一、解决方案架构

1.1 来自产业的项目
实训项目全部是基于产业的商业化项目,经过角色拆解、任务拆解、代码拆解、部署流程拆解等过程,讲其标准化为教师可以带领学生完成的实训内容,真正帮助学生接触产业前沿技术和工作内容,提升就业竞争力。
1.2 来自百度智能云的硬件设备保障
实训室配备百度智能云的磐玉-AIBOX-L01(RK3576)、磐玉-AIBOX-L02(RK3588)、磐玉-AIBOX-M01(BM1684)、磐玉-AIBOX-H01(BM1684X)服务器若干台。多规格可选,算法搭配灵活,可选使用百度算法,也支持客户算法导入。满足学员对于AI项目的实训需求。
1.3 创新的AI训练实训平台
云原生一站式机器学习/深度学习/大模型AI平台可以大大提高带领学生完成AI实训和项目开发的效率,区别于市场上现有的实训平台,完整的平台包含:
-
1、机器的标准化
-
2、分布式存储(单机可忽略)、k8s集群、监控体系(prometheus/efk/zipkin)
-
3、基础能力(tf/pytorch/mxnet/valcano/ray等分布式,nni/katib超参搜索)
-
4、平台web部分(oa/权限/项目组、在线构建镜像、在线开发、pipeline拖拉拽、超参搜索、推理服务管理等)
二、部署推理硬件:百度智能云AIBOX边缘计算



三、云原生一站式机器学习/深度学习/大模型AI平台

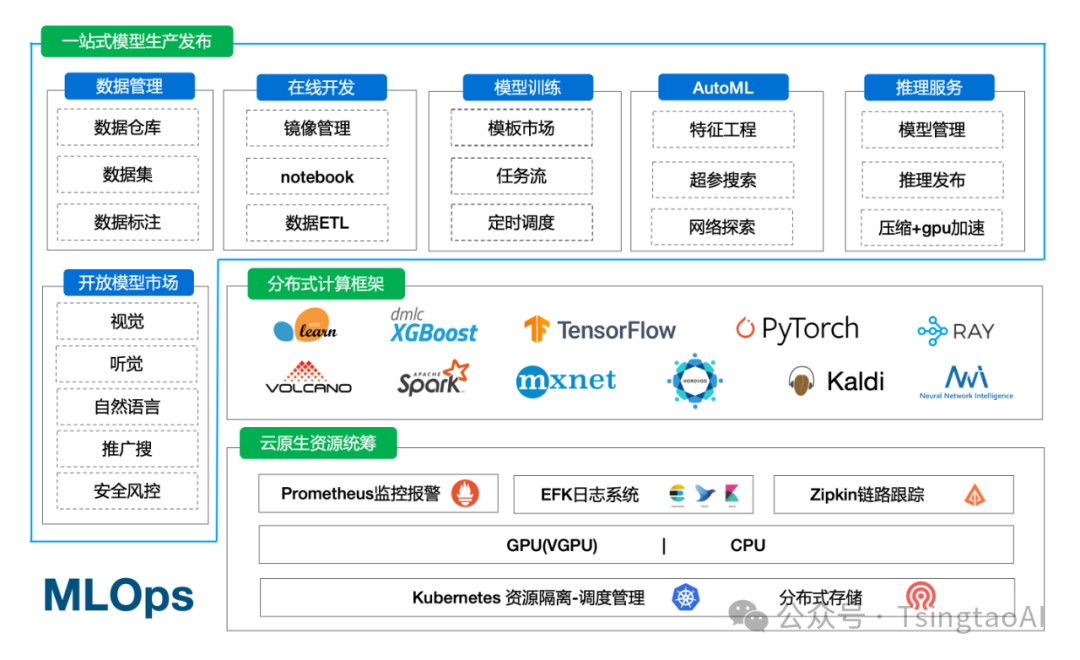
3.1 功能介绍
算力/存储/用户管理
算力:
-
云原生统筹平台cpu/gpu等算力
-
支持划分多资源组,支持多k8s集群,多地部署
-
支持T4/V100/A100/昇腾/dcu/VGPU等异构GPU/NPU环境
-
支持边缘集群模式,支持边缘节点上开发/训练/推理
-
支持鲲鹏芯片arm64架构,RDMA
存储:
-
自带分布式存储,支持多机分布式下文件处理
-
支持外部存储挂载,支持项目组挂载绑定
-
支持个人存储空间/组空间等多种形式
-
平台内存储空间不需要迁移
用户权限:
-
支持sso登录,对接公司账号体系
-
支持项目组划分,支持配置相应项目组用户的权限
-
管理平台用户的基本信息,组织架构,rbac权限体系
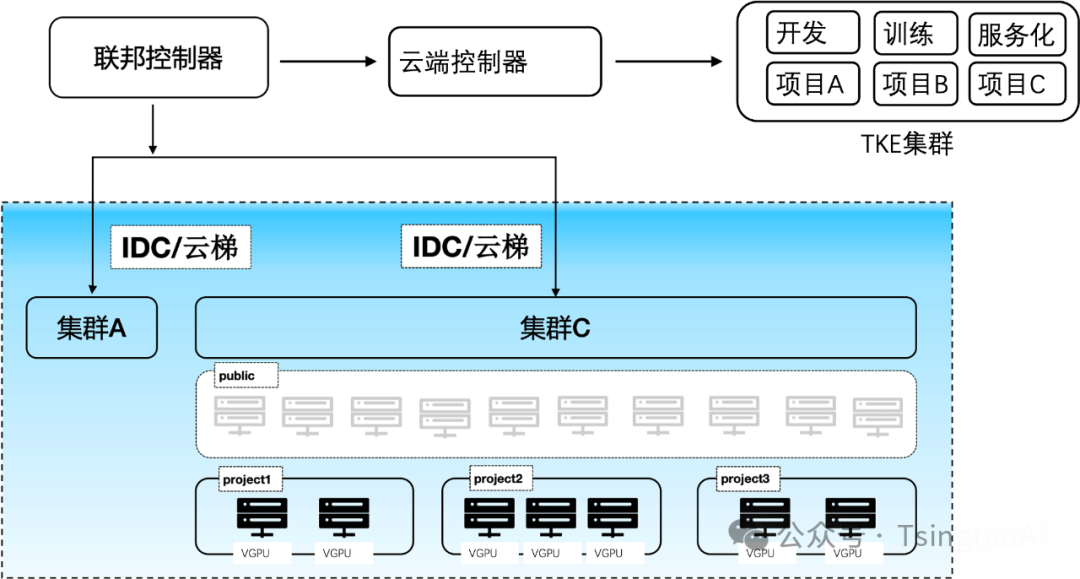
多集群管控
cube支持多集群调度,可同时管控多个训练或推理集群。在单个集群内,不仅能做到一个项目组内对在线开发、训练、推理的隔离,还可以做到一个k8s集群下多个项目组算力的隔离。另外在不同项目组下的算力间具有动态均衡的能力,能够在多项目间共享公共算力池和私有化算力池,做到成本最低化。
分布式存储
自动为用户挂载用户的个人目录,同一个用户在平台任何地方启动的容器,其用户个人子目录均为/mnt/$username。可以将pvc/hostpath/memory/configmap等挂载成容器目录。同时可以在项目组中配置项目组的默认挂载,进而实现一个项目组共享同一个目录等功能。
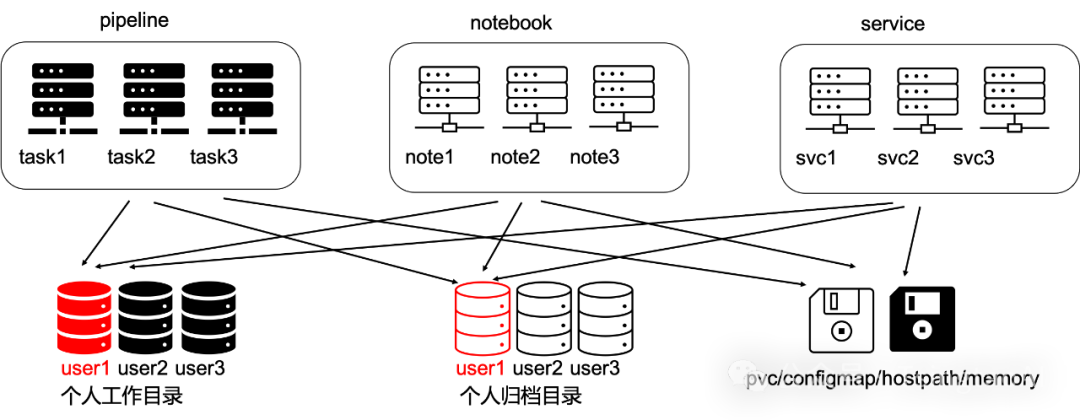
在线开发
-
系统多租户/多实例管理,在线交互开发调试,无需安装三方控件,只需浏览器就能完成开发。
-
支持vscode,jupyter,Matlab,Rstudio等多种在线IDE类型
-
Jupyter支持cube-studio sdk,Julia,R,python,pyspark多内核版本,
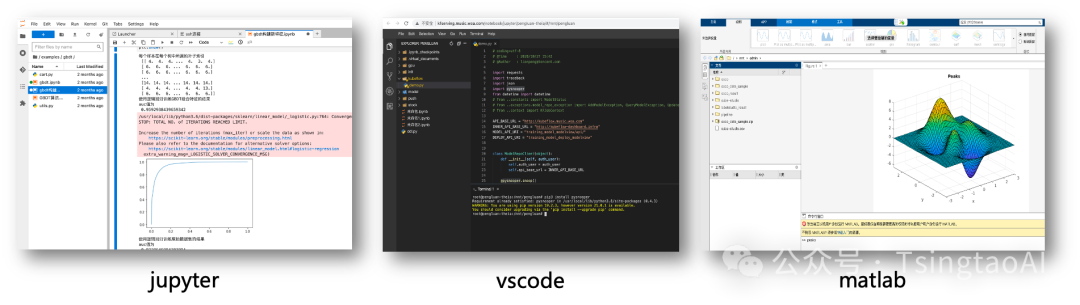
-
支持c++,java,conda等多种开发语言,以及tensorboard/git/gpu监控等多种插件
-
支持ssh remote与notebook互通,本地进行代码开发
-
在线镜像构建,通过Web Shell方式在浏览器中完成构建;并提供各种版本notebook,inference,gpu,python等基础镜像
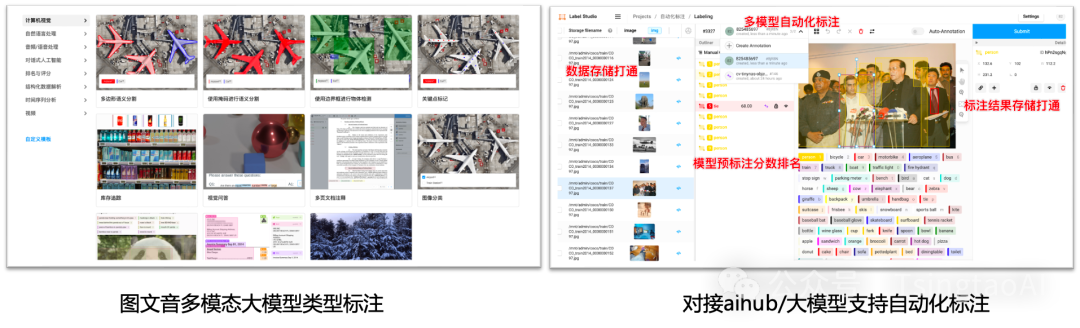
标注平台
-
支持图/文/音/多模态/大模型多种类型标注功能,用户管理,工作任务分发
-
对接aihub模型市场,支持自动化标注;对接数据集,支持标注数据导入;对接pipeline,支持标注结果自动化训练
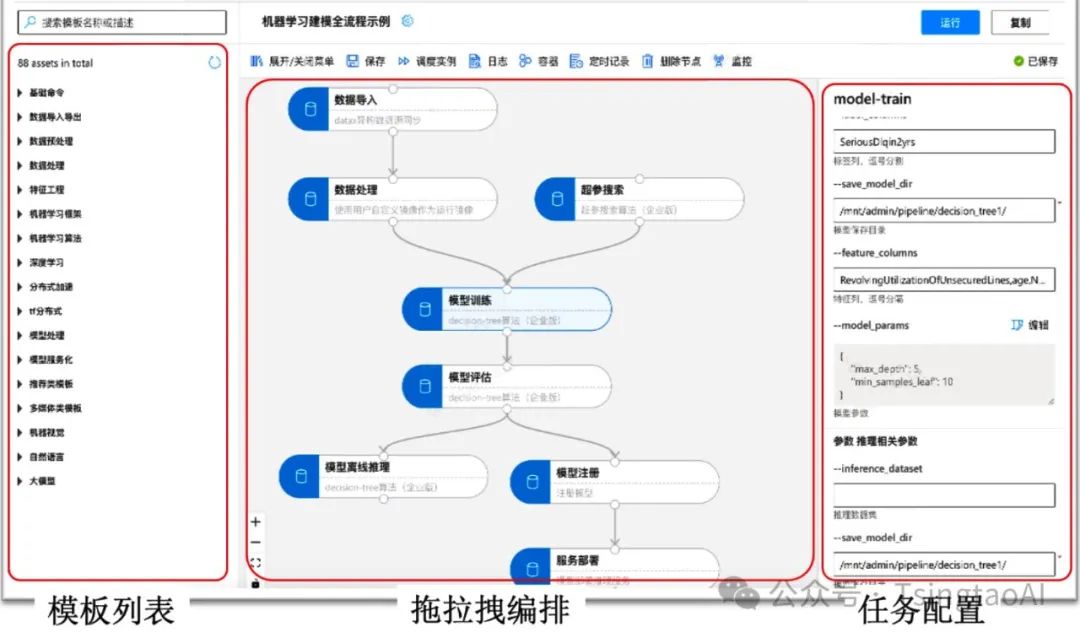
拖拉拽pipeline编排
1、Ml全流程
数据导入,数据预处理,超惨搜索,模型训练,模型评估,模型压缩,模型注册,服务上线,ml算法全流程
2、灵活开放
支持单任务调试、分布式任务日志聚合查看,pipeline调试跟踪,任务运行资源监控,以及定时调度功能(包含补录,忽略,重试,依赖,并发限制,过期淘汰等功能)
分布式框架
1、训练框架支持分布式(协议和策略)
2、代码识别分布式角色(有状态)
3、控制器部署分布式训练集群(operator)
4、配置分布式训练集群的部署(CRD)
多层次多类型算子
以k8s为核心,
1、支持tf分布式训练、pytorch分布式训练、spark分布式数据处理、ray分布式超参搜索、mpi分布式训练、horovod分布式训练、nni分布式超参搜索、mxnet分布式训练、volcano分布式数据处理、kaldi分布式语音训练等,
2、 以及在此衍生出来的分布式的数据下载,hdfs拉取,cos上传下载,视频采帧,音频抽取,分布式的训练,例如推荐场景的din算法,ComiRec算法,MMoE算法,DeepFM算法,youtube dnn算法,ple模型,ESMM模型,双塔模型,音视频的wenet,containAI等算法的分布式训练。
功能模板化
-
和非模板开发相比,使用模板建立应用成本会更低一些,无需开发平台。
-
迁移更加容易,通过模板标准化后,后续应用迁移迭代只需迁移配置模板,简化复杂的配置操作。
-
配置复用,通过简单的配置就可以复用这些能力,算法与工程分离避免重复开发。
为了避免重复开发,对pipeline中的task功能进行模板化开发。平台开发者或用户可自行开发模板镜像,将镜像注册到平台,这样其他用户就可以复用这些功能。平台自带模板在job-template目录下
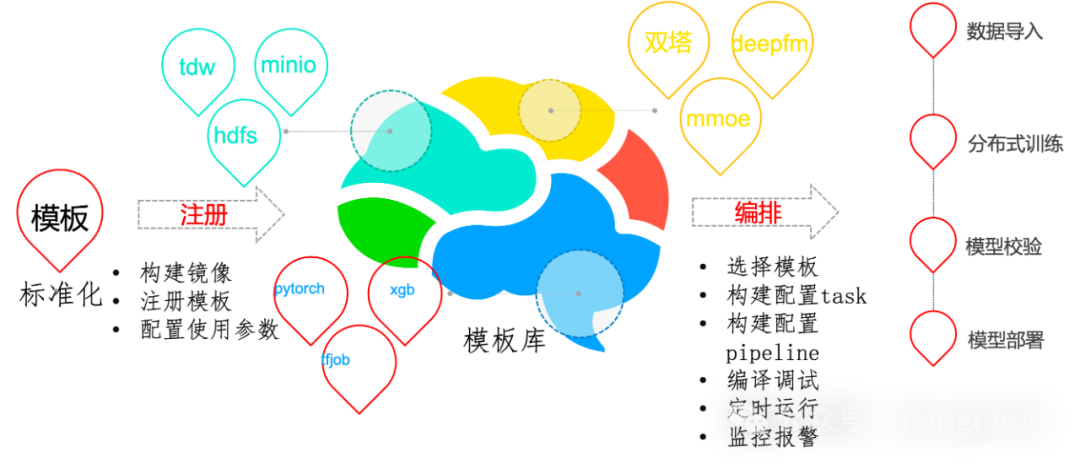
流水线调试
-
Pipeline调试支持定时执行,支持,补录,并发限制,超时,实例依赖等。
-
Pipeling运行,支持变量在任务间输入输出,全局变量,流向控制,模板变量,数据时间等
-
Pipeling运行,支持任务结果可视化,图片、csv/json,echart源码可视化
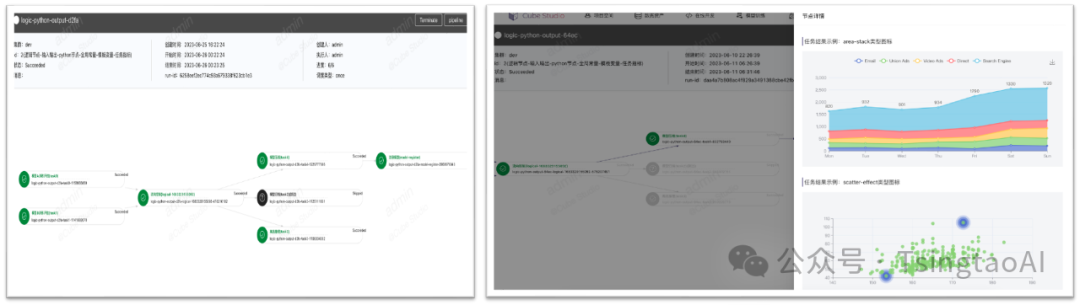
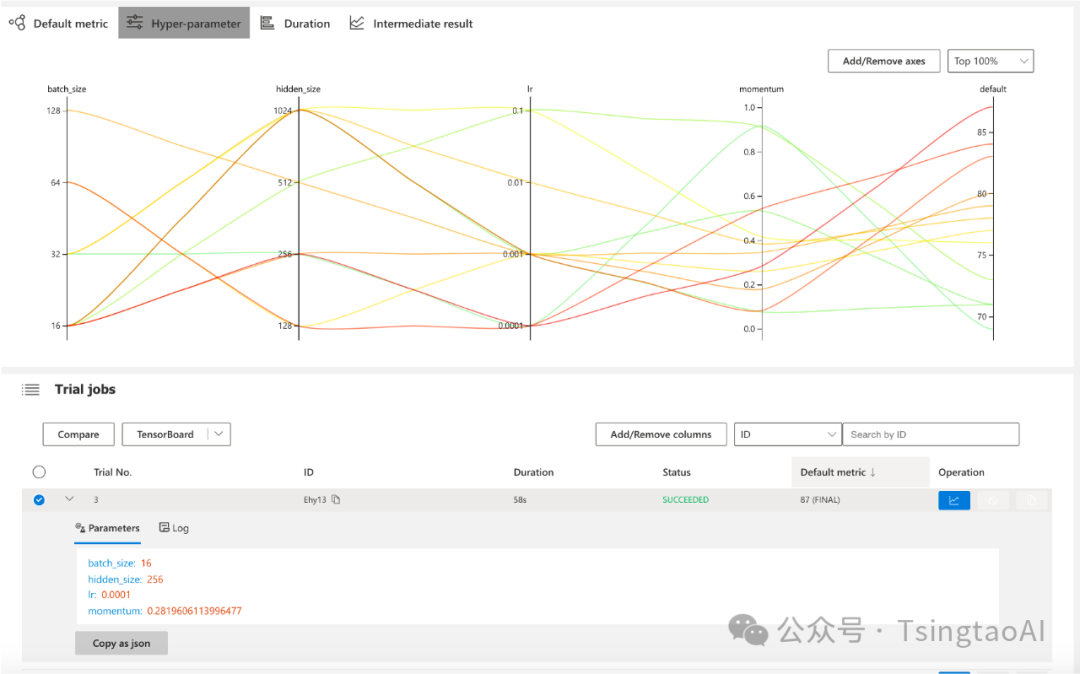
nni超参搜索
界面化呈现训练各组数据,通过图形界面进行直观呈现。减少以往开发调参过程的枯燥感,让整个调参过程更加生动具有趣味性,完全无需丰富经验就能实现更精准的参数控制调节。
# 上报当前迭代目标值
nni.report_intermediate_result(test_acc)
# 上报最终目标值
nni.report_final_result(test_acc)
# 接收超参数为输入参数
parser.add_argument('--batch_size', type=int)
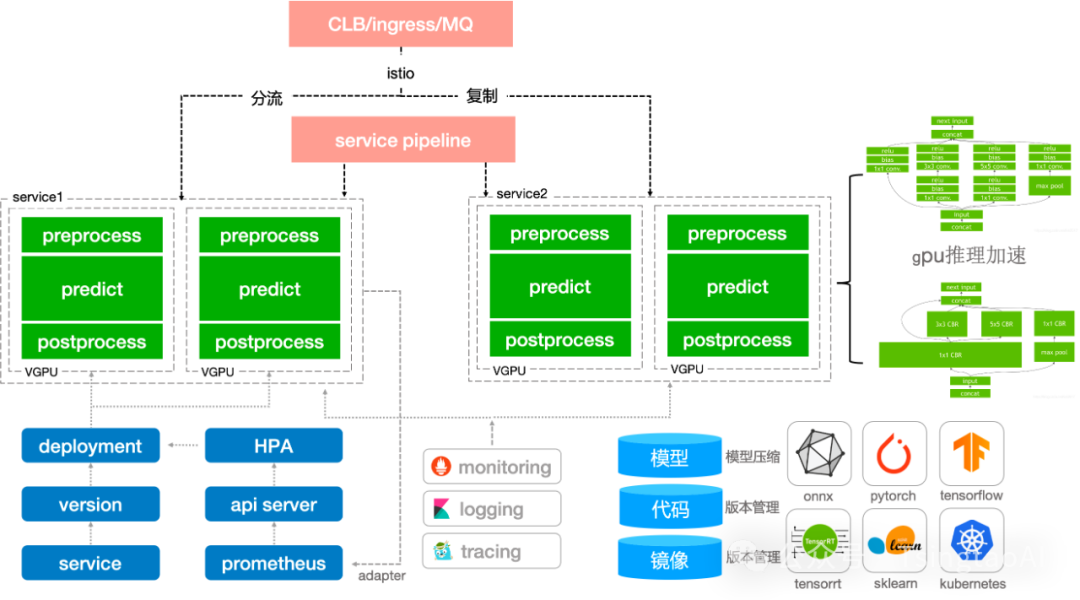
推理服务
0代码发布推理服务从底层到上层,包含服务网格,serverless,pipeline,http框架,模型计算。
-
服务网格阶段:主要工作是代理流量的中转和管控,例如分流,镜像,限流,黑白名单之类的。
-
serverless阶段:主要为服务的智能化运维,例如服务的激活,伸缩容,版本管理,蓝绿发布。
-
pipeline阶段:主要为请求在各数据处理/推理之间的流动。推理的前后置处理逻辑等。
-
http/grpc框架:主要为处理客户端的请求,准备推理样本,推理后作出响应。
-
模型计算:模型在cpu/gpu上对输入样本做前向计算。
主要功能:
-
支持模型管理注册,灰度发布,版本回退,模型指标可视化,以及在piepline中进行模型注册
-
推理服务支持多集群,多资源组,异构gpu环境,平台资源统筹监控,VGPU,服务流量分流,复制,sidecar
-
支持0代码的模型发布,gpu推理加速,支持训练推理混部,服务优先级,自定义指标弹性伸缩。
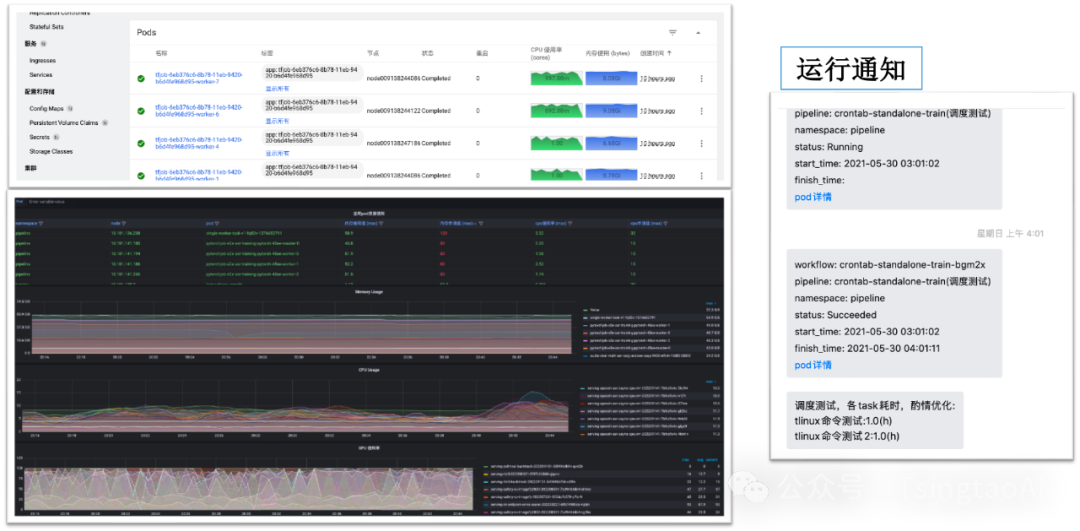
监控和推送
监控:cube-studio集成prometheus生态,可以监控包括主机,进程,服务流量,gpu等相关负载,并配套grafana进行可视化
推送:cube-studio开放推送接口,可自定义推送给企业oa系统
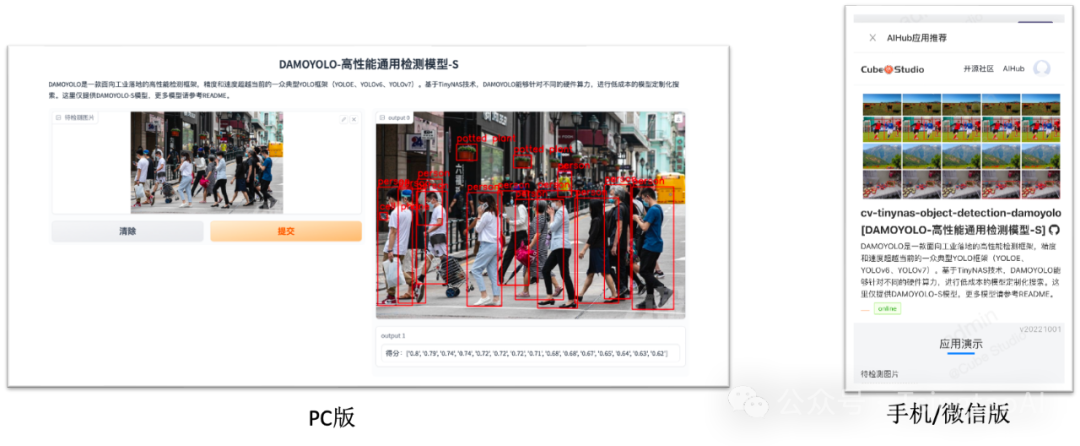
AIHub
-
系统自带通用模型数量400+,覆盖绝大数行业场景,根据需求可以不断扩充。
-
模型开源、按需定制,方便快速集成,满足用户业务增长及二次开发升级。
-
模型标准化开发管理,大幅降低使用门槛,开发周期时长平均下降30%以上。
-
AIHub模型可一键部署为WEB端应用,手机端/PC端皆可,实时查看模型应用效果
-
点击模型开发即可进入notebook进行模型代码的二次开发,实现一键开发
-
点击训练即可加入自己的数据进行一键微调,使模型更贴合自身场景
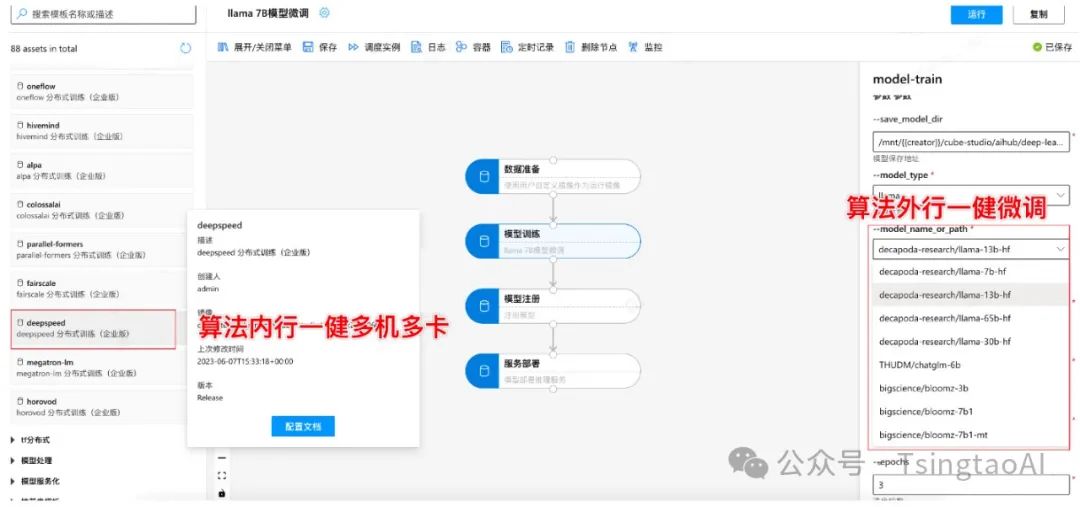
GPT训练微调
-
cube-studio支持deepspeed/colossalai等分布式加速框架,可一键实现大模型多机多卡分布式训练
-
AIHub包含gpt/AIGC大模型,可一键转为微调pipeline,修改为自己的数据后,便可以微调并部署
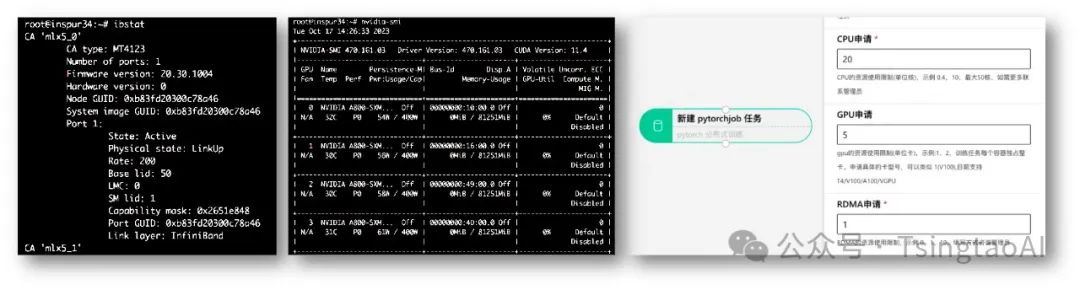
GPT-RDMA
rdma插件部署后,k8s机器可用资源
capacity: cpu: '128' memory: 1056469320Ki nvidia.com/gpu: '8' rdma/hca: '500'
代码分布式训练中使用IB设备
export NCCL_IB_HCA=mlx5 export MLP_WORKER_GPU=$GPU_NUM export MLP_WORKER_NUM=$WORLD_SIZE export MLP_ROLE_INDEX=$RANK export MLP_WORKER_0_HOST=$MASTER_ADDR export MLP_WORKER_0_PORT=$MASTER_PORT
gpt私有知识库
-
数据智能模块可配置专业领域智能对话,快速敏捷使用llm
-
可为某个聊天场景配置私有知识库文件,支持主题分割,语义embedding,意图识别,概要提取,多路召回,排序,多种功能融合
gpt智能聊天
-
可以将智能会话与AIHub相结合,例如下面AIGC模型与聊天会话
-
可使用Autogpt方式串联所有aihub模型,进行图文音智能化处理
-
智能会话与公共直接打通,可在微信公众号中进行图文音对话
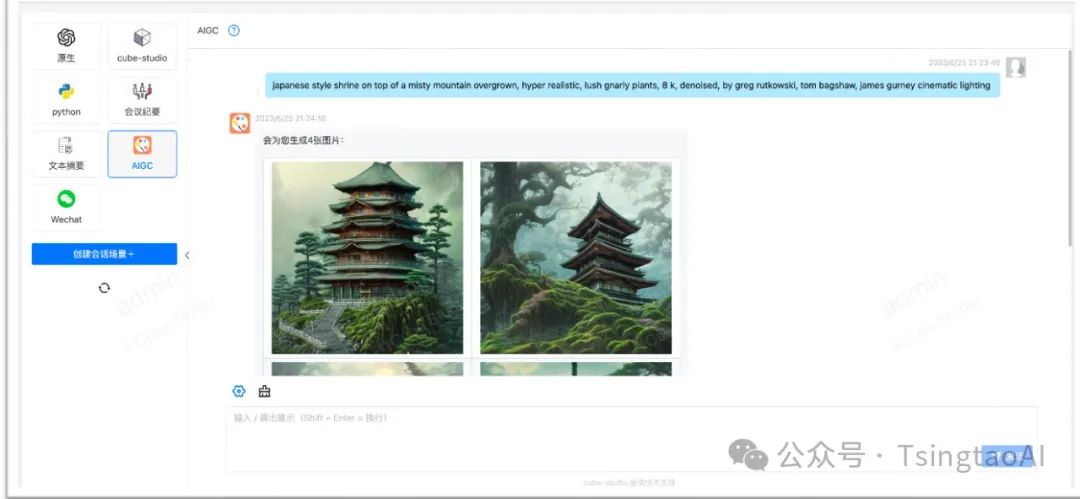
数据平台对接
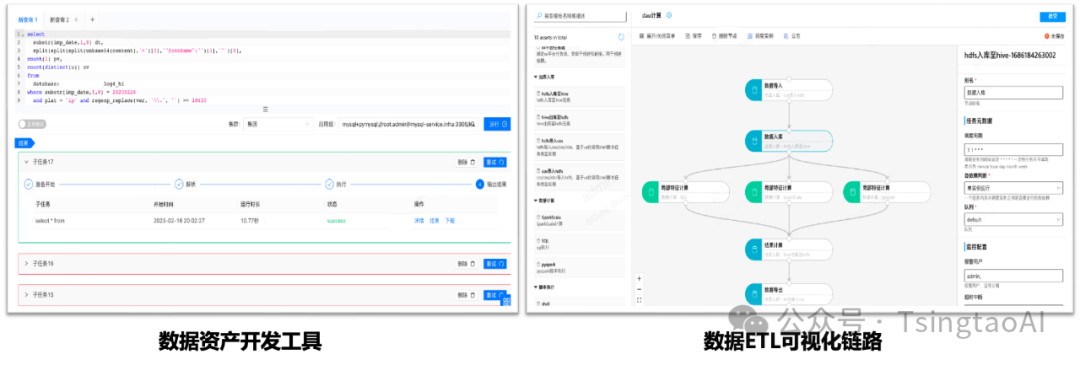
为了加速AI算法平台的使用,cube-studio支持对接公司原有数据中台,包括数据计算引擎sqllab,元数据管理,指标管理,维表管理,数据ETL,数据集管理
三种方式部署
针对企业需求,根据不同场景对计算实时性的不同需求,可以提供三种建设模式
模式一:私有化部署——对数据安全要求高、预算充足、自己有开发能力
模式二:边缘集群部署——算力分散,多个子网环境的场景,或边缘设备场景
模式三:serverless集群——成本有限,按需申请算力的场景
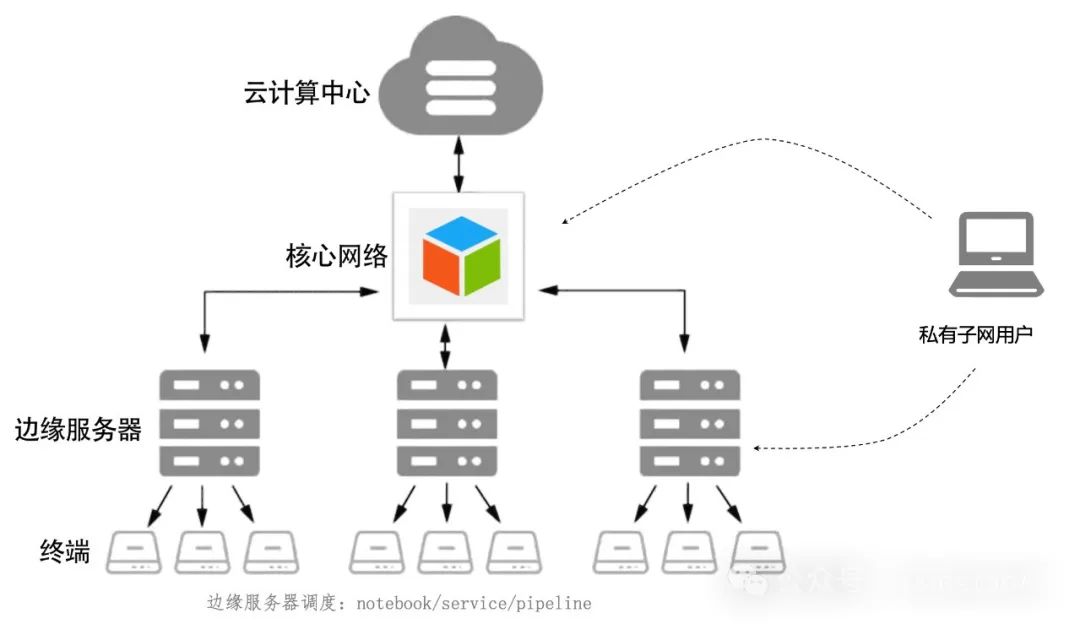
边缘计算
通过边缘集群的形式,在中心节点部署平台,并将边缘节点加入调度,每个私有网用户,通过项目组,将notebook,pipeline,service部署在边缘节点
-
1、避免数据到中心节点的带宽传输
-
2、避免中心节点的算力成本,充分利用边缘节点算力
-
3、避免边缘节点的运维成本
四、AI实训项目课程
AI实训项目包含两大类:企业级AI实训项目和AI课程。
企业级AI实训项目完全从商业化出发,全部都是真实投入市场中的项目。根据不同行业对于人才的需求,对这些真实的项目进行里程碑和任务拆解、教学环节的标准化设置等及教研工作,从商业产品变成培养符合企业实际用人需求的实训项目。AI课程选取了AI不同领域的经典案例,进行标准化的二次开发和任务拆解,从传统的讲解调整为动手实操。
4.1 企业级AI实训项目
以下是为CS/AI专业本科生设计的企业级计算机视觉(CV)实训课程大纲,涵盖了在不同业务场景中的AI应用和边缘部署实践。每门课程16课时,共8门课程,分别如下:
实训课程一:计算机视觉入门与边缘部署基础
课程大纲:
-
计算机视觉概述
-
计算机视觉的基本概念与应用场景
-
边缘计算与传统云计算的对比
-
-
AIBOX硬件架构解析
-
百度智能云AIBOX的硬件概述(RK3568、RK3576、RK3588、BM1684、BM1684X等)
-
边缘计算盒的接口与通讯协议(如USB、RS485等)
-
-
边缘计算应用场景
-
零售行业、智慧社区、智慧校园等典型场景解析
-
行业内AI算法的需求与挑战
-
-
边缘部署基础
-
算法在边缘计算设备上的部署流程
-
边缘设备与摄像头、IoT设备的整合
-
-
业务需求分析与场景设计
-
边缘计算在不同场景中的实施策略与部署规划
-
实训课程二:AI算法模型训练与优化
课程大纲:
-
计算机视觉核心算法概述
-
图像分类、目标检测与实例分割
-
在不同场景下算法的选择与对比
-
-
模型训练与优化
-
基于TensorFlow、PyTorch、ONNX等框架的训练流程
-
模型量化与加速方法(INT8量化、模型剪枝)
-
-
边缘推理与优化
-
轻量化模型在边缘设备上的应用与性能优化
-
视频流多路处理与模型优化
-
-
实验:模型训练与部署
-
模拟工业场景,设计模型训练流程,部署在通用服务器上
-
-
边缘计算优化方法
-
算力调度与算子编排,最大化利用边缘算力
-
实训课程三:智能视频分析与应用
课程大纲:
-
智能视频分析概述
-
视频分析技术与边缘计算结合的优势
-
视频编解码技术(H.265/H.264等)
-
-
典型视频分析算法
-
运动检测、人脸识别、人员越界、车流统计等
-
-
智慧城市中的视频分析应用
-
智慧社区、校园安防、园区管理等场景中的视频监控需求
-
-
边缘部署:视频流处理与推理
-
视频流采集与预处理
-
视频流实时处理与异常监测
-
-
项目实战:智能视频监控
-
模拟部署场景,实现视频分析算法并进行边缘推理
-
实训课程四:行为识别与安全监测
课程大纲:
-
行为识别概述
-
行为识别的应用领域及关键技术
-
吸烟检测、打电话检测、摔倒检测模型等应用
-
-
行为识别算法
-
视频分析与人体姿态估计的结合
-
安全监测中的行为识别技术
-
-
智能工地与智慧园区应用
-
工地人员安全监测(安全帽检测、反光衣检测)
-
园区环境安全检测(烟火检测、越界监测)
-
-
项目实战:安全监测系统设计
-
设计基于AIBOX的园区安全监测系统
-
-
边缘计算部署与验证
-
在边缘计算盒上部署行为识别算法并进行测试
-
实训课程五:车辆识别与交通监控
课程大纲:
-
车辆识别技术
-
车辆结构化识别、车牌识别、动态车流统计
-
-
智慧交通中的车辆监控
-
城市交通监控与分析需求
-
车流控制与拥堵检测技术
-
-
车辆检测算法
-
YOLO、Faster R-CNN等目标检测模型在车辆检测中的应用
-
-
实验:车辆监控系统部署
-
边缘计算盒在交通场景下的部署优化
-
车辆检测模型的调试与测试
-
-
项目实践:交通监控系统设计
-
设计一个智慧交通监控系统,应用于实际场景中
-
实训课程六:人脸识别与身份验证
课程大纲:
-
人脸识别技术基础
-
人脸检测与特征提取方法
-
人脸识别模型的训练与应用
-
-
校园与园区中的人脸识别应用
-
门禁系统、考勤签到系统
-
-
身份验证算法的实现与优化
-
人脸属性检测、姿态检测模型
-
人脸识别在多摄像头系统中的应用
-
-
边缘推理部署
-
边缘计算盒上的人脸识别算法部署
-
身份验证过程中的数据加密与隐私保护
-
-
项目实战:人脸识别门禁系统设计
-
设计校园门禁应用模型,实现人脸识别的实时验证
-
实训课程七:物体检测与场景管理
课程大纲:
-
物体检测技术
-
卷积神经网络在物体检测中的应用
-
高性能物体检测模型选择
-
-
智慧零售与工业场景中的物体检测
-
商品检测与货架管理、危险物体识别模型应用等
-
-
项目实战:零售货架管理系统
-
商品识别与数量统计
-
边缘部署货架管理系统的设计
-
-
边缘设备部署与调试
-
低功耗边缘计算盒在零售场景中的应用
-
-
系统优化
-
算力调度与低功耗设备优化
-
实训课程八:异常事件检测与预警
课程大纲:
-
异常检测技术
-
异常行为与事件检测模型
-
-
典型异常检测场景
-
食品安全监控、消防安全、工厂安全生产
-
-
实验:异常事件检测系统
-
烟火检测、人员倒地检测、越界报警等
-
-
项目实战:异常事件预警系统设计
-
在智慧工地场景中,设计异常事件检测模型应用并进行实际测试
-
-
边缘设备部署与监控
-
实现异常事件的边缘检测,并实时发送预警通知
-
4.2 AI课程
以下是为CS/AI专业本科生设计的AI课程大纲,包括2门课程,分别是《大语言模型原理及应用实践》和《AIGC应⽤开发实践》。每门课程64课时,理论32课时+实践32课时。
4.1 大语言模型方向课程:《大语言模型原理及应用实践》
理论32课时+实践32课时,10个以上PPT,实验指导书8个。
课程主要围绕大语言模型技术的核心知识点展开,重点介绍背景与基础知识、大语言模型架构、预训练、微调与对齐(P-tuning、Lora、RLHF)、推理与部署、大模型应用技术(RAG、Agent)等部分,并梳理最具代表性的模型,如GPT系列、T5、ChatGLM系列以及基于MOE结构的大语言模型等。
为帮助学生更好地理解和掌握大语言模型技术,能够快速上手相关的科研与工程项目,本课程为每个核心知识点配备有趣的实验案例,并给出详细的步骤讲解。
课程内实验案例包括:
1)法律领域大模型构建:基于中国法律知识数据使用LoRA等技术微调Gemma大模型,实现法律知识问答和法条推理功能,并基于Streamlit框架实现用户交互界面,方便用户与微调后的模型以自然语言进行法律知识问答,以及根据用户的案情描述进行法条推理。案例要求至少包含构建法律知识数据集、数据预处理、Gemma大模型原理介绍、LoRA微调LLM、模型推理、WebUI构建。实验时长4课时。
2)金融领域大模型构建:基于金融数据使用QLoRA等技术微调Llama3大模型,使其具备金融知识问答、解读年报、深度金融分析的能力,能够回答用户提出的金融专业问题,以及对年报信息进行分析,并搭建WebUI界面与用户的交互。案例要求至少包含金融知识数据集构建、数据预处理、Llama3大模型原理介绍、QLoRA技术的使用、模型推理、基于Gradio构建WebUI。实验时长4课时。
3)大模型量化:基于GPTQ、AWQ、llama.cpp等技术对大模型进行量化处理,并测试量化后模型的性能。案例要求至少包含对齐数据准备、GPTQ、AWQ、llama.cpp量化技术的原理介绍、参数配置、量化后模型的推理及性能测试。实验时长4课时。
4)农业领域大模型应用:基于检索增强生成(RAG)技术构建农业知识库,在农业知识库中检索用户输入信息的上下文来优化Prompt,并输入给大模型,实现农业知识问答系统,问答内容包含作物栽培技巧、病虫害防治措施、土壤改良建议。案例要求至少包含农业语料收集与清洗、文档加载、文本分割、Embedding、Faiss向量数据库、向量相似度计算、Rerank、模型部署与推理、WebUI构建。实验时长4课时。
5)医疗领域大模型应用:基于大语言模型(LLM)+ GraphRAG构建医学知识图谱,模型能够根据用户查询信息精准做出回答实现医学知识问答功能;能够根据用户病情描述识别潜在病症与治疗建议实现智能线上问诊功能;能够帮助用户快速阅读医学文献实现医学文献摘要功能。案例要求至少包含医学数据收集与清洗、GraphRAG安装、图索引构建、全局查询、局部查询、大语言模型本地部署(vllm)、Embedding模型部署等知识点。实验时长4课时。
6)工业制造领域Agent构建:利用铸造产品数据集训练CNN分类模型,实现工业铸造产品缺陷识别工具(Tool),并通过大语言模型(LLM)和LangChain中的ReAct框架创建工业铸造产品缺陷识别智能体(Agent),Agent根据用户输入的图片自主进行思考、观察、行动,最终完成铸造产品缺陷识别的任务。案例要求至少包含训练工业铸造产品缺陷识别模型、LLM本地部署、ReAct框架的原理与运行机制、提示模板设计。实验时长4课时。
7)课程大纲包括课程基本信息、课程教学目标、课程教学内容和要求、课程教学方法、课程考核、本课程与其他课程联系与分工、建议教材及教学参考书七个部分。
4.2 多模态大模型方向课程:《AIGC应⽤开发实践》
理论32课时+实践32课时,20个PPT,实验指导书8个。
课程旨在系统讲解AIGC相关的理论和技术,并配套相关的实验案例,提供包括大模型技术概述、面向理解任务的多模态大模型、面向生成任务的多模态大模型、兼顾理解和生成任务的多模态大模型、知识增强的多模态大模型、大模型的预训练与微调、大模型的评估压缩推理与部署、大模型的安全性、课程总结等课程内容,提供基于CLIP模型的智能广告生成系统、基于VATT模型的视频检索系统、基于Stable Diffusion模型的影视特效生成、基于VL-T5模型的智能教育问答系统等共计8个配套实验。
课程内实验案例包括:
1) 包括基于CLIP模型的智能广告生成系统:利用先进的图像与文本匹配技术,实现自动化创作个性化高相关度广告内容,提升营销效率与用户体验。
2) 包括基于VATT模型的视频检索系统:该实验融合视觉、音频、文本及时序信息,实现精准高效的视频内容搜索与定位,从而优化视频检索的用户体验。
3) 包括基于DDPM模型的高质量图像生成:通过深度学习与强化学习的结合,从而可生成细腻逼真的图像,推动数字艺术与视觉内容创作的新边界。
4) 包括基于Stable Diffusion模型的影视特效生成:通过扩散模型的微调,可生成影视特效画面,从而革新视觉效果制作,快速渲染逼真特效,加速影视后期制作,引领影视艺术新潮流。
5) 包括基于VL-T5模型的智能教育问答系统:融合视觉与自然语言理解技术,可实现精准解答学习疑问,助力个性化教育,提升学习效率。
6)包括 基于ERNIE-ViL模型的智慧医疗系统:通过深度融合视觉与语言知识,精准辅助医疗决策,提升诊疗效率与质量,引领健康医疗新未来。
7) 包括基于Unified VLP模型的智慧工厂监控系统:集成视觉与自然语言处理技术,实时监控生产流程,优化资源配置,提升工厂智能化管理水平。
8)包括 基于BLIP-2模型的智能音乐生成系统:融合多模态学习,自动创作个性化旋律与和声,开启音乐创作新纪元。
4.3 课程配套
1)课程介绍
2)课程大纲
3)PPT课件
《大语言模型原理与应用实践》课程包含十章PPT课件,涉及内容为认识大语言模型、大语言模型基础、大语言模型的主流架构、稀疏结构大模型、大语言模型训练技术、人类对齐、大语言模型推理与部署、检索增强生成技术、智能体、大语言模型评估;
《AIGC应用开发实践课程:多模态大模型应用开发》课程包含二十一章PPT课件,涉及大模型技术概述、大模型的基础知识、多模态大模型概述、CLIP模型原理、VATT模型原理、ALIGN模型原理、基础扩散模型原理、DDPM模型原理、DDIM模型原理、Stable Diffusion模型原理、VL-T5模型原理、Unified VLP模型原理、BLIP-2模型原理、ERNIE-ViL模型原理、大模型的预训练、大模型的微调技术、大模型的评估、大模型的压缩技术、大模型的推理与部署、大模型的安全性、课程总结与未来展望。
4)实验指导书
《大语言模型原理与应用实践》实验指导书包含8个;
《AIGC应用开发实践课程:多模态大模型应用开发》实验指导书包含8个。
5)实验相关资料
《大语言模型原理与应用实践》实验案例提供实验环境和实验指导手册。包含源码、实验目的、实验内容、实验数据、实验知识点、实验时长、实验环境介绍、实验分析、实验过程详解(模型和数据下载、代码构建与分析、实验结果);
《AIGC应用开发实践课程:多模态大模型应用开发》实验案例提供实验环境和实验指导手册。包含源码、实验目的、实验内容、实验数据、实验知识点、实验时长、实验环境介绍、实验分析、实验过程详解(模型和数据下载、代码构建与分析、实验结果)。