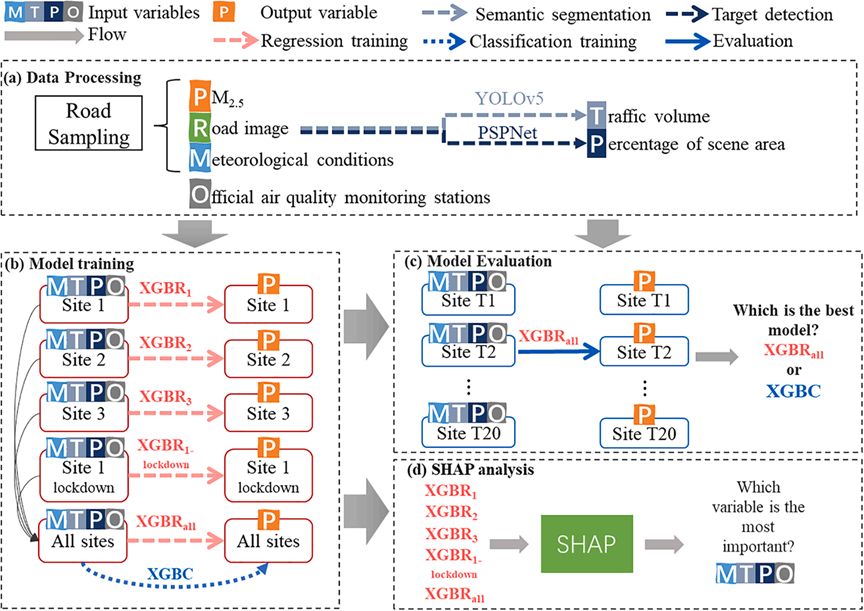
图2. (a) 数据处理流程图, (b) 模型训练流程图, (c) 模型评估流程图, 和 (d) SHapley Additive exPlanation (SHAP) 分析流程图。
2.2.2. 车辆检测和车牌监控
为了监控车辆的车牌,我们使用了一个名为“You Only Look Once (YOLOv5)”的视觉模型,这是一个实时目标检测模型(https://github.com/ultralytics/yolov5)。本研究仅关注由于车辆在道路上行驶引起的PM2.5浓度变化,考虑到这些变化可能来源于行驶车辆的排放和由此产生的重悬浮。研究排除了停车车辆对PM2.5的影响(图S3)。随后,蓝色(汽油车)、绿色(新能源车)和黄色(卡车和公交车)车牌分别用作统计分析的输入变量。我们收集的车牌数据中,YOLO v5在蓝色车牌上的平均精度(AP)为85.5%,绿色车牌为84.3%,黄色车牌为76.5%。有关车牌颜色、车辆类型和燃料类型之间关系的更多详细信息,请参见文本S1。
2.2.3. 道路场景解析
为了收集场景信息,我们使用了名为“金字塔场景解析网络(PSPNet)”的语义分割方法(Sun & Zheng, 2022; Yang & Guo, 2022; Yuan et al., 2022; Yue et al., 2022),这是一个场景解析模型,能够提供街道上每个场景中不同移动和固定物体的比例(https://github.com/bubbliiiing/pspnet-pytorch),更多详细信息见文本S2。根据当前研究中的实际道路场景,我们在PSPNet中配置了七个类别,包括建筑物、山脉、天空、植被、道路、河流和其他。当前研究中,这些类别已经涵盖了街道场景中绝大多数的元素。除“其他”类别外,PSPNet模型在6个对象类别中实现了最高的平均交并比(mIoU)为83.6%。尽管某些对象,如山脉区域和河流区域,其交并比(IoU)值相对较低,大约为39%,但大多数检测到的对象的IoU值超过70%,例如道路区域(93.8%)、天空区域(97.7%)、植被区域(94.5%)和建筑区域(73.0%)。每种场景类型的计算结果以图像区域的百分比表示,这些百分比作为PM2.5评估模型的输入变量。
2.3. 气象数据
我们在所有地点收集了气象数据。这些数据包括温度、相对湿度、大气压力和风速,使用了便携式气象站(Kestrel 5500, Nielsen-Kellerman, USA),采样频率为2秒。风速数据仅收集了与道路平行的风速。这些气象变量用于检查在道路交叉口采样的PM2.5对实时气象条件的响应,因为这些条件通常决定了PM2.5的形成和扩散。
2.4. 交叉口的PM2.5
在所有地点的PM2.5浓度通过DustTrak™II气溶胶监测仪8532(TSI-8532 DUSTTRAK,美国)进行测量,采样频率为2秒。TSI-8532是一种便携式仪器,准确度为±0.001 mg/m³,测量范围为0.001–150 mg/m³。附加的采样设备信息见表S2。在采样之前,我们将TSI-8532的采样结果与兰州大气成分监测超级站的数据进行了比较,以确保TSI-8532能够获得与固定监测站一致的PM2.5浓度时间序列特征(图S4)。两者之间的Pearson相关系数为0.877。在每次采样前进行零点校准,并在采样后排除超出设备测量范围的数据。我们还使用了从官方空气质量监测站收集的小时PM2.5浓度数据作为我们模型的输入特征,这些浓度可以视为背景浓度。官方的小时PM2.5浓度数据可以在中国国家环境监测中心的网站(http://air.cnemc.cn/)上获得。图1显示了所有地点和两个官方空气质量监测站(O1和O2)的地点。
2.5. 模型化PM2.5评估
研究已经证明,交通交叉口PM2.5浓度的实时变化受到气象条件、交通模式和交叉口建成环境的影响(Xu等,2022)。基于上述假设,目前选择极端梯度提升(XGB)作为评估模型。XGB模型利用梯度提升算法和正则化技术,适应复杂的非线性关系,有效控制模型复杂性,减轻过拟合风险,并提高准确性。XGB的详细信息见Chen & Guestrin(2016)。此外,XGB展示了快速执行速度和可解释性,通过特征重要性计算提供对预测结果的洞察。我们建立了极端梯度提升回归(XGBR)模型,并收集了街景、气象和PM2.5官方空气质量监测数据以训练我们的道路交叉口PM2.5预测模型。如图2b所示,为了在模型中包含气象条件和道路场景的影响,我们建立了五个XGBR回归模型(图2c)。第一个模型整合了所有来自站点1–3的数据,以训练XGBRall模型,其余四个模型使用了站点1–3的数据,并在交通控制期再次使用站点1的数据,这些模型分别称为XGBR1、XGBR2、XGBR3和XGBR1-封锁。然后在这五个模型模拟中进行SHapley Additive exPlanation(SHAP)分析,以量化每个输入变量对道路PM2.5的贡献(图2d)。值得注意的是,五个模型中只有XGBRall中的道路场景特征发生了变化。因此,我们只关注XGBRall中道路场景对道路PM2.5的影响。在确定最优采样频率时,我们比较了在2秒、4秒、6秒、8秒和10秒采样频率下获得的XGBR结果。五个XGBR模型的详细参数见表S3。
具备外推能力的模型需要更少的数据,从而降低数据收集和模型训练的成本。我们通过使用二十个不包括在训练过程中的站点(T1-T20)来验证XGBR模型的外推能力。我们将其外推性能与极端梯度提升分类(XGBC)模型进行了比较。XGBC采用与XGBRall相同的训练数据,输出数据用于PM2.5浓度区间分类。为了便于健康评估,PM2.5浓度根据世界卫生组织指南(WHO全球空气质量指南,2023)分为六组。每个浓度分类的范围见表S4。此外,我们考虑了样本数据在六个浓度分类下的统计分布,以确保模型性能未受到分类不平衡的影响。每组PM2.5数据的统计概率密度和数据量在图S5和S6中展示。
我们使用了10折交叉验证方法,总样本量为92468,使用80%的随机数据进行模型训练,其他数据用于估算和测试模型准确性。XGBR和XGBC模型使用scikit-learn Python包构建,变量归因的SHAP分析使用SHAP Python包进行,更多方法细节见Text S3。我们使用XGBR和XGBC预测了T1至T20站点的PM2.5浓度。将结果与实际数据进行比较,以评估模型的外推能力(图2c)。如果一个在站点1到3训练的模型可以预测站点T1到T20的PM2.5浓度,它有可能显著降低道路PM2.5监测的成本。
【结果】
3.1. 道路特征与交通
通过PSPNet进行场景解析,我们获得了目标街道上的基础表面覆盖百分比,包括建筑物、山脉、天空、植被、道路、河流等。图3展示了训练站点1至3和测试站点T1至T3,其余测试站点T4至T20显示在图S7中。场景分析结果表明,在所有街道场景中,道路是最突出的特征。此外,由于建筑物遮挡了天空,建筑物与天空的比例之间存在反向关系。同样,植被在遮挡建筑物方面也表现出类似的关系。建筑物和树木在目标街道的天空覆盖百分比提供了有关街道宽度和道路两侧建筑高度的信息。街道的高度与宽度比(H/W)通常用于估计街道峡谷空气污染。图3中,“其他”类别表示未特别分类的场景元素,包括道路标志、人行道和行人护栏。如图3所示,站点2的视野比站点1和站点3更开阔,而后者的道路两侧建筑物较高。站点3位于一条六车道街道上,路上的车辆数量比站点1(双车道街道)更多。由于山丘和河流在道路景观中占比非常小,因此在道路场景中被忽略。
通过YOLOv5获得了与站点1–3相关的交通量数据和车牌信息。图S8展示了站点1–3在早晨和下午的总车辆数。蓝色车牌的小型汽油车在所有站点中占据了最高数量,其次是包括混合动力电动车和纯电动车的新型能源车。燃油卡车和公交车(黄色车牌)占车辆数量的最低。站点3由于是城市的主要街道和交通动脉,观察到最多的交通拥堵,而站点1的交通最少。
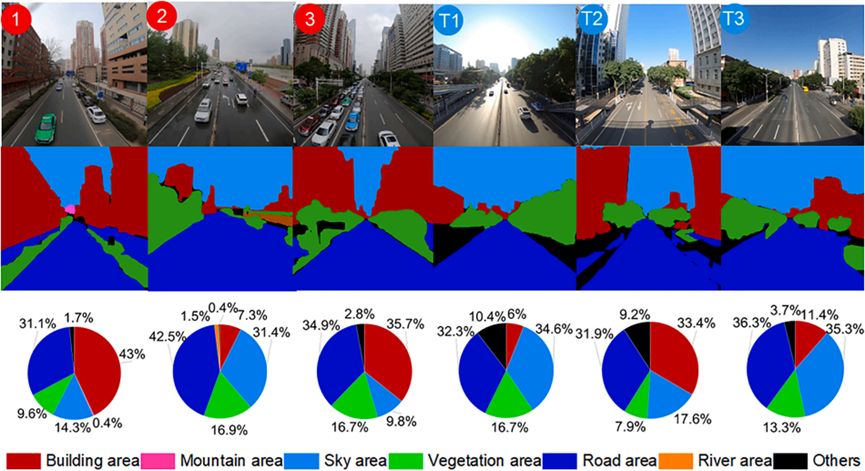
图3. 七种场景类别的分段及每个类别下的面积百分比。
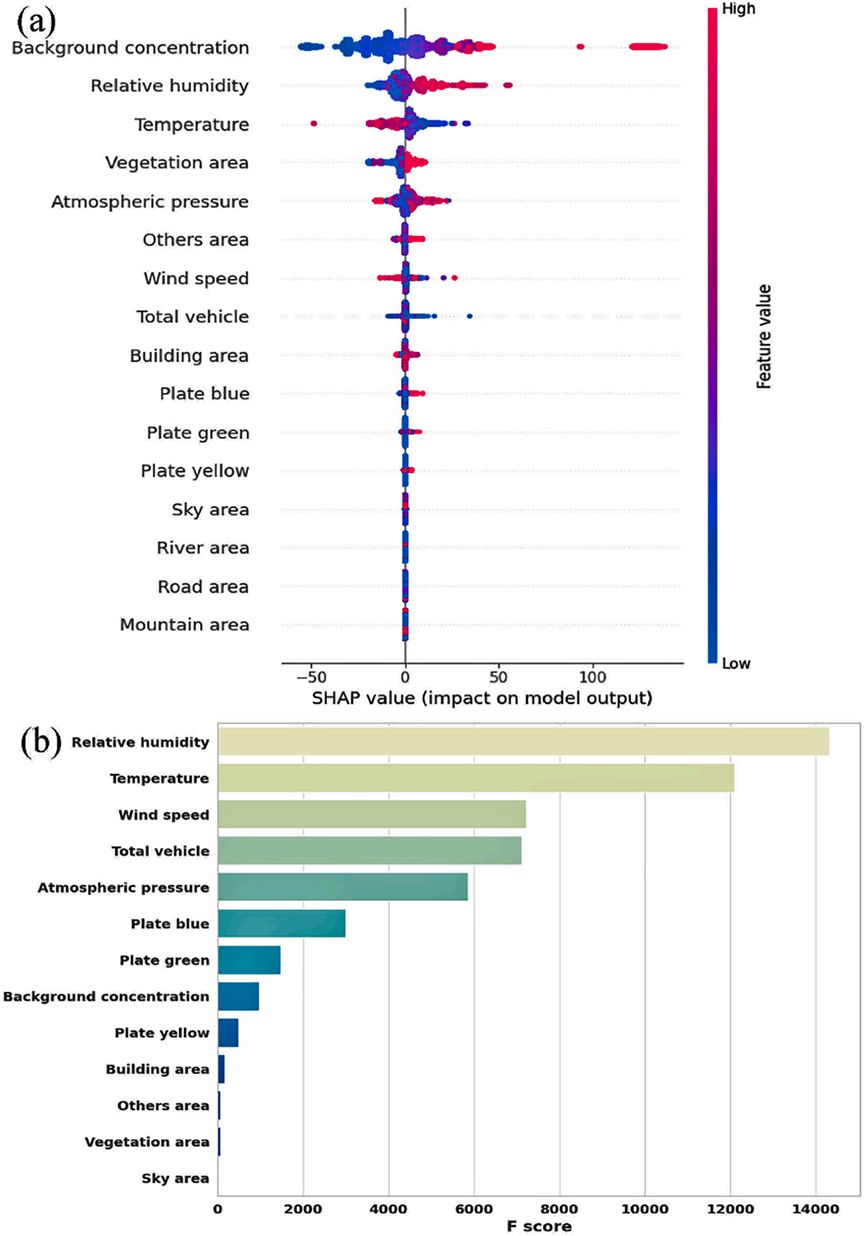
图4.(a) 基于SHAP值的输入变量:展示了XGBRall模型中输入变量的重要性,从高到低排序。(b) 基于XGB特征分数的输入变量:展示了XGBRall模型中输入变量的重要性,从高到低排序。
3.2. 道路PM2.5与气象条件
我们将各站点的样本PM2.5与离这些站点最近的官方空气质量监测站的测量值进行了比较。结果见图S9和S10。高峰时段的道路PM2.5浓度显著较高,道路PM2.5中位数比官方测量数据高1.58–2.07倍,特别是在主街道上的站点2和站点3。高浓度异常值主要出现在站点1和站点3。我们进一步分析了交通量与PM2.5浓度之间的关系。如图S8d所示,站点3的PM2.5中位数比固定监测站的值高30 μg/m³,这在三个站点中是最高的。值得注意的是,站点3也是所有站点中交通量最大的。三个位点PM2.5中位数与固定站点差值的皮尔逊相关系数为0.972,表明它们之间存在正相关关系。
便携式气象站每2秒测量的气温在下午通常高于早晨(见图S11)。风速大多小于或等于2 m/s(图S12)。相对湿度趋于稳定,波动较小(图S13)。
3.3. 评估模型化PM2.5浓度
3.3.1. XGBR性能与SHAP分析
XGBR模型用于预测站点1–3的实时PM2.5浓度,使用了收集到的道路场景、交通量、气象条件和背景PM2.5浓度。在站点1–3对每个模型进行训练和性能评估时,使用了相同站点的数据。五个XGBR模块的决定系数(R²)达到了0.956(图S14a和S15)。使用我们随机选择的500个测试样本显示,预测的PM2.5浓度在高浓度和低浓度范围内的拟合也很好(图S16)。
这五个模型的Shapley分析结果揭示了PM2.5背景浓度(来自官方空气质量监测站)和气象条件是对道路PM2.5贡献最大的因素,其次是道路场景和交通量。图4(a)展示了XGBRall对预测PM2.5浓度的不同输入变量的贡献,按从高到低排序。在站点1–3中,背景PM2.5浓度的SHAP值最高,与实时道路PM2.5浓度正相关。在这些气象变量中,相对湿度和大气压力对建模PM2.5有正面贡献,而温度则有负面贡献。风速的SHAP值为零,表明风速对实时道路PM2.5浓度没有显著贡献。对于道路场景,建筑物覆盖区域的比例与实时道路PM2.5浓度呈负相关关系。图S17显示,在站点1、站点2的XGBR1、XGBR1-封锁和XGBR2模型中,背景PM2.5浓度、气象条件和交通量的输入变量重要性依次递减。然而,对于站点3,输入变量的重要性依次为气象因素、背景PM2.5浓度和交通量。
3.3.2. 模型外推能力评估
XGBRall模型基于站点1-3的数据构建,表现出良好的预测性能(R²= 0.956)。然而,在额外的20个测试站点(T1至T20)上,其回归预测能力不足(见表S6),表明XGBRall缺乏外推能力。因此,我们转向评估XGBC模型的外推能力。图5的结果表明,XGBC的表现显著优于XGBRall。在20个测试站点中,有60%的站点的准确率高于0.6。此外,有7个站点的准确率超过了0.9。还有6个站点的准确率低于0.2,其余7个站点的准确率在0.4到0.9之间。其中,站点T1达到了最高的准确率0.998,而站点T4的准确率为零,表现最差。20个站点的平均准确率为0.592。
【讨论】
在本研究中,我们评估了道路PM2.5浓度与街景、气象条件和交通量之间的关系,采用了CVT方法。我们旨在进一步探索这种方法在预测道路PM2.5浓度中的潜在应用。结果显示,气象条件、交通量和街道峡谷形态是影响道路PM2.5浓度模型预测性的主要因素。
道路和建筑物是城市街道峡谷的主要形态,与道路上大气污染物的扩散密切相关。例如,地点1和地点3的建筑物比地点2的建筑物高;建筑物的存在影响了天空覆盖度,即低天空覆盖度意味着建筑物更多。SHAP分析可以辨别出建筑物覆盖面积和天空覆盖度在预测街道PM2.5浓度中的重要性。街道峡谷中PM2.5的移动观测和计算流体动力学模拟常采用街道纵横比(H/W)来估计空气污染物的去除。密集建筑的街道形态可以解释PM2.5空间变异的37%(He et al., 2017; Hu et al., 2021)。虽然本研究中未使用H/W模型,但显然地点1和地点3的H/W大于地点2,并且在形态上对称,可能导致更多的涡旋形成,这不利于PM2.5的去除。这可能是地点1和地点3的PM2.5浓度高于地点2的原因之一(Yazid et al., 2014)。
相对湿度和气压与PM2.5表现出正相关关系,而温度与PM2.5之间没有明显关系。之前的研究表明,高相对湿度不利于污染物的扩散,但有利于街道上二次PM2.5的形成(Huang et al., 2016)。由于兰州市的山谷地形导致稳定的层结和宁静的风速,不利于空气污染物的扩散,反而导致污染物的积累(Deaves & Lines, 1998)。温度对污染物扩散的影响一方面可以归因于热不稳定性,这有助于将空气污染物带出大气边界层;另一方面,街道形态和风向可能对污染物去除产生相反的效果,导致污染物在街道路边地面附近积累。如图S17所示,气压与地点3的PM2.5浓度具有显著的正相关关系。在地点1,气压与PM2.5之间的正相关性较弱但仍然明显。相比之下,地点2这种关系不明显。基于当前的分析方法,我们很难深入探讨不同地点之间变量贡献的差异。然而,当前方法所提供的全球变量重要性已显示气象因素的显著性。
车辆是道路上移动排放的主要来源。风速、风向、街道峡谷形态、车辆速度和车辆行驶方向的综合影响可能增加道路上空气污染物的传播,并增强PM2.5从街道峡谷中的去除。在我们的研究中,地点3的交通量最高,PM2.5水平倾向于较高;然而,地点1和地点2没有显示出与PM2.5的明确关系。带有蓝色车牌的燃油车对道路PM2.5浓度的影响大于其他车辆类型。然而,我们的研究无法区分车辆对道路PM2.5的贡献是否源自行驶车辆扬起的灰尘还是车辆排放。
模型的目标是预测PM2.5浓度,XGBR模型在不同地点的预测性能确实存在差异。图S15b明显指出,地点1的模型性能逊色于其他地点,而图S15和图S16则表明地点1的PM2.5值较高。我们比较了预测和采样浓度的统计分布,如图S20a所示。模型在预测高PM2.5浓度时表现出显著的误差,而预测值的分布与220 μg/m³以下浓度的采样值分布一致(图S20b)。因此,预测高值的缺陷可能是导致模型性能下降和结果不确定性的一个重要因素。值得注意的是,XGB方法是一种集成模型方法,融合了多个输出结果的分布。因此,预测高浓度的缺陷更可能归因于高浓度场景数据的稀缺。
模型输入输出变量的结果提供了气象条件、临近道路建筑形态和交通排放在影响道路PM2.5浓度中的不同作用的见解。在道路两侧高耸建筑物、交通流量大的街区以及气象条件不利于扩散的城市区域,在评估通勤期间PM2.5暴露时需要特别关注。在这些区域中,应定期实施固定和移动监测,以确定通勤个体在高峰时段的潜在长期暴露。
目前,利用道路影像数据进行PM2.5暴露评估展示了回归模型和分类模型各自的优势。回归模型提供了更精确的预测结果,而分类模型具有潜在的迁移能力。然而,当前模型框架仍存在一些限制。首先,气象数据作为影响不同道路交叉口PM2.5浓度差异的重要变量,仍需额外设备进行获取。其次,现实世界中的交通影像可能在分辨率、颜色和场景覆盖等方面与我们收集的数据不同,可能会影响模型结果。此外,尽管分类模型展现了迁移能力,但其稳定性仍不足以支持实际应用,因此需要进一步在真实场景中进行开发和验证。
总之,我们的研究结果确认了利用交通影像预测实时道路PM2.5浓度及其暴露评估的适用性。此外,这种方法还可以分析气象、建筑属性和交通流量等变量对不同道路交叉口PM2.5浓度的影响。迁移能力的潜力也使得该方法有可能以更高的时空分辨率捕捉城市道路大气污染特征。
【结论】
在本研究中,我们尝试建立一个利用城市交通摄像头捕捉的街景图像和机器学习模型来预测道路PM2.5污染的模型框架。我们展示了机器学习模型在道路PM2.5预测中的优秀表现。该模型在较小的样本量下实现了较好的道路PM2.5预测准确性。街景提供了有关车辆和道路环境的附加信息,使其成为道路PM2.5预测的重要变量。然而,在道路PM2.5浓度的快速波动方面,气象条件发挥了更重要的作用。
模型的外推能力在实际应用中决定了成本降低的潜力。目前的方法在一些地点表现出了出色的外推能力,表明其应用潜力。然而,考虑到当前外推结果的不稳定性,将当前研究结果应用于实际道路场景仍显不足。尽管如此,随着模型框架和数据的改进,这种低成本的道路PM2.5预测方法有可能成为现实。我们期待类似的方法在更多城市进行测试。借助人工智能技术,我们期望利用现有的公共基础设施,如交通摄像头,为城市环境和公共卫生管理者提供更丰富的工具和信息。
致谢
本研究得到了中国国家自然科学基金(42107106)和甘肃省青年科技基金项目(21JR7RA524和 21JR7RA528)的资助。感谢兰州大学超级计算中心的支持。
补充材料
与本文相关的补充材料可以在在线版本中找到,网址为:doi:10.1016/j.scs.2023.105009。
相关信息
采样点信息; 采样仪器; 模型的参数和性能; PM2.5浓度的分类和统计分布; SHAP值; 道路采样与常规空气质量监测站PM2.5浓度的比较结果; 气象参数与附近固定站点的小时数据比较结果; PSPNet和SHAP方法介绍。






![[代码随想录打卡 Day3] 链表理论基础 203.移除链表元素 707.设计链表 206.反转链表](https://i-blog.csdnimg.cn/direct/52b9b647a468402c8a5a88f7b1eec23d.png)