模型剪枝如何为企业节省百万预算?
©作者|DWT
来源|神州问学
近年来,大型语言模型(LLM)如GPT-3、LLaMA等在自然语言处理领域取得了令人瞩目的成果。然而,这些模型通常拥有数十亿甚至上千亿的参数,训练和使用成本高昂,限制了其在实际应用中的普及。如何在保持模型性能的同时,降低其使用成本,成为了研究者们关注的焦点。模型剪枝(Pruning)作为一种有效的模型压缩技术,正在为降低模型使用成本带来新的希望。
本文将聚焦于模型剪枝技术,探讨如何通过剪枝来降低大型语言模型的使用成本,并介绍两项最新的研究进展:DSA(Discovering Sparsity Allocation for Layer-wise Pruning of Large Language Models)和Pruner-Zero(Evolving Symbolic Pruning Metric from Scratch for Large Language Models)。
一、模型剪枝的价值:降低模型使用成本
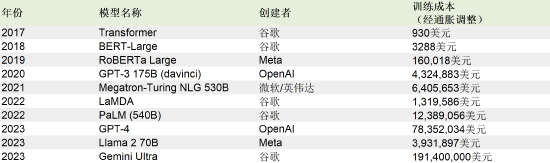
自2017年以来,经通胀调整后的主要AI模型的培训成本
1. 大型模型的训练成本
大型语言模型的训练成本极其高昂,主要由于其庞大的参数量和对海量数据的需求。例如,GPT-3拥有约1750亿个参数,训练这样的模型需要耗费巨大的计算资源和长时间的训练周期。据估计,GPT-3的训练成本在数百万美元级别。这种高昂的成本使得只有少数公司和机构能够承担,限制了大型模型的广泛应用。
2. 模型使用成本的挑战
除了训练成本外,部署和使用大型模型也面临巨大挑战。模型参数量巨大,推理时需要消耗大量的计算资源,导致延迟增加,实时性降低。此外,模型占用的存储空间庞大,部署在资源受限的设备(如移动端)上存在困难。大量的计算和存储需求直接转化为高能耗,增加了运营成本和环境负担。
3. 模型剪枝如何降低成本
模型剪枝通过删除不重要的参数,使模型变得更加稀疏,从而降低训练和使用成本。剪枝后的模型参数更少,重新训练或微调时所需的计算资源和时间大幅减少。推理过程中,剪掉的参数不再参与计算,降低了计算复杂度,提高了推理速度。模型大小的减小也降低了存储需求,使得模型可以更方便地部署在资源受限的环境中。此外,计算和存储需求的降低,直接减少了能源消耗和运营成本。
例如,通过剪枝,可以将一个拥有数十亿参数的模型缩减50%甚至更多,在保持性能的同时,推理速度提高一倍,存储需求减半。这对需要实时响应的应用,如智能客服、语音助手等,具有重要意义。
二、DSA:自动发现逐层稀疏分配函数
1. 核心思想
DSA(Discovering Sparsity Allocation)旨在解决传统剪枝方法的局限,通过自动化框架来发现针对LLM的逐层稀疏度分配方案。其核心在于利用进化算法,自动探索映射层重要性指标到稀疏率的最佳函数,确保在剪枝后模型性能的最小损失。
传统的剪枝方法通常采用全局统一的稀疏率,忽略了不同层的重要性差异,可能导致关键层被过度剪枝,影响模型的整体性能。而非关键层可能保留了过多的参数,没有充分利用剪枝的优势。DSA通过逐层分析模型参数的重要性,自动分配适合各层的稀疏率,实现了更加精细化的剪枝。
2. DSA的解决方案
(1)自动化框架
DSA利用表达式发现和进化算法,自动探索映射层重要性指标到稀疏率的最佳函数。这个过程消除了手动调整稀疏率的过程,节省了时间和人力成本。通过自动化的框架,DSA能够在庞大的搜索空间中高效地找到最优的稀疏度分配方案。
(2)逐层优化
首先,计算每层参数的重要性得分,发现前几层通常更为关键。然后,对每层的重要性得分进行预处理和缩减,提取出代表性的指标。接着,应用各种变换和后处理步骤,生成适合各层的稀疏率。通过这种方式,DSA实现了逐层的精细化剪枝,确保关键层得到充分保留,而非关键层被适当剪枝。
(3)进化算法搜索
在进化算法的框架下,DSA初始化一组候选的稀疏度分配函数。通过交叉和变异,不断改进候选方案。在每一代中,评估候选方案的性能,淘汰表现不佳的方案,保留和优化表现优异的方案。最终,确定最优的稀疏度分配函数,应用于模型剪枝。
3. 成本降低的效果
DSA方法在实际应用中取得了显著的成本降低效果:
● 模型大小减小:在对LLaMA模型进行剪枝时,模型参数量减少了约60%,但性能仅有轻微下降。
● 训练成本降低:剪枝后的模型在微调或再训练时,训练时间减少了约50%,节省了大量计算资源。
● 推理速度提升:由于参数减少,推理过程中的计算量降低,推理速度提升了近一倍。
● 存储需求降低:模型大小的减小使得存储需求显著降低,节省了超过50%的存储空间。
4. 实验结果
在LLaMA、Mistral和OPT等模型上的实验表明,DSA在高稀疏度下仍能保持较高的模型性能。例如:
● 在保持模型准确率下降不超过1%的情况下,剪枝率达到50%。
● 在一些基准测试上,剪枝后的模型性能甚至有所提升,可能是由于剪枝带来的正则化效果。
这些结果证明了DSA在降低模型使用成本方面的有效性。
三、Pruner-Zero:从零开始进化剪枝指标
1. 核心思想
Pruner-Zero旨在自动化地发现适用于LLM的最佳剪枝指标,减少对人为经验和繁琐调试的依赖。其主要创新在于将剪枝指标的发现问题转化为符号回归问题,构建了一个包含多种变量和操作的广泛搜索空间。利用遗传编程和相反操作简化策略,自动生成高效的剪枝指标。
传统的剪枝方法需要专家根据经验设计剪枝指标,耗时且效果不一定最佳。而剪枝指标对其数学表达形式敏感,可能导致剪枝效果不稳定。Pruner-Zero通过自动化的方式,避免了人为设计的局限性,提升了剪枝指标的性能和稳定性。
2. Pruner-Zero的解决方案
● 统一的搜索空间:Pruner-Zero使用权重(W)、梯度(G)和激活(X)作为剪枝指标的输入,将剪枝指标表示为符号树,节点为变量和操作符。这种表示方式构建了一个统一而广泛的搜索空间,包含了各种可能的剪枝指标。
● 遗传编程与OOS策略:在遗传编程的框架下,Pruner-Zero模拟生物进化过程,通过选择、交叉、变异等操作,搜索最优的剪枝指标。为提高搜索效率,Pruner-Zero引入了相反操作简化(OOS)策略,识别并简化符号树中的对立操作,减少冗余,加速收敛。
● 自动化发现最佳指标:通过节点突变和子树交叉,保持剪枝指标的多样性,避免陷入局部最优。OOS策略的应用,避免了重复搜索,提高了剪枝指标发现的速度和效率。最终,Pruner-Zero能够自动生成性能优异的剪枝指标,无需人为干预。
3. 成本降低的效果
Pruner-Zero在降低模型使用成本方面也取得了显著效果:
● 无需再训练:剪枝过程不需要对模型进行再训练,节省了大量的计算资源和时间。
● 模型压缩率高:通过自动生成的剪枝指标,模型参数量减少了约55%,但性能保持稳定。
● 训练成本降低:对于需要微调的模型,剪枝后的训练时间减少了约40%。
● 推理效率提升:参数减少带来了推理速度的提升,推理时间平均减少了40%。
4. 实验结果
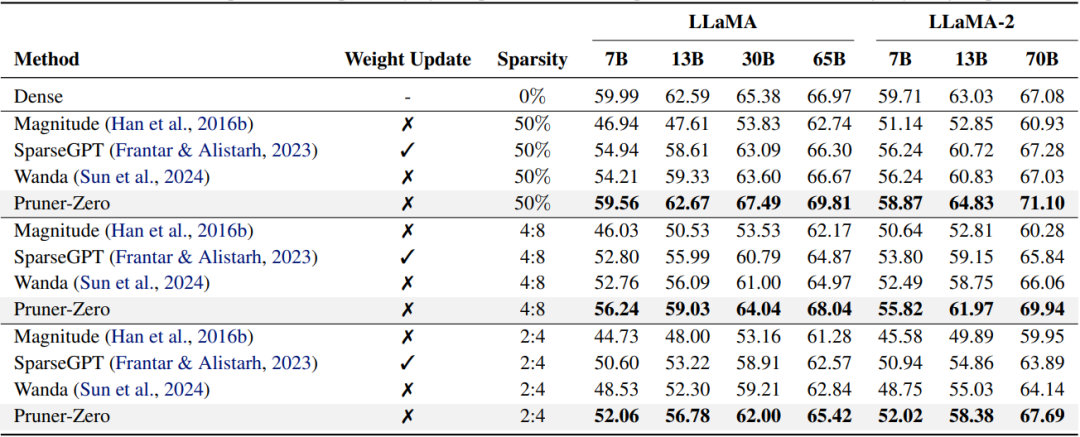
修剪后的 LLaMA 和 LLaMA-2 模型在 BoolQ、RTE、HellaSwag、WinoGrande、ARC 和 OBQA 数据集上的平均零样本准确率 (%)。Wanda 的表现与之前的最佳方法 SparseGPT 相当,且未引入任何权重更新。
在多个LLM上的实验显示,Pruner-Zero的自动化剪枝指标能够有效降低模型使用成本。例如:
● 在特定任务上,剪枝后的模型性能与原始模型几乎无差别,但参数量减少了一半以上。
● 在资源受限的设备上,剪枝后的模型能够实现实时推理,满足应用需求。
这些数据充分体现了Pruner-Zero在降低模型使用成本方面的潜力。
四、模型剪枝技术的总结与展望
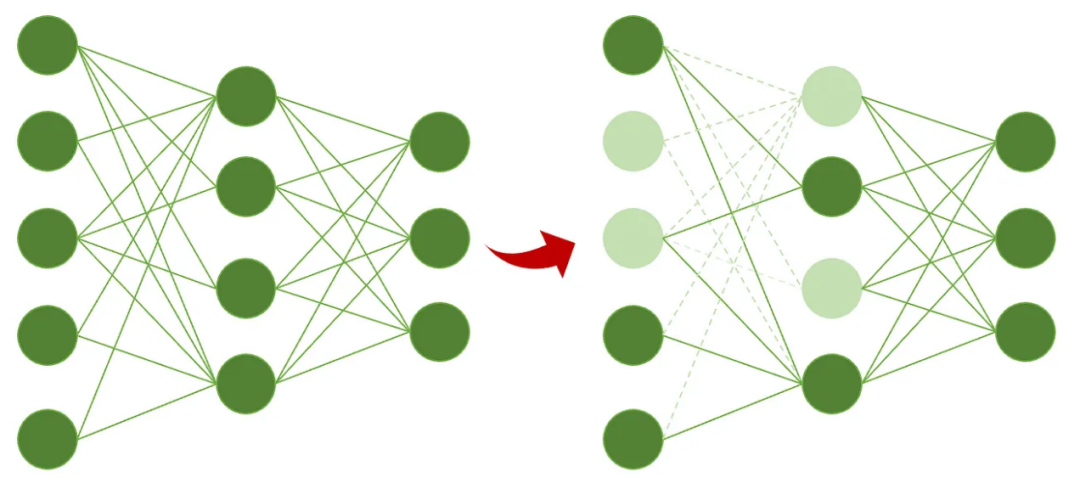
通过修剪优化深度学习模型示例
模型剪枝技术在现代AI的应用中扮演着不可或缺的角色,特别是在处理大型语言模型时,剪枝技术的重要性更是显著。通过减少模型的参数量,剪枝不仅能显著降低计算资源的需求,还能提高模型的运行效率,使模型更适合部署在资源受限的环境中,如移动设备和嵌入式系统。
剪枝技术能有效减轻模型的存储负担和加速模型的推理过程,这对于实时应用尤为重要。例如,在自动驾驶车辆和实时语音翻译设备中,快速准确的模型响应是至关重要的。此外,减少能源消耗这一点,对于运行在电池供电设备上的应用来说,更是一个巨大的优势。
从成本效益的角度来看,剪枝技术也为企业和研究机构提供了实现更经济的模型训练和部署的可能。通过减少所需的计算资源,组织可以更经济地扩展其AI能力,特别是在资源有限的情况下。这也可能促使AI技术的民主化,使更多的创新者和开发者能够参与到AI的研发中来。
展望未来,模型剪枝技术的发展将可能朝几个方向进展。首先,与其他模型压缩技术如量化和模型蒸馏的结合使用,可能会进一步提升模型效率,同时保持甚至增强模型的性能。例如,通过联合使用剪枝和量化技术,可以在极大降低模型大小和计算需求的同时,最小化性能损失。
其次,随着硬件加速器技术的发展,未来的剪枝技术可能会更加硬件友好,即优化剪枝算法以充分利用GPU、TPU等专用硬件的架构。这种硬件-算法协同设计的方法,不仅可以进一步提高运行效率,还可以在硬件层面上实现能源和成本效益的最大化。
最后,随着自动机器学习(AutoML)技术的发展,自动化剪枝算法可能会变得更加精细和高效。通过机器学习模型自动确定最优的剪枝策略,将大大减少人为干预,使模型优化过程更加智能化和自适应。这不仅可以简化模型的开发流程,还可以为特定的应用或数据集定制高度优化的模型。
五、结语
大型语言模型在带来智能化应用的同时,也伴随着高昂的训练和使用成本。模型剪枝作为一种有效的模型压缩技术,正在为降低模型使用成本、推动模型在实际应用中的落地发挥重要作用。
DSA和Pruner-Zero的研究进展,展示了通过自动化和精细化的剪枝策略,可以在保持模型性能的同时,大幅降低模型的计算和存储成本。未来,随着剪枝技术的不断发展和成熟,我们有望看到更加高效、低成本的模型应用,为人工智能的普及和发展注入新的活力。
术语解释:
● 模型量化:降低模型参数的数值精度(如从32位降到8位),以减小模型大小和加速计算。
● 模型剪枝:删除模型中不重要的权重或神经元,减少模型参数量,降低计算复杂度。
● 分层剪枝:根据模型各层的重要性差异,分别设置不同的剪枝策略。
● 稀疏度:模型中被剪枝掉的参数占总参数的比例,稀疏度越高,模型越稀疏。
● 符号回归:通过找到最能拟合数据的数学表达式,解决回归问题的方法。